多芯算力交叉拉远,拓展AI算力边界
概念定义
多芯算力交叉拉远是指:通过高效的网络传输技术、算力池化和调度算法,将不同厂商、型号的算力设备资源调度到单一算力需求侧,以实现多样化的算力资源协同调度和灵活使用,提高整体算力利用效率和业务灵活性。
在当今数智化时代,人工智能(AI)的蓬勃发展使得GPU(图形处理器)成为实现高性能计算的核心。许多企业曾大量采购Nvidia的GPU以应对不断增长的AI计算需求,随着国产GPU技术的崛起,许多厂商也纷纷开始转向购买国产算力卡,缓解一卡难求的尴尬。
与此同时,在涉及多样化的AI业务和不同GPU设备的情境下,传统的资源调用方式可能面临灵活性不足、效率低下等问题。
1 问题与挑战
技术不是一蹴而就,AI应用的平台和系统往往也没有统一规划,是烟囱式的竖井结构,很多企业面临着算力资源孤岛的挑战,业务协同受限,而传统的调度方式在适应多变的业务需求上显得力不从心;随着大规模上线AI应用, 对异构算力资源的使用需求,显得愈加突出:
1) 业务与资源孤岛
企业内的业务往往与AI算力卡资源的类型相绑定,难以实现多业务间的算力资源共享与协同使用,从而形成AI算力孤岛,限制了AI业务的整体协同效能。
2) AI业务弹性受限
多厂商算力资源类型的统一纳管和混合部署,使AI算力在面对业务波动时,难以迅速适应业务的变化,从而导致业务资源难以扩容或缩容,出现资源供应不足或浪费。
3) 依赖多厂商多型号算力资源的AI应用困境
现代AI应用复杂性,可能同时对多种不同厂商的算力资源产生依赖。然而,由于不同厂商和型号GPU卡之间的技术路线不同,使用和调度这些异构资源变得异常复杂。
综合以上原因,结合AI算力国产化背景,需要一种能够解决资源孤岛问题、提高调度灵活性和弹性,降低系统复杂度,优化效率的新型技术。为此,多芯算力交叉拉远技术应运而生。
通过该技术,用户可以有效地实现多芯算力的灵活调度和共享,从而提高整体AI业务的运行效率和灵活性。
2?解决方案
通过趋动科技OrionX“交叉拉远”的特性,AI业务可访问整个集群算力池中的所有不同厂商不同类型的AI算力资源。AI业务可以被调度到集群内的任意节点上,甚至是不带任何算力卡的CPU节点。
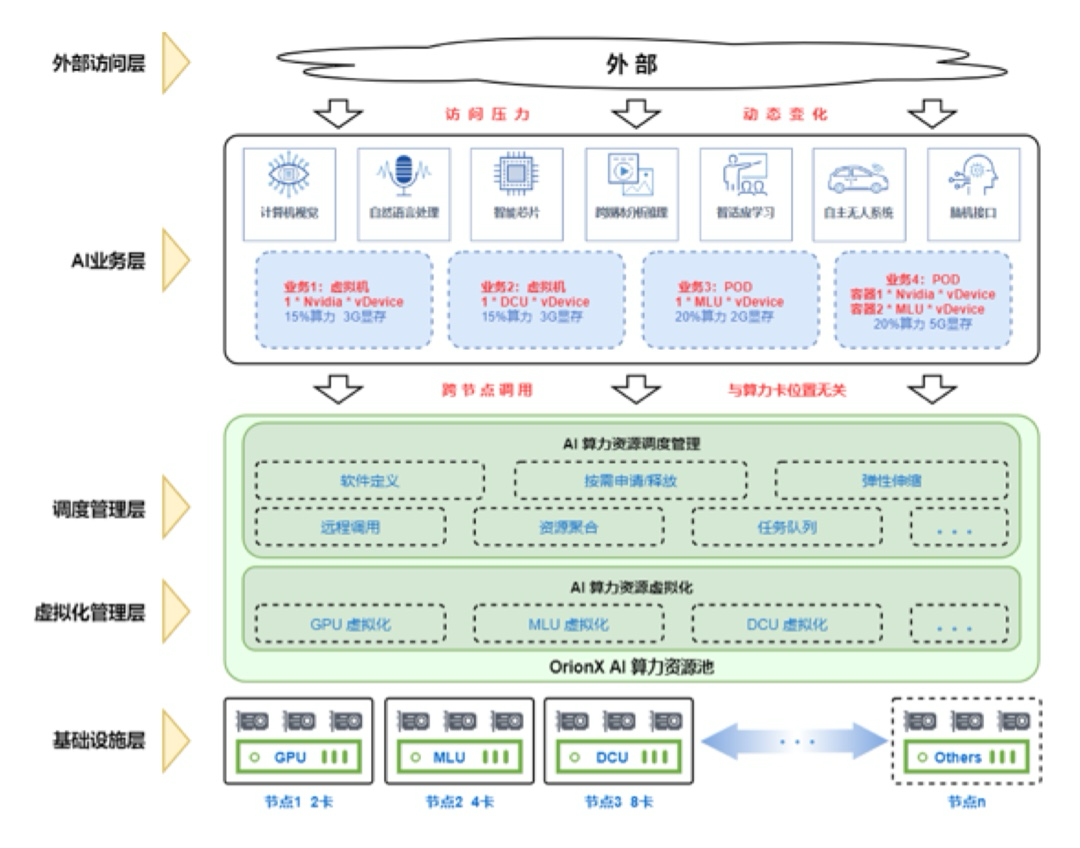
多芯资源交叉拉远技术的架构图
多芯资源交叉拉远技术的架构设计主要包含以下层次:
外部访问层:作为整个系统的入口,接收外部用户或系统的算力资源调用请求。负责与外部系统进行通信,传递业务需求。
AI业务层:在业务调度层进行业务请求的接收和解析。通过与动态调度层的交互,确定为业务分配何种类型的虚拟算力资源。
调度管理层:根据业务需求、实时监控数据以及虚拟化管理层的信息交互,完成实际的资源调度。确保每个业务获得最适宜的算力资源,提高系统的效率。
虚拟化管理层:负责将不同厂商类型和型号的算力资源抽象为虚拟算力,形成算力资源池。管理虚拟GPU资源的状态、性能信息监控等。
基础设施层:包括各厂商不同类型和型号的AI算力设备,作为实际的计算资源提供支持。这些设备通过网络与虚拟化管理层进行交互,执行动态调度的指令。网络在这一层扮演关键角色,确保设备之间的高效通信和指令传递,为整个资源池的协同运作提供必要的连接和支持。
多芯算力交叉拉远技术的实现,取决于多项关键技术的打通:
1) 算力池化技术
这项技术将不同厂商、型号和类型的算力资源抽象为虚拟资源,进行统一管理和调用。通过硬件虚拟化和软件虚拟化,实现了对AI算力资源的灵活分配,提高了系统对多芯算力设备的兼容性,使其能够统一管理。
2) 远程调用
通过高效的网络通信协议和统一远程调用接口,实现了在单个计算节点内为不同AI业务分配来自不同厂商算力节点资源的目标。这项技术要求网络具备较高的吞吐量和低延迟,以确保在动态调度过程中实现即时响应。建议采用RoCE(RDMA over Converged Ethernet)或IB(InfiniBand)等高性能网络,以满足对通信效率和协同工作的高要求。
3) 动态调度算法
动态调度算法根据业务需求和算力资源负载情况,实现了最佳适应、负载均衡和预测性调度。这确保了算力资源的智能分配,使系统能够根据实际情况合理调整业务的资源调用,提高整体系统性能。
4) 资源隔离技术
通过硬件隔离和容器化隔离,资源隔离技术确保了每个业务在使用算力资源时互不干扰。这有效防止了不同业务之间的冲突,保障了业务的稳定性和性能表现。
5) 跨厂商兼容性
为了解决不同厂商算力设备的差异,跨厂商兼容性采用了统一驱动接口、驱动抽象层和跨平台开发工具。这一系列措施确保了系统能够在不同算力设备上实现统一的管理和调用,提高了系统的可维护性和兼容性。
通过综合运用这些关键技术,和科学、合理的架构设计保证了系统的灵活性、高效性以及对不同算力设备的兼容性,OrionX最终实现了多芯算力交叉拉远技术的顺利运行。
3 应用场景
多芯算力交叉拉远技术作为一项创新技术,正逐渐在多个行业场景中展现其广泛应用和独特优势,满足不同领域对于灵活调用算力资源的紧迫需求。这一技术为科研、企业以及多任务应用等领域带来了显著的价值,并为未来的算力资源管理提供了新的可能性。
1)?科研与开发
在科研和开发领域,研究人员通常需要进行多样化的实验和深度学习模型的训练。多芯算力交叉拉远技术可以为每个实验或模型分配不同类型的算力资源,充分发挥各算力设备的优势,提高科研效率。
2) 多芯异构的管理
企业在多芯算力环境中,可通过多芯算力交叉拉远技术统一管理不同厂商算力芯片,屏蔽不同算力芯片的软件生态差异,大大简化管理和运维流程,提升异构资源利用率。
3)?多任务协同
企业运行多个AI任务时,这些任务的算力资源需求可能截然不同。通过多芯算力交叉拉远技术,企业可动态调配资源给每个任务,任务完成后资源自动回收,从而实现更加灵活的资源管理,提高多任务协同运行的效率。
4 优势与价值
1) 灵活性提升
多芯算力交叉拉远技术使得用户可以更加灵活地根据业务需求调用不同厂商的算力资源,最大程度发挥各算力设备的优势。
2) 资源利用效率提高
通过在单个计算节点内实现AI算力资源的跨机调用,规避了传统模式下,AI业务只能运行在GPU节点的问题,提高了整体资源利用效率。
3) 成本效益提升
企业可以更加充分地利用现有的AI算力资源,避免了过度投入单种类型算力设备的锁定风险,降低了IT设备的购置和运维成本。
4) 业务扩展便捷
对于不同业务需求,用户无需针对性地购置不同类型的AI算力设备,可通过多芯算力交叉拉远技术,轻松应对多样化的业务场景,实现业务的便捷扩展。
5 结语
多芯算力交叉拉远技术为解决多样化AI业务中,AI算力资源调用的灵活性和效率问题提供了创新性的解决方案。这一技术将在不同行业场景中,推动算力资源被更加智能、灵活、高效地利用,为企业在数字化时代中取得成功和实现创新提供有力支持。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JAVA实现循环日期加一天
- IDEA的facets和artifacts
- 高性价比的高速吹风机/高速风筒解决方案,基于普冉单片机开发
- 轻松打造命令行工具:探索 zx | 超棒 NPM 库.md
- c语言中一维数组在计算机内部的二进制数存储规则
- Leetcode 第 120 场双周赛 Problem C 统计移除递增子数组的数目 II(Java + 双指针 + 前缀和)
- 如何用Python批量计算Word中的算式
- 计算机蠕虫与病毒:有什么区别?
- Description:An attempt was made to call a method that does not exist.
- Python面向对象之跨类调用(Python系列17)