掌握Spring缓存-全面指南与最佳实践

第1章:引言
大家好,我是小黑,咱们今天来聊聊缓存,在Java和Spring里,缓存可是个大角色。咱们在网上购物,每次查看商品详情时,如果服务器都要去数据库里翻箱倒柜,那速度得慢成什么样?这就是缓存发光发热的时刻。缓存就像是服务器的“小抽屉”,把经常用到的数据放在里面,下次需要的时候,直接从“小抽屜”里拿,快得多。
缓存的概念很简单,但深入了解它的工作原理,对提升咱们应用的性能有巨大的帮助。缓存减少了数据库的压力,提高了响应速度,是高性能应用不可或缺的部分。
Spring提供了一套优雅的缓存抽象,让咱们不仅可以轻松地实现缓存,还能方便地切换不同的缓存方案。这意味着,咱们只需要简单的配置,就可以享受到缓存带来的种种好处。
第2章:Spring框架及缓存简介
Spring框架不仅仅是一个框架,它更像是一个庞大的生态系统,提供了从核心容器、数据访问/集成、Web应用到云服务等全方位的解决方案。Spring的核心是依赖注入(DI)和面向切面编程(AOP),这两个功能让代码更加模块化,易于管理和维护。
来,咱们看个简单的例子,理解一下Spring是怎么工作的。想象咱们有个类BookService,它依赖于另一个类BookRepository。在没有Spring的世界里,可能得这样写:
public class BookService {
private BookRepository bookRepository = new BookRepository();
}
但在Spring的世界里,咱们可以这样写:
@Service
public class BookService {
@Autowired
private BookRepository bookRepository;
}
看到没有?这里的@Service和@Autowired就是Spring的用法。它们告诉Spring,BookService是个服务层的组件,而且需要自动注入(自动装配)一个BookRepository的实例。这样,Spring就会自动处理这些依赖关系,咱们不需要手动创建对象,一切都交给Spring来管理。
而对于缓存来说,Spring框架提供了一种简洁的方式来声明方法调用的缓存规则。通过注解,比如@Cacheable,咱们可以轻松地将方法的返回值缓存起来。比如,咱们有个方法用来获取书籍详情,每次调用这个方法都要去查询数据库,花费不少时间。但使用了Spring的缓存注解后,情况就不同了:
@Cacheable("books")
public Book getBookById(String bookId) {
// 这里是查询数据库的操作
return bookRepository.findBookById(bookId);
}
在这个例子中,@Cacheable("books") 告诉Spring,当调用getBookById方法时,先检查缓存中是否有以bookId为键的缓存。如果有,直接从缓存中返回结果,不再执行方法体内的代码。如果没有,执行方法体,将结果存入缓存,并返回结果。这样一来,当同一个bookId的请求再次发生时,就能极大地提高响应速度了。
Spring框架的美在于它的强大和灵活。通过依赖注入和面向切面编程,它简化了Java应用的开发和维护。而在缓存方面,Spring提供的抽象层使得实现和管理缓存变得异常简单,让应用的性能得到了显著的提升。在接下来的章节中,咱们会深入探讨Spring中的缓存机制,以及如何在实际项目中高效地使用它。
第3章:缓存基础
在咱们深入Spring框架的缓存之前,先来聊聊缓存的基础。理解缓存的工作原理对于有效使用和管理缓存至关重要。缓存,简单来说,就是一种保存数据副本的技术,目的是加快数据检索速度。这就像是小黑的书桌抽屉,经常用的笔和本子放在最上面,不常用的东西放在下面。需要笔的时候,直接从上层拿,不用每次都翻箱倒柜。
缓存的工作原理
缓存的核心是减少访问高成本资源(如数据库)的次数。当一个请求来到,系统首先检查是否有缓存数据。如果有,直接使用缓存数据;如果没有,才去访问数据库,同时将结果存入缓存。下次同样的请求来时,就可以直接用缓存的数据了。
缓存类型
在Java中,缓存可以大致分为两种:本地缓存和分布式缓存。
-
本地缓存:数据存储在本地内存中。速度快,但容量有限,且不利于多服务间的数据共享。举个例子,假设小黑在自己电脑上跑了个Java程序,用HashMap作为缓存:
Map<String, Object> cache = new HashMap<>(); cache.put("key", "这是一条缓存数据"); Object data = cache.get("key");这里的
HashMap就是个简单的本地缓存。但这只适用于小型或单机应用。 -
分布式缓存:数据存储在网络上的多台服务器中。适用于大型、分布式系统,如Redis、Memcached等。
// 假设使用Redis作为分布式缓存 Jedis jedis = new Jedis("localhost"); jedis.set("key", "这是一条分布式缓存数据"); String data = jedis.get("key");这段代码使用了Redis作为缓存。Redis是一个非常流行的分布式缓存解决方案。
缓存策略
缓存的有效管理还需要合适的缓存策略。最常见的有:
- 最近最少使用(LRU,Least Recently Used):淘汰最长时间未被使用的数据。
- 先进先出(FIFO,First In First Out):按数据的到达顺序进行淘汰。
- 最少使用(LFU,Least Frequently Used):淘汰使用次数最少的数据。
每种策略都有各自的适用场景。比如,LRU适合那些经常访问相同数据的应用。
理解了缓存的基本概念,咱们就能更好地把握Spring框架中的缓存使用和管理了。缓存虽小,但功不可没,它在提升应用性能、减轻数据库负担方面发挥着巨大作用。在接下来的章节中,咱们将深入Spring的缓存抽象,探索如何在Java应用中高效地利用缓存。
第4章:Spring缓存抽象
现在咱们来深入一下Spring框架中的缓存抽象。在Spring中,缓存不仅仅是个简单的工具,它是一种编程模式,可以让咱们的应用更加高效。
缓存抽象的概念和优势
在Spring框架中,缓存抽象主要是通过一系列的接口和注解来实现的。这种设计让咱们可以在不改变代码逻辑的情况下,灵活地切换不同的缓存实现。比如,今天用本地缓存,明天想换成Redis,后天又想试试EhCache,都是轻轻松松、随心所欲。
核心接口和类
在Spring的缓存抽象中,最重要的几个接口和类包括:
CacheManager:管理各种缓存(Cache)实例。Cache:Spring中缓存的接口,定义了缓存的基本操作。- 注解:如
@Cacheable、@CachePut、@CacheEvict等,用于声明方法的缓存行为。
来,咱们看个例子。假设小黑有个服务,需要通过ID获取用户信息,这种情况下使用缓存就非常合适:
@Service
public class UserService {
// 这里假设有个方法用来真正获取用户信息
public User getUserById(String id) {
// 模拟数据库操作
return new User(id, "用户姓名");
}
// 使用Spring的缓存注解
@Cacheable(cacheNames = "user", key = "#id")
public User getCachedUserById(String id) {
return getUserById(id);
}
}
// 简单的用户类
class User {
private String id;
private String name;
User(String id, String name) {
this.id = id;
this.name = name;
}
// 省略getter和setter方法
}
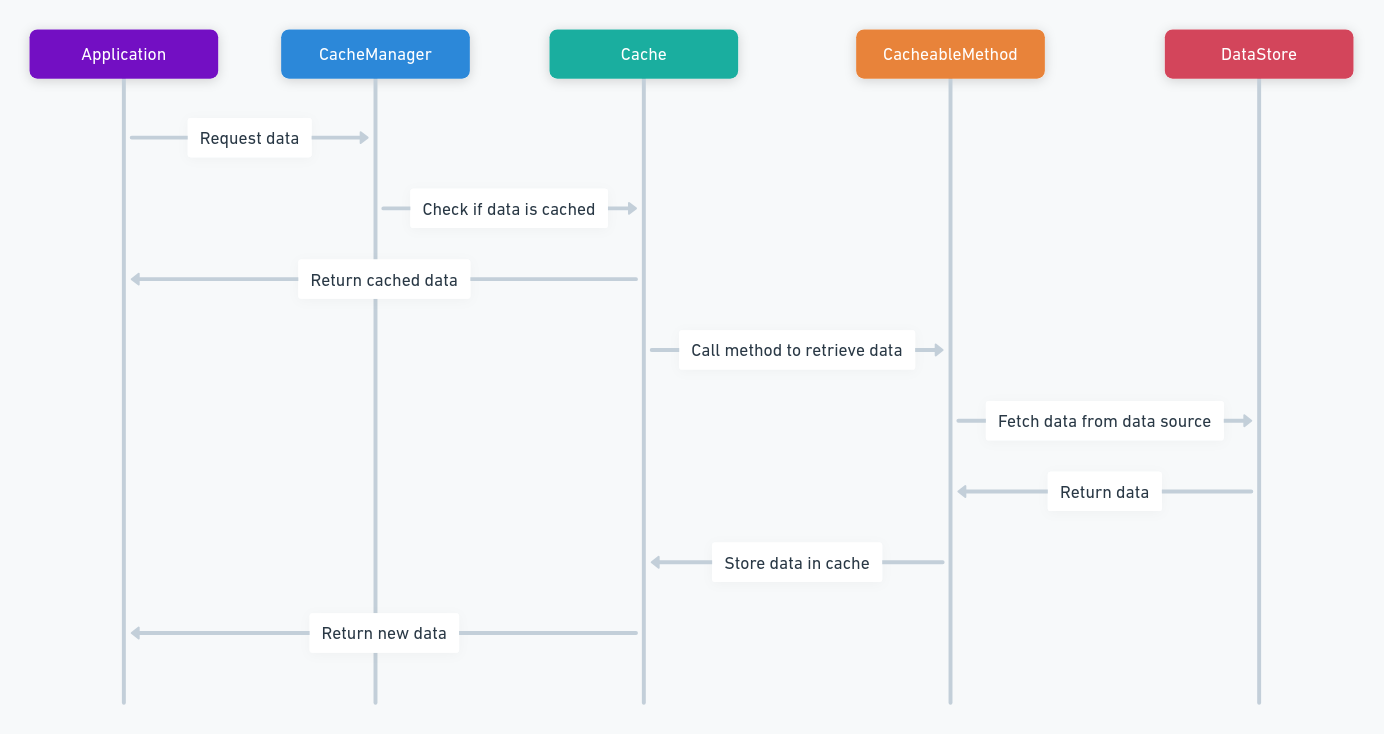
在这个例子中,@Cacheable注解告诉Spring,当调用getCachedUserById方法时,先查看名为user的缓存中是否有以用户ID为键的缓存项。如果有,直接返回缓存项,不执行方法体;如果没有,执行方法体,然后将结果存入名为user的缓存。
缓存抽象的优势
使用Spring的缓存抽象,咱们可以享受以下几个优势:
- 简化开发:通过注解,可以轻松实现复杂的缓存逻辑。
- 灵活性:支持多种缓存技术,轻松切换。
- 可维护性:缓存逻辑和业务逻辑分离,代码更加清晰。
通过Spring的缓存抽象,咱们可以实现高效且易于维护的缓存策略,大大提高了应用的性能和可扩展性。记住,优秀的缓存策略不仅可以提升性能,还能减轻后端存储的压力,这在处理大量数据和高并发场景下尤为重要。
第5章:Spring Cache注解详解
本章让咱们来聊聊Spring Cache的注解。这些注解是Spring提供的一大利器,能让缓存的实现变得轻而易举。通过几个简单的注解,咱们就可以控制方法如何缓存,怎样更新缓存,甚至是何时清除缓存。这不仅提高了开发效率,还增加了代码的可读性。
@Cacheable
@Cacheable 是最常用的缓存注解之一。它会在方法执行前检查缓存,如果缓存中存在相应的数据,就不执行方法,直接返回缓存数据。
看这个例子,假设咱们有个获取书籍详情的方法:
@Cacheable(value = "books", key = "#isbn")
public Book findBookByIsbn(String isbn) {
// 这里是查询数据库的操作
return new Book(isbn, "书名", "作者");
}
在这里,value 属性指定了缓存的名称,key 属性指定了缓存的键。这意味着当调用 findBookByIsbn 方法时,Spring会检查名为 books 的缓存中,是否有键为该方法参数 isbn 的缓存项。如果有,就直接返回缓存的数据;如果没有,就执行方法体,并将结果存入缓存。
@CachePut
@CachePut 注解用于更新缓存数据。这个注解确保方法始终被执行,同时其返回值也会
放入缓存中。这常用于更新操作,确保缓存中存储的是最新数据。
例如,当小黑更新一本书的信息时,可以使用 @CachePut 来确保缓存也被更新:
@CachePut(value = "books", key = "#book.isbn")
public Book updateBook(Book book) {
// 这里是更新数据库的操作
return book; // 更新后的书籍信息
}
在这个例子中,每当 updateBook 方法被调用,不论缓存中是否存在相应的书籍信息,都会执行方法体,并将执行后的结果(即最新的书籍信息)存储到名为 books 的缓存中。
@CacheEvict
而 @CacheEvict 注解用于清除缓存。这在删除操作中特别有用,可以保证当数据不再存在时,缓存也同步移除,防止脏读。
来看看怎么用:
@CacheEvict(value = "books", key = "#isbn")
public void deleteBook(String isbn) {
// 这里是删除书籍的操作
}
这段代码表示,当调用 deleteBook 方法时,会自动从名为 books 的缓存中移除键为 isbn 的缓存数据。
高级应用
Spring的缓存注解不仅功能强大,而且非常灵活。例如,你可以使用 condition 属性来指定在什么条件下缓存数据,或者使用 unless 属性来指定不缓存的条件。
@Cacheable(value = "books", key = "#isbn", condition = "#isbn.length() > 10")
public Book findBook(String isbn) {
// 方法实现
}
这里 condition = "#isbn.length() > 10" 表示只有当 isbn 的长度大于10时,才会对结果进行缓存。
通过这些注解,咱们可以精细地控制缓存的行为,让缓存逻辑更加清晰,更易于维护。Spring的缓存抽象不仅使得缓存的实现变得简单,还使得缓存的维护和管理更加高效。通过灵活运用这些注解,可以大大提升应用的性能和用户体验。
第6章:集成外部缓存解决方案
虽然Spring提供了自己的缓存抽象,但有时候,咱们需要更强大的特性,比如分布式缓存。这时候,流行的缓存解决方案比如Redis和EhCache就派上用场了。
与Redis集成
Redis是一个开源的、内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。在Spring中使用Redis作为缓存非常普遍。下面是一个简单的例子,展示了如何在Spring Boot应用中配置Redis作为缓存。
首先,咱们需要在项目的pom.xml中添加Redis依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
然后,在应用的配置文件中,配置Redis服务器的连接信息:
spring:
redis:
host: localhost
port: 6379
最后,在Java代码中,咱们可以使用Spring的缓存注解,就像之前用内置缓存那样:
@Cacheable(value = "users", key = "#userId")
public User getUserById(String userId) {
// 这里是获取用户信息的逻辑
return new User(userId, "用户名");
}
这样一来,当调用 getUserById 方法时,Spring会自动使用Redis来缓存和检索数据。
与EhCache集成
EhCache是一个纯Java的进程内缓存框架,拥有快速、简单等特点。集成EhCache同样简单。首先,咱们需要在pom.xml中添加EhCache的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
</dependency>
接着,在Spring的配置文件中配置EhCache:
spring:
cache:
type: ehcache
ehcache:
config: classpath:ehcache.xml
ehcache.xml 是EhCache的配置文件,定义了各种缓存的名称、超时时间等信息。
在Java代码中,使用缓存的方式和之前类似:
@Cacheable(value = "books", key = "#isbn")
public Book findBookByIsbn(String isbn) {
// 这里是查询书籍的逻辑
return new Book(isbn, "书名", "作者");
}
通过这些步骤,咱们就可以在Spring应用中轻松集成Redis或EhCache,享受它们强大的缓存功能。这样的集成使得应用在处理大量数据和高并发请求时更加高效,同时也能更好地扩展和维护。
性能和一致性考虑
当咱们选择使用外部缓存解决方案时,性能和一致性是两个需要特别注意的方面。比如,使用Redis这种分布式缓存,虽然可以大幅提升性能,但也可能会引入网络延迟和数据一致性的问题。咱们得权衡这些因素,根据应用的具体需求来做出合适的选择。
比如,如果咱们的应用对数据的实时性要求非常高,可能就需要设置更短的缓存过期时间,或者在数据更新时立即清除相关缓存。这就需要咱们在使用缓存的时候,细心设计缓存策略和失效机制。
通过灵活运用Spring的缓存抽象和外部缓存解决方案,咱们可以构建出既高效又可靠的应用系统。不过,别忘了,任何技术都不是银弹,合理的设计和实现才是关键。
第7章:高级特性与最佳实践
条件缓存
在Spring缓存中,可以根据特定条件来决定是否使用缓存。这就像是,小黑在找书的时候,如果书很新,就直接看新书,不去翻旧书堆。用代码来说,就是这样的:
@Cacheable(value = "books", key = "#isbn", condition = "#isbn.length() > 10")
public Book findBook(String isbn) {
// 这里是查询书籍的逻辑
return new Book(isbn, "书名", "作者");
}
这段代码中的 condition = "#isbn.length() > 10" 表示只有当 isbn 的长度大于10时,才会把结果缓存起来。这种条件缓存可以帮助咱们更加灵活地控制缓存行为,避免不必要的缓存操作。
缓存预热
缓存预热是指在应用启动时就加载一些常用数据到缓存中。这样可以避免在应用刚启动时,由于缓存尚未填充而导致的性能问题。比如,小黑可以在系统启动时,就预先加载一些热门书籍的信息到缓存中:
@PostConstruct
public void initCache() {
popularIsbns.forEach(isbn -> findBook(isbn));
}
这里,@PostConstruct 注解的 initCache 方法在应用启动后会自动运行,进行缓存预热。
缓存性能优化
缓存虽好,但也要合理使用。过多或不当的缓存可能会导致内存溢出等问题。因此,小黑在使用缓存时需要注意以下几点:
- 合理设置缓存大小:根据应用的内存情况,合理设置缓存大小,避免消耗过多内存。
- 合理设置缓存过期时间:设置合适的过期时间,可以防止缓存中存储过时的数据,同时也能有效利用内存资源。
- 使用合适的缓存策略:根据应用的特点选择合适的缓存策略,如LRU、LFU等。
缓存的监控和维护
缓存的监控和维护也很重要。咱们需要定期检查缓存的命中率、响应时间等指标,确保缓存正常运行。如果发现性能问题,可能需要调整缓存策略或进行缓存优化。
通过这些高级特性和最佳实践,咱们可以更好地利用Spring缓存,提升应用的性能和稳定性。当然,每个应用的情况都不相同,所以在实际操作中,小黑得根据自己应用的特点和需求来灵活应用这些知识。
比如说,在处理非常大的数据集时,可能需要特别注意缓存的内存使用情况,避免因为缓存太多数据而导致内存溢出。或者在某些高并发场景下,可能需要优化缓存的同步机制,防止多个线程同时操作缓存造成的性能瓶颈。
咱们可以使用Spring Boot Actuator等工具来监控缓存的性能,比如检查缓存的命中率、查看当前缓存的大小等。这些工具能够帮助小黑更加直观地了解缓存的状态,及时做出调整。
合理地使用缓存可以为应用带来显著的性能提升,但同时也需要注意不要滥用缓存。
第8章:总结
- 缓存基础:理解了缓存的工作原理和类型,以及常用的缓存策略。
- Spring框架的缓存抽象:了解了Spring提供的缓存抽象,包括核心接口和类,以及如何通过注解来使用缓存。
- 缓存注解详解:深入学习了
@Cacheable、@CachePut和@CacheEvict等注解的使用方法。 - 集成外部缓存解决方案:探讨了如何在Spring中集成像Redis和EhCache这样的外部缓存系统。
- 高级特性与最佳实践:讨论了条件缓存、缓存预热、性能优化和监控等高级主题。
缓存作为提升应用性能的重要手段之一,其在Spring框架中的应用和发展是一个持续进步的过程。对于咱们来说,不断学习和实践,跟上技术的发展步伐,是提升技术实力的不二法门。希望这篇博客能给咱们在Spring缓存领域的学习和工作带来帮助,也期待看到缓存技术未来的发展和创新。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何让工业机器视觉呈现更清晰的图像?
- TP6+uni书写,校园圈子论坛程序,二开无忧,源码交付,支持APP小程序H5
- Java stream 进阶版
- 【实用干货】通过PMP认证考试的心得分享
- [Angular] 笔记 23:Renderer2 - ElementRef 的生产版本
- Opencv实验合集——实验四:图片融合
- [Beego]1.Beego简介以及beego环境搭建,bee脚手架的使用,创建,运行项目
- Linux——LAMP平台部署及应用
- JavaScript 数据结构和算法复习总结
- RK3568驱动指南|第九篇 设备模型-第109章 probe函数执行流程分析实验