猫狗大战(猫狗识别)
1.问题简介
1.1问题描述
????????在这个问题中,你将面临一个经典的机器学习分类挑战——猫狗大战。你的任务是建立一个分类模型,能够准确地区分图像中是猫还是狗。?
1.2预期解决方案
????????你的目标是通过训练一个机器学习模型,使其在给定一张图像时能够准确地预测图像中是猫还是狗。模型应该能够推广到未见过的图像,并在测试数据上表现良好。我们期待您将其部署到模拟的生产环境中——这里推理时间和二分类准确度(F1分数)将作为评分的主要依据。
1.3数据集
????????链接:百度网盘 请输入提取码
????????提取码:jc34
2.数据处理
2.1数据集特征

?2.2数据预处理
2.3数据集划分
? ? ? ? 猫狗分类:图片数据集的命名方式是 type.num.jpg,首先根据train目录下的文件名称前缀识别动物类别,并且将其放入对应文件夹(cat、dog)中。
# 指定目录
source_dir = './dataset/train'
dogs_dir = './train_data/dog'
cats_dir = './train_data/cat'
# 创建目标目录
os.makedirs(dogs_dir, exist_ok=True)
os.makedirs(cats_dir, exist_ok=True)
# 获取目录下所有文件
files = os.listdir(source_dir)
# 遍历文件
for file in files:
# 根据前缀分类
if file.startswith('dog'):
shutil.move(os.path.join(source_dir, file), os.path.join(dogs_dir, file))
elif file.startswith('cat'):
shutil.move(os.path.join(source_dir, file), os.path.join(cats_dir, file))

? ? ? ? 划分测试集:由于需要测试数据验证模型好坏,将从cat与dog目录中随机取出20%的数据作为测试集。
# 源目录路径
src_dir = './train_data'
# 目标目录路径
dst_dir = './test_data'
# 确保目标目录存在
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
# 遍历源目录下的cat和dog子目录
for animal in ['cat', 'dog']:
src_animal_dir = os.path.join(src_dir, animal)
dst_animal_dir = os.path.join(dst_dir, animal)
# 确保动物子目录在目标目录下存在
if not os.path.exists(dst_animal_dir):
os.makedirs(dst_animal_dir)
# 获取源目录下所有图片文件
img_files = [f for f in os.listdir(src_animal_dir) if os.path.isfile(os.path.join(src_animal_dir, f)) and f.endswith(('.jpg', '.png', '.jpeg'))]
# 计算需要移动的图片数量(20%)
num_to_move = int(len(img_files) * 0.2)
# 随机选取20%的图片
selected_files = random.sample(img_files, num_to_move)
# 移动选中的图片到目标目录
for file in selected_files:
src_file_path = os.path.join(src_animal_dir, file)
dst_file_path = os.path.join(dst_animal_dir, file)
shutil.move(src_file_path, dst_file_path)
print("已完成图片迁移操作!")
2.4数据加载器的构建?
数据预处理:transforms.Compose类定义了一系列图像转换操作。
????????注意:标签是由ImageFolder类通过目录结构自动获取的。ImageFolder会将cat和dog作为标签,内部创建一个字典来映射类别名称到索引,并且每个子目录中的图片都将被标记为相应的类别,如{'cat': 0, 'dog': 1}。
# 数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 数据集路径
train_dir = './train_data'
# 创建ImageFolder实例时,使用filter参数来排除不需要的文件夹
train_dataset = ImageFolder(train_dir, transform=transform)
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True, num_workers=4)
# 数据长度
print(len(train_dataset))
# 标签
# print(train_dataset.classes) # 输出: ['cat', 'dog']
print(train_dataset.class_to_idx) # 输出: {'cat': 0, 'dog': 1}? ? ? ? ?报错:有可能出现错误——在遍历加载图片使,遇见了“.ipynb_checkpoints”,具体产生原因未知。
# 通常.ipynb_checkpoints 是 Jupyter Notebook 的自动保存副本存放位置
# 查找 .ipynb_checkpoints 目录并删除(包括其所有子文件和子目录)
checkpoints_path = os.path.join(train_dir, '.ipynb_checkpoints')
if os.path.exists(checkpoints_path):
shutil.rmtree(checkpoints_path)
else:
print(f"The directory '{checkpoints_path}' does not exist and therefore cannot be removed.")数据加载器——训练集:

数据加载器——测试集:

?3.猫狗分类器设计
3.1模型选择
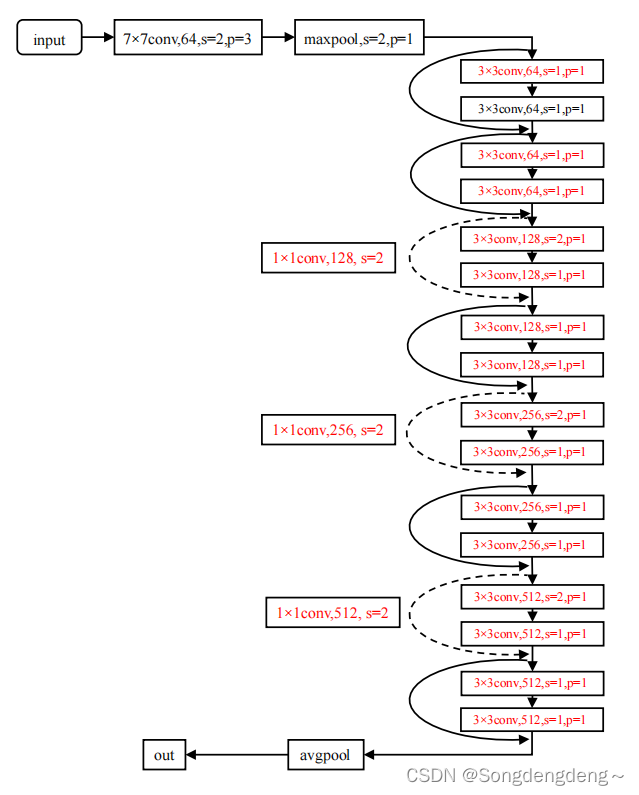
????????ResNet18是深度残差网络(Residual Network)的一个具体实现。该网络架构的设计目的是为了缓解随着网络深度增加带来的梯度消失和训练困难问题。ResNet通过引入“残差块”(Residual Block)结构来改进传统的卷积神经网络(CNN),使得网络能够更容易地学习到更深层次的特征表达。ResNet18之所以得名,是因为它有18层深(不包括输入层和输出层),其深层设计得益于残差连接机制。这种结构使得网络可以轻易地构建超过100层甚至更深,而不会遇到梯度消失或梯度爆炸的问题,因此它具有很强的深度可扩展性。所以本次研究选用了 ResNet18模型。
3.2平台搭建
硬件平台
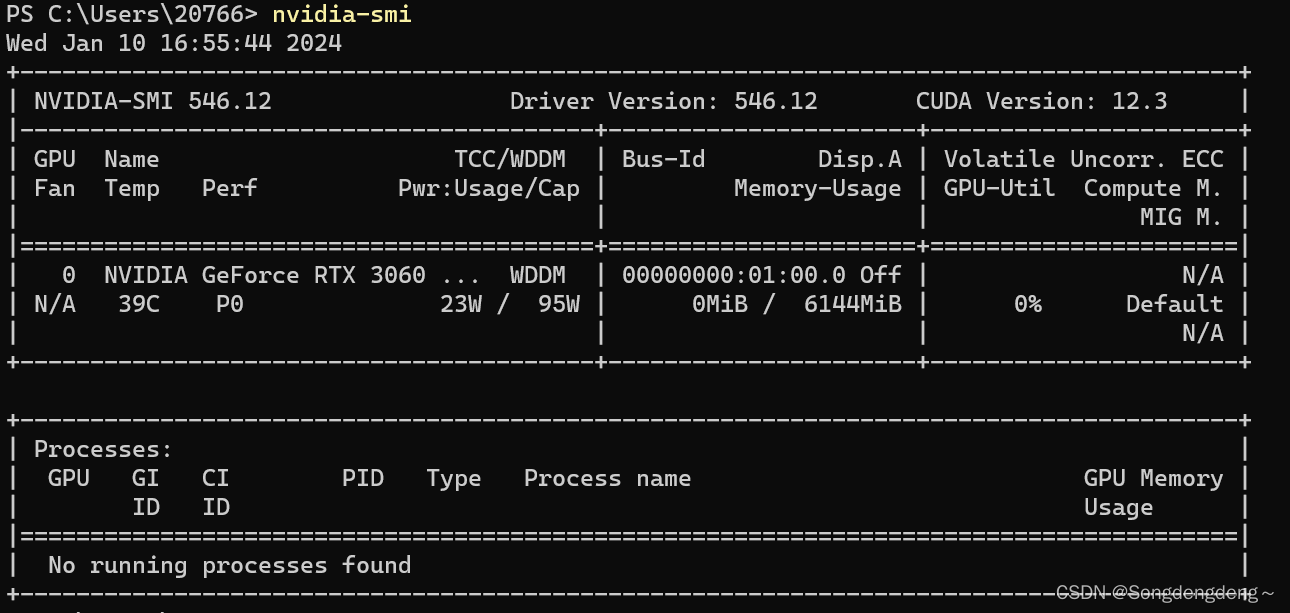
本研究采用NVIDIA GeForce RTX 3060 GPU作为主要的计算硬件平台。该GPU基于先进的NVIDIA Ampere架构设计,拥有强大的并行处理能力和高效能的显存系统。GeForce RTX 3060配备了充足的CUDA核心以支持大规模的数据并行计算任务,并且内建RT Core与Tensor Core技术,为深度学习模型训练提供实时光线追踪加速以及DLSS等AI运算优化能力。
软件栈
在软件层面,我们选择了PyTorch开源深度学习框架作为主要的开发工具。PyTorch以其灵活动态的计算图特性、直观易用的API以及丰富的社区资源而著称,特别适合于科研探索与原型开发。通过集成对CUDA和cuDNN库的支持,PyTorch能够在NVIDIA GeForce RTX 3060 GPU上充分利用硬件加速优势,实现高效的深度学习模型训练与推断。
??
3.3ResNet的主要优势
? ? ? ? ResNet的设计主要针对解决随着网络深度增加而出现的训练困难问题,如梯度消失和爆炸问题,这些问题使得在网络加深后准确率不再提升甚至下降。
????????ResNet引入了残差块(Residual Block)的概念:一个残差块包含多个卷积层,其核心思想是引入“快捷连接”或“跳跃连接”,允许信息直接从输入跳过一些中间层传递到输出。通过构建由多个残差块堆叠而成的网络,ResNet能够实现上百层的深度。
? ? ? ? 解决退化现象:线性转换是关键目标,它将数据映射到高纬空间以便于更好的完成“数据分类”。随着网络深度的不断增大,所引入的激活函数也越来越多,数据被映射到更加离散的空间,此时已经难以让数据回到原点(恒等变换)。或者说,神经网络将这些数据映射回原点所需要的计算量,已经远远超过我们所能承受的。
????????退化现象让我们对非线性转换进行反思,非线性转换极大的提高了数据分类能力,但是,随着网络的深度不断的加大,我们在非线性转换方面已经走的太远,竟然无法实现线性转换。显然,在神经网络中增加线性转换分支成为很好的选择,于是,ResNet团队在ResNet模块中增加了快捷连接分支,在线性转换和非线性转换之间寻求一个平衡。
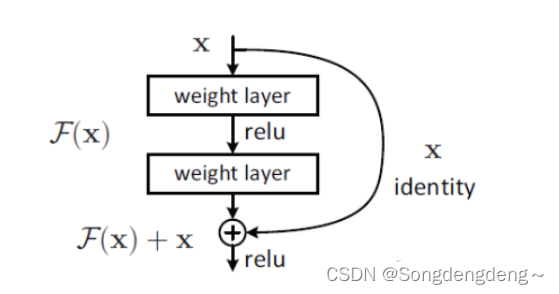
3.4自定义网络架构
? ? ? ? 基础的猫狗大战问题属于二分类问题,因此最后输出层输出大小为2。
model = torchvision.models.resnet18(pretrained=False)
num_features = model.fc.in_features
# 加载预训练的模型
model.load_state_dict(torch.load("./resnet18-f37072fd.pth"))
# print(model)
# 输出类别数等于数据集类别数
model.fc = nn.Linear(num_features, len(train_dataset.classes)) 4.模型训练
4.1模型基本参数设置
# 设定设备(GPU或CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)4.2模型训练
? ? ? ? 为了提高效率,首先在本机的GPU上进行模型的训练。
# 训练
# 使用预训练的ResNet18,并且只修改最后一层适应我们的分类任务(假设类别数为2:dog和cat)
model = torchvision.models.resnet18(pretrained=False)
num_features = model.fc.in_features
# 加载预训练的模型
model.load_state_dict(torch.load("./resnet18-f37072fd.pth"))
# print(model)
model.fc = nn.Linear(num_features, len(train_dataset.classes)) # 输出类别数等于数据集类别数
# 设定设备(GPU或CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 训练轮数
num_epochs = 1
i=0
# 计时
start_time = time.time() # 记录开始时间
for epoch in range(num_epochs):
model.train() # 设置模型为训练模式
print("num:",epoch)
for inputs, labels in train_loader:
print(i, end=" ")
i+=1
inputs, labels = inputs.to(device), labels.to(device) # 将数据转移到设备上
optimizer.zero_grad() # 清零梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新权重
print(f'Epoch {epoch + 1}/{num_epochs}, Loss: {loss.item():.4f}')
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start_time
print(f'轮数{epoch} 训练集用的时间为: {elapsed_time:.2f} seconds')
如果直接使用cpu:

4.3训练结果

4.4保存模型
# 在训练完成后保存模型权重
torch.save(model.state_dict(), './my_model_weights.pth')
# 若要加载保存的模型权重
# 加载模型架构
model = torchvision.models.resnet18(pretrained=False)
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, len(train_dataset.classes))
# 将模型加载到GPU或CPU上
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 加载之前保存的权重
model.load_state_dict(torch.load('./my_model_weights.pth'))
# 保存和加载整个模型(包括模型结构和权重),可以这样做:
# 保存整个模型
torch.save(model, './my_model.pth')
# 加载整个模型
# model = torch.load('./my_model.pth', map_location=device) 效果演示:?

5.将模型移植至intel 云平台
5.1加载模型
? ? ? ? 保存模型后将其上传至云平台,再加载模型至云平台上运行。

device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load('./my_model.pth', map_location=device) ?5.3预测结果

5.4公共测试集预测结果?
? ? ? ? 后续补发了公共测试集:猫狗数据各500张。


?
6.可视化模型预测
6.1自定义数据
? ? ? ? 方式:从抖音获取截图。
?
? ? ? ? 6.2模型尝试分类
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load('./my_model.pth', map_location=device)
model.eval() # 设置模型为评估模式
# 定义测试图像的路径
test_image_path = './free_test/tiktokCat.jpg'
# 定义图像预处理的变换
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载测试图像
test_image = Image.open(test_image_path)
plt.imshow(test_image)
#变换
test_image = transform(test_image).unsqueeze(0) # 添加一个批次维度
start_time = time.time() # 记录开始时间
# 进行预测
with torch.no_grad(): # 测试阶段不需要计算梯度
output = model(test_image)
# 概率大的解释预测结果
_, predicted = torch.max(output, 1)
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start_time
print(f'预测一张自定义图片所用的时间为: {elapsed_time:.2f} seconds')
# 根据类别数量,我们可以直接映射
predicted_label = predicted.item()
# cat: 0, dog: 1
if predicted_label == 0:
predicted_class_name = 'cat'
else:
predicted_class_name = 'dog'
# print(f'Predicted: {predicted_class_name}')
plt.axis('off')
plt.title("Predicted: "+predicted_class_name)
plt.show()
print(predicted_class_name)6.3预测结果


7.使用OneAPI组件
????????Intel oneAPI 是一个跨行业、开放、基于标准的统一的编程模型,旨在提供一个适用于各类计算架构的统一编程模型和应用程序接口。也就是说,应用程序的开发者只需要开发一次代码,就可以让代码在跨平台的异构系统上执行,底层的硬件架构可以是CPU、GPU、FPGA、神经网络处理器,或者其他针对不同应用的硬件加速器等等。由此可见,oneAPI既提高开发效率,又可以具有一定的性能可移植性。
?
7.1使用Intel Extension for PyTorch进行优化
简介:
????????Intel Extension for PyTorch(也称为IPEX)是Intel为PyTorch深度学习框架开发的一系列优化库,旨在提高在Intel架构上的性能表现,特别是针对CPU和GPU(如Intel Xeon和Intel Data Center GPU Flex Series)。这个扩展提供了以下功能:
**自动混合精度**:对于支持的硬件平台,可能包括自动混合精度训练功能,通过动态地将部分计算从单精度浮点(FP32)转换到半精度浮点(FP16),从而减少内存占用并加速计算。
使用Intel Extension for PyTorch可以简化代码调整过程,并且无需大量修改现有PyTorch代码即可获得显著性能提升。只需导入相应的库并调用特定函数或方法,就可以利用这些优化特性。
# 将模型移动到CPU
# print(model)
device = torch.device('cpu')
model.to(device)
model = torch.load('./my_model.pth', map_location=device)
# 重新构建优化器
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
# 使用Intel Extension for PyTorch进行优化
my_model, optimizer = ipex.optimize(model=model, optimizer=optimizer, dtype=torch.float32)
保存优化模型
# 保存模型参数
torch.save(my_model.state_dict(), 'my_model_optimized.pth')
# 加载模型参数
my_model.load_state_dict(torch.load('my_model_optimized.pth'))
优化结果:


?
7.2使用 Intel? Neural Compressor 量化模型?
# 将模型移动到CPU
model.load_state_dict(torch.load('my_model_optimized.pth'))
model.to('cpu') # 将模型移动到 CPU
model.eval()
model.eval()
# 定义评估函数
def eval_func(model):
with torch.no_grad():
y_true = []
y_pred = []
for inputs, labels in train_loader:
inputs = inputs.to('cpu')
labels = labels.to('cpu')
outputs = model(inputs)
_, predicted = torch.max(outputs, 1)
# print(predicted,labels,end=" ")
y_pred.extend(predicted.cpu().tolist())
y_true.extend(labels.cpu().tolist())
return accuracy_score(y_true, y_pred)
# 配置量化参数
conf = PostTrainingQuantConfig(backend='ipex', # 使用 Intel PyTorch Extension
accuracy_criterion=AccuracyCriterion(higher_is_better=True,
criterion='relative',
tolerable_loss=0.01))
start_time = time.time() # 记录开始时间
# 执行量化
q_model = quantization.fit(model,
conf,
calib_dataloader=train_loader,
eval_func=eval_func)
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start_time
print(f'量化用时: {elapsed_time:.2f} seconds')
# 保存量化模型
quantized_model_path = './quantized_models'
if not os.path.exists(quantized_model_path):
os.makedirs(quantized_model_path)
q_model.save(quantized_model_path)
量化结果:

?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python将普通图像转化为栅格影像
- Shutter Encoder多媒体转换v17.8
- 【OpenCV学习笔记17】- 平滑图像
- Elasticsearch:升级到 elasticsearch-py 8.x 的 10 个理由
- 自然语言处理--概率最大中文分词
- 一套rk3588 rtsp服务器推流的 github 方案及记录 -02
- 【重点问题】攻击面发现及管理
- 基于web的电影院购票系统
- 【ECON30001】Advanced Microeconomics
- Gin入门指南:从零开始快速掌握Go Web框架Gin