Spark 初级编程实践
什么是Spark?
Spark是一个快速、通用、可扩展的大数据处理引擎,最初由加州大学伯克利分校的AMPLab开发。它提供了高级API,用于在大规模数据集上执行并行处理。Spark支持多种编程语言,包括Java、Scala、Python和R,因此被广泛应用于大数据分析和机器学习等领域。
一、目的
1、掌握使用 Spark 访问本地文件和 HDFS 文件的方法
2、掌握 Spark 应用程序的编写、编译和运行方法
二、平台
(1)操作系统:Ubuntu20.04或其他稳定版本;
(2)Spark 版本:3.1.3;
(3)Hadoop 版本:3.1.3。
三、步骤
1、Spark读取文件系统的数据
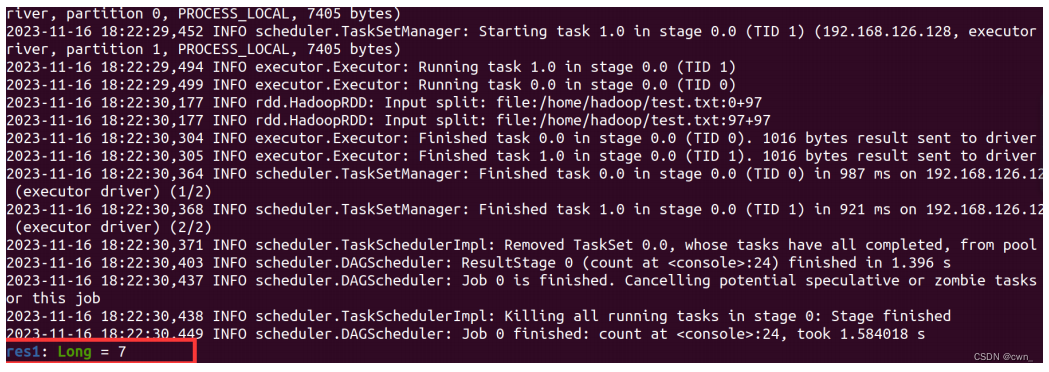
(1)在 spark-shell 中读取 Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
启动spark-shell:
cd /usr/local/spark
bin/spark-shell

读取文件:
val textFile=sc.textFile("file:///home/hadoop/test.txt")

统计文件的行数:
textFile.count()
(2)在 spark-shell 中读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在, 请先创建),然后,统计出文件的行数;
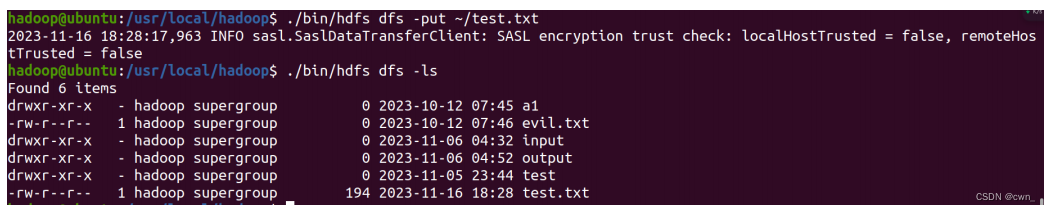
启动Hadoop,向hdfs中上传文件test.txt:
./sbin/start-dfs.sh
./bin/hdfs dfs -put ~/test.txt
./bin/hdfs dfs -ls
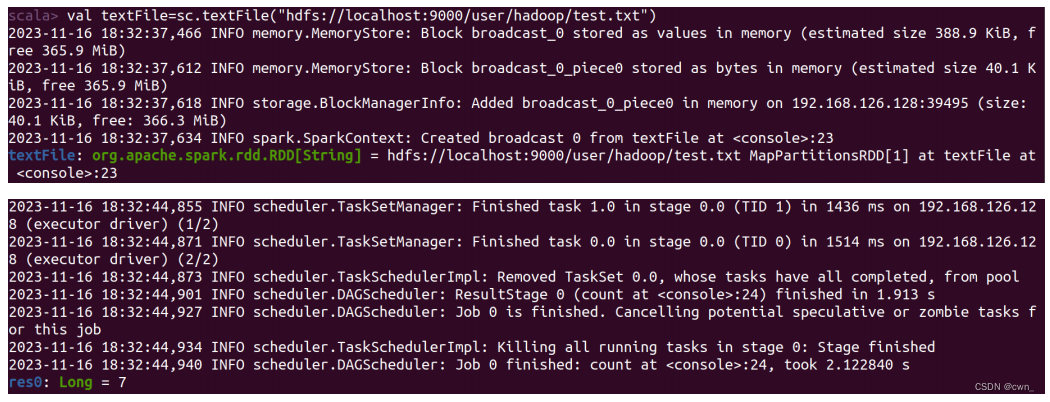
读取 HDFS 系统文件“/user/hadoop/test.txt”并统计文件的行数:
val textFile=sc.textFile("hdfs://localhost:9000/user/hadoop/test.txt")
textFile.count()
(3)编写独立应用程序(使用 Scala 语言),读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包,并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令。
查看sbt版本,验证sbt安装成功:
cd /usr/local/sbt
./sbt sbtVersion

创建一个文件夹 sparkapp 作为应用程序根目录并编写HDFStest.scala文件:
cd ~ # 进入用户主文件夹
mkdir ./sparkapp # 创建应用程序根目录
mkdir -p ./sparkapp/src/main/scala # 创建所需的文件夹结构
cd sparkapp/src/main/scala
touch HDFStest.scala #创建名为HDFStest.scala的文件
gedit HDFStest.scala #编写程序
HDFStest.scala文件内容:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object HDFStest {
def main(args: Array[String]) {
val logFile = "hdfs://localhost:9000/user/hadoop/test.txt"
val conf = new SparkConf().setAppName本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 飞凌嵌入式T113-i开发板的调屏方法,就是这样简单
- 外汇天眼:BarnBridge解决SEC指控 SMART Yield池吸引5.09亿美元
- 零基础开发 React+ TS 后台实战课程介绍
- 第七章 函数(三)
- U盘无法安全弹出怎么办?
- Arduino stm32 USB CDC虚拟串口使用示例
- 从Scroll怒喷社区用户事件,看L2龙头ZKFair的做事格局
- 基于SSM的在线电影票购买系统(有报告)。Javaee项目。ssm项目。
- 【Linux】Linux Page Cache页面缓存的原理
- 性能测试 —— 生成html测试报告、参数化、jvm监控