理解MoCo
目录
1、简介
对比学习的本质实际上是让两个相似(比如相同类别)的图像在特征空间内尽可能相近,不相似的图像尽可能远,这里相似的图像就是正样本,不相似的图像就是负样本。而如何区分正负样本对的方法就形成了各式各样的代理任务(pretext task)。那MoCo所用的代理任务就是个体判别了,每张图像都是单独的一类,在网络中只有原图经过数据增强后的图像属于原图的正样本,其他的图像都是负样本。
有了区分正负样本的方法后就是常规的,进入encoder提取特征,输出的特征用NCEloss进行反向传播,梯度下降。
2、MoCo
2.1、引言
无监督学习在nlp领域取得了巨大的成功,比如BERT、GPT等等,但是在cv领域还是有监督占据主流,效果更好。这可能是因为nlp天然是一个离散信号,不同的单词都可以表示为词汇表中的一类,相当于是一个分类任务。所以在nlp中,无监督学习容易去建模,优化。但是图像往往是连续,高维的信息,不想单词那样有很强的语义信息,所以不适合去tokenize建模。
MoCo把对比学习看作是一个动态字典的任务,他把锚点图像看作是一个query,将query与字典中的所有特征进行查询匹配,与正样本更加接近,与负样本远离。为了使字典中的k0,k1...与q能匹配上,字典的编码器是要一直随着锚点的编码器更新的,尽可能与锚点编码器相似,所以字典是动态的。
为了使对比学习结果更好,字典应该具有两个特性,一个是字典足够大,第二个是在训练时要保持尽可能的一致性。
(1)字典足够大才能学习到真正将正负样本区分开的特征。
(2)只有锚点的编码器和字典的编码器保持一致,才能让网络真正匹配到正样本。如果用了不同的编码器,那么q很有可能匹配到与q特征相似,但是匹配到的是负样本的情况。

但是之前的自监督文章要么只关注字典的大小,忽略了一致性,比如Inst Disc。要么只关注一致性而忽略了字典的大小,比如SimCLR。
SimCLR如上图(a)所示,他是一个端到端的模型,所有编码器都可以通过梯度回传更新,模型直接从原始输入到最终输出,没有明确定义的中间步骤或子任务。这样可以保证所有正负样本都是从同一个编码器输出的特征,具有高度的一致性。但是缺点是负样本大小就是batchsize的大小。如果想要大的字典就需要大的batchsize,大的硬件支持,比如SimCLR的batchsize就为8192。并且大的batchsize会导致模型优化困难。
Inst Disc如上图(b)所示,他只具有一个编码器,其他所有样本的特征都存在memory bank中。Inst Disc的memory bank就包含了128万个特征,为了节省内存,每个特征是128维的。在前向过程中从memory bank中随机选取一部分作为负样本进行对比学习,然后用更新后的编码器去重新提取刚才负样本的特征放入memory bank中。但是这样会导致字典中的样本特征和q特征不一致(因为提取特征的编码器不同),导致训练结果产生偏差。
2.2、主要贡献
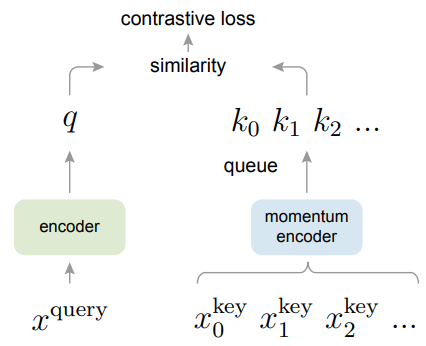
MoCo的主要改进在于做了一个动态的字典,其中包括一个队列和一个移动平均编码器,也就是动量编码器。
其中用队列表示字典,将字典的大小与batchsize大小的关系剥离开。比如你的batchsize只有32,但是你的队列就完全可以是batchsize大小的10倍大小,每次将新的特征传入字典中时,队列中最早的特征就会被踢出。因为队列不会进行梯度回传,所以队列可以放很多负样本,使字典变得很大。
![]()
动量编码器的表达式如上式所示,yt为该时刻输出,yt-1表示上一时刻输出,xt表示该时刻输入,m是动量权重,值在0~1之间。当m趋近于1时,表示该时刻输出更加依赖于上一时刻输出,趋近于0时,表示该时刻输出更依赖于该时刻输入。MoCo中,动量编码器是由锚点编码器初始化的,m选取的比较大,所以动量编码器变化的比较缓慢,目的是想让队列里的特征尽量都是由相同的编码器提取的,使特征保持一致性。
通过队列和动量编码器的设置,MoCo就可以创建一个又大又一致的字典了。
MoCo比较灵活,可以应用在很多代理任务上。在论文中主要采用了个体判别的任务,q和k是同一个图片的不同视角(不同数据增强),则认为是正样本。
2.3、相关工作
一般无监督的创新方式分为两种,一种是代理任务的创新,一种是目标函数的创新。MoCo就是目标函数的创新。
目标函数是测量模型预测的结果和固定目标之间的差异的。目标函数有生成式和判别式的。生成式就比如自编码器,重建图像,由原图作为标签,目标函数是L1loss或者L2loss。判别式就是类似分类任务,用交叉熵损失函数。
但是生成式和判别式的损失函数中,标签都是固定的值,原始图像或者类别标签。但是对比学习的目标函数的标签不是固定的。对比学习中的标签一般是正样本和负样本经过编码器提取的特征,由于编码器是不断变化的,所以特征值也是不断在变化的。
对抗性的目标函数也没有固定的值,比如GAN,衡量的是两个概率分布之间的差异。
有监督任务都是有ground truth标签的,通过模型输出预测的结果,通过目标函数来衡量输出和标签的差异。但是当数据集没有标签的时候怎么办呢?我们就通过代理任务生成一个自监督信号,去充当ground truth标签信息,通过特定的目标函数来衡量他们之间的差异。
2.4、方法
2.4.1、损失函数
我们想让q和正样本之间的loss尽量小,和负样本之间的loss尽量大。MoCo提出了InfoNCE。
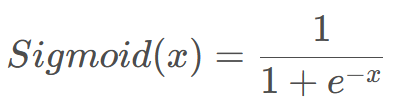
先来讲讲sigmoid函数,sigmoid函数可以看作一个二分类的结果,最后一层全连接神经元的个数为1,输出结果的取值范围是[0,1]。为什么是二分类的呢?因为只有当x=-x时,sigmoid函数相加为1。
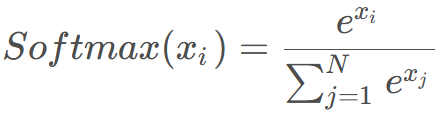
softmax是多分类的结果,每个输出值都可当成概率来理解,所有输出相加为1。
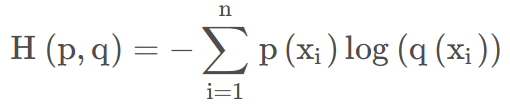
而交叉熵损失函数往往是和softmax函数一起使用的,其中p(x)表示one-hot标签,q(x)表示预测的值,范围为[0,1]。所以交叉熵损失的结果一般是-log(x),x表示输出某一类概率最大的值。
对比学习理论上来说是可以用交叉熵损失函数的,因为本质上对比学习属于一个多分类问题,字典中每一个图像都是一个类别。但是这样softmax是没法计算的,因为类别太多,还要对每个类别的输出归一化为概率,还要取指数和负对数,计算量爆炸。所以对比学习一般使用NCEloss。
NCEloss是将多分类问题转化为了二分类问题,分为数据和噪声两类。正样本就是数据类,负样本就是噪声类。并且如果对字典中每个输出都来计算二分类,计算量还是太大了,NCEloss就想在噪声类别(负样本)中进行采样,采样的结果再来计算二分类。
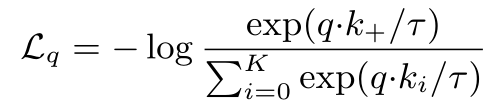
但是MoCo这篇论文认为,如果把所有负样本都看作噪声类也是不太合理的,因为负样本中也有与正样本相似的图像,所以提出了InfoNCEloss,如上式所示。分母的K表示负样本个数,i从0到K一共K+1个样本,其实这就是一个交叉熵损失函数加了一个温度系数tao。
2.4.2、队列
MoCo用队列的方式表示字典,将字典大小和batchsize大小的关系分离开,并且可以实时更新字典,使字典中的负样本特征尽量保持一致。
2.4.3、动量编码器
![]()
因为队列无法进行梯度回传,所以正负样本编码器无法更新。如果直接复制锚点编码器的话效果不太好,可能是因为这样的话队列中的特征就不一致了(因为是不同时刻编码器输出的特征)。所以MoCo采用了动量编码器,将m设为0.999,这样动量编码器变化的就非常缓慢,使队列中的特征保持一致性,效果非常好。
2.4.4、前向过程

上图是MoCo论文中前向过程的伪代码。
- 先随机初始化query编码器,然后将参数赋给key编码器。
- 从dataloader中取出mini-batch个图像,经过图像增强得到x_q和x_k,x_q作为锚点,x_k作为正样本。
- x_q和x_k经过编码器得到特征q(256*128)和k(256*128),k不进行梯度计算。
- 将q和k通过矩阵乘法计算正样本相似度l_pos(256*1)。
- 将队列中的负样本与q进行矩阵乘法得到负样本相似度l_neg(256*65536)。
- 将正负样本向量concat起来得到logits(256*65537)。
- 创建一个值为0,大小为batchsize的标签。因为concat时所有正样本都位于batch的第0个位置,所以可以直接用CEloss计算。至于详细的计算过程可以参考文章交叉熵函数Cross_EntropyLoss()的详细计算过程-CSDN博客
- 然后梯度回传,更新f_q编码器。
- 动量更新编码器f_k。
- 更新队列,将最新的mini-batch的特征放入队列,将旧的去除。
2.5、实验

MoCo实验细节如上图所示。
2.5.1、网络结构比较
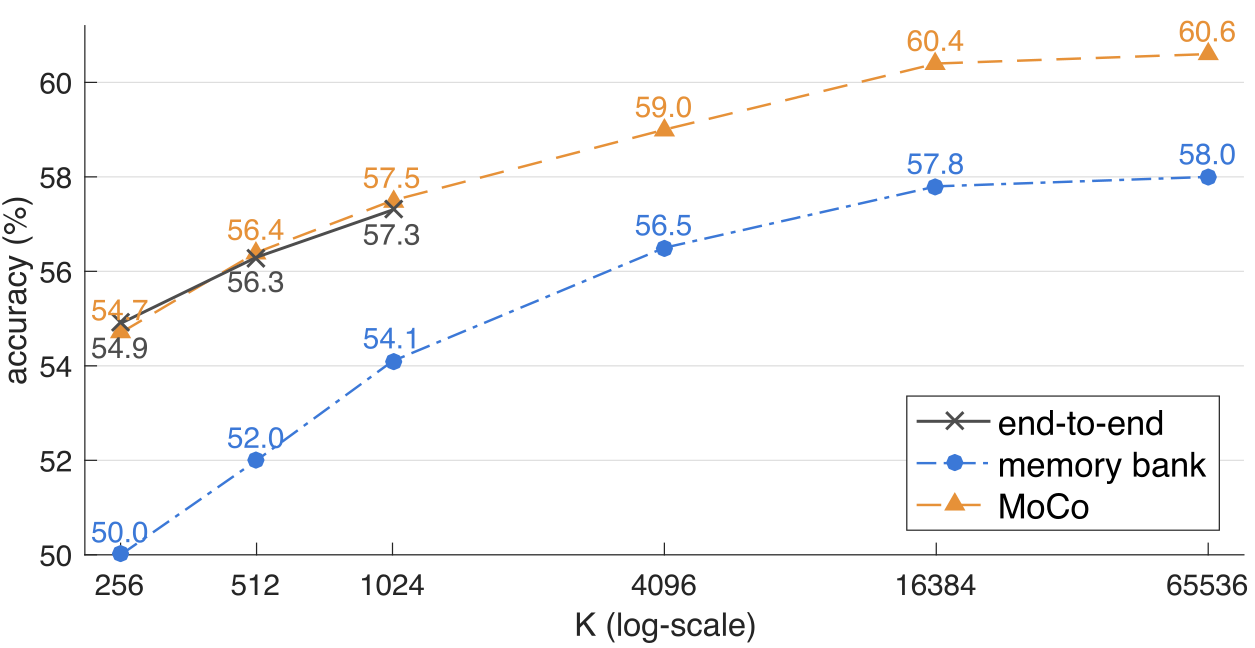
上图所示是三种自监督方法的比较,横坐标为负样本数量,纵坐标为精度。
2.5.2、动量参数m
![]()
上图证明,动量参数越大越好,动量编码器更新的越慢越好。
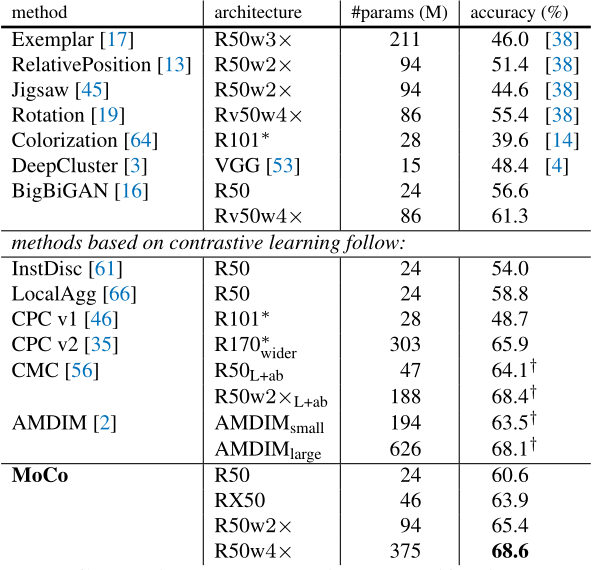
2.5.3、imageNet数据集结果
2.5.4、迁移特性
无监督学习最主要的目标就是去学习一个可以迁移的特征。是ImageNet影响力广泛最主要的原因就是在ImageNet上预训练的模型可以在下游任务上微调,从而使模型在数据集少的任务中也可以获得很好的效果。
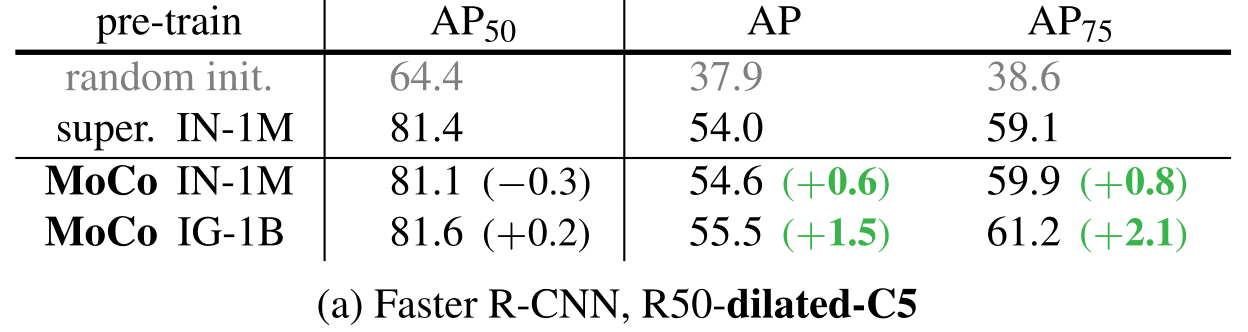
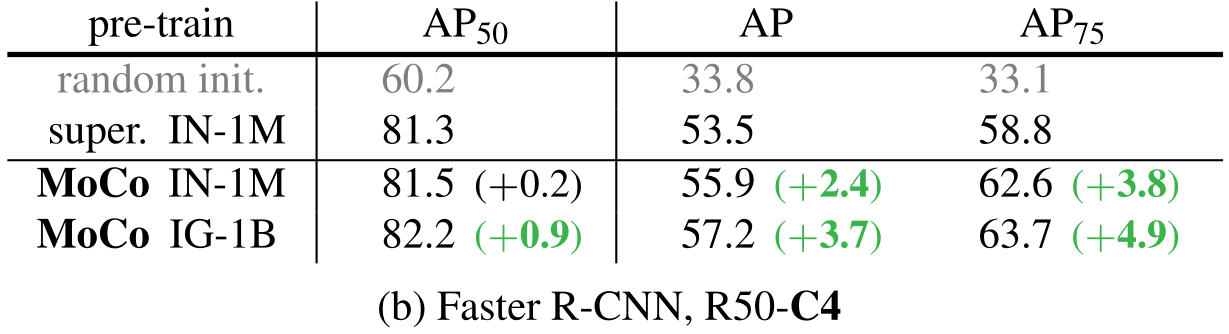
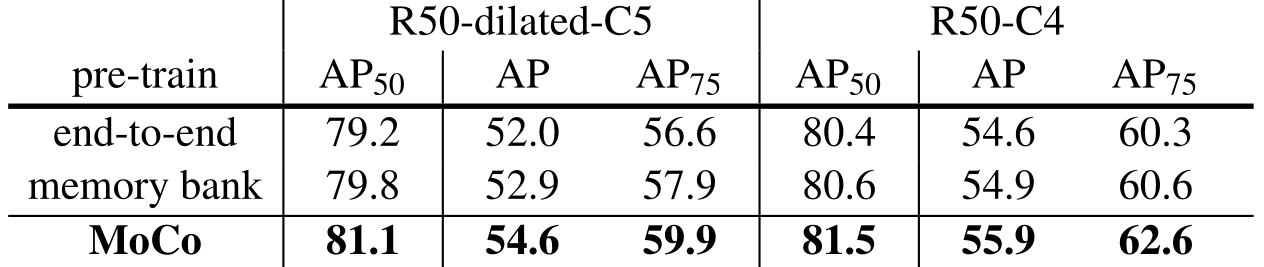
实验证明,在下游任务上,MoCo全面领先。
2.6、MoCo代码
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 铣刀刀口破损缺陷检测
- 2020年第九届数学建模国际赛小美赛D题石头剪刀游戏与合作解题全过程文档及程序
- 在机关单位上班的你,需要掌握这些网络安全知识!
- 小程序基础学习(登录)(重点核心)
- 多项创新技术加持,汉威科技危化品企业、化工园区两大智能化管控平台重磅发布
- Linux终端常见用法总结
- PHY6212 Dongle 升级 PHY62XX 固件方法 PHY6252/PHY6222芯片特性对比
- 电容充电时间的计算
- 第11章 GUI Page462~476 步骤二十三,二十四,二十五 Undo/Redo ③实现“Undo/Redo”菜单项
- 学习python仅此一篇就够了(JSON数据格式转换)