Elasticsearch基本使用
文章目录
概要
Elaticsearch简称为ES,是一个开源的可扩展的分布式的全文检索引擎,它可以近乎实时的存储、检索数据。本身扩展性很好,可扩展到上百台服务器,处理PB级别的数据。
本文基于7.x版本,总结ES常用的基本操作。
相关链接:
官网
es版本与jvm版本
下载地址
Rest风格API
Java客户端API
一、核心概念
Elasticsearch是基于Lucene的全文检索引擎,本质也是存储和检索数据。ES中的很多概念与MySQL类似 可以按照关系型数据库的经验去理解。
索引(index)
类似的数据放在一个索引,非类似的数据放不同索引, 一个索引也可以理解成一个关系型数据库。
类型(type)
代表document属于index中的哪个类别(type)
type就像是数据库的表,比如dept表,user表。
注意ES每个大版本之间区别很大:
ES 5.x中一个index可以有多种type。
ES 6.x中一个index只能有一种type。
ES 7.x以后 逐渐移除type这个概念。
映射(mapping)
mapping定义了每个字段的类型等信息,相当于关系型数据库中的表结构。
常用数据类型: text、keyword、number、array、range、boolean、date、geo_point、ip、nested、object
| MySQL | Elasticsearch |
|---|---|
| 数据库Database | 索引index |
| 表Table | 索引index类型(type) |
| 数据行Row | 文档Document |
| 数据列Column | 字段Field |
| 约束Schema | 映射Mapping |
二、索引操作
Elasticsearch采用Rest风格API,因此其API就是一次http请求,你可以用任何工具发起http请求
2.1 创建索引
语法:
PUT /索引名称
{
"settings":{
"属性名":"属性值"
}
}
settings:索引库设置,可以定义索引库的属性,例如:分片数、副本数;也可以不设置,采用默认属性。
示例:

2.2 判断索引是否存在
语法:
HEAD/索引名称
示例:

2.3 查看索引
查看单个索引
语法:
GET /索引名称
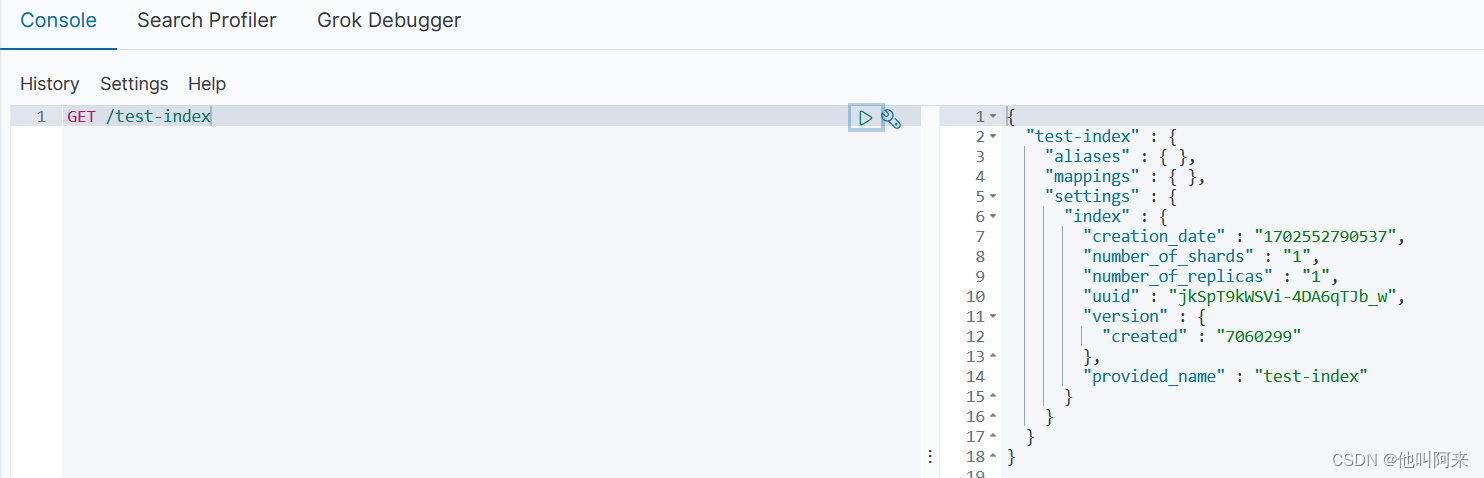
批量查看索引
GET /索引名称1,索引名称2...
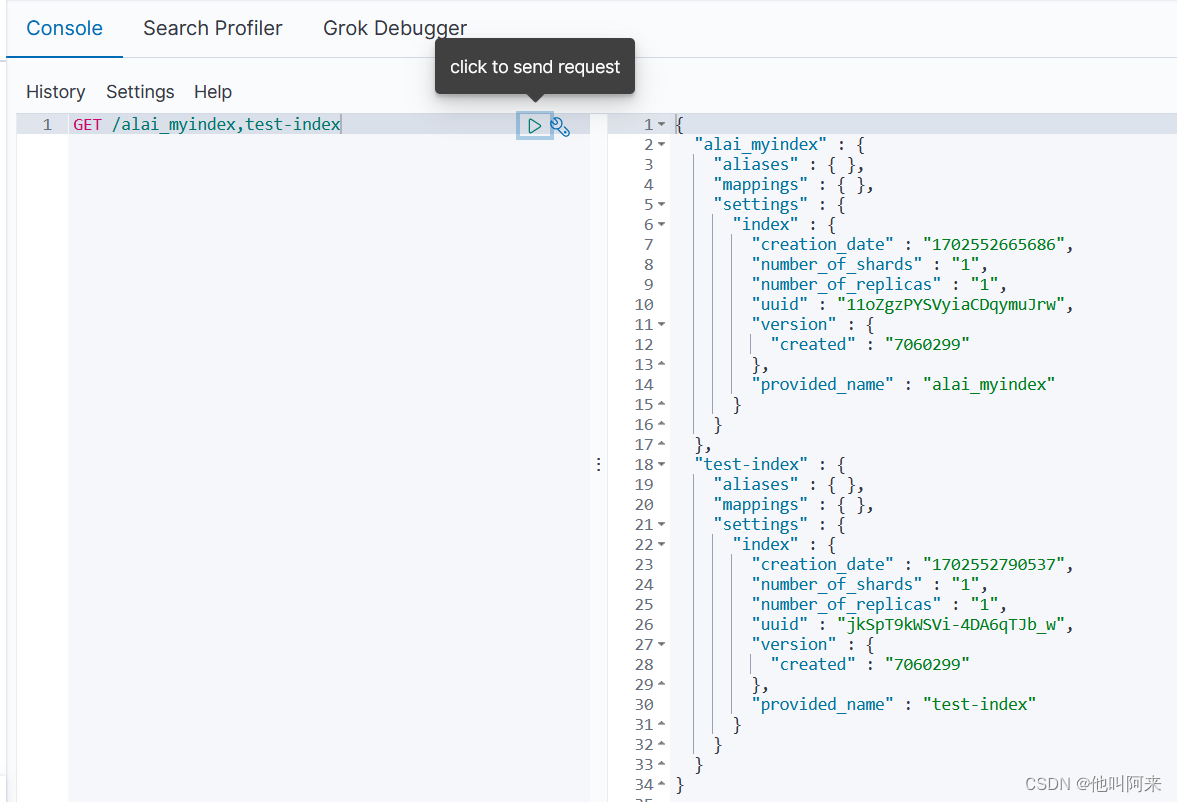
查看所有索引
方式一:
GET _all
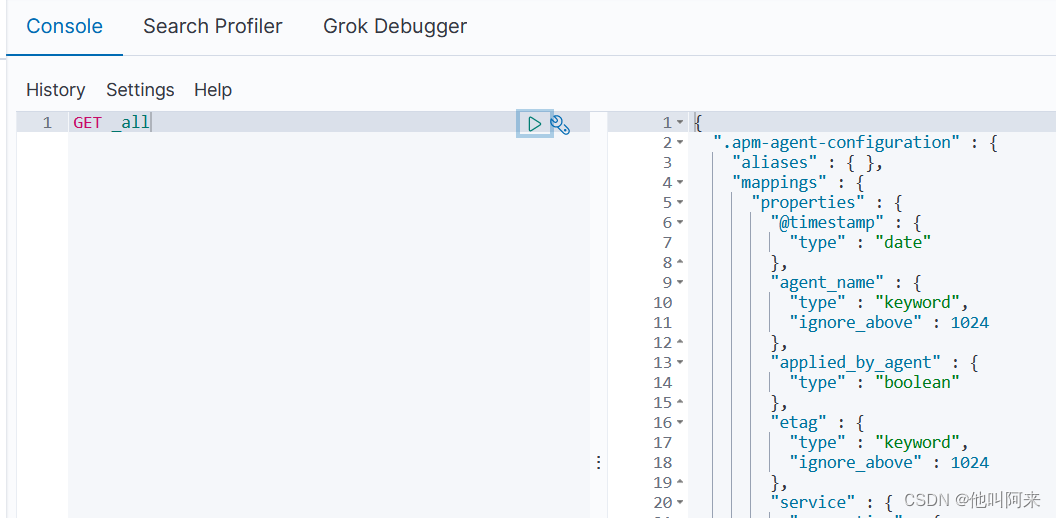
方式二:
GET /_cat/indices?v
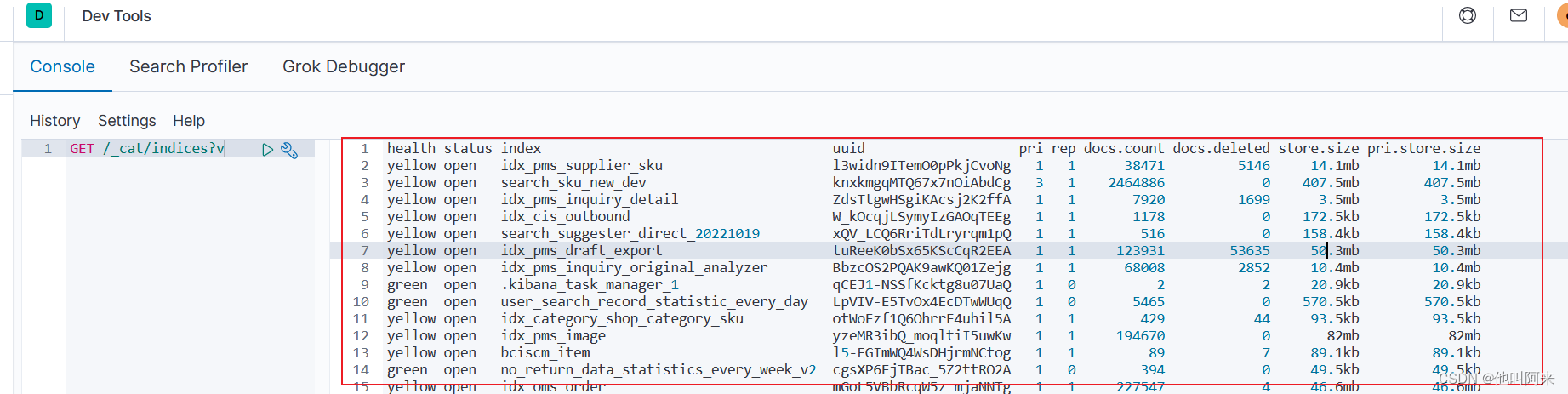
green:索引的所有分片都正常分配。
yellow:至少有一个副本没有得到正确的分配。
red:至少有一个主分片没有得到正确的分配。
2.4 打开、关闭索引
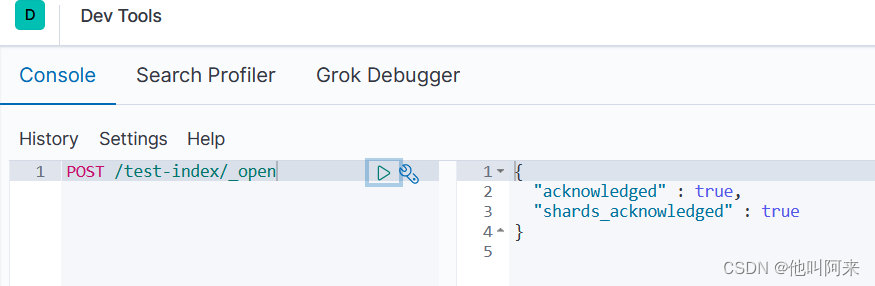
打开:
POST /索引名称/_open
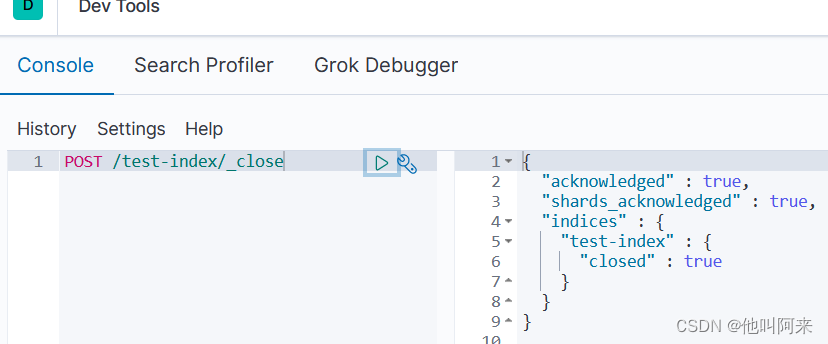
关闭
POST /索引名称/_close
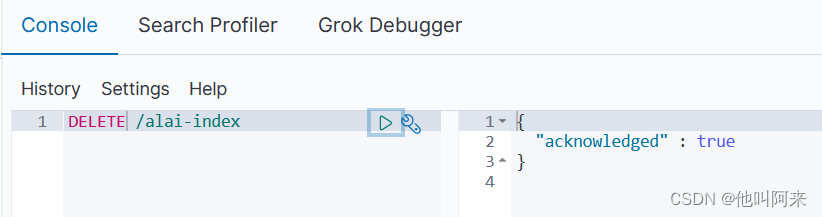
2.5 删除索引
DELETE /索引名称1,索引名称2...
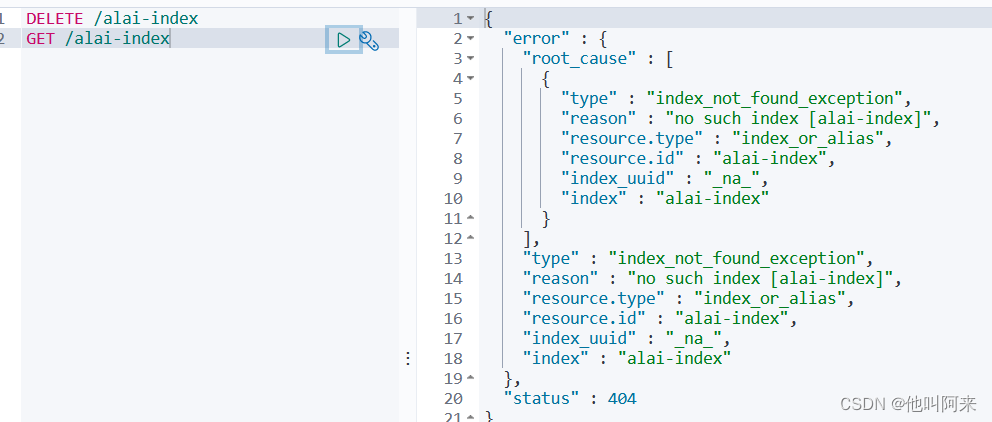
再次查看
三、映射操作
索引创建之后,等于有了关系型数据库中的database。Elasticsearch7.x取消了索引type类型的设置,不允许指定类型,默认为_doc,但字段仍然是有的,需要设置字段的约束信息,叫做字段映射
(mapping)
字段的约束包括但不限于:
- 字段的数据类型
- 是否要存储
- 是否要索引
- 分词器
3.1 创建映射字段
PUT /test-index/_mapping
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}
字段名:跟mysql的字段一样,由用户命名
属性,例如:
type:类型,可以是text、long、short、date、integer、object等index:是否索引,默认为truestore:是否存储,默认为falseanalyzer:指定分词器
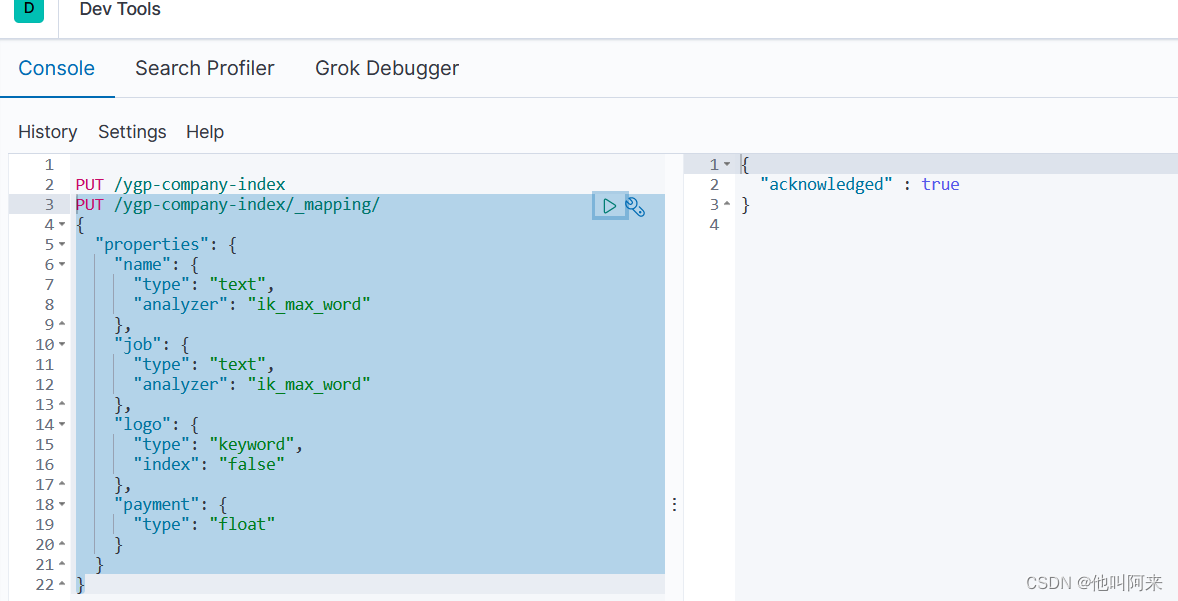
PUT /ygp-company-index
PUT /ygp-company-index/_mapping/
{
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"job": {
"type": "text",
"analyzer": "ik_max_word"
},
"logo": {
"type": "keyword",
"index": "false"
},
"payment": {
"type": "float"
}
}
}
3.2 映射属性详解
type
Elasticsearch支持的数据类型非常丰富:
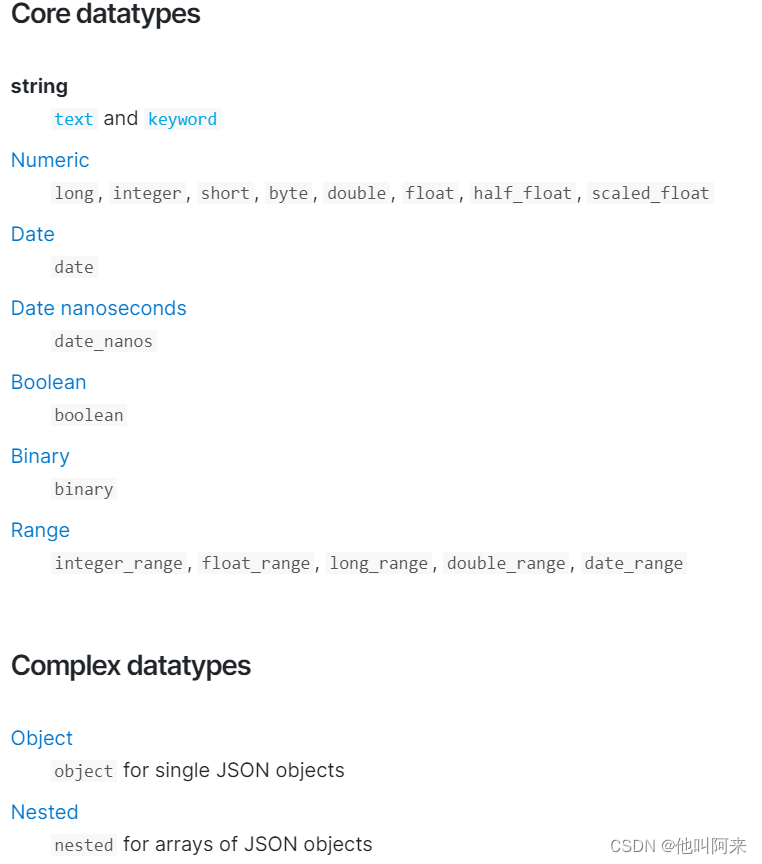
这里挑选比较关键的进行说明
-
String类型,可分为两种
- text: 可分词,不可参与聚合
- keywork: 不可分词,数据作为完整字段进行匹配,可以参与聚合
-
Numerical:数值类型,分两类
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型: scaled_float
-
Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议存储为毫秒,存储为long,节省空间。 -
Array: 数组类型
- 进行匹配时,任意一个元素满足,都认为满足
- 排序时,如果升序则用数组中最小值来排序,如果降序则用数组中的最大值来排序
-
Object:对象
{
"name":"Tome",
"age": 20,
"girl":{
"name":"Rose","age":20,
}
}
如果存储到索引库的是对象类型,例如上面的girl,会把girl变成两个字段:girl.name和girl.age
index
index影响字段的索引情况:
- true:字段会被索引,则可以用来进行搜索。默认值就是true。
- false:字段不会被索引,不能用来搜索
store
是否将数据进行独立存储
原始的文本会存储在_source里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source里面提取出来的,页可以独立存储某个字段,设置store:true;获取独立存储的字段要比从_source中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置,默认为false。
analyzer
指定分词器
一般处理中文会选择ik分词器:ik_max_word、ik_smart
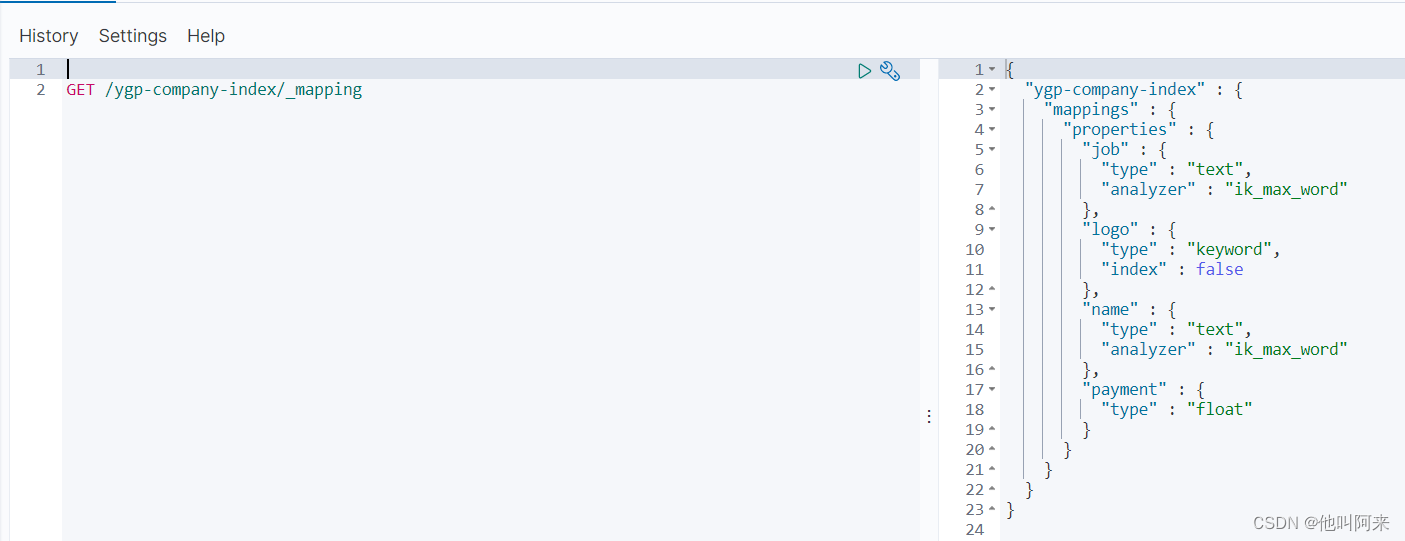
3.3 查看映射关系
查看单个索引映射关系
GET /索引名称/_mapping
查看多个索引的映射
# 方式一
GET _mapping
# 方式二
GET all/_mapping
修改索引映射关系
PUT /索引名/_mapping
PUT /ygp-company-index/_mapping
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}
同时创建索引和设置映射
PUT /mcs-index
{
"settings": {
"索引库属性名": "索引库属性值"
},
"mappings": {
"properties": {
"字段名": {
"映射属性名": "映射属性值"
}
}
}
}
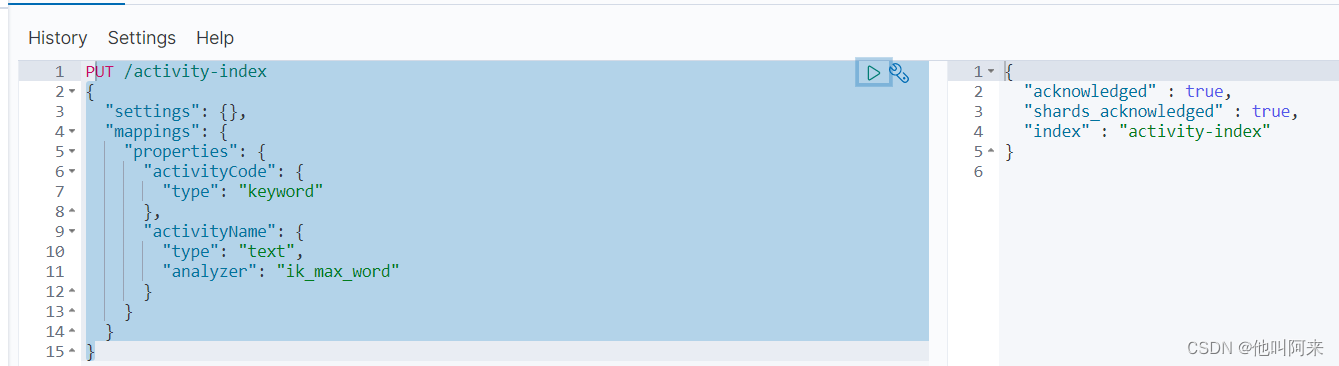
使用示例
PUT /activity-index
{
"settings": {},
"mappings": {
"properties": {
"activityCode": {
"type": "keyword"
},
"activityName": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
四、文档增删改查
文档,即数据库中的数据,会根据规则创建索引,将来用于搜索;可以类比数据库中的一行数据。
4.1 新增文档
新增文档,id的生成方式有两种,手动指定或者自动生成。
新增文档(手动指定)
POST /索引名称/_doc/{id}
{
"field":"value"
}
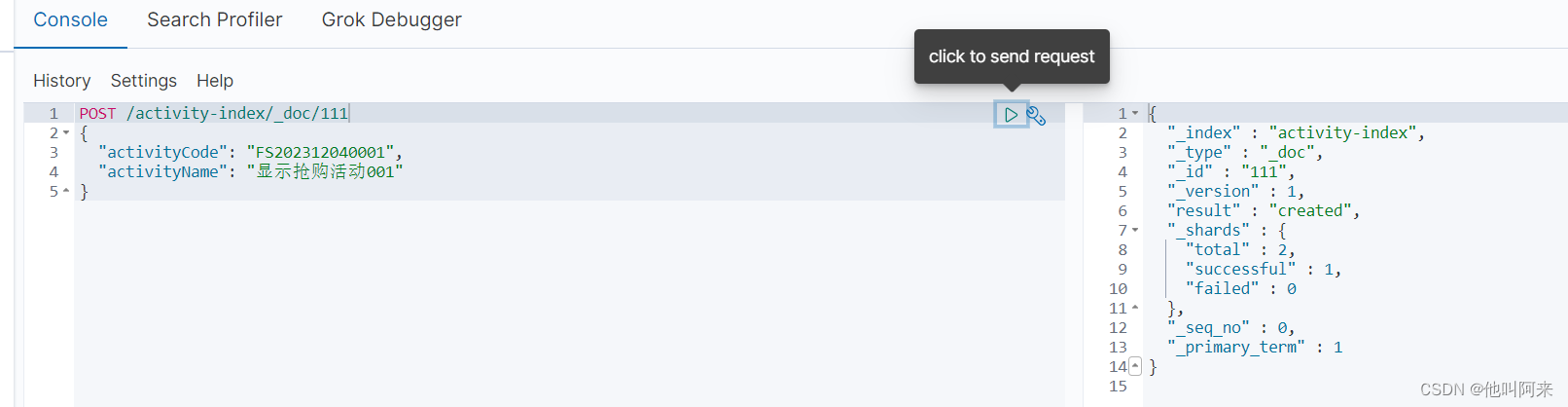
新增文档(自动生成id)
POST /索引名称/_doc
{
"field":"value"
}
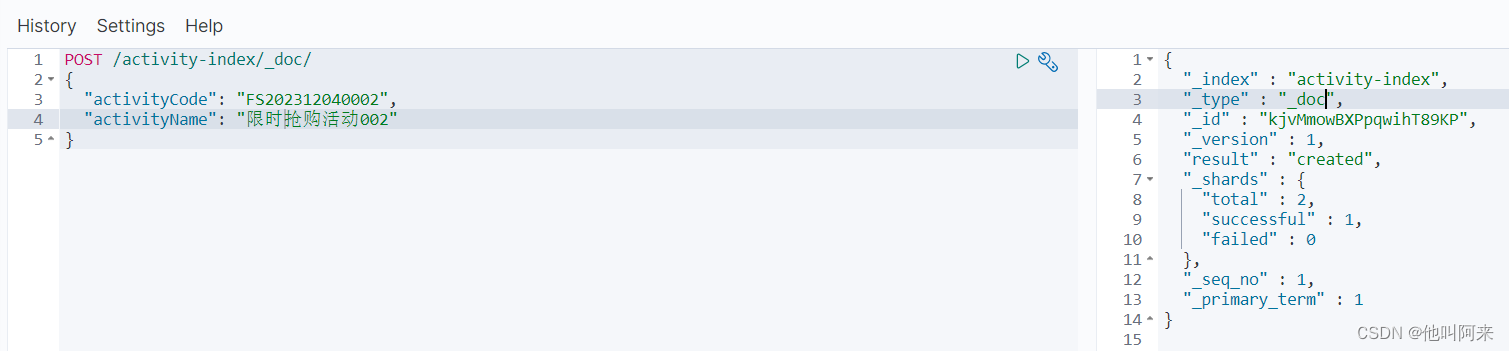
可以看到结果显示为: created ,代表创建成功。
另外,需要注意的是,在响应结果中有个 _id 字段,这个就是这条文档数据的 唯一标识 ,以后的增删改查都依赖这个_id作为唯一标示,这里是Elasticsearch帮我们随机生成的id
4.2 查看单个文档
GET /索引名称/_doc/{id}
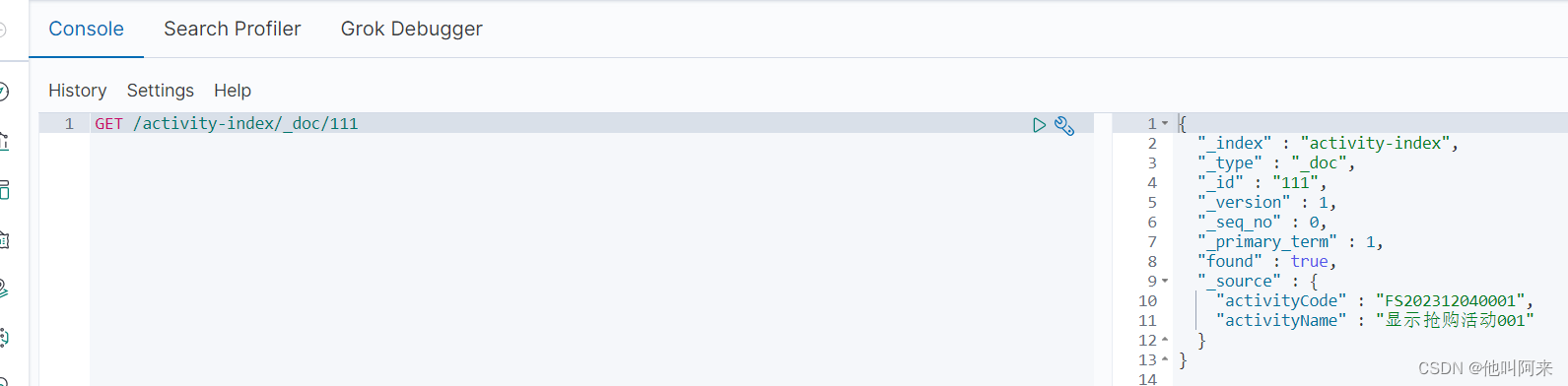
文档元数据解读:
| 元数据项 | 含义 |
|---|---|
| _index | document所属的index |
| _type | document所属的type,Elasticsearch7.x默认type为_doc |
| _id | 代表document的唯一标识,与index一起,可以唯一标识和定位一个document |
| _version | document的版本号,Elasticsearch利用_version (版本号)的方式来确保应用中相互冲突的变更不会导致数据丢失。需要修改数据时,需要指定想要修改文档的version号,如果该版本不是当前版本号,请求将会失败 |
| _seq_no | 严格递增的顺序号,每个document一个,严格递增,保证后写入的doc的_seq_no大于先写入的_seq_no |
| _primary_term | 任何类型的写操作,包括index、create、update和Delete,都会生成一个_seq_no。 |
| found | true/false 是否查找到文档 |
| _source | 存储原始文档 |
4.3 查看所有文档
POST /索引名称/_search
{
"query": {
"match_all": {}
}
}

4.4 _source定制返回字段
某些业务场景下,我们不需要搜索引擎返回_source中的所有字段,可以使用source进行定制,如下,多个字段之间使用逗号分隔
GET /activity-index/_doc/111?_source=activityCode
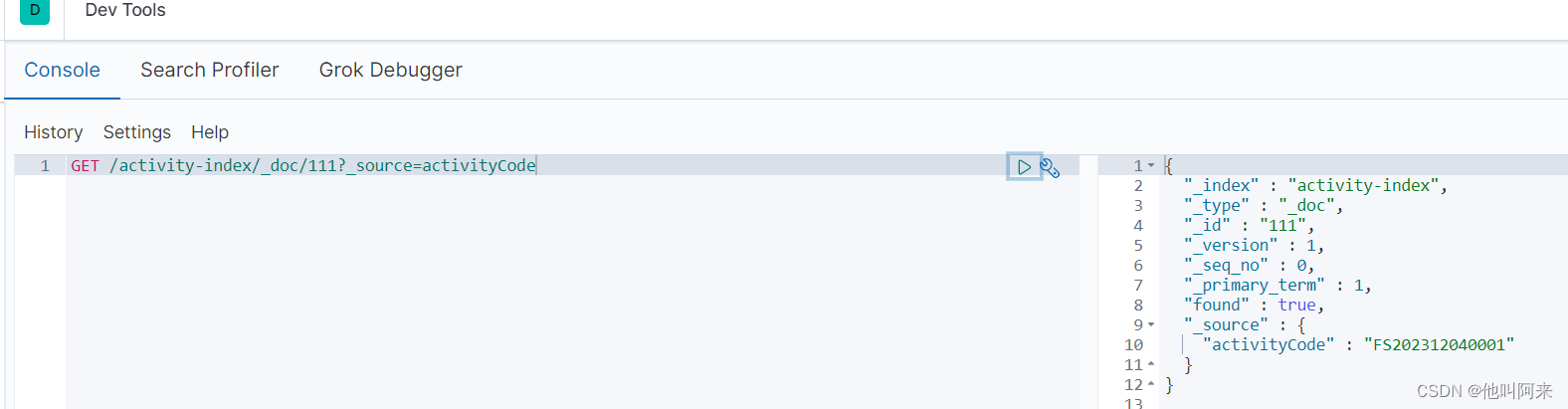
4.5 更新文档
全部更新
更新文档为PUT操作,更新时需要指定id
- id对应的文档存在,则修改
- id对应的文档不存在,则新增
PUT /activity-index/_doc/3
{
"activityCode": "FS202312240003",
"activityName": "限时抢购活动003"
}
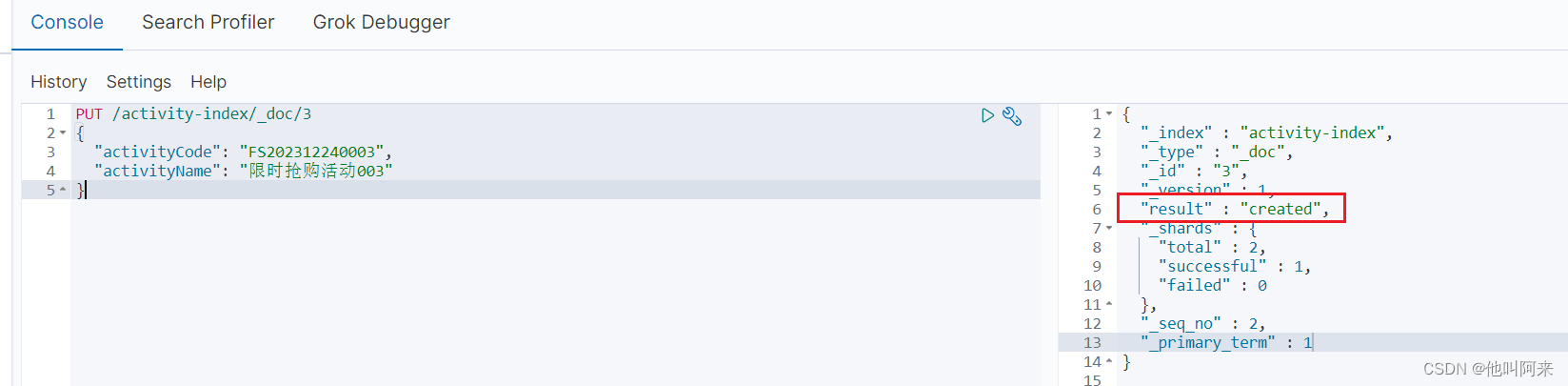
id=3这条记录不存在,返回的_result属性显示的时创建
再次执行上面的命令,并将数据修改一下:
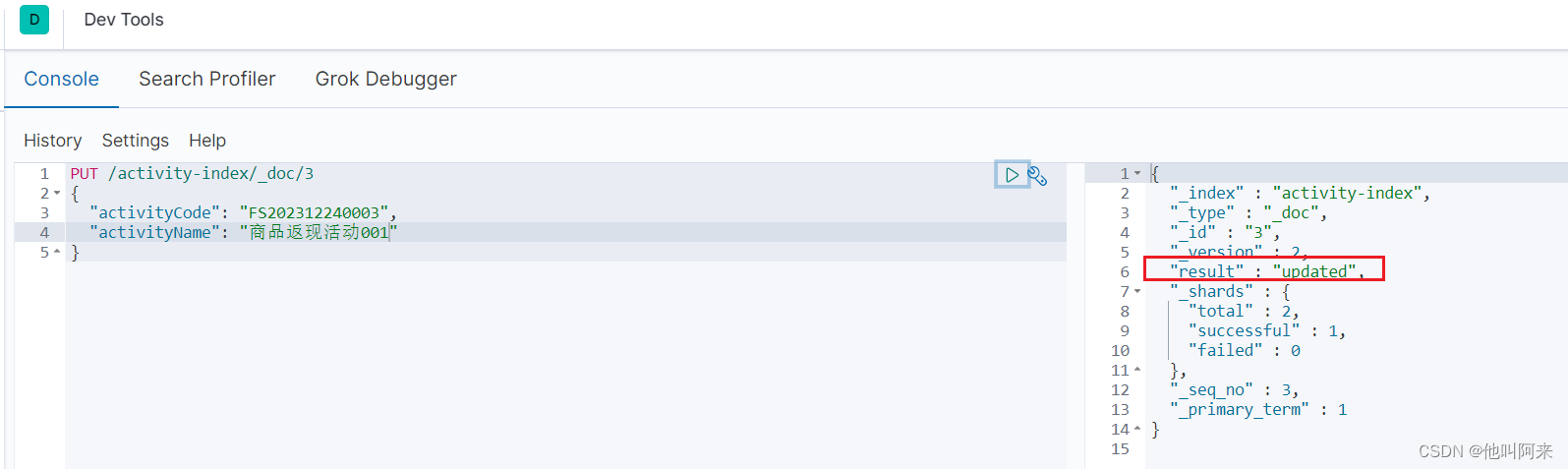
此时显示的是修改
上面就是Elasticsearch使用PUT或者POST对文档进行更新(全部更新),如果指定ID的文档已经存在,则执行更新操作。
全部更新就是,Elasticsearch首先将旧的文档标记为删除状态,然后添加新的文档,旧的文档不会立即消失,也无法访问;Elasticsearch会在你继续添加更多数据的时候在后台清理已经标记为删除状态的文档。
局部更新
局部更新就是,只是修改某个字段
POST /activity-index/_update/111
{
"doc": {
"activityName": "限时抢购活动001"
}
}
如果局部更新的文档不存在,则会返回异常
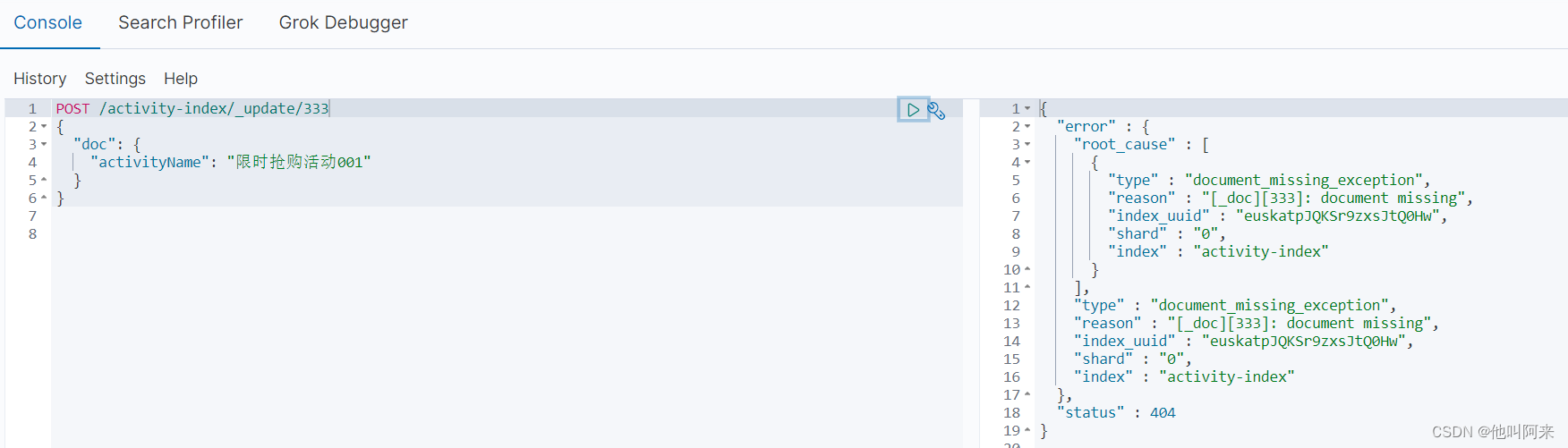
4.6 删除文档
根据id进行删除
DELETE /索引名称/_doc/{id}
根据查询条件删除
POST /activity-index/_delete_by_query
{
"query": {
"match": {
"activityName": "限时抢购活动002"
}
}
}
删除所有
POST /activity-index/_delete_by_query
{
"query": {
"match_all": {}
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!