std::atomic<int>的原理
发布时间:2024年01月14日
??WARNING??
注意:
试验平台是CentOS7,x86_64,Intel Xeon CPU
不同平台原理大不相同!
[mzhai@include]$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 1
On-line CPU(s) list: 0
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel? Xeon? Gold 6242R CPU @ 3.10GHz
试验程序
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
std::atomic_int acnt;
int cnt;
void f()
{
for (int n = 0; n < 10000; ++n)
{
++acnt;
++cnt;
// Note: for this example, relaxed memory order
// is sufficient, e.g. acnt.fetch_add(1, std::memory_order_relaxed);
}
}
void g(){
acnt.fetch_add(1,std::memory_order_relaxed);
acnt.fetch_add(1,std::memory_order_consume);
acnt.fetch_add(1,std::memory_order_acquire);
acnt.fetch_add(1,std::memory_order_release);
acnt.fetch_add(1,std::memory_order_acq_rel);
}
int main()
{
std::vector<std::thread> pool;
for (int n = 0; n < 10; ++n)
pool.emplace_back(f);
for(auto&& t:pool){
t.join();
}
std::cout << "The atomic counter is " << acnt << '\n'
<< "The non-atomic counter is " << cnt << '\n';
g();
}
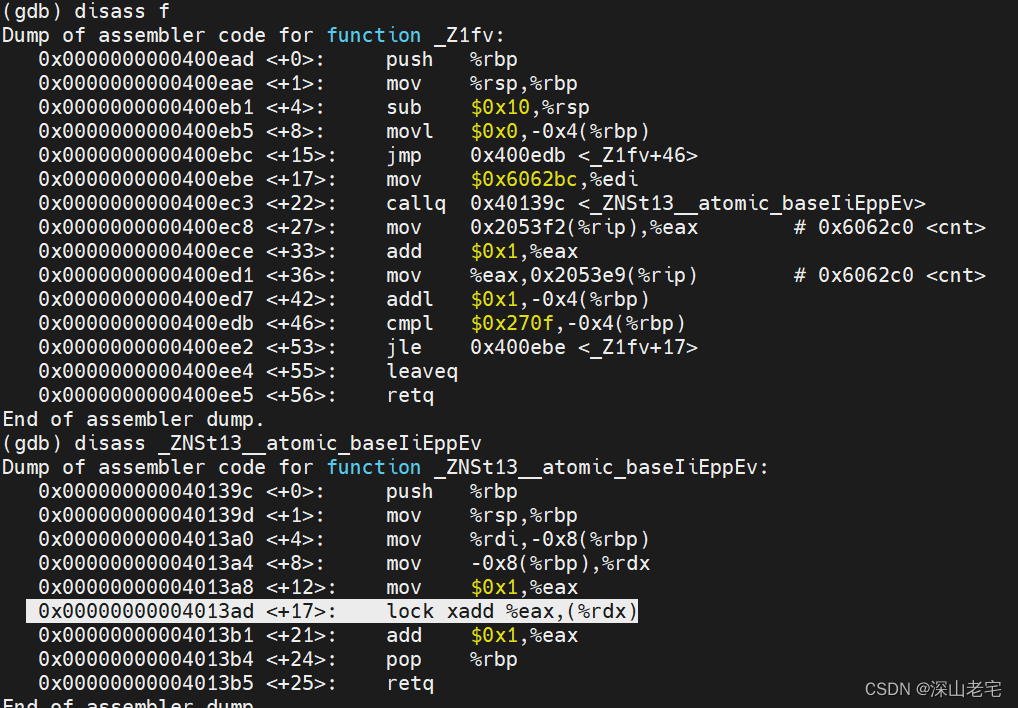
先看atomic++操作:
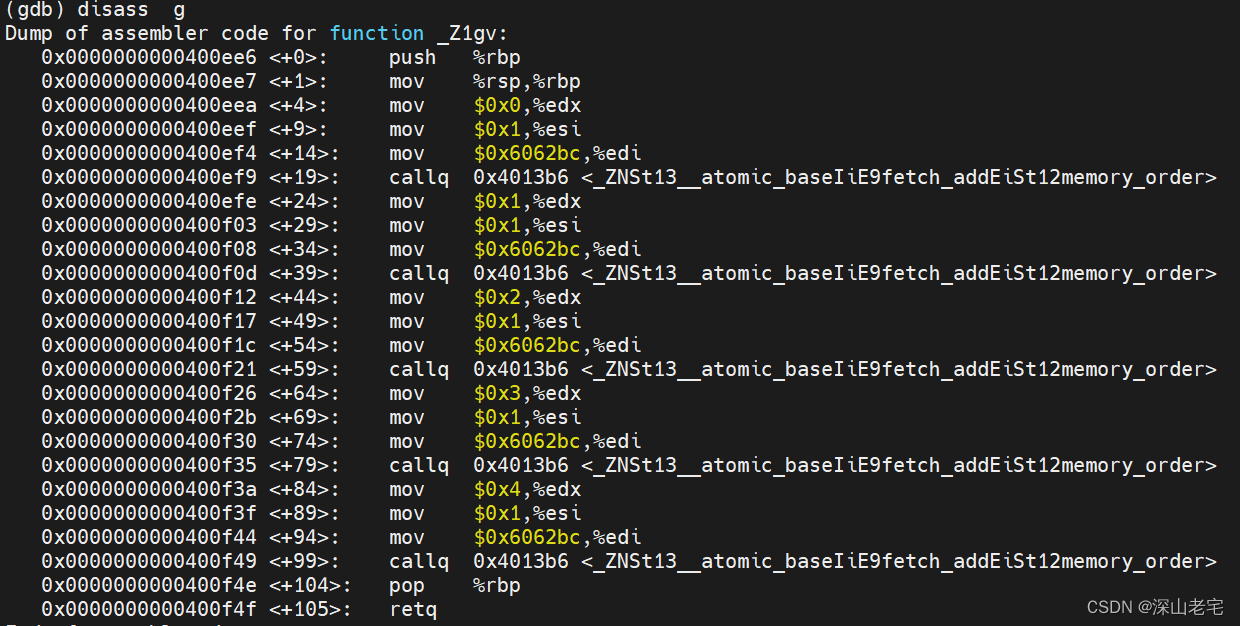
再看fetch_add:
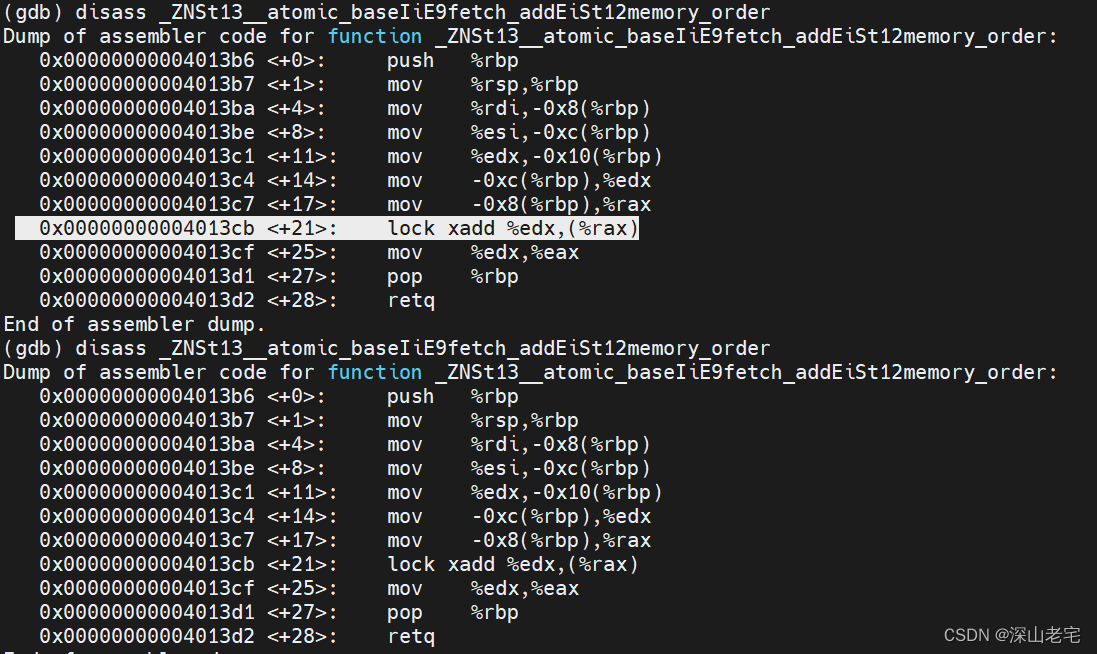
结论
很明显所有加法操作,++,fetch_add, 不论用什么memory order底层都是用lock xadd指令实现的。
over
文章来源:https://blog.csdn.net/zhaiminlove/article/details/135586353
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Spring IOC之Condition 接口
- vscode代码片段记录 C#
- linux ubuntu常用命令大总结(1)
- 代码随想录算法训练营第60天|84.柱状图中最大的矩形
- 【复现】奥威亚视屏云平台文件读取漏洞_27
- 红帽宣布CentOS 7和RHEL 7将在2024年6月30日结束支持,企业面临紧迫的迁移压力!
- 鹧鸪云光伏系统免费版上线,100%源码部署
- 软件测试/测试开发丨Web自动化测试策略
- 响应式Web开发项目教程(HTML5+CSS3+Bootstrap)第2版 第1章 HTML5+CSS3初体验 项目1-1 三栏布局页面
- 【C++】POCO学习总结(十四):引用计数、共享指针、缓冲区管理