从零开始复现BERT,并进行预训练和微调
从零开始复现BERT
代码地址:https://gitee.com/guojialiang2023/bert
模型
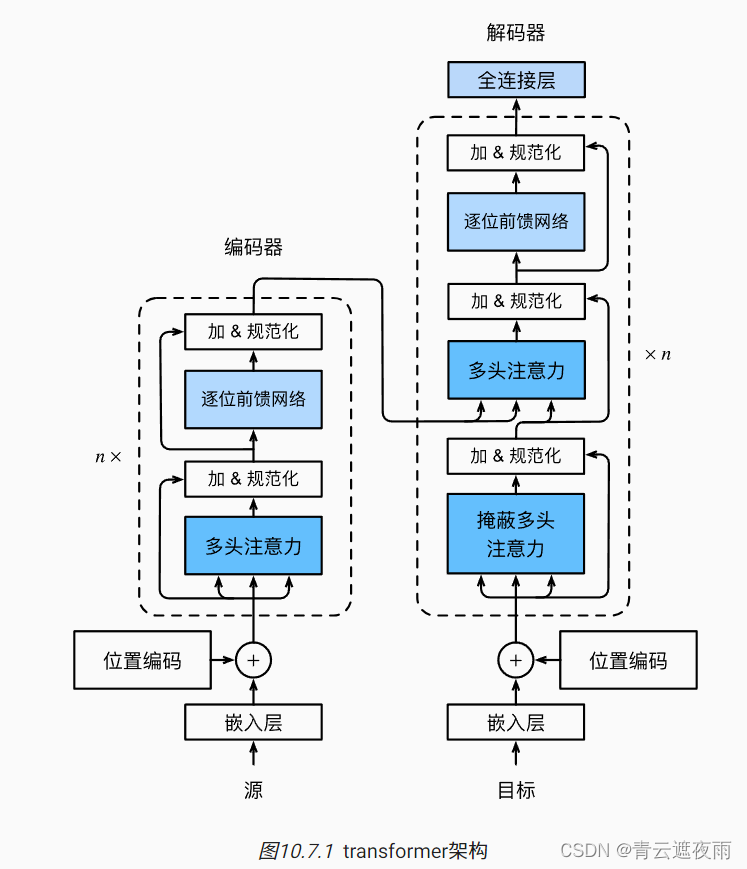
BERT 是一种基于 Transformer 架构的大型预训练模型,它通过学习大量文本数据来理解语言的深层次结构和含义,从而在各种 NLP 任务中实现卓越的性能。
核心的 BERTModel 类集成了模型的主体架构。它首先利用 BERTEncoder 编码器来处理输入的文本。这个编码器由多个 Transformer 编码块构成,每个编码块内包含多头注意力机制和前馈神经网络。这种结构能够有效地捕捉文本中不同词汇间的复杂关联,使模型能够理解上下文中的语义信息。模型还包括了两个关键任务:掩蔽语言模型(MaskLM)和下一句预测(NextSentencePred)。MaskLM 任务通过随机掩蔽输入文本中的某些单词,训练模型去预测这些被掩蔽的单词,从而学习语言的内部结构。下一句预测任务则是让模型判断两个句子是否是连续的,这有助于模型理解句子间的关系。
在 BERTEncoder 类中,包含了一个词嵌入层、一个段落嵌入层以及位置嵌入,这些嵌入层共同为模型提供了关于单词、其在句子中的位置以及句子所属段落的信息。随后,这些嵌入信息被送入一系列的 Transformer 编码块中,每个编码块都包含了多头注意力机制和位置级前馈网络。通过这样的结构设计,BERT 能够综合考虑文本中每个词汇的上下文信息,生成富有表现力的特征表示。
除了核心的编码器和任务模块,代码中还实现了一些辅助功能,如 AddNorm 类用于实现加法归一化,它在每个注意力和前馈网络操作后应用,以稳定训练过程;PositionWiseFFN 类实现了位置级前馈网络,用于增强模型对局部结构的理解;MaskLM 类和 NextSentencePred 类则分别用于实现掩蔽语言模型和下一句预测任务。
import torch
from torch import nn
from attention import *
from d2l import torch as d2l
#@save
class BERTModel(nn.Module):
"""
BERT模型
- vocab_size: 词汇表大小,确定了词嵌入的维度。
- num_hiddens: 隐藏层的维数。
- norm_shape: 归一化层的形状。
- ffn_num_input: 前馈网络的输入维度。
- ffn_num_hiddens: 前馈网络隐藏层的维度。
- num_heads: 注意力机制的头数。
- num_layers: 编码器中的层数。
- dropout: 用于层间的dropout比例。
- max_len: 序列的最大长度,默认为1000。
- key_size: 键向量的大小,默认为768。
- query_size: 查询向量的大小,默认为768。
- value_size: 值向量的大小,默认为768。
- hid_in_features: 用于下一句预测的多层感知机分类器的隐藏层的维数。
- mlm_in_features: 掩蔽语言模型的隐藏层维数。
- nsp_in_features: 下一句预测模型的隐藏层维数。
- **kwargs: 其他关键字参数,主要用于nn.Module的初始化。
"""
def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
hid_in_features=768, mlm_in_features=768,
nsp_in_features=768):
super(BERTModel, self).__init__()
self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, num_layers,
dropout, max_len=max_len, key_size=key_size,
query_size=query_size, value_size=value_size)
self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),
nn.Tanh())
self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)
self.nsp = NextSentencePred(nsp_in_features)
def forward(self, tokens, segments, valid_lens=None,
pred_positions=None):
encoded_X = self.encoder(tokens, segments, valid_lens)
if pred_positions is not None:
mlm_Y_hat = self.mlm(encoded_X, pred_positions)
else:
mlm_Y_hat = None
# 用于下一句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引
nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))
return encoded_X, mlm_Y_hat, nsp_Y_hat
class BERTEncoder(nn.Module):
"""
BERT编码器:
- vocab_size: 词汇表大小,确定了词嵌入的维度。
- num_hiddens: 隐藏层的维数。
- norm_shape: 归一化层的形状。
- ffn_num_input: 前馈网络的输入维度。
- ffn_num_hiddens: 前馈网络隐藏层的维度。
- num_heads: 注意力机制的头数。
- num_layers: 编码器中的层数。
- dropout: 用于层间的dropout比例。
- max_len: 序列的最大长度,默认为1000。
- key_size: 键向量的大小,默认为768。
- query_size: 查询向量的大小,默认为768。
- value_size: 值向量的大小,默认为768。
- **kwargs: 其他关键字参数,主要用于nn.Module的初始化。
"""
def __init__(self,vocab_size, num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, num_layers, dropout,
max_len=1000, key_size=768, query_size=768, value_size=768,
**kwargs):
super(BERTEncoder, self).__init__(**kwargs)
self.token_embedding = nn.Embedding(vocab_size, num_hiddens)
self.segment_embedding = nn.Embedding(2, num_hiddens)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(f"{i}", EncoderBlock(
key_size, query_size, value_size, num_hiddens, norm_shape,
ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))
# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数
self.pos_embedding = nn.Parameter(torch.randn(1, max_len,
num_hiddens))
def forward(self, tokens, segments, valid_lens):
# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)
X = self.token_embedding(tokens) + self.segment_embedding(segments)
X = X + self.pos_embedding.data[:, :X.shape[1], :]
for blk in self.blks:
X = blk(X, valid_lens)
return X
class EncoderBlock(nn.Module):
"""
Transformer编码器:
- key_size: 键向量的大小,默认为768。
- query_size: 查询向量的大小,默认为768。
- value_size: 值向量的大小,默认为768。
- num_hiddens: 隐藏层的维数。
- norm_shape: 归一化层的形状。
- ffn_num_input: 前馈网络的输入维度。
- ffn_num_hiddens: 前馈网络隐藏层的维度。
- num_heads: 注意力机制的头数。
- dropout: 用于层间的dropout比例。
- **kwargs: 其他关键字参数,主要用于nn.Module的初始化。
"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout,
use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(
ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
class AddNorm(nn.Module):
"""
带有层规范化的残差连接
- normalized_shape: 归一化层的形状。
- dropout: 用于层间的dropout比例。
- **kwargs: 其他关键字参数,主要用于nn.Module的初始化。
"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
class PositionWiseFFN(nn.Module):
"""
逐位前馈网络
- ffn_num_input: 前馈网络的输入维度。
- ffn_num_hiddens: 前馈网络隐藏层的维度。
- ffn_num_outputs: 前馈网络输出维度。
- **kwargs: 其他关键字参数,主要用于nn.Module的初始化。
"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
class MaskLM(nn.Module):
"""BERT的掩蔽语言模型任务"""
def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs):
super(MaskLM, self).__init__(**kwargs)
self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),
nn.ReLU(),
nn.LayerNorm(num_hiddens),
nn.Linear(num_hiddens, vocab_size))
def forward(self, X, pred_positions):
num_pred_positions = pred_positions.shape[1]
pred_positions = pred_positions.reshape(-1)
batch_size = X.shape[0]
batch_idx = torch.arange(0, batch_size)
# 假设batch_size=2,num_pred_positions=3
# 那么batch_idx是np.array([0,0,0,1,1,1])
batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)
masked_X = X[batch_idx, pred_positions]
masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))
mlm_Y_hat = self.mlp(masked_X)
return mlm_Y_hat
class NextSentencePred(nn.Module):
"""BERT的下一句预测任务"""
def __init__(self, num_inputs, **kwargs):
super(NextSentencePred, self).__init__(**kwargs)
self.output = nn.Linear(num_inputs, 2)
def forward(self, X):
# X的形状:(batchsize,num_hiddens)
return self.output(X)
注意力机制的实现
多头注意力机制(MultiHeadAttention)是Transformer模型的关键组件,广泛应用于自然语言处理(NLP)领域。多头注意力机制通过并行处理信息来捕捉不同子空间中的特征,从而增强模型对文本的理解能力。
在MultiHeadAttention类中,主要工作是将输入的查询(queries)、键(keys)和值(values)通过三个独立的线性层进行转换,以生成对应的查询、键和值表示。这个过程是为了使模型能够并行处理不同的表示子空间。转换后,使用transpose_qkv函数对这些张量进行重塑和转置,以适应多头处理的格式。这种设计使得模型能够在不同的表示子空间中学习信息,提高了注意力机制的表达能力。
该类的核心是内部的DotProductAttention类,实现了点积注意力机制。这个过程涉及计算查询和键的点积,然后通过缩放因子(通常是查询维度的平方根)进行缩放,以稳定训练过程。如果提供了有效长度(valid_lens),则在计算注意力分数之前,会用它们来掩盖(mask)序列中无效或不相关的元素,这是为了防止模型从填充的部分学习无用信息。有效长度的掩盖通过masked_softmax函数实现,它在执行softmax操作之前,在最后一个轴上掩盖掉了被标记为无效的元素。
多头注意力机制的一个重要特性是它允许模型在不同的表示子空间中并行捕捉信息。在forward方法中,通过调用attention实例计算得到的注意力分数与值(values)相乘,得到加权和输出。这些输出随后被重新组合(通过transpose_output函数),形成最终的多头注意力输出。
此外,代码中包含了一些辅助函数,如sequence_mask和transpose_qkv。sequence_mask用于在序列处理中应用掩码,而transpose_qkv和transpose_output则分别用于在多头注意力计算前后对数据进行适当的转置和重塑。
import math
from torch import nn
import torch
class MultiHeadAttention(nn.Module):
"""多头注意力机制
- key_size: 键向量的大小,默认为768。
- query_size: 查询向量的大小,默认为768。
- value_size: 值向量的大小,默认为768。
- num_hiddens: 隐藏层的维数。
- num_heads: 注意力机制的头数。
- dropout: 用于层间的dropout比例。
- **kwargs: 其他关键字参数,主要用于nn.Module的初始化。
"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# Shape of `queries`, `keys`, or `values`:
# (`batch_size`, no. of queries or key-value pairs, `num_hiddens`)
# Shape of `valid_lens`:
# (`batch_size`,) or (`batch_size`, no. of queries)
# After transposing, shape of output `queries`, `keys`, or `values`:
# (`batch_size` * `num_heads`, no. of queries or key-value pairs,
# `num_hiddens` / `num_heads`)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# On axis 0, copy the first item (scalar or vector) for
# `num_heads` times, then copy the next item, and so on
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# Shape of `output`: (`batch_size` * `num_heads`, no. of queries,`num_hiddens` / `num_heads`)
output = self.attention(queries, keys, values, valid_lens)
# Shape of `output_concat`:
# (`batch_size`, no. of queries, `num_hiddens`)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
class DotProductAttention(nn.Module):
"""点积注意力
- dropout: 用于层间的dropout比例。
- **kwargs: 其他关键字参数,主要用于nn.Module的初始化。
"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# Shape of `queries`: (`batch_size`, no. of queries, `d`)
# Shape of `keys`: (`batch_size`, no. of key-value pairs, `d`)
# Shape of `values`: (`batch_size`, no. of key-value pairs, value dimension)
# Shape of `valid_lens`: (`batch_size`,) or (`batch_size`, no. of queries)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
def masked_softmax(X, valid_lens):
"""
通过在最后一个轴上掩盖元素来执行softmax操作。
"""
# `X`: 3维张量, `valid_lens`: 1维或2维张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
# 如果valid_lens是1维的,则将其重复扩展以匹配X的形状
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
# 如果valid_lens是2维的,则将其重塑为1维
valid_lens = valid_lens.reshape(-1)
# 在最后一个轴上,用一个非常大的负数替换被掩盖的元素,
# 这个大的负数的指数结果为0
X = sequence_mask(X.reshape(-1, shape[-1]), valid_lens, value=-1e6)
# 将X重塑回原来的形状,并执行softmax操作
return nn.functional.softmax(X.reshape(shape), dim=-1)
def sequence_mask(X, valid_len, value=0):
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
def transpose_qkv(X, num_heads):
"""
为多个注意力头的并行计算进行转置操作。
"""
# 输入 `X` 的形状:
# (`batch_size`, 查询或键值对的数量, `num_hiddens`)。
# 输出 `X` 的形状:
# (`batch_size`, 查询或键值对的数量, `num_heads`,`num_hiddens` / `num_heads`)
# 重新塑形X以分割隐藏维度到多个头
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出 `X` 的形状:
# (`batch_size`, `num_heads`, 查询或键值对的数量,
# `num_hiddens` / `num_heads`)
# 使用permute对X进行转置以便将头维度移到前面
X = X.permute(0, 2, 1, 3)
# `output` 的形状:
# (`batch_size` * `num_heads`, 查询或键值对的数量, `num_hiddens` / `num_heads`)
# 重塑输出以合并批次和头维度,为点积注意力做准备
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X, num_heads):
"""
Reverse the operation of `transpose_qkv`.
"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
预训练
代码展示了使用BERT模型进行预训练的完整流程,主要包括数据加载、模型构建、损失函数定义和训练循环。首先,通过load_data_wiki函数从维基百科数据集加载训练数据,该函数返回了一个用于训练的迭代器train_iter和词汇表vocab。数据集中的文本经过预处理,限制为最大长度max_len,并批量化为batch_size。
模型构建部分初始化了一个BERT模型实例net。在这里,模型的各种参数,如隐藏层维度num_hiddens、前馈网络的输入和隐藏层维度、注意力头数num_heads、编码器层数num_layers等都被指定。这些参数定义了模型的结构和容量,影响着模型的学习能力和效果。
接下来定义了损失函数loss,这里使用交叉熵损失函数,它是处理分类问题常用的损失函数。然后定义了_get_batch_loss_bert函数,该函数在给定一批数据时计算BERT模型的损失。这个函数首先执行模型的前向传播,然后分别计算掩蔽语言模型(MLM)和下一句预测(NSP)任务的损失。MLM任务预测被掩蔽的词,而NSP任务判断两个句子是否连续。
最后是训练循环train_bert,它采用了数据并行方法,允许在多个GPU上进行训练。在每一步训练中,首先将数据移动到指定的设备(如GPU),然后执行前向和后向传播,计算损失并更新模型的权重。在训练过程中,使用d2l.Animator绘制了MLM和NSP损失的动态图,以便实时观察训练过程。训练完成后,输出MLM和NSP的平均损失,以及设备上每秒可以处理的句子对数量。
from utils import *
from model import *
batch_size, max_len = 512, 64
train_iter, vocab = load_data_wiki(batch_size, max_len)
net = BERTModel(len(vocab), num_hiddens=128, norm_shape=[128],
ffn_num_input=128, ffn_num_hiddens=256, num_heads=2,
num_layers=2, dropout=0.2, key_size=128, query_size=128,
value_size=128, hid_in_features=128, mlm_in_features=128,
nsp_in_features=128)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss()
def _get_batch_loss_bert(net, loss, vocab_size, tokens_X,
segments_X, valid_lens_x,
pred_positions_X, mlm_weights_X,
mlm_Y, nsp_y):
# 前向传播
_, mlm_Y_hat, nsp_Y_hat = net(tokens_X, segments_X,
valid_lens_x.reshape(-1),
pred_positions_X)
# 计算遮蔽语言模型损失
mlm_l = loss(mlm_Y_hat.reshape(-1, vocab_size), mlm_Y.reshape(-1)) *\
mlm_weights_X.reshape(-1, 1)
mlm_l = mlm_l.sum() / (mlm_weights_X.sum() + 1e-8)
# 计算下一句子预测任务的损失
nsp_l = loss(nsp_Y_hat, nsp_y)
l = mlm_l + nsp_l
return mlm_l, nsp_l, l
def train_bert(train_iter, net, loss, vocab_size, devices, num_steps):
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
trainer = torch.optim.Adam(net.parameters(), lr=0.01)
step, timer = 0, d2l.Timer()
animator = d2l.Animator(xlabel='step', ylabel='loss',
xlim=[1, num_steps], legend=['mlm', 'nsp'])
# 遮蔽语言模型损失的和,下一句预测任务损失的和,句子对的数量,计数
metric = d2l.Accumulator(4)
num_steps_reached = False
while step < num_steps and not num_steps_reached:
for tokens_X, segments_X, valid_lens_x, pred_positions_X,mlm_weights_X, mlm_Y, nsp_y in train_iter:
tokens_X = tokens_X.to(devices[0])
segments_X = segments_X.to(devices[0])
valid_lens_x = valid_lens_x.to(devices[0])
pred_positions_X = pred_positions_X.to(devices[0])
mlm_weights_X = mlm_weights_X.to(devices[0])
mlm_Y, nsp_y = mlm_Y.to(devices[0]), nsp_y.to(devices[0])
trainer.zero_grad()
timer.start()
mlm_l, nsp_l, l = _get_batch_loss_bert(
net, loss, vocab_size, tokens_X, segments_X, valid_lens_x,
pred_positions_X, mlm_weights_X, mlm_Y, nsp_y)
l.backward()
trainer.step()
metric.add(mlm_l, nsp_l, tokens_X.shape[0], 1)
timer.stop()
animator.add(step + 1,
(metric[0] / metric[3], metric[1] / metric[3]))
step += 1
if step == num_steps:
num_steps_reached = True
break
print(f'MLM loss {metric[0] / metric[3]:.3f}, '
f'NSP loss {metric[1] / metric[3]:.3f}')
print(f'{metric[2] / timer.sum():.1f} sentence pairs/sec on '
f'{str(devices)}')
train_bert(train_iter, net, loss, len(vocab), devices, 50)
微调
代码展示了如何使用预训练的BERT模型(bert.small)来构建一个文本分类器,并在自然语言推断(NLI)任务上进行微调和评估。首先,代码中加载了一个预训练的小型BERT模型,并为其指定了网络参数,如隐藏层维度、前馈网络维度、注意力头数、层数和最大序列长度。接着,使用SNLIBERTDataset类加载了斯坦福自然语言推断(SNLI)数据集,该数据集包含了一对句子以及它们之间的逻辑关系(蕴含、矛盾或中立)。
在模型构建方面,定义了BERTClassifier类,它继承自nn.Module。这个分类器使用BERT模型的编码器(bert.encoder)作为句子的特征提取器,并添加了一个全连接层(nn.Linear)来预测三种逻辑关系中的一种。在模型的前向传播方法中,首先通过BERT编码器处理输入,然后将编码器的输出传递给全连接层以得到最终的分类结果。
训练过程在train函数中实现。在这个函数中,首先将模型部署到可用的GPU上(如果有的话),然后在每个epoch中遍历训练数据,使用交叉熵损失函数计算损失,并通过反向传播更新模型参数。训练过程中,使用d2l.Animator可视化了训练损失、训练准确率和测试准确率。每个epoch结束时,还在测试集上评估模型的准确率。
train_batch函数负责处理单个批次的数据,包括数据的传输到GPU、模型的前向和后向传播以及优化器的更新步骤。这个函数返回了批次的损失和准确率。
最后,定义了学习率、训练的epoch数、优化器和损失函数,然后开始了训练过程。这个过程通过微调预训练的BERT模型,使其能够更好地适应NLI任务。经过训练,模型在SNLI数据集上达到了较高的准确率,显示出了BERT在自然语言理解任务上的强大性能。
from model import *
from utils import *
from d2l import torch as d2l
devices = d2l.try_all_gpus()
bert, vocab = load_pretrained_model(
'bert.small', num_hiddens=256, ffn_num_hiddens=512, num_heads=4,
num_layers=2, dropout=0.1, max_len=512, devices=devices)
# 如果出现显存不足错误,请减少“batch_size”。在原始的BERT模型中,max_len=512
batch_size, max_len, num_workers = 512, 128, d2l.get_dataloader_workers()
data_dir = d2l.download_extract('SNLI')
train_set = SNLIBERTDataset(d2l.read_snli(data_dir, True), max_len, vocab)
test_set = SNLIBERTDataset(d2l.read_snli(data_dir, False), max_len, vocab)
train_iter = torch.utils.data.DataLoader(train_set, batch_size, shuffle=True,
num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(test_set, batch_size,
num_workers=num_workers)
class BERTClassifier(nn.Module):
def __init__(self, bert):
super(BERTClassifier, self).__init__()
self.encoder = bert.encoder
self.hidden = bert.hidden
self.output = nn.Linear(256, 3)
def forward(self, inputs):
tokens_X, segments_X, valid_lens_x = inputs
encoded_X = self.encoder(tokens_X, segments_X, valid_lens_x)
return self.output(self.hidden(encoded_X[:, 0, :]))
def train(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples,
# no. of predictions
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch(
net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')
def train_batch(net, X, y, loss, trainer, devices):
if isinstance(X, list):
# Required for BERT fine-tuning (to be covered later)
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
net = BERTClassifier(bert)
lr, num_epochs = 1e-4, 5
trainer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss(reduction='none')
train(net, train_iter, test_iter, loss, trainer, num_epochs,devices)
工具函数
这段代码是使用BERT模型进行预训练和微调的一个完整示例,主要包括预训练数据的处理、模型的加载和微调。首先,代码从WikiText-2数据集中读取文本数据,用于BERT模型的预训练。文本数据被分割成句子,并进行了随机化处理。预训练数据包括两部分:下一句预测(NSP)和遮蔽语言模型(MLM)。NSP任务是判断两个句子是否连续,而MLM任务则是预测文本中被遮蔽的单词。
在数据预处理阶段,对于每个段落,随机选择句子并执行一系列操作,包括判断是否为连续句子(NSP任务)以及选择一些词汇进行遮蔽(MLM任务)。对于MLM,随机替换一部分单词为特殊标记<mask>或其他随机单词。所有的输入序列都被填充到相同的长度,并将它们转换为模型可接受的格式。
在模型加载部分,代码首先下载并加载预训练的BERT模型。这里使用了较小的bert.small模型,具有指定的隐藏层大小、前馈网络大小、注意力头数等参数。加载的模型将用于微调阶段。
微调部分使用了斯坦福自然语言推理(SNLI)数据集,该数据集包含一对句子及其关系标签(蕴含、矛盾或中立)。在这一阶段,BERT模型被应用于自然语言推理任务。数据集被预处理为BERT的输入格式,包括截断过长的句子对,并将它们转换为词元ID、片段索引和有效长度。
import json
import multiprocessing
import os
import random
import torch
from d2l import torch as d2l
from model import BERTModel
def get_tokens_and_segments(tokens_a, tokens_b=None):
"""获取输入序列的词元及其片段索引"""
tokens = ['<cls>'] + tokens_a + ['<sep>']
# 0和1分别标记片段A和B
segments = [0] * (len(tokens_a) + 2)
if tokens_b is not None:
tokens += tokens_b + ['<sep>']
segments += [1] * (len(tokens_b) + 1)
return tokens, segments
# 预训练部分
d2l.DATA_HUB['wikitext-2'] = (
'https://s3.amazonaws.com/research.metamind.io/wikitext/'
'wikitext-2-v1.zip', '3c914d17d80b1459be871a5039ac23e752a53cbe')
def _read_wiki(data_dir):
file_name = os.path.join(data_dir, 'wiki.train.tokens')
with open(file_name, 'r') as f:
lines = f.readlines()
# 大写字母转换为小写字母
paragraphs = [line.strip().lower().split(' . ')
for line in lines if len(line.split(' . ')) >= 2]
random.shuffle(paragraphs)
return paragraphs
# 生成下一句预测任务的数据
def _get_next_sentence(sentence, next_sentence, paragraphs):
if random.random() < 0.5:
is_next = True
else:
# paragraphs是三重列表的嵌套
next_sentence = random.choice(random.choice(paragraphs))
is_next = False
return sentence, next_sentence, is_next
def _get_nsp_data_from_paragraph(paragraph, paragraphs, vocab, max_len):
nsp_data_from_paragraph = []
for i in range(len(paragraph) - 1):
tokens_a, tokens_b, is_next = _get_next_sentence(
paragraph[i], paragraph[i + 1], paragraphs)
# 考虑1个'<cls>'词元和2个'<sep>'词元
if len(tokens_a) + len(tokens_b) + 3 > max_len:
continue
tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b)
nsp_data_from_paragraph.append((tokens, segments, is_next))
return nsp_data_from_paragraph
# 生成遮蔽语言模型任务的数据
def _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds,
vocab):
# 为遮蔽语言模型的输入创建新的词元副本,其中输入可能包含替换的“<mask>”或随机词元
mlm_input_tokens = [token for token in tokens]
pred_positions_and_labels = []
# 打乱后用于在遮蔽语言模型任务中获取15%的随机词元进行预测
random.shuffle(candidate_pred_positions)
for mlm_pred_position in candidate_pred_positions:
if len(pred_positions_and_labels) >= num_mlm_preds:
break
masked_token = None
# 80%的时间:将词替换为“<mask>”词元
if random.random() < 0.8:
masked_token = '<mask>'
else:
# 10%的时间:保持词不变
if random.random() < 0.5:
masked_token = tokens[mlm_pred_position]
# 10%的时间:用随机词替换该词
else:
masked_token = random.choice(vocab.idx_to_token)
mlm_input_tokens[mlm_pred_position] = masked_token
pred_positions_and_labels.append(
(mlm_pred_position, tokens[mlm_pred_position]))
return mlm_input_tokens, pred_positions_and_labels
#@save
def _get_mlm_data_from_tokens(tokens, vocab):
candidate_pred_positions = []
# tokens是一个字符串列表
for i, token in enumerate(tokens):
# 在遮蔽语言模型任务中不会预测特殊词元
if token in ['<cls>', '<sep>']:
continue
candidate_pred_positions.append(i)
# 遮蔽语言模型任务中预测15%的随机词元
num_mlm_preds = max(1, round(len(tokens) * 0.15))
mlm_input_tokens, pred_positions_and_labels = _replace_mlm_tokens(
tokens, candidate_pred_positions, num_mlm_preds, vocab)
pred_positions_and_labels = sorted(pred_positions_and_labels,
key=lambda x: x[0])
pred_positions = [v[0] for v in pred_positions_and_labels]
mlm_pred_labels = [v[1] for v in pred_positions_and_labels]
return vocab[mlm_input_tokens], pred_positions, vocab[mlm_pred_labels]
# 将文本转换为预训练数据集
#@save
def _pad_bert_inputs(examples, max_len, vocab):
max_num_mlm_preds = round(max_len * 0.15)
all_token_ids, all_segments, valid_lens, = [], [], []
all_pred_positions, all_mlm_weights, all_mlm_labels = [], [], []
nsp_labels = []
for (token_ids, pred_positions, mlm_pred_label_ids, segments,
is_next) in examples:
all_token_ids.append(torch.tensor(token_ids + [vocab['<pad>']] * (
max_len - len(token_ids)), dtype=torch.long))
all_segments.append(torch.tensor(segments + [0] * (
max_len - len(segments)), dtype=torch.long))
# valid_lens不包括'<pad>'的计数
valid_lens.append(torch.tensor(len(token_ids), dtype=torch.float32))
all_pred_positions.append(torch.tensor(pred_positions + [0] * (
max_num_mlm_preds - len(pred_positions)), dtype=torch.long))
# 填充词元的预测将通过乘以0权重在损失中过滤掉
all_mlm_weights.append(
torch.tensor([1.0] * len(mlm_pred_label_ids) + [0.0] * (
max_num_mlm_preds - len(pred_positions)),
dtype=torch.float32))
all_mlm_labels.append(torch.tensor(mlm_pred_label_ids + [0] * (
max_num_mlm_preds - len(mlm_pred_label_ids)), dtype=torch.long))
nsp_labels.append(torch.tensor(is_next, dtype=torch.long))
return (all_token_ids, all_segments, valid_lens, all_pred_positions,
all_mlm_weights, all_mlm_labels, nsp_labels)
# 数据集
class _WikiTextDataset(torch.utils.data.Dataset):
def __init__(self, paragraphs, max_len):
# 输入paragraphs[i]是代表段落的句子字符串列表;
# 而输出paragraphs[i]是代表段落的句子列表,其中每个句子都是词元列表
paragraphs = [d2l.tokenize(
paragraph, token='word') for paragraph in paragraphs]
sentences = [sentence for paragraph in paragraphs
for sentence in paragraph]
self.vocab = d2l.Vocab(sentences, min_freq=5, reserved_tokens=[
'<pad>', '<mask>', '<cls>', '<sep>'])
# 获取下一句子预测任务的数据
examples = []
for paragraph in paragraphs:
examples.extend(_get_nsp_data_from_paragraph(
paragraph, paragraphs, self.vocab, max_len))
# 获取遮蔽语言模型任务的数据
examples = [(_get_mlm_data_from_tokens(tokens, self.vocab)
+ (segments, is_next))
for tokens, segments, is_next in examples]
# 填充输入
(self.all_token_ids, self.all_segments, self.valid_lens,
self.all_pred_positions, self.all_mlm_weights,
self.all_mlm_labels, self.nsp_labels) = _pad_bert_inputs(
examples, max_len, self.vocab)
def __getitem__(self, idx):
return (self.all_token_ids[idx], self.all_segments[idx],
self.valid_lens[idx], self.all_pred_positions[idx],
self.all_mlm_weights[idx], self.all_mlm_labels[idx],
self.nsp_labels[idx])
def __len__(self):
return len(self.all_token_ids)
def load_data_wiki(batch_size, max_len):
"""加载WikiText-2数据集"""
num_workers = d2l.get_dataloader_workers()
data_dir = d2l.download_extract('wikitext-2', 'wikitext-2')
paragraphs = _read_wiki(data_dir)
train_set = _WikiTextDataset(paragraphs, max_len)
train_iter = torch.utils.data.DataLoader(train_set, batch_size,
shuffle=True, num_workers=num_workers)
return train_iter, train_set.vocab
# 微调部分
d2l.DATA_HUB['bert.base'] = (d2l.DATA_URL + 'bert.base.torch.zip',
'225d66f04cae318b841a13d32af3acc165f253ac')
d2l.DATA_HUB['bert.small'] = (d2l.DATA_URL + 'bert.small.torch.zip',
'c72329e68a732bef0452e4b96a1c341c8910f81f')
def load_pretrained_model(pretrained_model, num_hiddens, ffn_num_hiddens,
num_heads, num_layers, dropout, max_len, devices):
data_dir = d2l.download_extract(pretrained_model)
# 定义空词表以加载预定义词表
vocab = d2l.Vocab()
vocab.idx_to_token = json.load(open(os.path.join(data_dir,
'vocab.json')))
vocab.token_to_idx = {token: idx for idx, token in enumerate(
vocab.idx_to_token)}
bert = BERTModel(len(vocab), num_hiddens, norm_shape=[256],
ffn_num_input=256, ffn_num_hiddens=ffn_num_hiddens,
num_heads=4, num_layers=2, dropout=0.2,
max_len=max_len, key_size=256, query_size=256,
value_size=256, hid_in_features=256,
mlm_in_features=256, nsp_in_features=256)
# 加载预训练BERT参数
bert.load_state_dict(torch.load(os.path.join(data_dir,
'pretrained.params')))
return bert, vocab
class SNLIBERTDataset(torch.utils.data.Dataset):
def __init__(self, dataset, max_len, vocab=None):
all_premise_hypothesis_tokens = [[
p_tokens, h_tokens] for p_tokens, h_tokens in zip(
*[d2l.tokenize([s.lower() for s in sentences])
for sentences in dataset[:2]])]
self.labels = torch.tensor(dataset[2])
self.vocab = vocab
self.max_len = max_len
(self.all_token_ids, self.all_segments,
self.valid_lens) = self._preprocess(all_premise_hypothesis_tokens)
print('read ' + str(len(self.all_token_ids)) + ' examples')
def _preprocess(self, all_premise_hypothesis_tokens):
pool = multiprocessing.Pool(4) # 使用4个进程
out = pool.map(self._mp_worker, all_premise_hypothesis_tokens)
all_token_ids = [
token_ids for token_ids, segments, valid_len in out]
all_segments = [segments for token_ids, segments, valid_len in out]
valid_lens = [valid_len for token_ids, segments, valid_len in out]
return (torch.tensor(all_token_ids, dtype=torch.long),
torch.tensor(all_segments, dtype=torch.long),
torch.tensor(valid_lens))
def _mp_worker(self, premise_hypothesis_tokens):
p_tokens, h_tokens = premise_hypothesis_tokens
self._truncate_pair_of_tokens(p_tokens, h_tokens)
tokens, segments = d2l.get_tokens_and_segments(p_tokens, h_tokens)
token_ids = self.vocab[tokens] + [self.vocab['<pad>']] \
* (self.max_len - len(tokens))
segments = segments + [0] * (self.max_len - len(segments))
valid_len = len(tokens)
return token_ids, segments, valid_len
def _truncate_pair_of_tokens(self, p_tokens, h_tokens):
# 为BERT输入中的'<CLS>'、'<SEP>'和'<SEP>'词元保留位置
while len(p_tokens) + len(h_tokens) > self.max_len - 3:
if len(p_tokens) > len(h_tokens):
p_tokens.pop()
else:
h_tokens.pop()
def __getitem__(self, idx):
return (self.all_token_ids[idx], self.all_segments[idx],
self.valid_lens[idx]), self.labels[idx]
def __len__(self):
return len(self.all_token_ids)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《python算法与数据结构2000讲》链表双指针深度剖析
- LLM商业落地中的注意事项、关于高级提示词prompt的思考
- 数据结构与算法:堆
- Flutter 缩放动画组件封装与使用
- AcWing算法进阶课-1.1.1EK求最大流
- 跟着LearnOpenGL学习9--光照
- uniapp中uview组件库的NoticeBar 滚动通知 使用方法
- 【Ubuntu】sudo apt-get update无法解析域名
- 骑砍战团MOD开发(23)-呼延灼连环铁骑
- RK3568驱动指南|第十二篇 GPIO子系统-第131章 GPIO子系统API函数的引入