机器学习_从线性回归到逻辑回归原理和实战
介绍分类问题
机器学习两个主要应用是回归和分类问题。
逻辑回归算法的本质其实仍然是回归。这个算法也是通过调整权重w和偏置b来找到线性函数来计算数据样本属于某一类的概率。比如二元分类,一个样本有60%的概率属于A类,有30%的概率属于B类,算法就会判断样本属于A类。
机器学习的分类方法,也是要找到一个合适的函数,拟合输入和输出的关系,输入一个或一系列事物的特征,输出这个事物的类别。
对于计算机来说,输入的特征必须是它所能够识别的。例如,我们无法把人(性别)输入计算机,那么只能找到最具代表性的特征(年龄、血压、账户存款余额等)转换成数值后输入模型。

而输出,则是离散的数值,如0、1、2、3等分别对应不同类别。例如,二元分类中的对或错、来或不来。
在输出明确的离散分类值之前,算法首先输出的其实是一个可能性,你们可以把这个可能性理解成一个概率。
-
机器学习模型根据输入数据判断一个人患心脏病的可能性为80%,那么就把这个人判定为“患病”类,输出数值1。
-
机器学习模型根据输入数据判断一个人患心脏病的可能性为30%,那么就把这个人判定为“健康”类,输出数值0。
机器学习的分类过程,也就是确定某一事物隶属于某一个类别的可能性大小的过程。
用线性回归+阶跃函数完成分类
我们注意到在60分左右的两个人,一个通过了考试,一个则挂科了。那么根据此批数据,在60分这个点,考试通过的概率为50%。而60分这个x点,用线性回归函数做假设函数时,所对应的y值刚好是 0.5,也就是50%
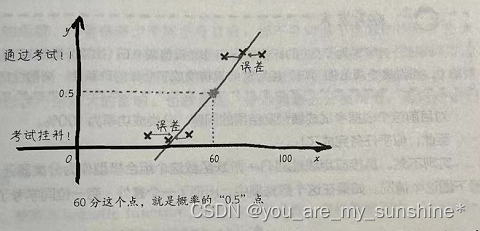
分类问题和回归问题的本质区别:对于分类问题来说,尽管分类的结果和数据的特征之间仍呈现相关关系,但是y的值不再是连续的,是0~1的跃迁。
但概率是连续的,随着成绩的上升,通过考试的概率是逐渐升高的,当达到一个关键点(阈值),如此例中的60分的时候,通过考试的概率就超过了0.5。那么从这个点开始,之后y的预测值都为1。”
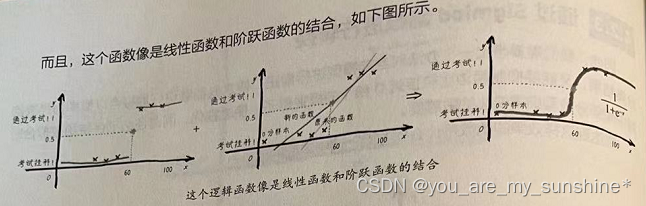
因此,只要将线性回归的结果做一个简单的转换,就可以得到分类器的结果。这个转换如下图所示。
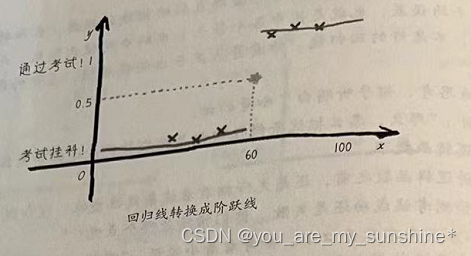
回归线转换成阶跃线
这可以分为以下两种情况。
- 线性回归模型输出的结果大于0.5,分类输入1。
- 线性回归模型输出的结果小于0.5,分类输入0。
直接应用线性回归+阶跃函数这个组合模型作为分类器还是会有局限性。假如有一位同学考了0分!
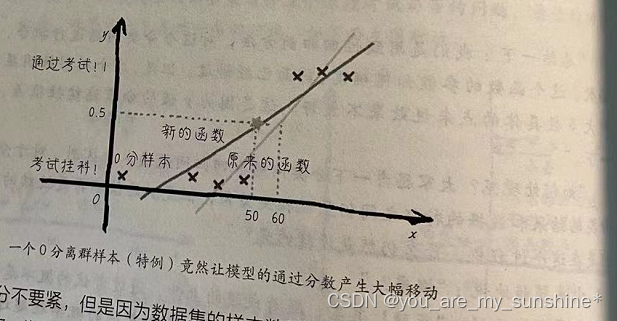
一个离群的样本会造成线性回归模型发生改变。为了减小平均误差,回归线现在要往0分那边稍作移动。因此,概率0.5这个阈值点所对应的x分数也发生了移动,目前变成了50分。这样,如果有一个同学考了51分, 本来是没有及格,却被这个模型判断为及格(通过考试的概率高于0.5)。这个结果与我们的直觉不符。
通过 Sigmiod 函数进行转换
因此,我们需要想出一个办法对当前模型进行修正,使之既能够更好地拟合以概率为代表的分类结果,又能够抑制两边比较接近0和1的极端例子,使之钝化,同时还必须保持函数拟合时对中间部分数据细微变化的敏感度。
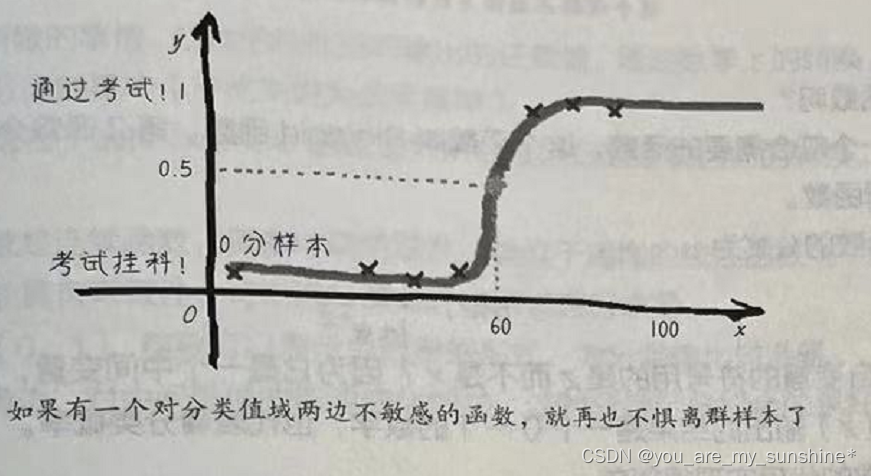
如果有这种S形的函数(logistic function,逻辑函数),不管有多少个同学考0分,都不会对这个函数的形状产生大的影响。因为这个函数对于靠近0分和100分附近的极端样本是很不敏感的,类似样本的分类概率将无限逼近0或1,样本个数再多也无所谓。但是在0.5这个分类概率临界点附近的样本将对函数的形状产生较大的影响。也就是说,样本越靠近分类阈值,函数对它们就越敏感。
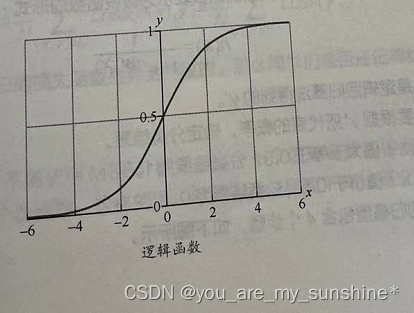
Sigmoid 函数的公式为: 
为什么这里自变量的符号用的是z而不是x?因为它是一个中间变量,代表的是线性回归的结果。而这里g(z)输出的结果是一个0~1的数字,也代表着分类概率。
Sigmoid函数的代码实现很简单:
y_hat = 1/(1+ np.exp(-z))#输入中间变量z,返回y'
通过 Sigmoid函数就能够比阶跃函数更好地把线性函数求出的数值,转换为一个0~1的分类概率值。
逻辑回归的假设函数
有了 Sigmoid函数,就可以开始正式建立逻辑回归的机器学习模型。上一课说过,建立机器学习的模型,重点要确定假设函数h(x),来预测y’。
总结一下上面的内容,把线性回归和逻辑函数整合起来,形成逻辑回归的假设函数。
(1)首先通过线性回归模型求出一个中间值z,
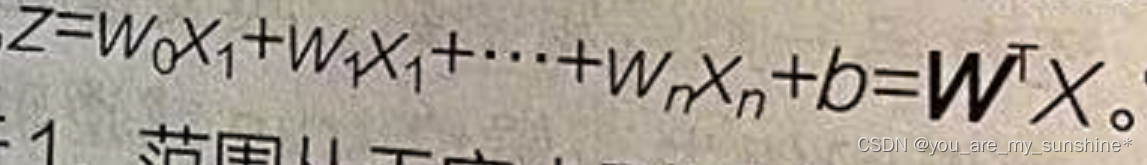
。它是一个连续值,区间并不在[0,1]之间,可能小于0或者大于1,范围从无穷小到无穷大。
(2)然后通过逻辑函数把这个中间值 z 转化成0~1的概率值,以提高拟合效果
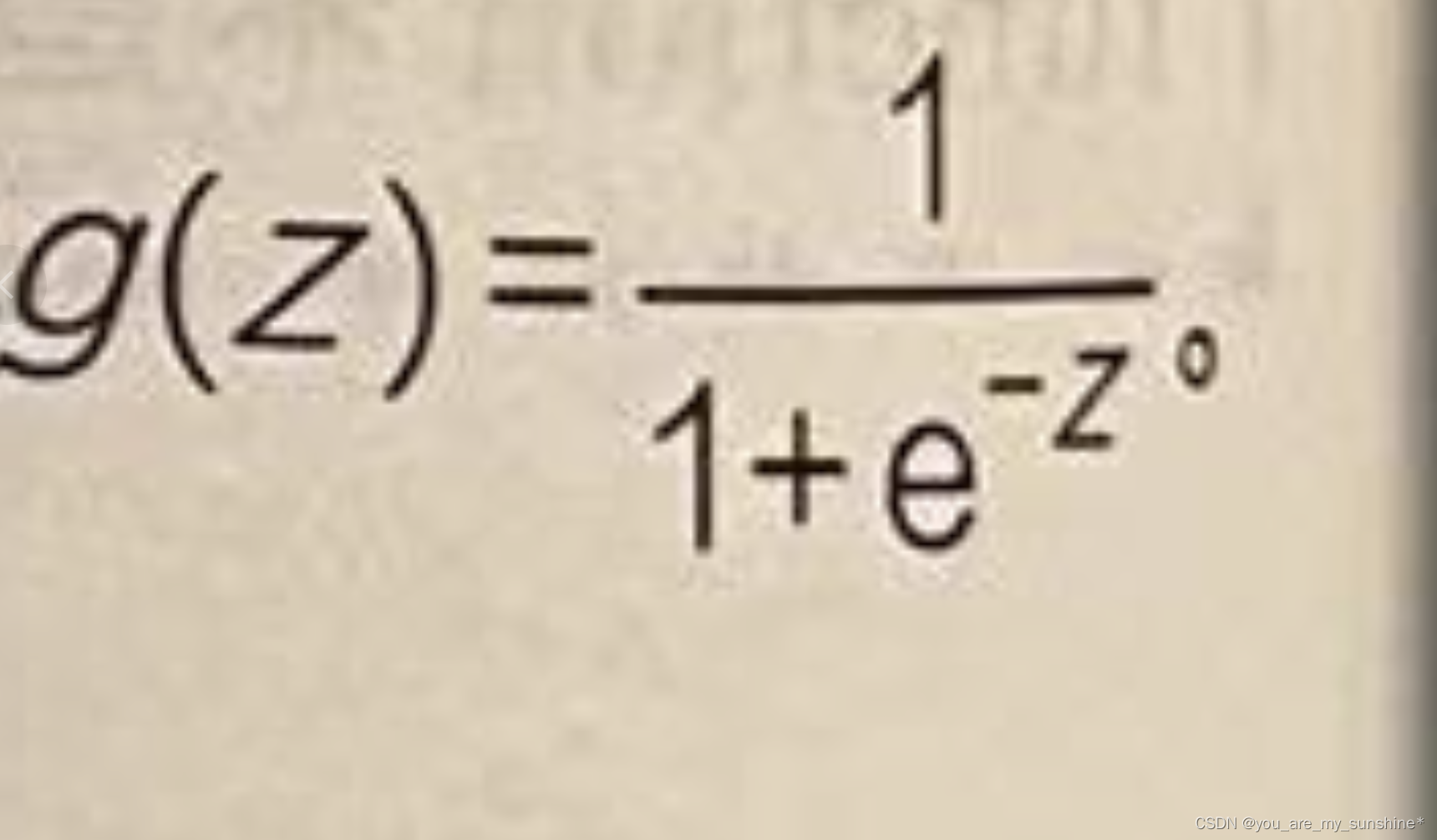
(3)结合步骤(1)和(2),把新的函数表示为假设函数的形式:
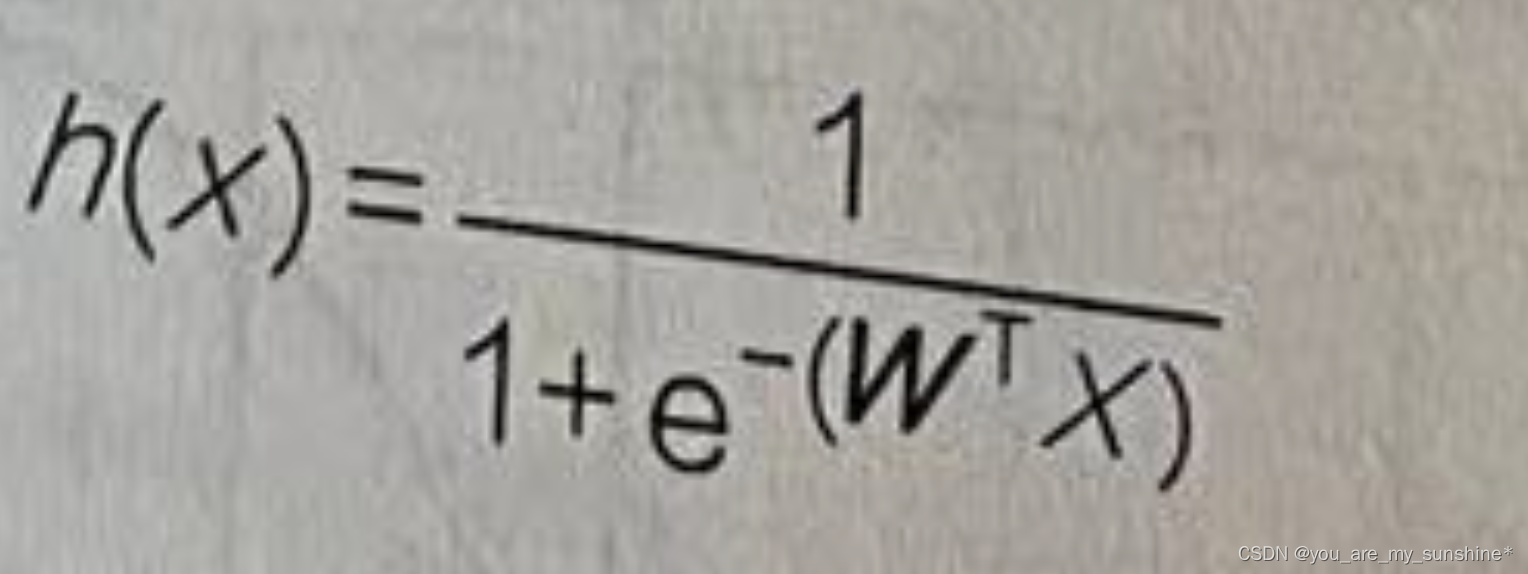
这个值也就是逻辑回归算法得到的y’。
(4)最后还要根据y’所代表的概率,确定分类结果。
- 如果h(x)值大于等于0.5,分类结果为1。
- 如果h(x)值小于0.5,分类结果为0。
因此,逻辑回归模型包含4个步骤,如下图所示。
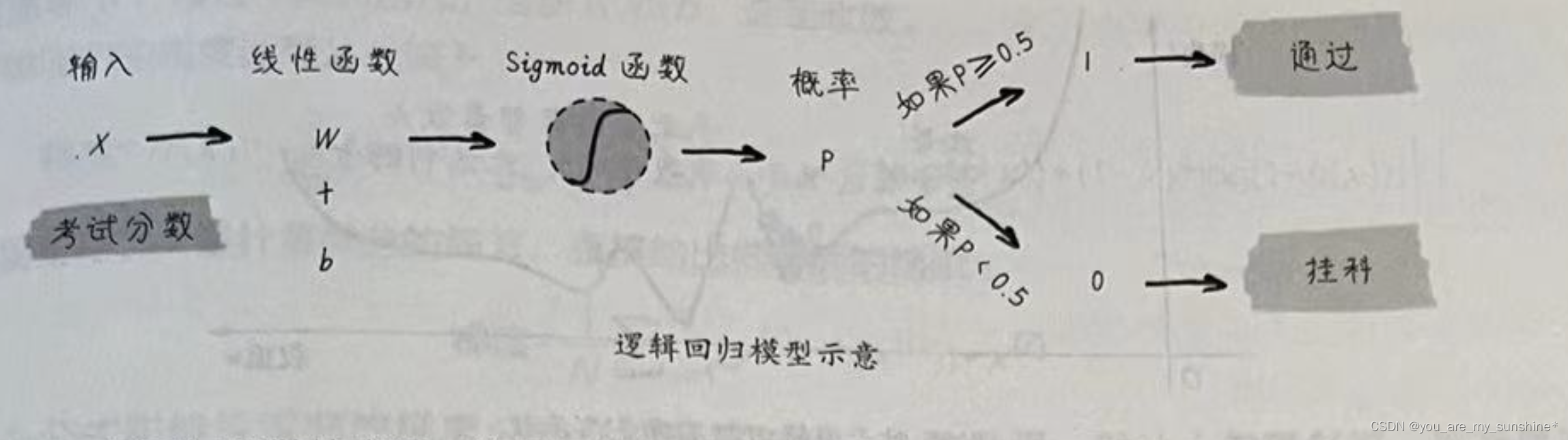
逻辑回归所做的事情,就是把线性回归输出的任意值,通过数学上的转换,输出为0~1的结果,以体现二元分类的概率(严格来说为后验概率)。
上述过程中的关键在于选择Sigmoid函数进行从线性回归到逻辑回归的转换。Sigmoid函数的优点如下。
- Sigmoid 函数是连续函数,具有单调递增性(类似于递增的线性函数)。
- Sigmoid 函数具有可微性,可以进行微分,也可以进行求导。
- 输出范围为【0,1],结果可以表示为概率的形式,为分类输出做准备。
- 抑制分类的两边,对中间区域的细微变化敏感,这对分类结果拟合效果好。
逻辑回归的损失函数
把训练集中所有的预测所得概率和实际结果的差异求和,并取平均值,就可以得到平均误差,这就是逻辑回归的损失函数:
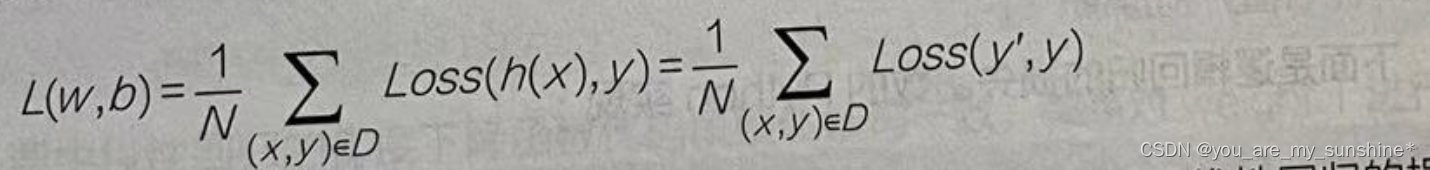
逻辑回归的损失函数,公式如下
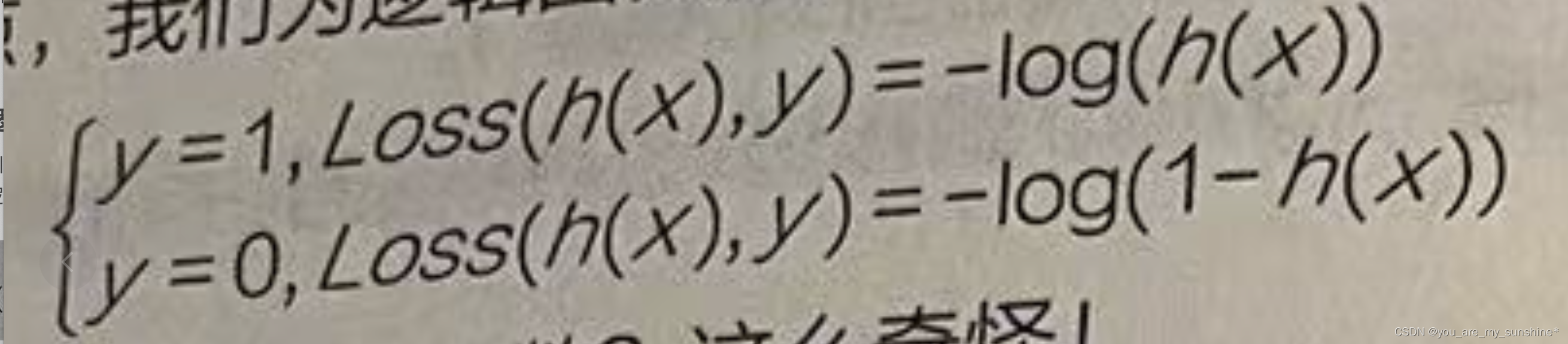
这是一个函数在真值为0或者1的时候的两种情况。这不就是以自然常数为底数的对数吗?而且,从图形上看(如下图所示),这个函数将对错误的猜测起到很好的惩罚效果。
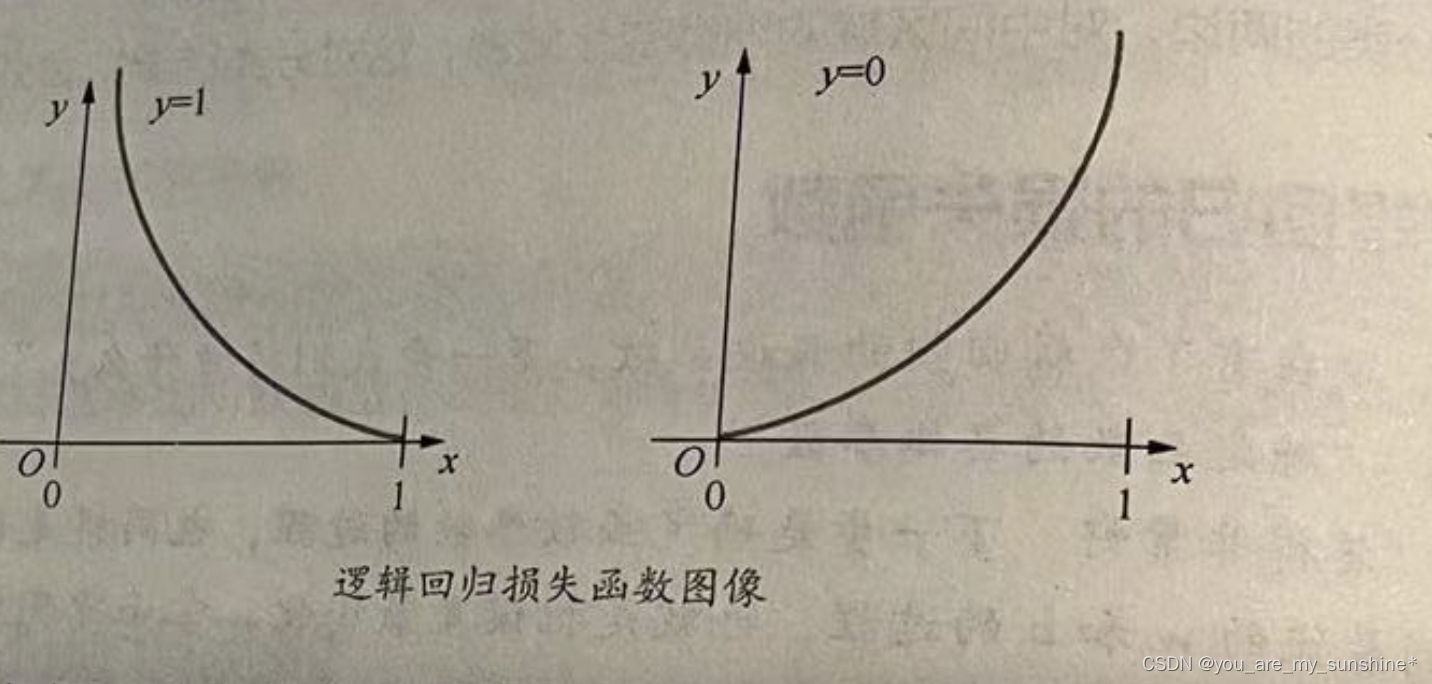
- 如果真值是1,但假设函数预测概率接近于0的话,得到的损失值将是巨大的。
- 如果真值是0,但假设函数预测概率接近于1的话,同样将得到天价的损失值。
而上面这种对损失的惩罚力度正是我们所期望的。
整合起来,逻辑回归的损失函数如下:
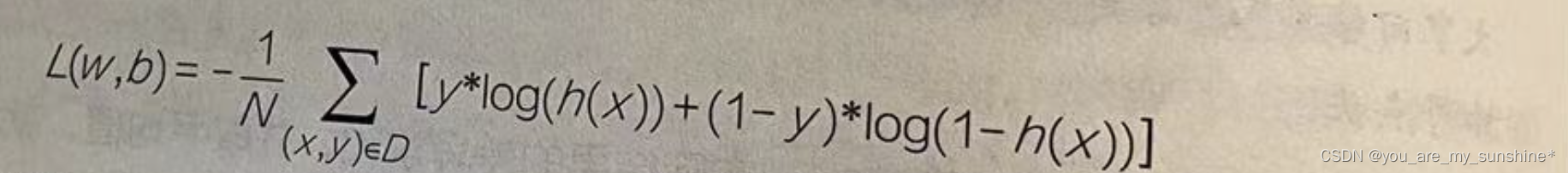
这个公式其实等价于上面的损失函数在0、1时的两种情况,可以自己代入y=0和y=1两种取值分别推演一下。
下面是逻辑回归的损失函数的Python 实现:
loss = - (y_train*np.log(y_hat) + (1-y_train) *np.log(1-y_hat))
用逻辑回归解决二元分类问题
import numpy as np # 导入NumPy数学工具箱
import pandas as pd # 导入Pandas数据处理工具箱
df_heart = pd.read_csv("../数据集/heart.csv") # 读取文件
df_heart.head() # 显示前5行数据
df_heart.target.value_counts() # 输出分类值,及各个类别数目
import matplotlib.pyplot as plt # 导入绘图工具
%matplotlib inline
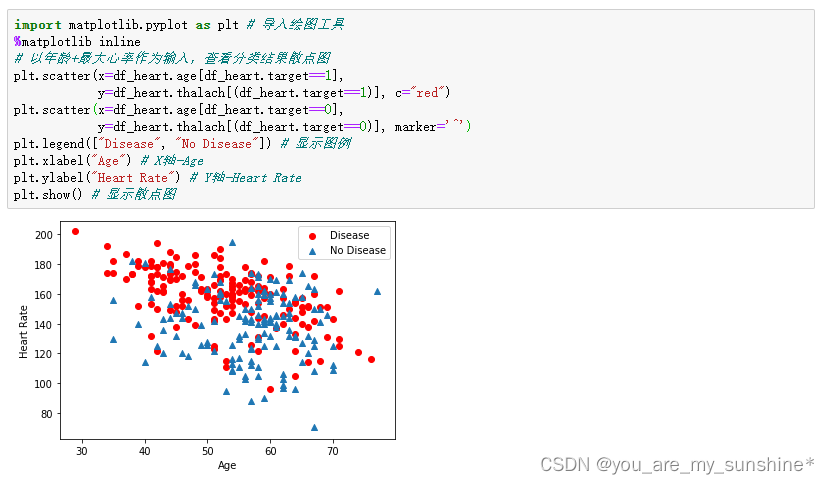
# 以年龄+最大心率作为输入,查看分类结果散点图
plt.scatter(x=df_heart.age[df_heart.target==1],
y=df_heart.thalach[(df_heart.target==1)], c="red")
plt.scatter(x=df_heart.age[df_heart.target==0],
y=df_heart.thalach[(df_heart.target==0)], marker='^')
plt.legend(["Disease", "No Disease"]) # 显示图例
plt.xlabel("Age") # X轴-Age
plt.ylabel("Heart Rate") # Y轴-Heart Rate
plt.show() # 显示散点图
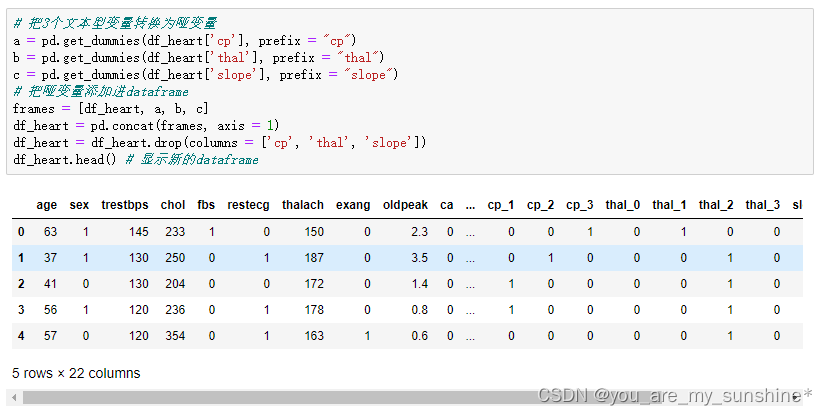
# 把3个文本型变量转换为哑变量
a = pd.get_dummies(df_heart['cp'], prefix = "cp")
b = pd.get_dummies(df_heart['thal'], prefix = "thal")
c = pd.get_dummies(df_heart['slope'], prefix = "slope")
# 把哑变量添加进dataframe
frames = [df_heart, a, b, c]
df_heart = pd.concat(frames, axis = 1)
df_heart = df_heart.drop(columns = ['cp', 'thal', 'slope'])
df_heart.head() # 显示新的dataframe
X = df_heart.drop(['target'], axis = 1) # 构建特征集
y = df_heart.target.values # 构建标签集
y = y.reshape(-1,1) # -1是 相对索引,等价于len(y)
print("张量X的形状:", X.shape)
print("张量X的形状:", y.shape)

from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.2)
from sklearn.preprocessing import MinMaxScaler # 导入数据缩放器
scaler = MinMaxScaler() # 选择归一化数据缩放器,MinMaxScaler
X_train = scaler.fit_transform(X_train) # 特征归一化 训练集fit_transform
X_test = scaler.transform(X_test) # 特征归一化 测试集transform
# 首先定义一个Sigmoid函数,输入Z,返回y'
def sigmoid(z):
y_hat = 1/(1+ np.exp(-z))
return y_hat
# 然后定义损失函数
def loss_function(X,y,w,b):
y_hat = sigmoid(np.dot(X,w) + b) # Sigmoid逻辑函数 + 线性函数(wX+b)得到y'
loss = -(y*np.log(y_hat) + (1-y)*np.log(1-y_hat)) # 计算损失
cost = np.sum(loss) / X.shape[0] # 整个数据集平均损失
return cost # 返回整个数据集平均损失
# 然后构建梯度下降的函数
def gradient_descent(X,y,w,b,lr,iter) : #定义逻辑回归梯度下降函数
l_history = np.zeros(iter) # 初始化记录梯度下降过程中误差值(损失)的数组
w_history = np.zeros((iter,w.shape[0],w.shape[1])) # 初始化权重记录的数组
b_history = np.zeros(iter) # 初始化记录梯度下降过程中偏置的数组
for i in range(iter): #进行机器训练的迭代
y_hat = sigmoid(np.dot(X,w) + b) #Sigmoid逻辑函数+线性函数(wX+b)得到y'
loss = -(y*np.log(y_hat) + (1-y)*np.log(1-y_hat)) # 计算损失
derivative_w = np.dot(X.T,((y_hat-y)))/X.shape[0] # 给权重向量求导
derivative_b = np.sum(y_hat-y)/X.shape[0] # 给偏置求导
w = w - lr * derivative_w # 更新权重向量,lr即学习速率alpha
b = b - lr * derivative_b # 更新偏置,lr即学习速率alpha
l_history[i] = loss_function(X,y,w,b) # 梯度下降过程中的损失
print ("轮次", i+1 , "当前轮训练集损失:",l_history[i])
w_history[i] = w # 梯度下降过程中权重的历史 请注意w_history和w的形状
b_history[i] = b # 梯度下降过程中偏置的历史
return l_history, w_history, b_history
def predict(X,w,b): # 定义预测函数
z = np.dot(X,w) + b # 线性函数
y_hat = sigmoid(z) # 逻辑函数转换
y_pred = np.zeros((y_hat.shape[0],1)) # 初始化预测结果变量
for i in range(y_hat.shape[0]):
if y_hat[i,0] < 0.5:
y_pred[i,0] = 0 # 如果预测概率小于0.5,输出分类0
else:
y_pred[i,0] = 1 # 如果预测概率大于0.5,输出分类0
return y_pred # 返回预测分类的结果
def logistic_regression(X,y,w,b,lr,iter): # 定义逻辑回归模型
l_history,w_history,b_history = gradient_descent(X,y,w,b,lr,iter)#梯度下降
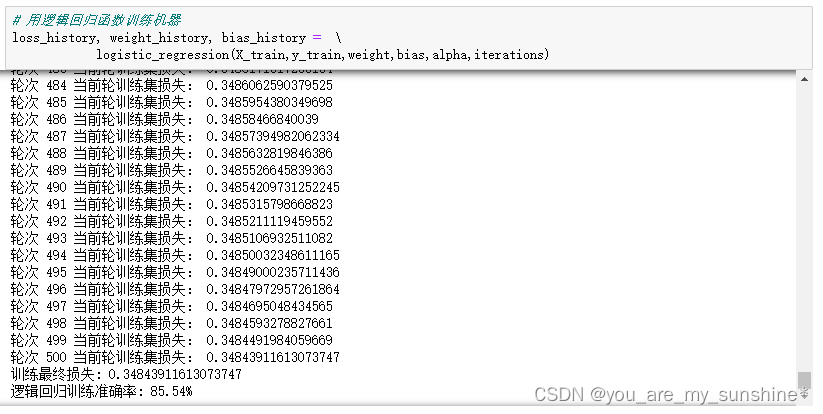
print("训练最终损失:", l_history[-1]) # 打印最终损失
y_pred = predict(X,w_history[-1],b_history[-1]) # 进行预测
traning_acc = 100 - np.mean(np.abs(y_pred - y_train))*100 # 计算准确率
print("逻辑回归训练准确率: {:.2f}%".format(traning_acc)) # 打印准确率
return l_history, w_history, b_history # 返回训练历史记录
#初始化参数
dimension = X.shape[1] # 这里的维度 len(X)是矩阵的行的数,维度是列的数目
weight = np.full((dimension,1),0.1) # 权重向量,向量一般是1D,但这里实际上创建了2D张量
bias = 0 # 偏置值
#初始化超参数
alpha = 1 # 学习速率
iterations = 500 # 迭代次数
# 用逻辑回归函数训练机器
loss_history, weight_history, bias_history = \
logistic_regression(X_train,y_train,weight,bias,alpha,iterations)
y_pred = predict(X_test,weight_history[-1],bias_history[-1]) # 预测测试集
testing_acc = 100 - np.mean(np.abs(y_pred - y_test))*100 # 计算准确率
print("逻辑回归测试准确率: {:.2f}%".format(testing_acc))
#逻辑回归测试准确率: 86.89%
print ("逻辑回归预测分类值:",predict(X_test,weight_history[-1],bias_history[-1]))
#逻辑回归预测分类值: [[1.]
# [1.]
# [1.]
# [1.]
# [1.]
# [0.]
# [1.]
# [1.]
# [0.]
# [1.]
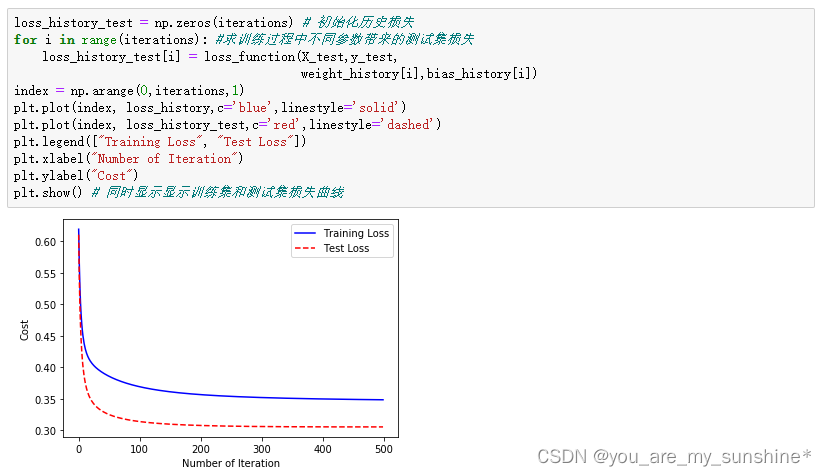
loss_history_test = np.zeros(iterations) # 初始化历史损失
for i in range(iterations): #求训练过程中不同参数带来的测试集损失
loss_history_test[i] = loss_function(X_test,y_test,
weight_history[i],bias_history[i])
index = np.arange(0,iterations,1)
plt.plot(index, loss_history,c='blue',linestyle='solid')
plt.plot(index, loss_history_test,c='red',linestyle='dashed')
plt.legend(["Training Loss", "Test Loss"])
plt.xlabel("Number of Iteration")
plt.ylabel("Cost")
plt.show() # 同时显示显示训练集和测试集损失曲线
直接调用 Sklearn 库
from sklearn.linear_model import LogisticRegression #导入逻辑回归模型
lr = LogisticRegression() # lr,就代表是逻辑回归模型
lr.fit(X_train,y_train) # fit,就相当于是梯度下降
print("SK-learn逻辑回归测试准确率{:.2f}%".format(lr.score(X_test,y_test)*100))

学习机器学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
…
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- android:clickable=“false“无效,依然能被点击
- 将vue项目打包成桌面客户端实现点击桌面图标直接进入项目
- Postgres 中文周报:PostgreSQL 2023 热门回顾
- 微前端:一种新型的前端架构方法
- Python字典详解
- HarmonyOS-LocalStorage:页面级UI状态存储
- Cdd诊断数据控中的zz rc yy
- SSH原理
- Note of CLEAN CODE chapter 2 - Meaningful Name
- 知识库建设教程来啦,赶紧收藏起来