java PDF文件解析方案
发布时间:2024年01月20日
一、目的
解析数万个PDF文件结构和内容
二、初始解析方案
以前已经解析过少量的PDF文件,在原来的基础上解析调整优化,形成初始的解析方案。

解析结果在大批量文件的情况下不可行。

原因统计分析

三、优化解析方案
3.1.优化策略

3.2.解析逻辑
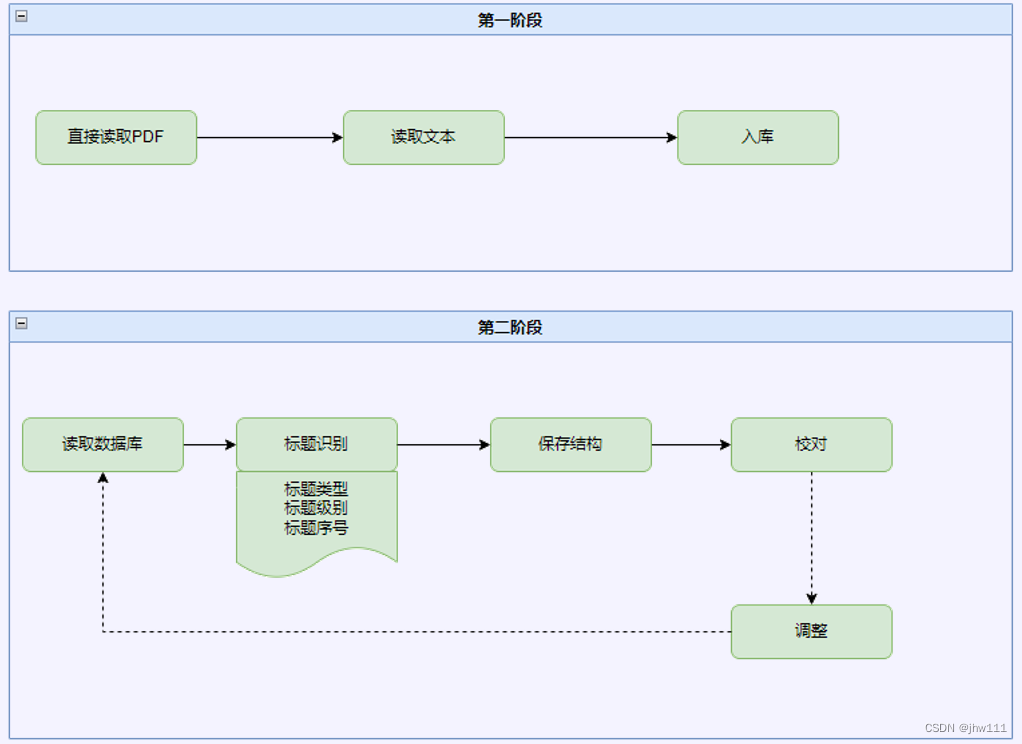
3.3.文本抽取工具选型

3.4.优化效果


3.5.针对少量pdf文本抽取为空的文件

文章来源:https://blog.csdn.net/jhw111/article/details/135667707
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024年【裂解(裂化)工艺】考试题库及裂解(裂化)工艺考试总结
- 【员工工资册】————大一期末答辩近满分作业分享
- mybatis-plus进行数据操作不生效,update等操作不生效
- docker搭建maven私库Nexus3
- Wheeltec小车的开发实录(0)
- windows任意APP注册成服务(以nginx服务为例)
- dom4j生成XML文件
- 动态IP与静态IP有何区别?怎么使用选择?
- 蓝桥杯--数的拆分
- [Angular] 笔记 6:ngStyle