Flink实时电商数仓(一)
发布时间:2023年12月18日
离线数据仓库
为数据分析而设计的企业级数据管理系统。常用的存储系统是Hadoop的HDFS文件系统,使用Hive进行数据计算,并将结果导入HDFS。离线数仓最明显的特点是T+1模式,今天只能算昨天的数据,时效性不够优秀。
实时数仓
- 时效性:针对数仓大屏展示这个领域,10~15s刷新一次即可。
- 核心架构
- 日志服务器:采集日志文件
- Kafka集群:消息缓存
- HDFS存储:即hadoop集群
- Hive分层数仓:ODS+DIM+DWD+DWS+ADS
- Mysql数据库:用于大屏展示的数据
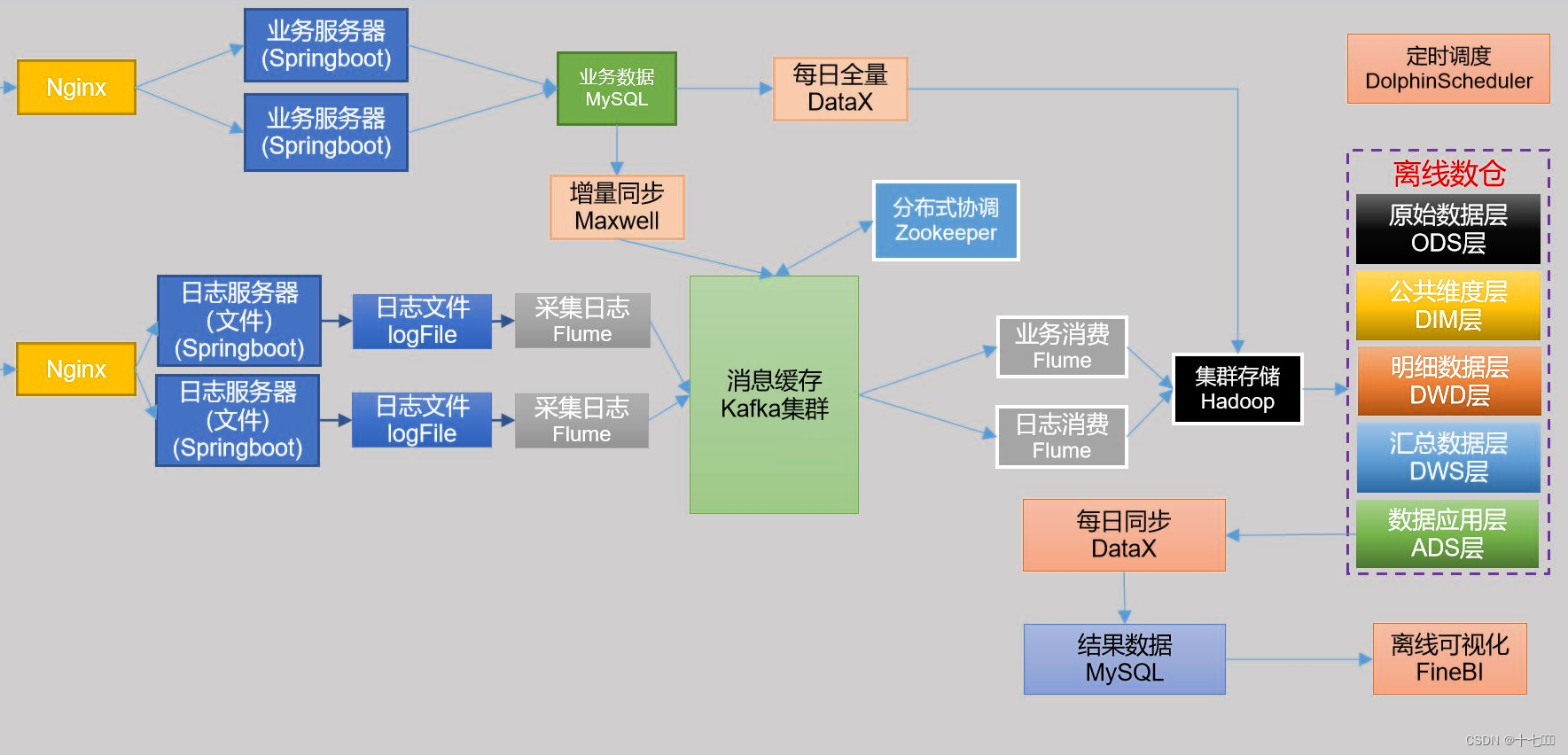
- 离线架构分析
- Maxwell 监控业务增量数据,是实时的
- Flume使用Tail dir Source实时监控日志文件
- Kafka集群收集数据,缓存消峰,事件流平台
- 其中只有Hadoop的HDFS文件系统比较慢,不是实时的
- 实时数仓架构
- ods层:不做处理
- dwd层:事务表,筛选后写回Kafka集群。(保持流状态)
- dim层:HBase+Redis层存储
- dws层:查询宽表,Doris架构
- ads层:SpringBoot数据接口服务
- 可视化:拉取接口数据,大屏展示
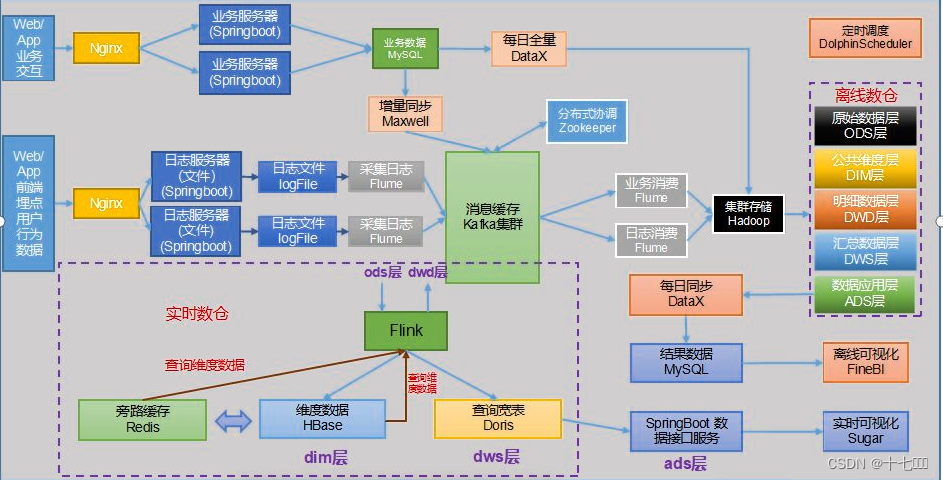
Doris框架
百度大数据研发,之前叫百度Palo。速度快并且支持10PB以上的超大数据集,唯一的缺点就是贵。对于生产环境机器的要求比较高,16核,64G内存,要固态内存,万兆网卡。
- 使用场景:各种数据源经过简单处理后直接导入Doris中即可。
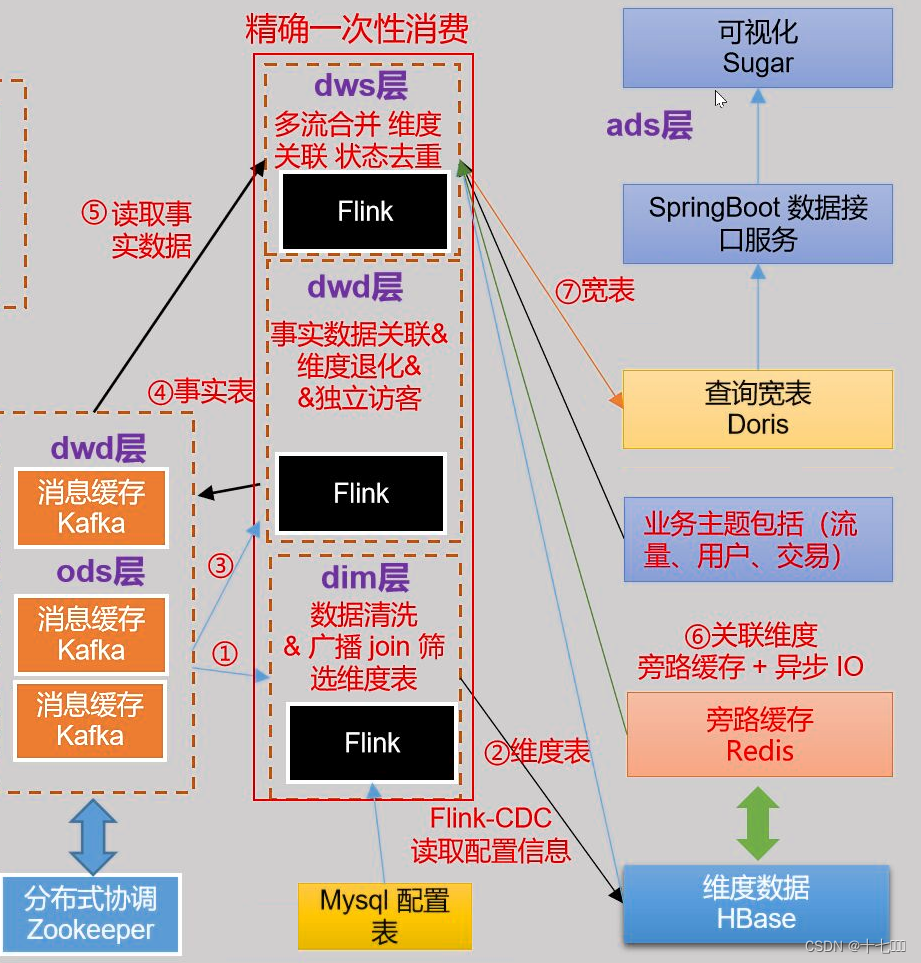
技术选型
- ods层:kafka对应的主题,topic_db, topic_log
- dwd层:保持数据流的形式,进行下一步的聚合。存储到kafka,主题名称对应不同的事实表。
- dim层:存储维度表,便于数据聚合后进行维度关联join。因此需要存储到数据库中。
- 备选框架:
- mysql: 快,不适合海量数据的存储
- redis: 更快,数据不是永久化存储的
- hbase: 速度一般,数据键值对存储,适合通过key进行查询,支持海量数据存储
- doris: 快,适合海量数据,使用成本较高,尽量不要让原始数据存储到doris
- clickHouse: 列式存储,列式数据聚合操作,速度非常快。
- 选型
- redis: 数据对丢,×
- clickHouse: dim层不需要聚合 ×
- doris: dim层数据是未经处理的原始数据,成本太高 ×
- mysql: 后续数据量增大后不适用 ×
- Hbase + redis : redis进行旁路缓存,提升Hbase速度 √
- dws层:读取dwd数据进行聚合,开窗聚合(10s), 再进行维度关联,后续进行灵活的数据接口编写,同时能够实现即席查询的功能。这里选择Doris存储,(之前是存储到clcikHouse)
- ads层:Spring boot编写接口,查询doris的接口。
- 备选框架:
实时数仓雪花模型
dim层维度表数仓建模主要有两种模型,星型模式和雪花模型。生产环境中,实时数仓只需要保存一份最新的维度数据,如果涉及到历史数据,在离线数仓中计算即可。在实时数仓开始时,需要从离线数仓中同步一份完整的维度数据。
文章来源:https://blog.csdn.net/qq_44273739/article/details/135041466
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【开题报告】基于SSM的传统节日宣传网站的设计与实现
- 基于SpringBoot的养老院管理系统
- 【资源】stable diffusion常用checkpoint
- 这个门禁监控技术,好用好用极了!!
- CMake入门指南:从基础到实战,掌握项目构建利器【导航目录汇总】
- http缓存协议详细介绍
- 物料采购合同管理系统(JSP+java+springmvc+mysql+MyBatis)
- JAVA版的鸿鹄云商B2B2C:多商家入驻直播商城系统特性解析 商城免 费搭建
- Airflow大揭秘:如何让大数据任务调度变得简单高效?
- vue学习中,一些vscode插件配置