Leetcode刷题(二十八)
找出字符串中第一个匹配项的下标(Easy)
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
示例 1:
输入:haystack = "sadbutsad", needle = "sad"
输出:0
解释:"sad" 在下标 0 和 6 处匹配。
第一个匹配项的下标是 0 ,所以返回 0 。
示例 2:
输入:haystack = "leetcode", needle = "leeto"
输出:-1
解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。
提示:
1 <= haystack.length, needle.length <= 104
haystack 和 needle 仅由小写英文字符组成
Related Topics
双指针
字符串
字符串匹配
思路分析
这道题是很经典的字符串匹配算法,这里第一个想到的就是KMP字符串匹配算法,这是很经典的数据结构算法,直接使用该算法就可以完成这道题。
这里我来复习一下什么是KMP算法:
首先我们要知道朴素字符串匹配会导致指针不断进行回溯,导致浪费。而KMP算法中的目标指针并不回溯,而是模式串的指针根据得到的next[]数组来进行部分回溯,并且不会重复比对一定相同的字符串。这样就节省了很多时间。比如说目标串为:ABCABEABCABCMN,模式串为:ABCABCMN。由这个例子可以看出,如果是朴素匹配,那么在对比到第一个E出现之后指针就有进行回溯,回溯到目标串[1]的位置,
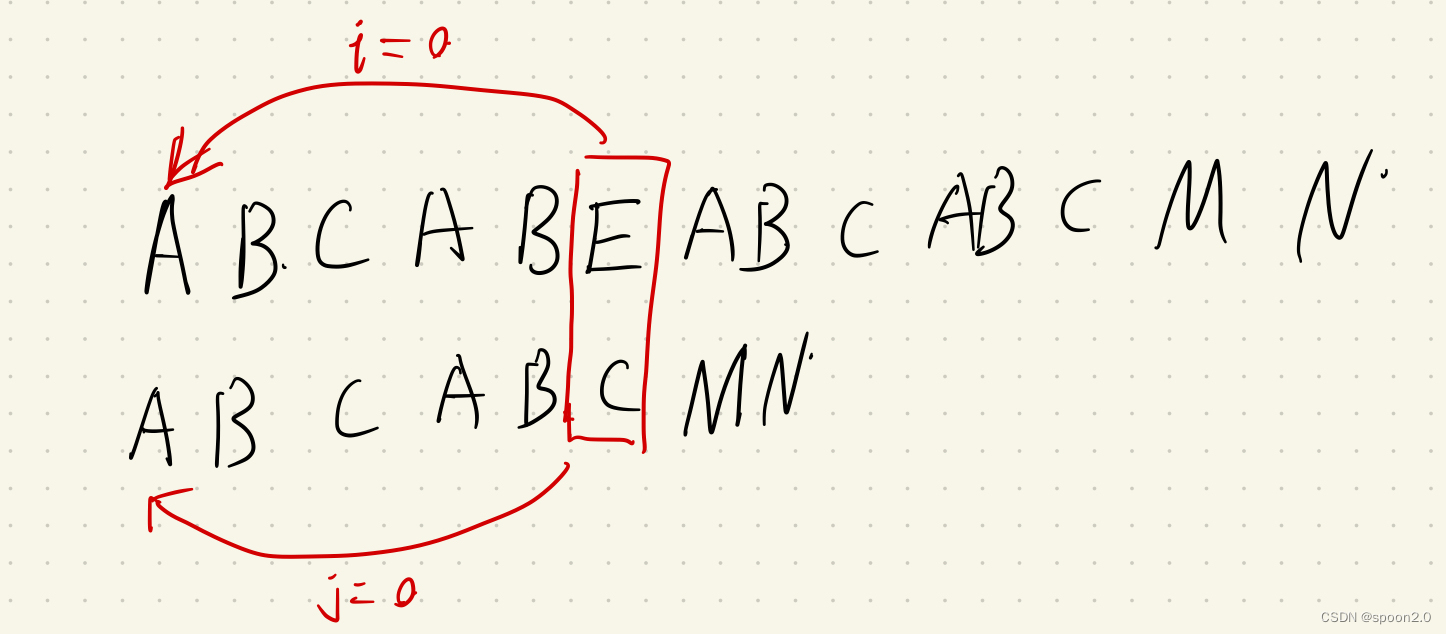
但是如果使用kmp算法,那么目标串的指针并不需要回溯,只需要根据next矩阵来回溯模式串的指针,这里需要回溯到模式串[2]的位置,以此类推。

KMP算法的核心就是如何计算模式串的next[]数组,要想理解如何计算该数组,首先要了解最长相同前后缀的概念。举一个例子就可以明白了,模式串ABCXABCMN,这里对于M位置的前缀:ABC,后缀:ABC.这里要注意,你想找某个位置的最长相同前后缀,那么后缀就不能包括这个位置,比如上面的例子就不包括M。那么这里我们同时也要说一下next数组中元素的含义就是回溯的位置,next[j] = i 的意思就是位置j的元素回溯到位置i。这里我们来看一下求next的公式。

公式通俗的解释就是1.当存在相同前后缀的时候,next[i]的值表示下标为i的字符前的字符串最长相等前后缀的长度。2. j = 0 的时候,也就是字符串第一个元素的时候,初始化为 -1。 3.其他没有相同前后缀的情况,设置为 0 .
同时要了解KMP算法还存在弊端,还可以继续优化,但这里就不再赘述,网上有很多讲解,这里主要还是刷题。
代码实现
//leetcode submit region begin(Prohibit modification and deletion)
class Solution {
public int strStr(String haystack, String needle) {
int flag = -1;
int j = 0;
int i = 0;
int[] next = builtNext(needle);
while (i < haystack.length() && j < needle.length()){
if (j == -1 || haystack.charAt(i) == needle.charAt(j)){
j++;
i++;
}else {
j = next[j];
}
if (j == needle.length()) flag = i-j;//返回匹配开始的位置
}
return flag;
}
//计算NEXT数组
public int[] builtNext(String needle){
int j = 0;
int k = -1;
int[] next = new int[needle.length()];
next[0] = -1;
while (j < needle.length()-1){
if (k == -1 || needle.charAt(k) == needle.charAt(j)){
k++;
j++;
next[j] = k;
}else {
k = next[k];
}
}
return next;
}
}
//leetcode submit region end(Prohibit modification and deletion)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何本地搭建Splunk Enterprise数据平台并实现任意浏览器公网访问
- 【EMC专题】浪涌的成因与ICE 61000-4-5标准
- 黑马程序员SSM框架-Maven进阶
- 图解python | 字符串及操作
- 【Gradle】运行时一直要下载 gradle-8.5-bin.zip
- 深入理解 go reflect - 反射为什么慢
- pip 常用指令 pip cache 命令用法介绍
- 类和对象之拜访对象村
- 演讲实录|博睿数据副总裁杨雪松:可观测性建设之路(上)
- VUE的template使用