Kafka为什么能高效读写数据
发布时间:2023年12月19日
1)Kafka 本身是分布式集群,可以采用分区技术,并行度高(生产消费方并行度高);
2)读数据采用稀疏索引,可以快速定位要消费的数据;
3)顺序写磁盘;
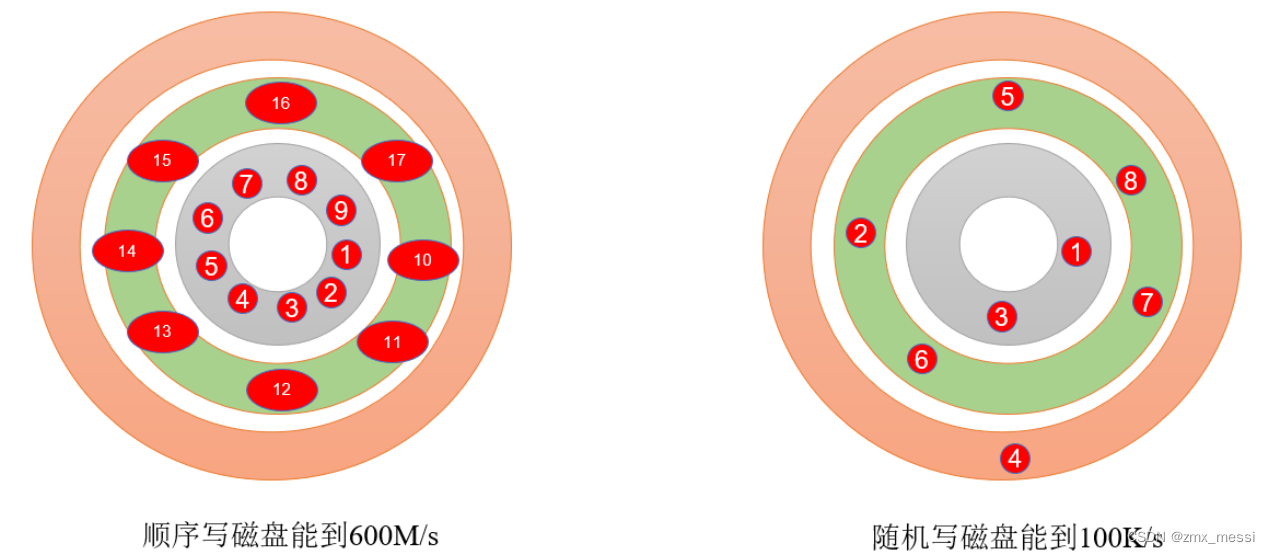
????????Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端, 为顺序写。官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
? ? ? ?又有如下两个优势:?
????????零拷贝:Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用 走应用层,传输效率高。
????????PageCache页缓存:Kafka重度依赖底层操作系统提供的PageCache功 能。当上层有写操作时,操作系统只是将数据写入 PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际上PageCache是把尽可能多的空闲内存 都当做了磁盘缓存来使用。
文章来源:https://blog.csdn.net/zmx_messi/article/details/135094049
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 可狱可囚的爬虫系列课程 12:在网站中寻找 API 接口(补充)(王者荣耀英雄信息抓取)
- Netty 简介
- CogAgent:带 Agent 能力的视觉模型来了
- 面试算法98:路径的数目
- 【C++进阶】心心念念的红黑树,它来了!
- VS报错:error:LNK2005 _main 已经在 *.obj 中定义
- 说说对React refs 的理解?应用场景?
- (2)释放 TypeScript 的力量:改进标准库类型
- 商品销售数据采集分析可视化系统 京东商品数据爬取+可视化 大数据 python计算机毕业设计(附源码)?
- 速看!盘点这一年 OpenTiny 都在做什么?