2023.1.21 关于 Redis 主从复制详解
发布时间:2024年01月22日
目录
引言
单点问题
- 单点 ——> 某个服务器只有一个节点,即只搞一个物理服务器来部署这个服务器程序???????
问题:
- 可用性:如果该机器挂了,便意味着服务器中断
- 性能、支持的并发量:十分有限
解决方案:
- 引入分布式系统,主要也就是为了解决单点问题??????????????
分布式系统
- 在分布式系统中,往往有多个服务器来部署 Redis 服务,从而构成一个 Redis 集群
- 此时便可以让该集群给整个分布式系统服务,以便提供更稳定 和 更高效的数据存储功能
三种部署方式:
- 主从模式
- 主从 + 哨兵模式
- 集群模式
- 本文主要详解 Redis 部署方式中的 主从模式
??????????????主从模式
- 在若干个 Redis 节点中,有的是?主节点,有的是 从节点
实例理解
- 假设有三个物理服务器,即三个节
- 这三个节点???????分别部署?redis-server 进程
- 此时就可以将其中的一个节点,作为 主节点,另外两个节点作为 从节点
- 从节点上的数据跟随主节点变化,从节点的数据要和主节点保持一致
具体理解:
- 本来主节点上保存一堆数据,在引入从节点后,便需要将主节点上的数据复制出来,放到从节点中
- 后续主节点对数据如果有任何修改,都需将修改给同步到从节点
- 即 从节点就是主节点的副本
问题:
- 如果修改了 从节点 的数据,是否还需要将 从节点 所修改的数据往 主节点 上同步呢?
回答:
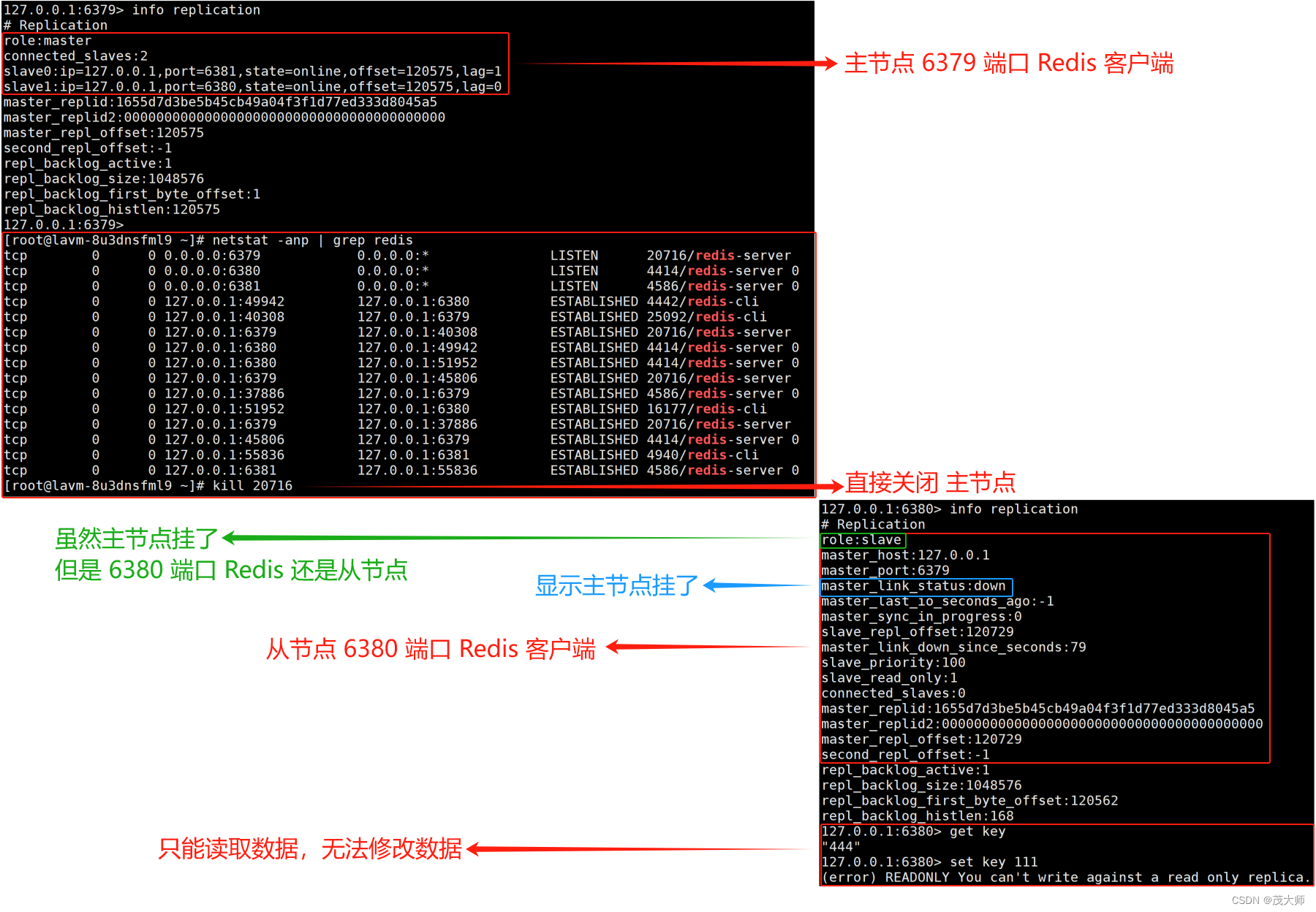
- 在 Redis 主从模式下,从节点上的数据,不允许修改!只能读取数据!
优势:
- Redis 主从结构可有效改善 可用性问题、性能、支持并发量有限 问题,即?单点问题
具体理解:(性能、并发量)
- 由于 从节点数据 时时刻刻与 主节点 保持一致
- 因此其他的客户端在 从节点读取的数据,和在 主节点读取的数据没有任何区别!
- 即 其他客户端如需读取数据,可随机挑选一个从节点,给该客户端提供读取数据的服务
- 引入了更多的计算资源,自然能够支持的并发量也便大幅提高了!
具体理解:(可用性)
- 相较于单个?Redis 服务器节点,如果该节点挂了,整个 服务也便中断了
- 而主从结构的 Redis 服务器节点是不太可能 同时挂了的!
问题一:
- 是否存在整个机房同时挂了的情况呢?
回答:
- 也是可能会存在的!
- 这个时候如果考虑到更高的可用性,便可以将这些机器分散到多个不同的机房中
- 即 异地多活
问题二:
- 如果是挂掉了某个从节点呢?
回答:
- 没啥影响
- 此时继续到?主节点或其他从节点 获取数据即可
- 因为得到的效果完全相同
问题三:
- ???????如果是挂掉了主节点呢?
回答:
- 还是有一定影响的
- 因为从节点只能读取数据,却无法写数据
- 即 可用性虽然是提高了,但是还没到非常理想的程度
问题四:
- 是否可以引入多个主节点呢?
回答:
- 一山不能容二虎
- 如果存在两个主节点,这两个主节点之间如何互相同步数据呢?
- 所以引入多个主节点,也并不能很好的解决上述问题
总结:
- 准确来说,主从模式主要是针对 "读操作" 来进行 并发量 和 可用性 的提高
- 而写操作,无论是可用性还是并发,均十分依赖主节点,而主节点又不能搞多个
注意点一:
- 实际业务场景中,读操作往往就是比写操作更频繁
注意点二:
- 主从结构是分布式系统中一种 比较典型的结构
- 不仅仅是 redis 支持,像 MySQL?等其他的常用组件 同样也是支持的
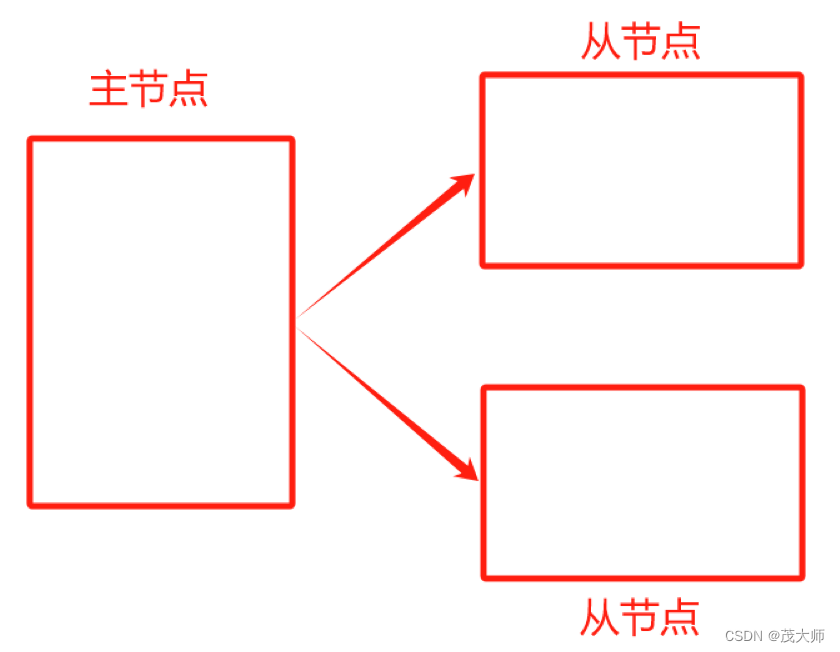
配置 Redis 主从结构
- 配置 Redis 主从结构,首先需要启动多个 Redis 服务器
注意:
- 正常来说,每个 Redis 服务器程序,都应该在一个单独的主机上
- 因为这才符合?分布式
问题一:
- 仅有一个云服务器,不能部署分布式系统吗?
回答:
- 一个云服务器上 是可以运行多个 redis-server 进程的
- 但是需要保证这多个 redis-server 端口需不同
- 本来 redis-server 默认的端口为?6379
- 此时便不能让新启动的 redis-server 再继续使用 6379 端口了
问题二:
- 如何指定 redis-server 的端口呢?
回答:
- 在启动程序时,通过命令行来指定端口号,即添加 --port 选项
- 直接在配置文件中设定端口(下文实例将通过该方式来完成)
实例理解
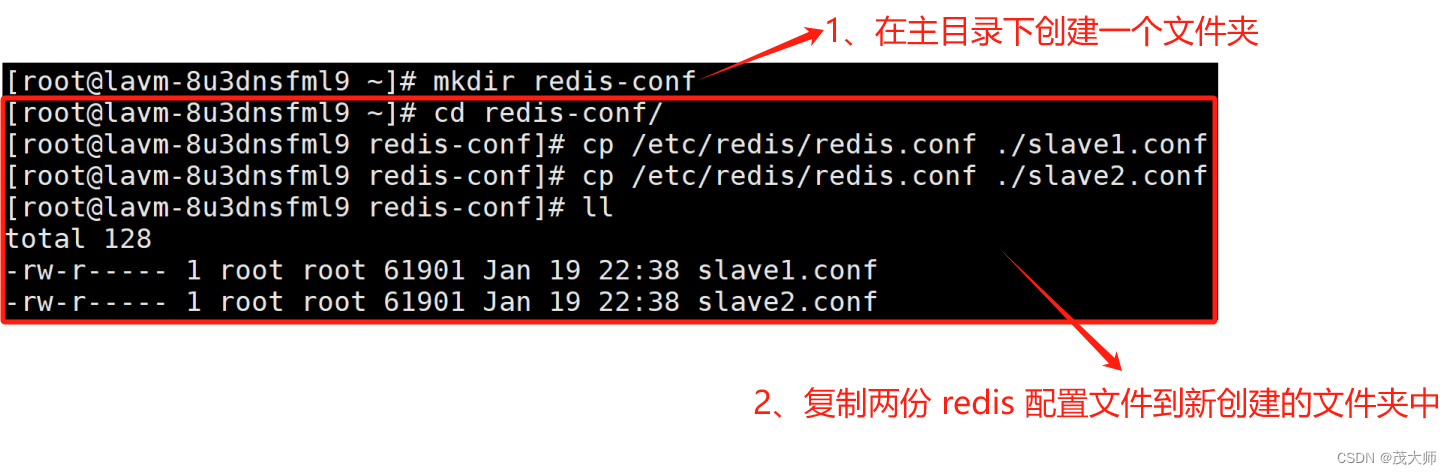
- ?假设我要配置一个主节点和两个从节点
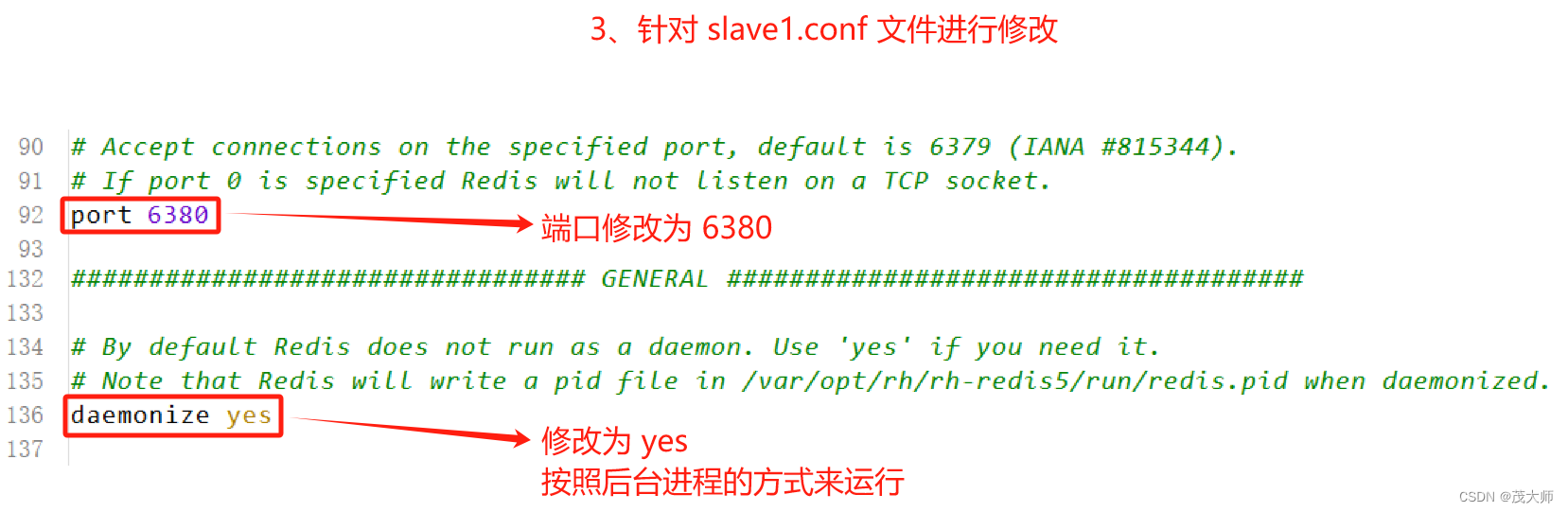
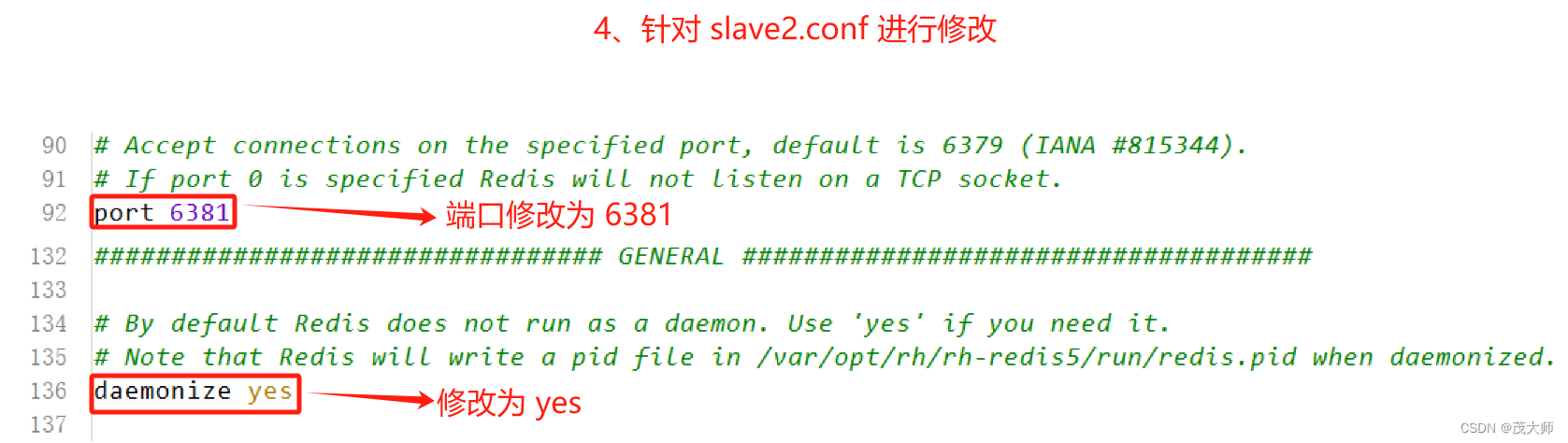
1、主节点配置不变,复制两份主节点配置文件,并修改这两份文件的端口和后台运行方式
- 此时我们便得到了两份?从节点 的配置文件,端口分别为 6380、6381
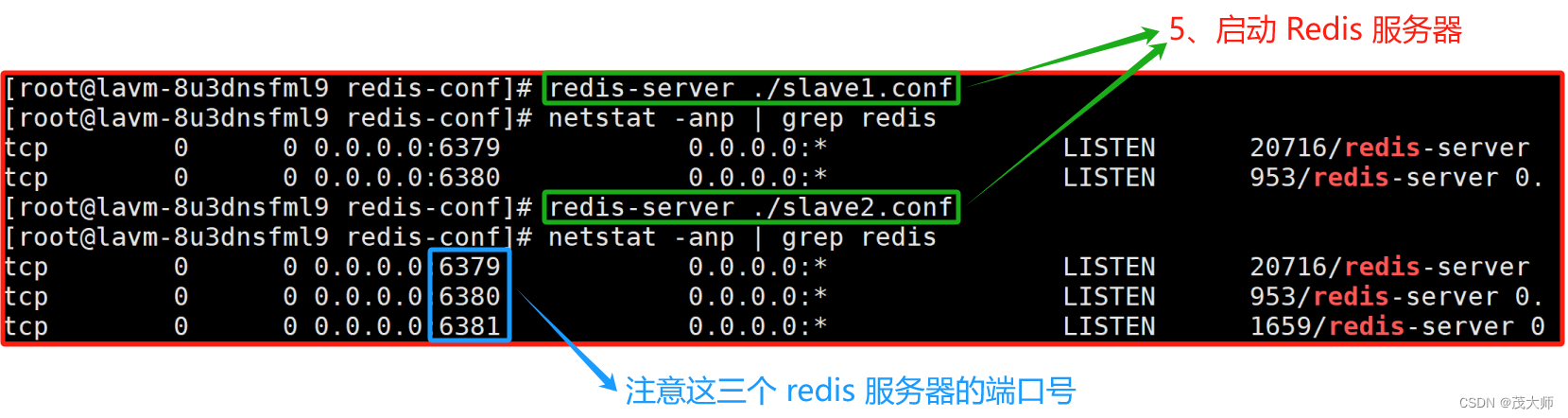
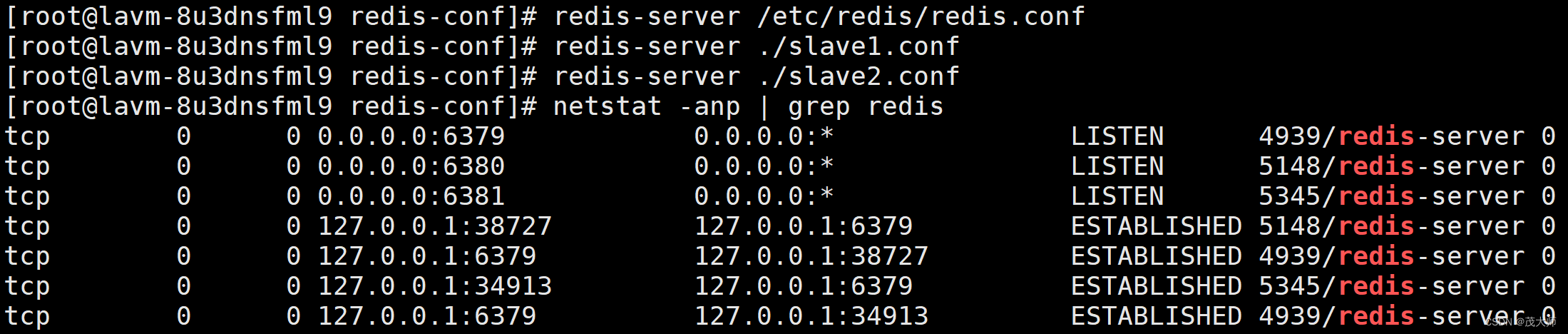
2、启动两个从节点的 Redis 服务器
??????????????
- 由上图可知,当前这三个节点并未构成主从结构,还需进一步的进行配置!
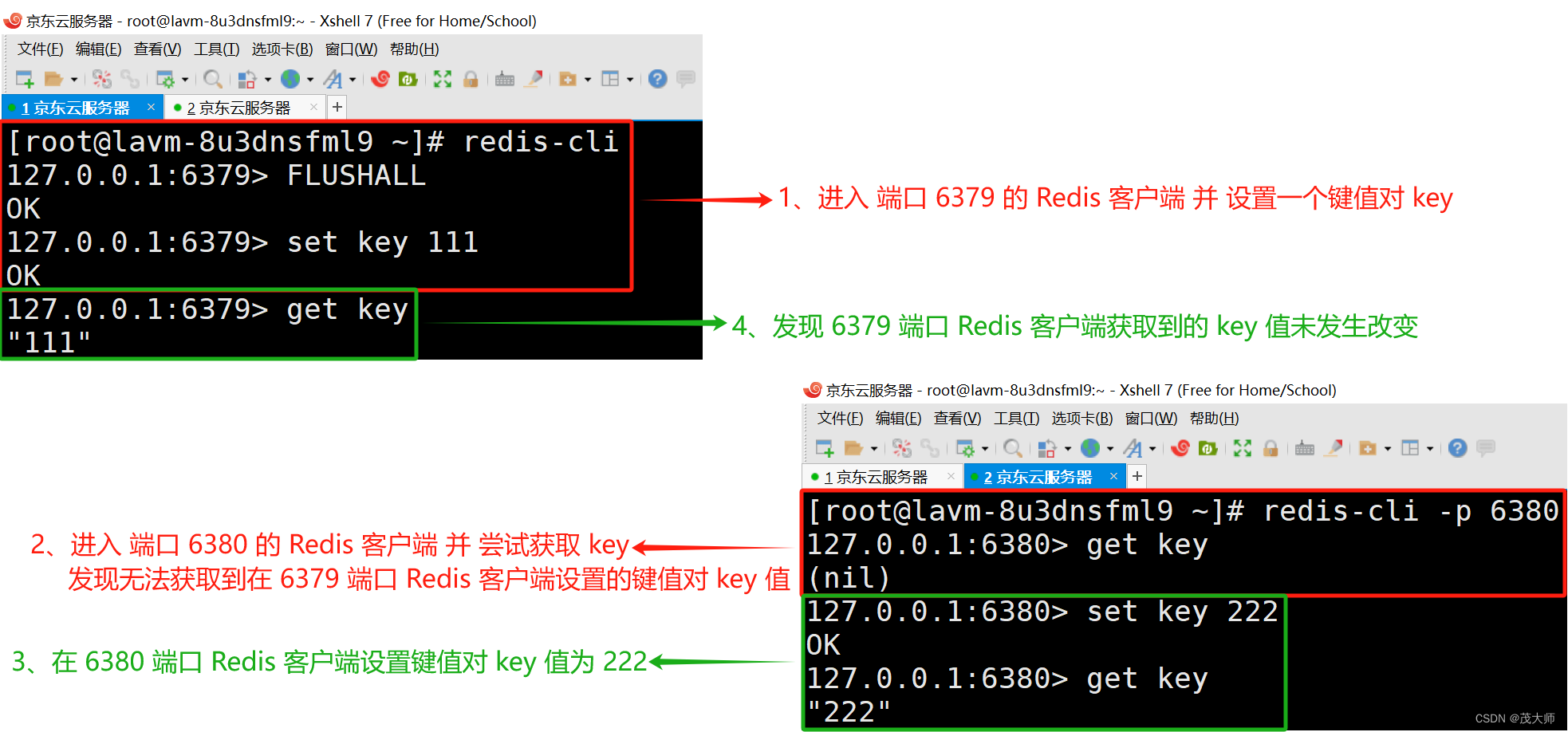
3、使用 slaveof 配置主从结构,此处我们以 6379 为主节点,6380 和 6381 为从节点
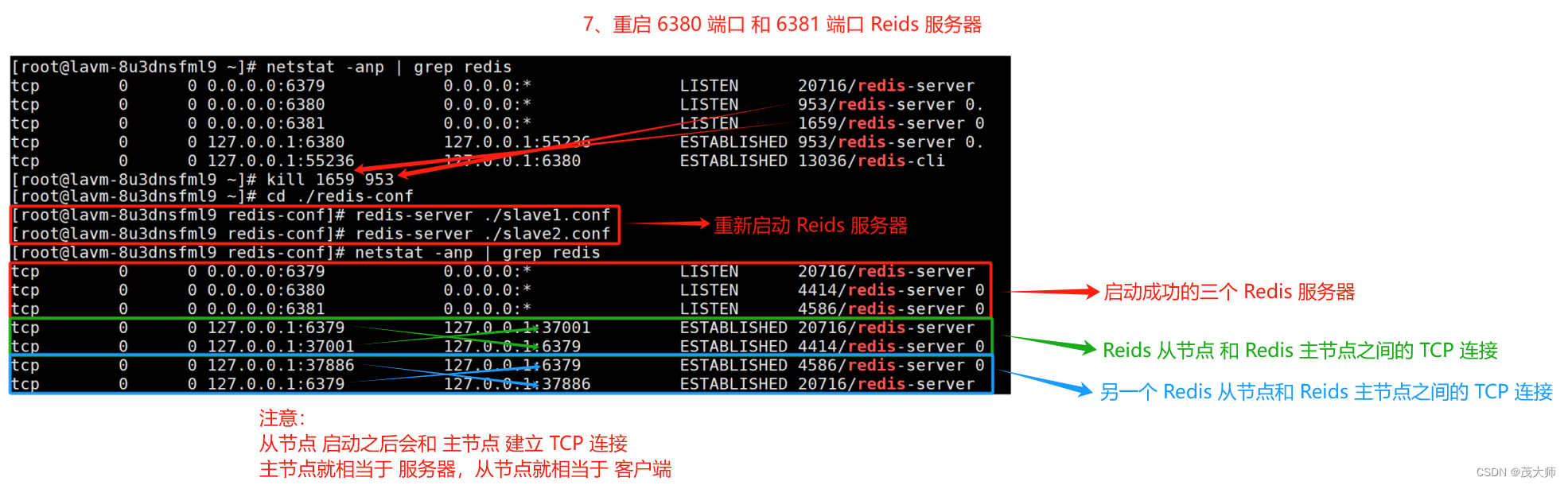
4、重启?两个从节点的 Redis 服务器
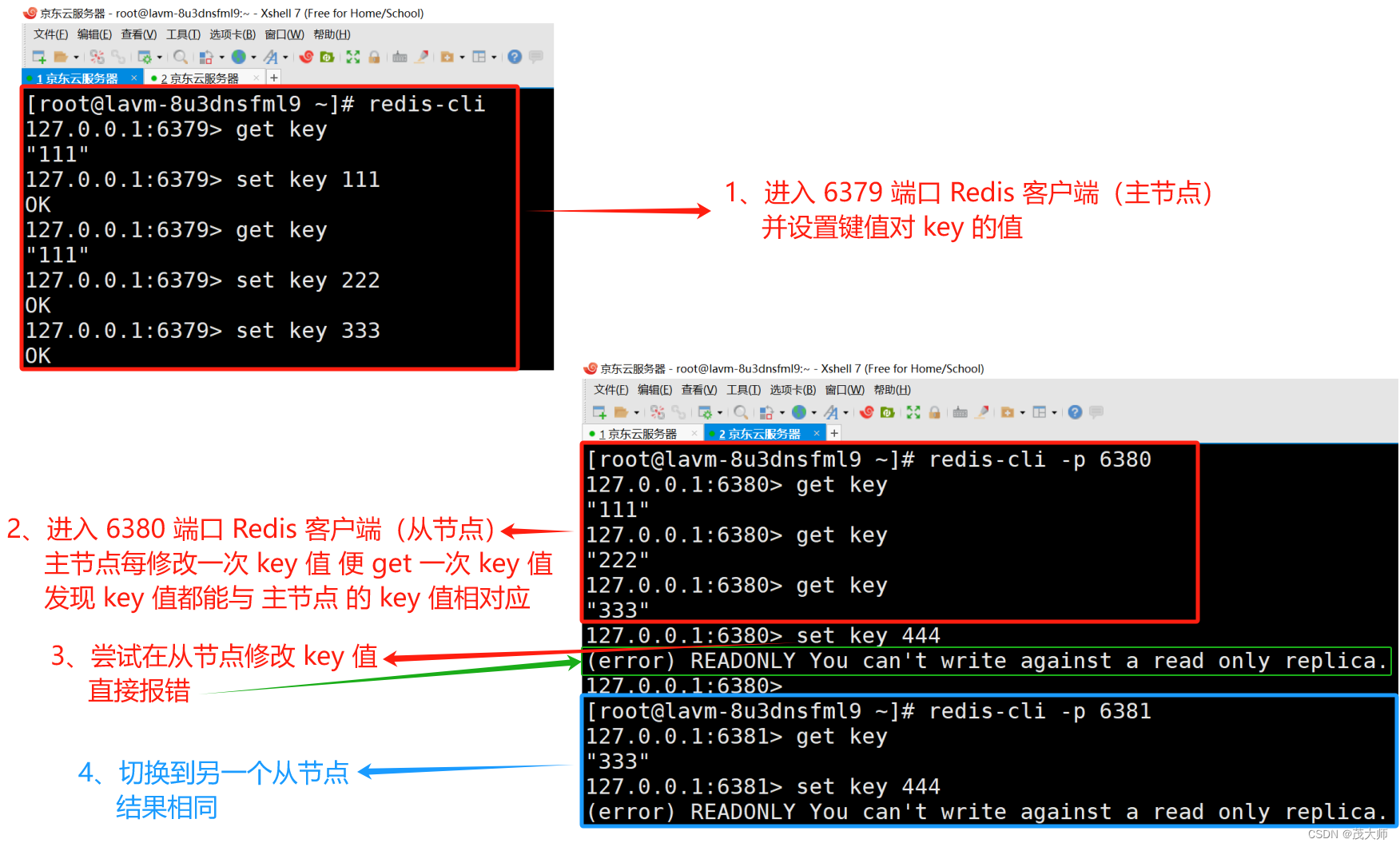
- 由上图可知,这三个节已经构成了主从结构
- 主节点这边数据产生任何修改,从节点这边能立即感知到(TCP 连接所起到的效果???????)
- 从节点无法写入数据
5、使用?info replication 命令查看主从结构信息
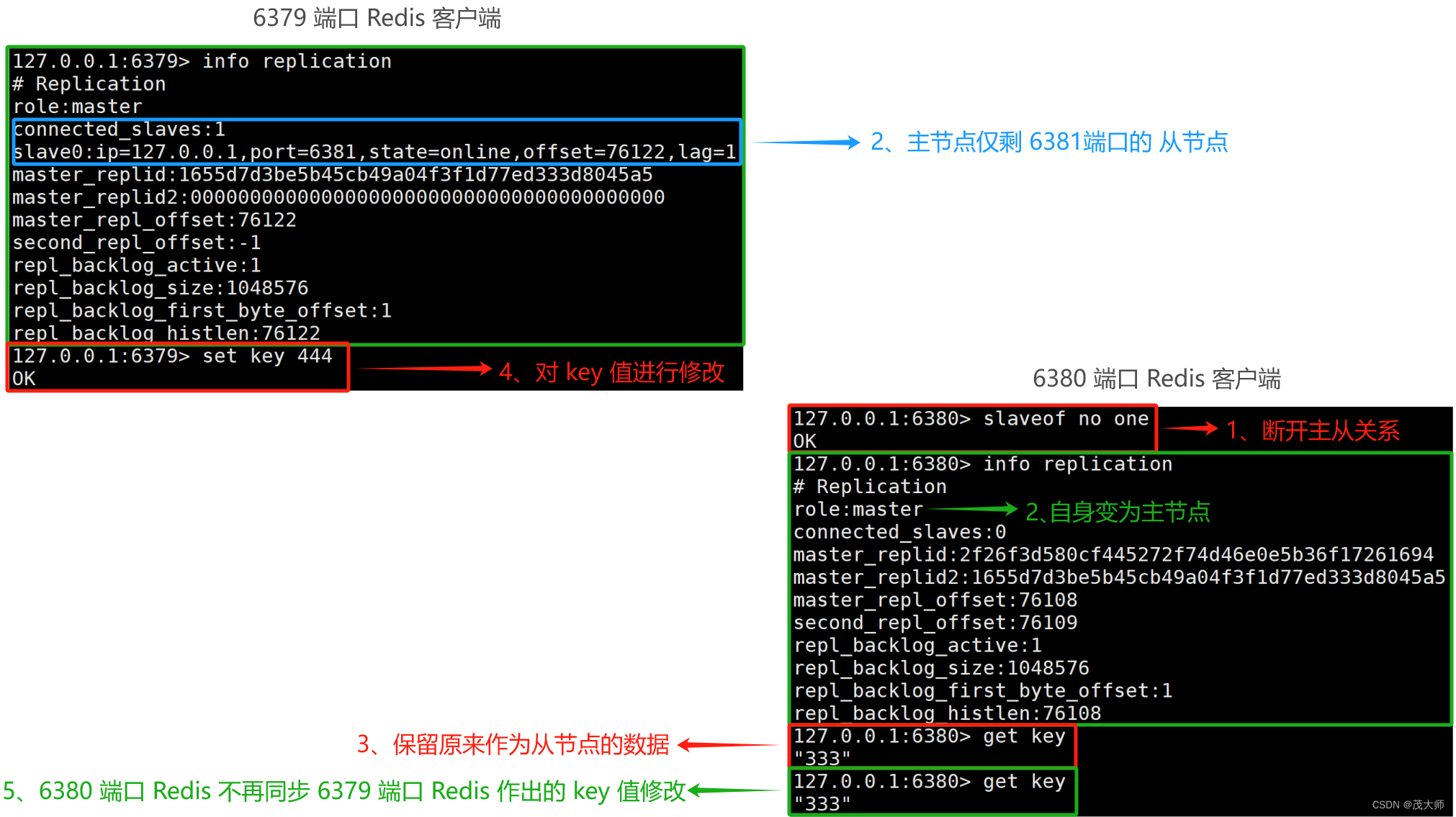
断开主从关系
- 我们可以直接使用 slaveof no one 命令,断开现有的主从复制关系
- 从节点断开主从关系,它便不再从属于其他节点了,即从节点自身变为主节点
- 即 后续主节点如果针对数据做出修改,从节点便无法再自动同步数据了
注意:
- 从节点断开主从关系后,从节点之前所存储的数据 不会丢弃!
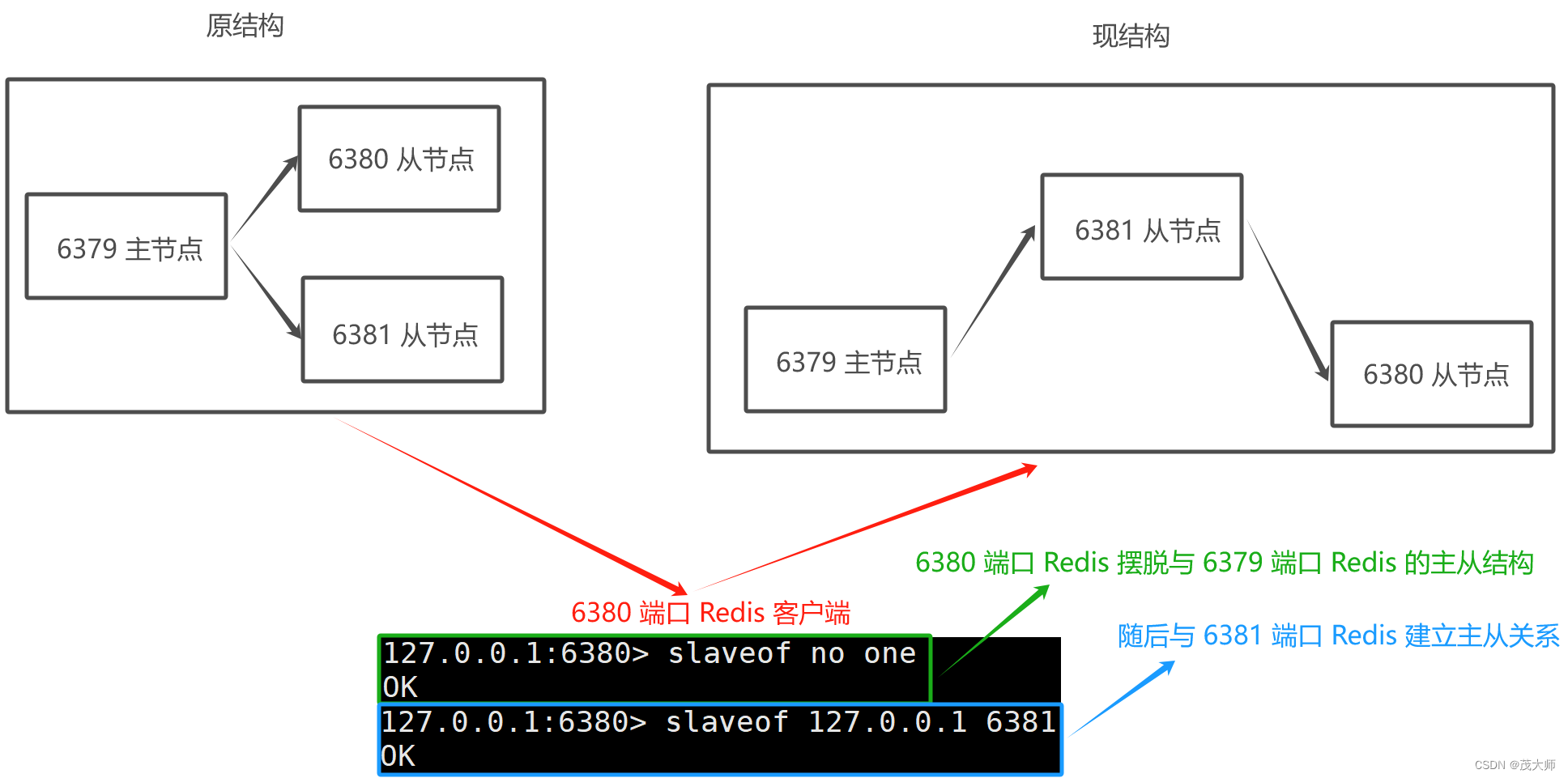
切换主从关系
- 先直接使用 slaveof no one 命令,断开现有的主从复制关系
- 再使用 slaveof newMasterIP newMasterPort 切换主从关系
注意点一:
- 此时 6381 端口 Redis 虽然看起来是个 主节点
- 但实际上,其仍然是个 从节点,仅作为 6380 端口 Redis 同步数据的来源,自身仍然是不能修改数据的!
注意点二:
- 通过 slaveof 虽然修改了 6380 端口 Redis 的主从结构
- 但是此处的修改是临时的,即 如果重新启动?Redis 服务器,仍然会按照最初在配置文件中设置的内容来建立主从关系


补充知识点一
只读
- 默认情况下 从节点使用 slave-read-only = yes 配置为只读模式
- 当然我们也可对该配置项进行修改
重点理解:
- 主从复制 是由?主节点 到 从节点
- 不能由? 从节点 到 主节点
- 如果允许从节点修改数据,此时主节点是无法感知的,进而导致主从节点数据不一致!
网络延迟
- 主节点和从节点之间通过 网络来传输(TCP)
- TCP 内部支持了 nagle 算法(默认开启)
- 开启 negle 算法,就会增加 TCP?传输延迟,节省网络带宽
- 关闭 negle 算法,就会减少 TCP?传输延迟,增加网络带宽
重点理解:
- negle 算法的目的 和 TCP?捎带应答是一样的
- 针对小?TCP?数据报进行合并,从而减少报的个数
注意点一:
- repl-disable-tcp-nodelay 配置项可用于在主从同步通信过程中关闭 TCP?的 nagle 算
- 进而从节点将更快速的和主节点进行同步
注意点二:
- 一般的游戏开发,尤其是对即时性要求很高的游戏,一般都会关闭 nagle 算法!
?拓扑结构
- 拓扑结构就描述了若干个节点之间,按照什么样的方式来进行组织连接
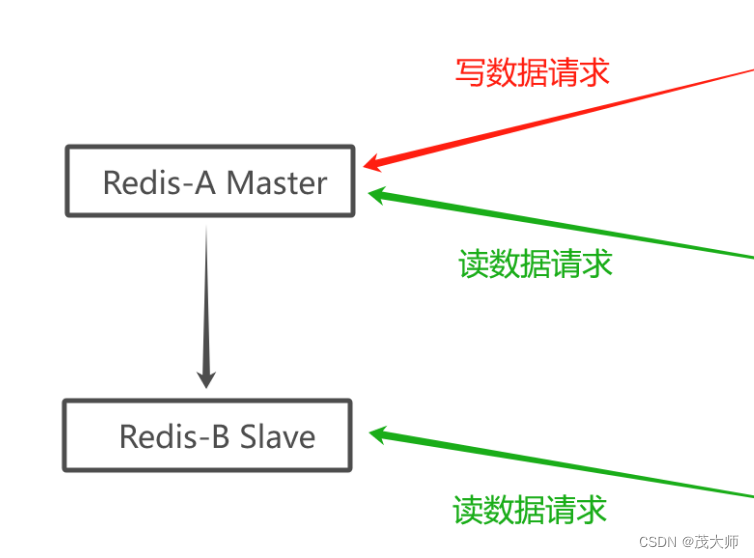
一主一从
- 如果写数据请求太多,此时便会会给主节点造成一定的压力
- 当然我们也可以通过关闭主节点的 AOF ,只在从节点上开启 AOF 来分担持久化压力,避免影响性能
注意:
- 该设置方式存在一个严重缺陷
- 即 主节点一旦挂了,就不能让他自动重启
- 如果主节点自动重启了,主节点便会因为其没有 aof?文件,而丢失之前的数据
- 随之同步到从节点上,从节点的数据也便跟着给删除了
改进办法:
- 当主节点挂了之后,让 主节点 到?从节点 这里获取?aof?文件,再进行启动!
重点强调:
- 在实际开发中,读请求 是要远远超过 写请求 的!
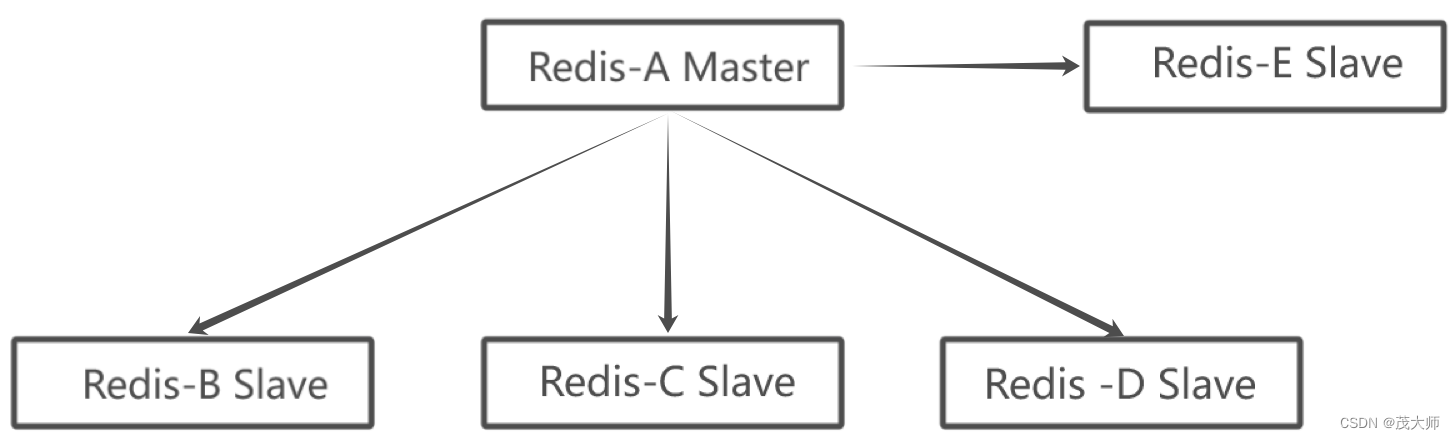
一主多从
- 主节点上数据发生改变时,此时便会将发送改变的数据 同时同步给所有从节点
注意:
- 随着从节点个数的增加,同步一条数据便需要传输多次
- 主节点便需要付出更大的网络带宽,因此成本也就越高!
树形主从结构
- 此时的 主节点 无需更大的网络带宽
注意:
- 如果数据一旦进行了修改,其同步延时比 一主多从 结构要更长!
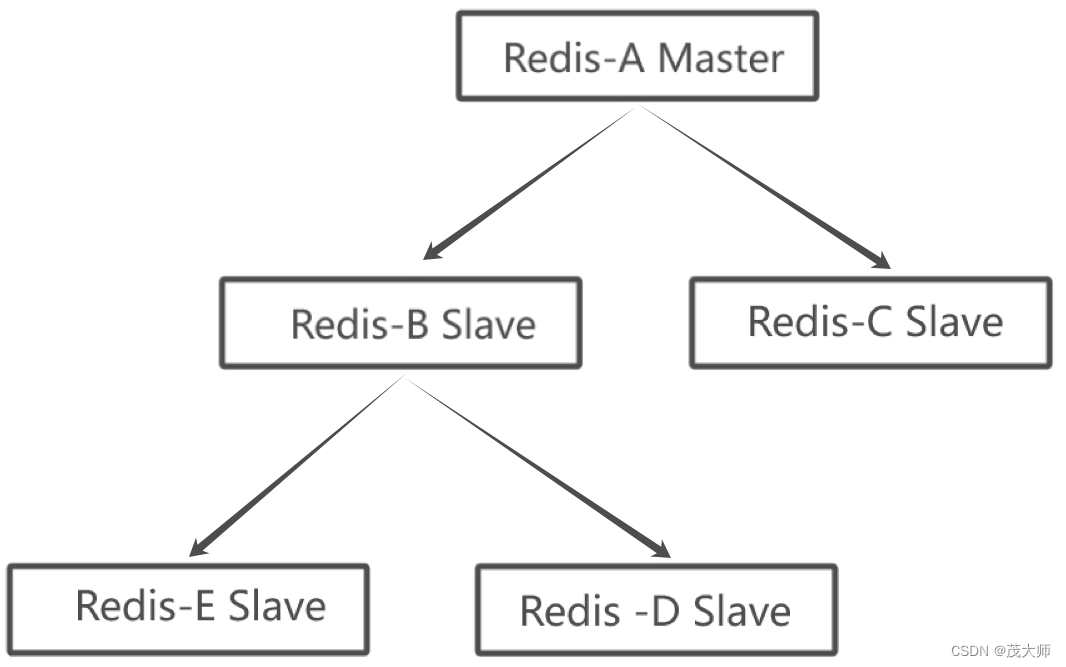
主从复制的基本流程?
数据同步
- Redis 提供了 psync 命令,完成数据同步的过程,psync 命令无需手动执行
- Redis 服务器会在建立好主从同步关系后,自动执行 psync 命令
- 从节点会自动执行 psync 命令,也就是?从节点 回去 主节点这边拉取数据
psync replicationid offset
- replicationid:表示要从哪个主节点上获取数据
- offset:为?-1,表示获取全量数据
- offset:写成具体的正整数,表示从当前偏移量位置来进行获取
replicationid
- replicationid?由主节点生成
- 主节点启动时 抑或?从节点晋升成主节点时,都会生成?replicationid
注意点一:
- 即使是同一个节点,每次启动所生成的 replicationid 均不同
具体理解:
- 当从节点和主节点建立了复制关系,便就会在主节点这边获取到?replicationid
问题:
- 当前讨论的是 一主多从 结构,后面谈到的集群 为 多个主节点 和 多个从节点
- 该情况下,多个不同主节点 之间存储的数据可能不太一样
- 那么各从节点应该从哪个主节点进行复制数据呢?
回答:
- 可以通过??replicationid 来明确,从节点应该到哪个主节点进行复制数据
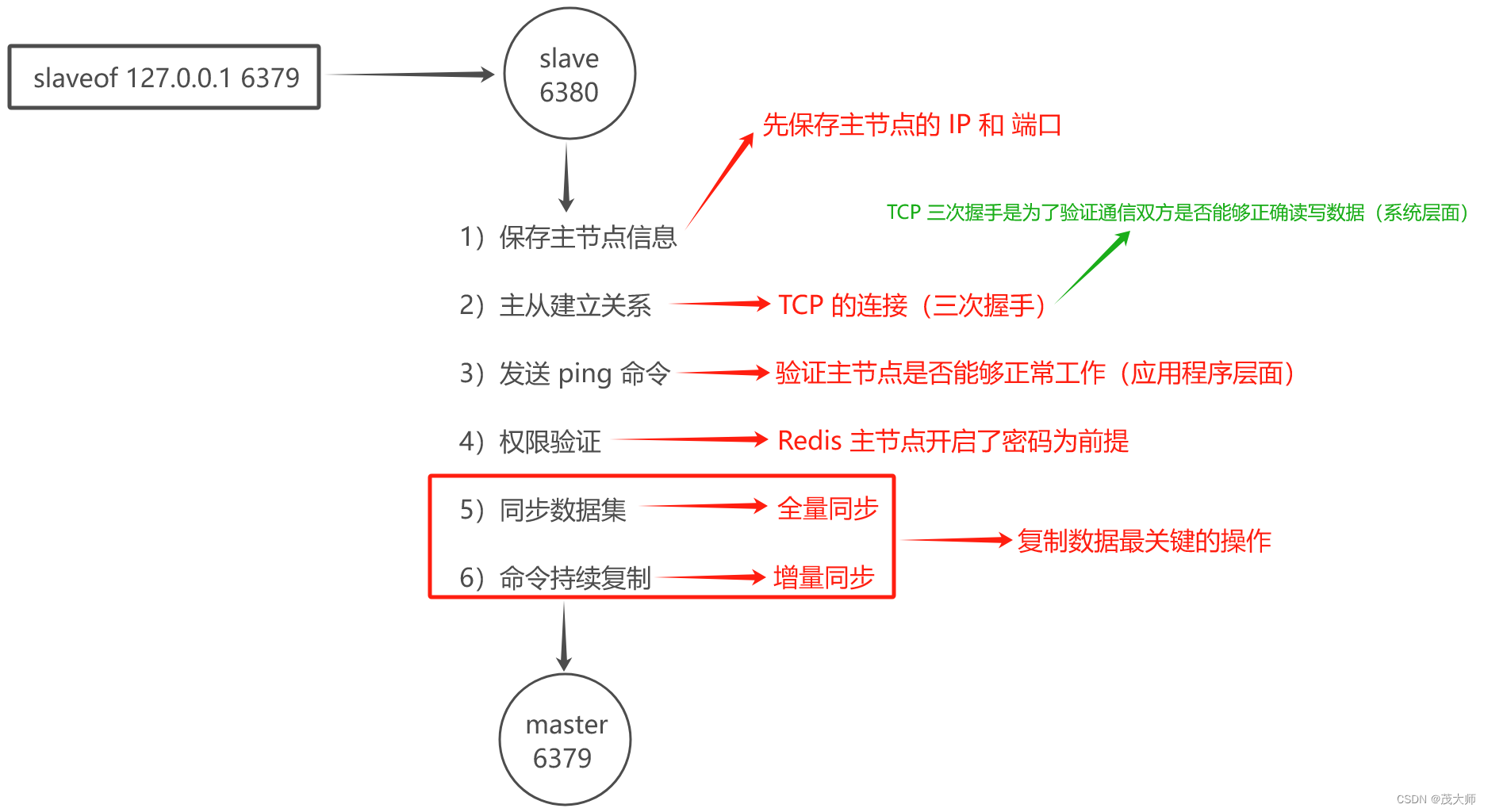
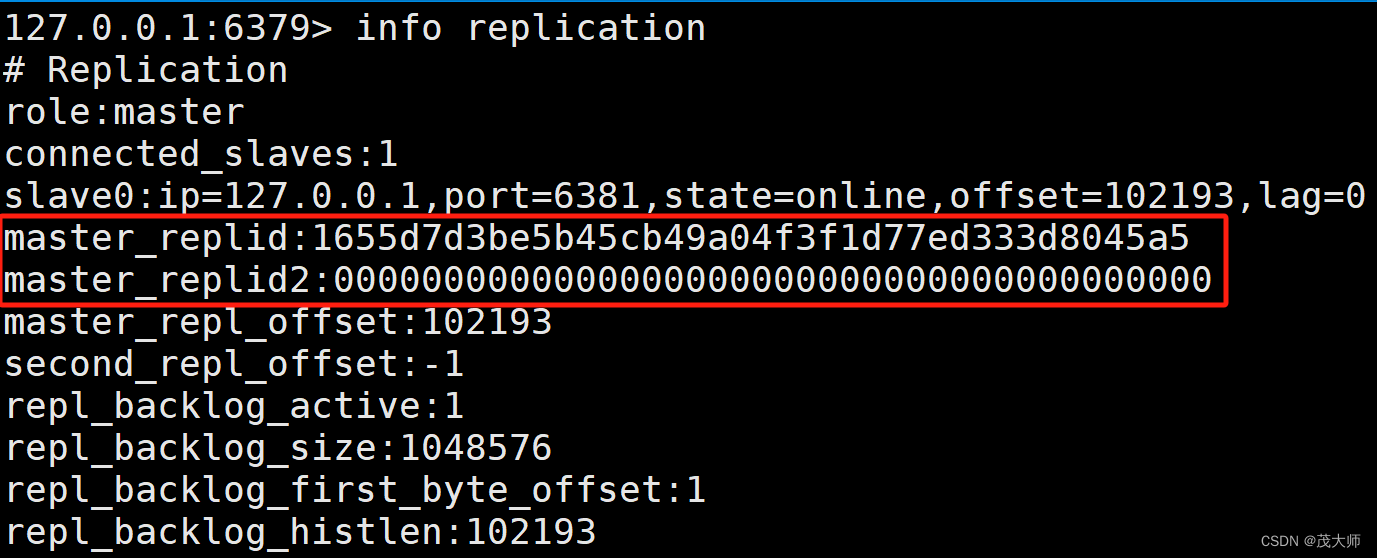
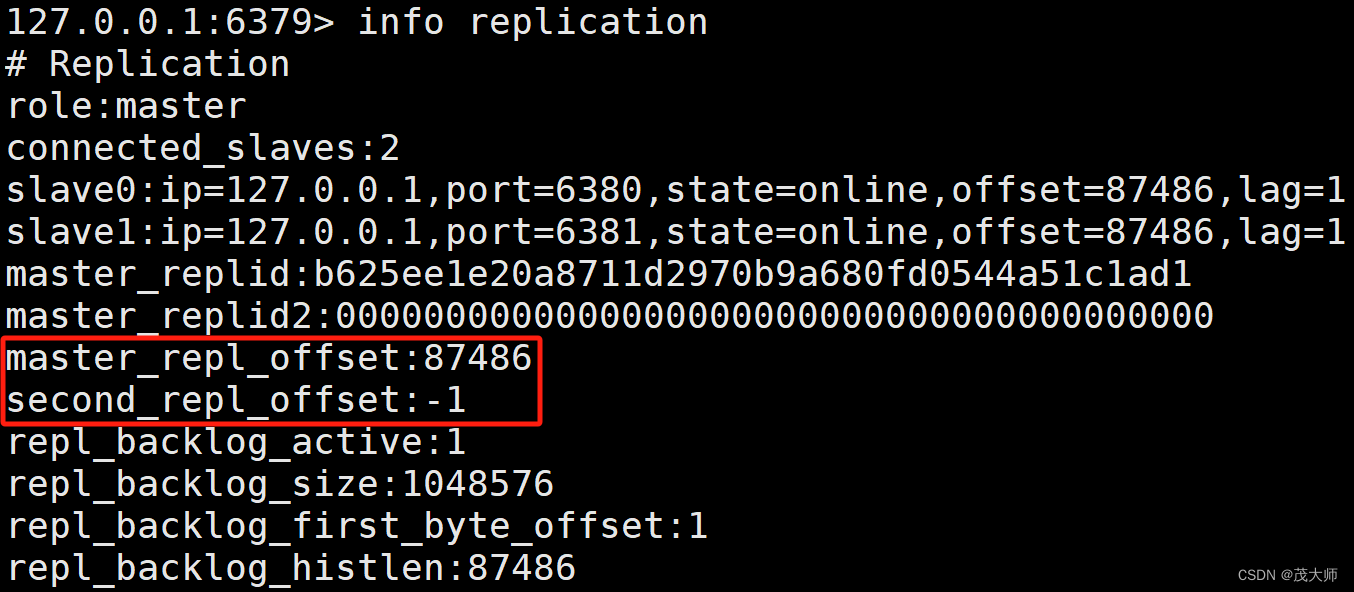
实例理解
- 在 Redis 客户端输入 info replication 命令获取当前 Reids 的 replicationid
注意:
- 一般情况下 replid2 是用不上的
特殊情况:
- 假设有两个节点???????,主节点A 和 从节点B
- 主节点A 生成 replid ,与此同时从节点B 获取到 主节点A 的 replid
- ?如果 A 和 B 的通信过程中出现了网络抖动,此时 B 便可能就会认为 A 挂掉了
- 那么 ???????B 就会自己成为主节点,同时给自己生成一个 replid
- 但是 B 还会通过 replid2 来记住之前主节点A 的 replid
- 后续网络稳定了,B 还可以根据 replid2 重新变为?A 的节点
- 此过程需要手动干预 ,但是哨兵机制,可以自动完成这个过程
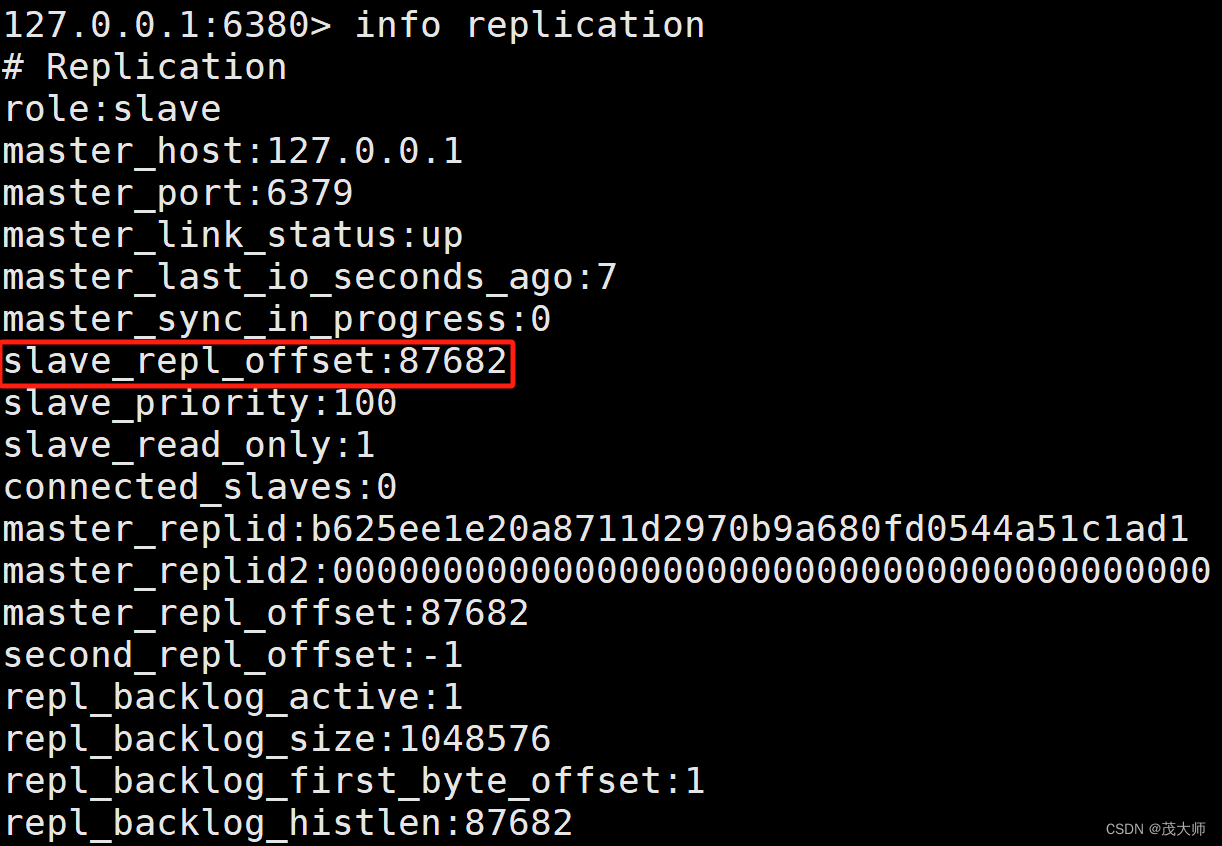
offset
- 主节点和从节点上均会维护 offset 偏移量(整数)
主节点偏移量:???????
- 主节点上会收到很多修改操作的命令,每个命令都要占据几个字节
- 主节点都会把这些修改命令,每个命令的字节数进行累加
从节点偏移量:
- 描述了该从节点数据同步到哪里了
- 如果从节点偏移量和主节点偏移量一样,则此时从节点的数据便跟主节点数据完全一致
小总结:
- replicationid 和 offset 共同描述了一个 "数据结合"
- 如果发现两个 Redis?的?replicationid 一样,offset 也一样,就可以认为这两个 Redis 机器上存储的数据完全一致!
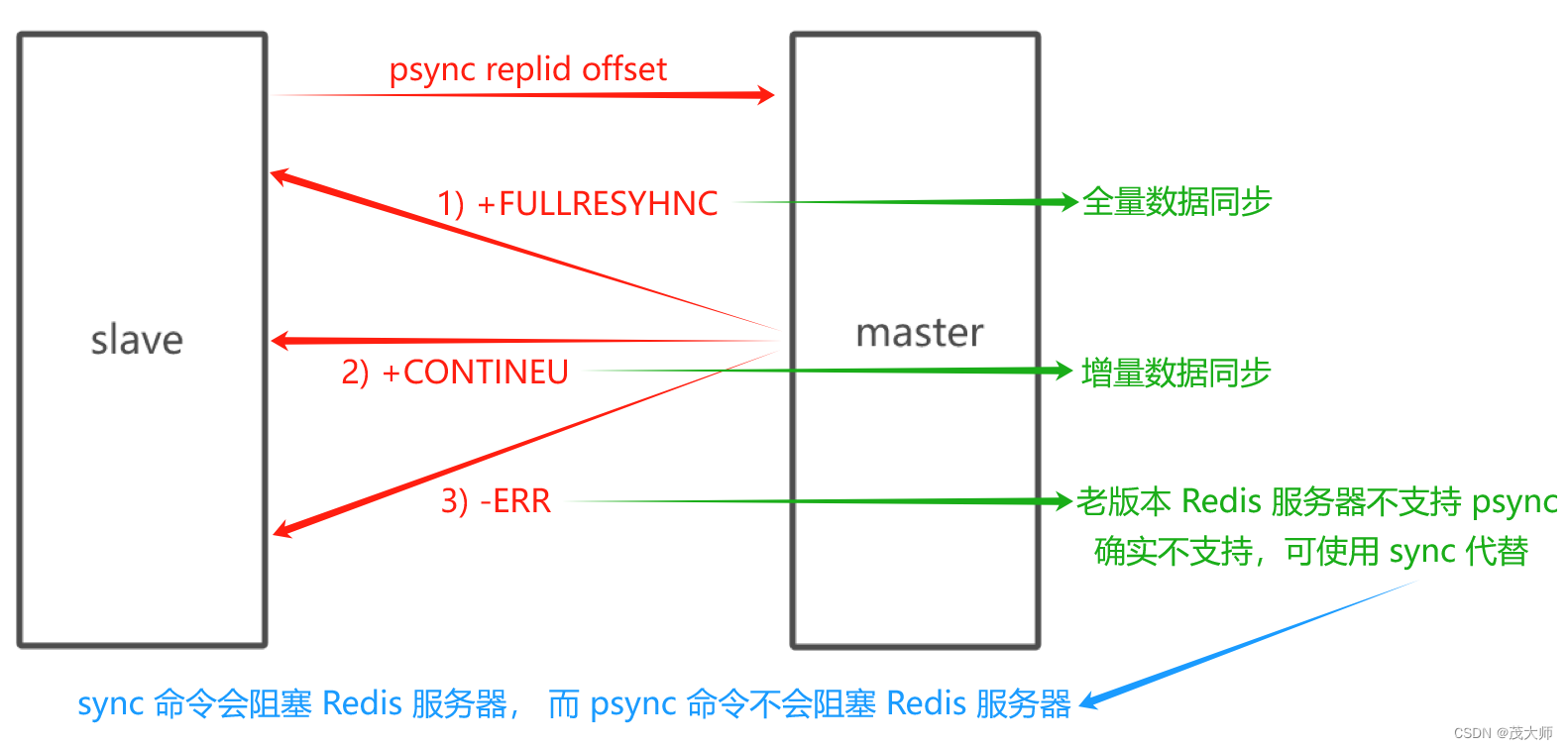
pzync 运行流程
- psync 命令可以从??主节点这里获取全量数据,也可以获取一部分数据
- 主要就是看 offset 这里的进度
- offset 写作-1 就是获取全量数据
- offset 写作具体的正整数,则是从当前偏移量位置来进行获取
注意点一:
- 获取全量数据是最稳妥的,但是会比较低效
- 如果从节点之前已经 在主节点这里复制过一部分数据了
- 此时仅需将 新数据,即之前没复制过的数据搞过来就行
注意点二:
- 不是从节点索要哪部分,主节点就一定给哪部分
- 主节点会自行判断,看当前是否方便给部分数据,不方便就只能给全量数据了
具体流程
问题一:
- 什么时候进行全量复制呢?
回答:
- 首次和主节点进行数据同步
- 主节点不方便进行部分复制时
问题二:
- 什么时候进行部分复制呢?
回答:
- 从节点已经从主节点复制过数据了,因为网络抖动或者从节点重启了
- 从节点需要重新从主节点这边同步数据,此时看能不能只同步一小部分
- 因为大部分数据都是一致的???????
?补充知识点二
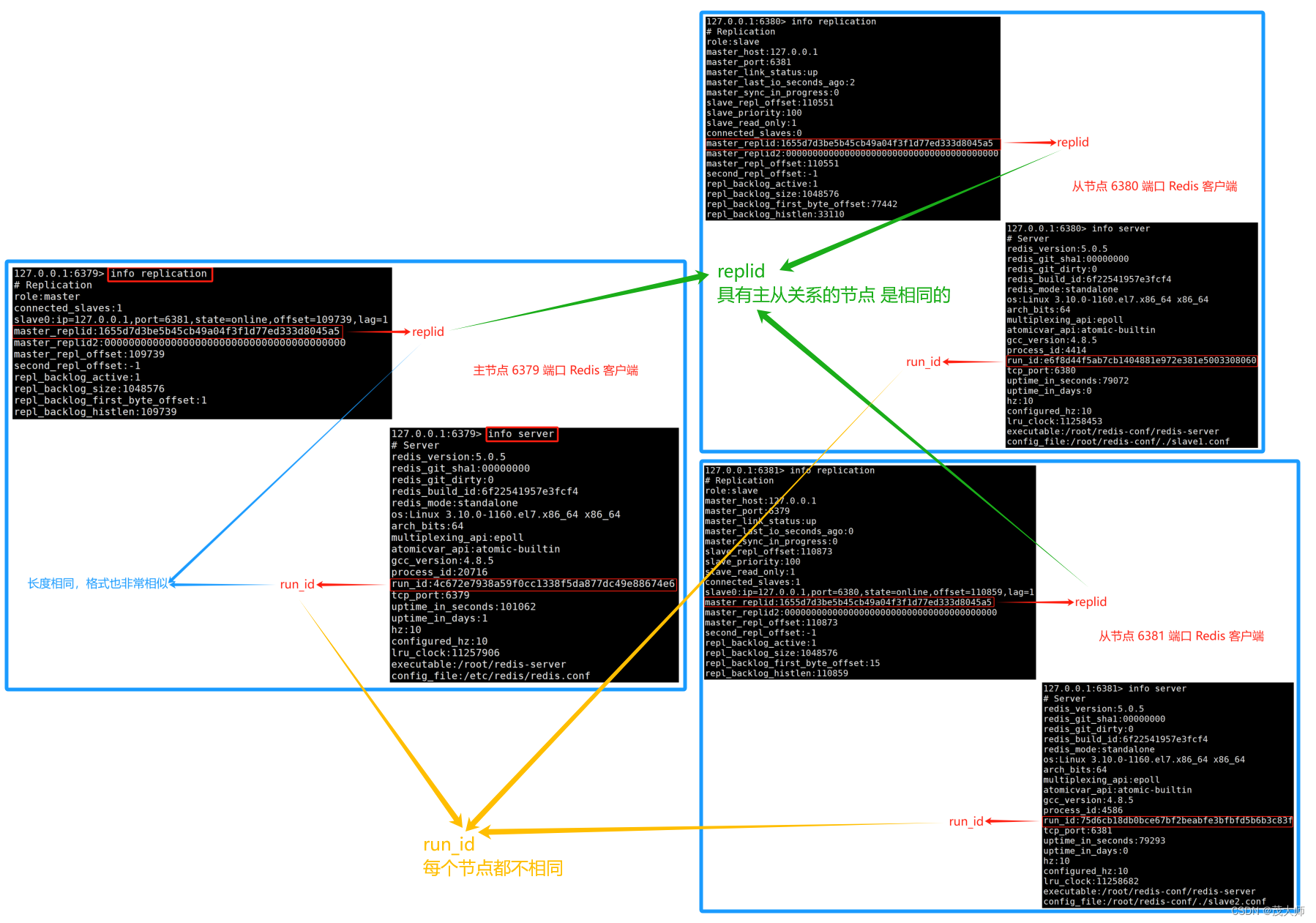
replicationid?与 runId 区别
- 一个 Redis 服务器上 既存在 replicationid(replid)又存在?runId
- 虽然这两个不同的 id 看起来非常像,但其实际上还是存在一定区别的
runId:
- run_id 仅用来标识一次 Redis 的 运行
- run_id 主要是用在支撑 Redis 哨兵模式
- 即 run_id 和 主从复制 这里没啥关联
replid:
- replid 主要就是在主从复制这里起作用
- replid 和 offset 共同标识一个数据集合
注意:
- 官方文档上明确说了 psync 命令使用的是 replicationId,而不是 runId
psync replicationid offset
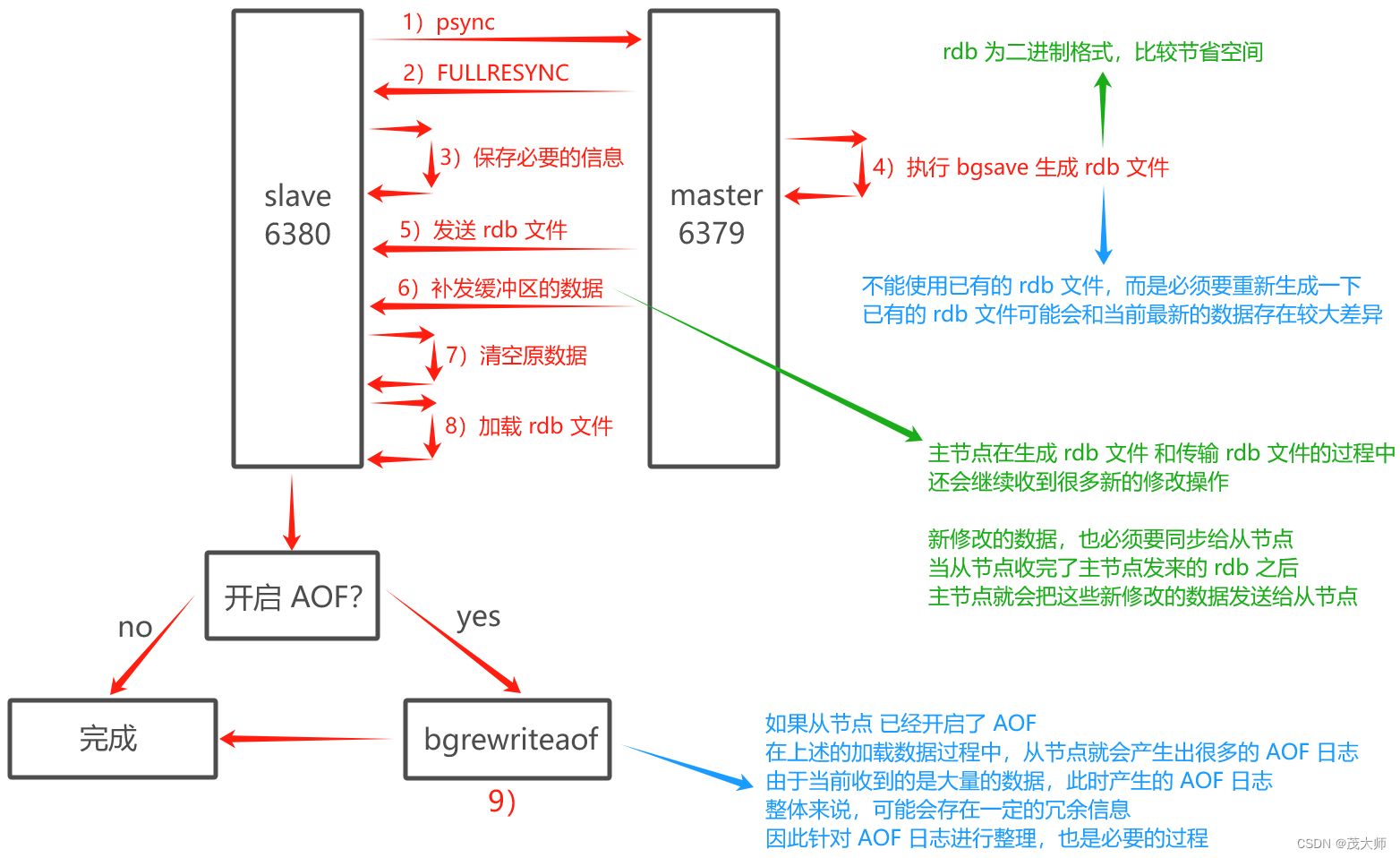
全量复制流程
- 从节点发送 psync 命令给主节点进行数据同步,由于第一次进行复制,从节点没有主节点的运行 ID 和 复制偏移量,所以发送 psync ?-1 命令
- 主节点根据命令,解析出要进行全量复制,回复 +FULLRESYNC 响应
- 从节点接收主节点的运行信息进行保存
- 主节点执行 bgsave 进行 rdb 文件的持久化
- 主节点发送 rdb 文件给从节点,从节点保存 rdb 数据到本地硬盘
- 主节点将从生成 rdb 到接收完成期间执行的写命令,写入到缓存区,等从节点保存完 rdb 文件后,主节点再将缓冲区内的数据补发给从节点,补发的数据仍然燃着 rdb 的二进制格式追加写入到收到的 rdb 文件中,保持主从一致性
- 从节点清空自身原有的旧数据
- 从节点加载 rdb 文件得到与主节点一致的数据
- 如果从节点加载 rdb 完成之后,开启了 AOF 持久化功能,它会进行 bgrewrite 操作,得到最近的 AOF 文件
补充:????????
- 主节点进行全量复制时,也支持 无硬盘模式(diskless)
- 即 主节点生成的 rdb 的二进制数据,不是直接保存到文件中了,而是直接进行网络传输
- 此模式可?省下一系列读硬盘和写硬盘的操作
- 从节点之前也是先将收到的 rdb 数据写入到硬盘中,然后再加载
- 现在也可以省略这个过程,直接将收到的 rdb 数据进行加载即可
注意:
- 即使引入了无硬盘模式,但是整个操作仍然还是比较重量、比较耗时的
- 因为网络传输是无法省略掉的
- 即 相比于 大规模数据(全量数据)网络传输,读写硬盘只能是是小头
???????部分复制流程
- 当主从节点之间出现网络中断时,如果超过 repl-timeout 时间,主节点会认为从节点故障并中断复制连接
- 主从连接中断期间主节点依然响应命令,但这些复制命令都因网络中断无法及时发送给从节点,所以暂时会将这些命令滞留在复制积压缓冲区中
- 当从节点网络恢复后,从节点再次连上主节点
- 从节点将之前保存的 replicationid 和 offset 作为 psync 的参数发送给主节点,请求进行部分复制
- 主节点接到 psync 请求后,进行必要的验证,随后根据 offset 去复制积压缓冲区查找合适的数据,并响应 +CONTINUE 给从节点
- 主节点将需要从节点同步的数据发送给从节点,最终完成一致性

实时复制流程
- 从节点和主节点完成了数据同步,即从节点这一时刻已经和主节点数据一致了
- 但是之后,主节点还是会源源不断地收到新的修改数据请求
- 主节点上的数据也会随之改变,同时这种改变也需要同步给从节点
具体流程
- 从节点 与 主节点之间建立 TCP 长连接
- 主节点将自己收到的修改数据请求,通过 TCP 长连接发送给从节点
- 从节点再根据这些修改请求,修改内存中的数据
注意:
- 上述流程具有一定的时延
- 正常来说该延时比较短,但是如果是多级从节点的树形主从结构
- 这里的从节点级别越多,时延也就越大
心跳包机制
- 引入该机制来保证? 在进行实时复制时,TCP 连接处于可用状态!
主节点:
- 默认每隔10秒给从节点发送一个 ping 命令,从节点收到就返回 pong
从节点:
- 默认每隔1秒给主节点发起一个特定的请求,上报当前从节点复制数据的进度 (offset)
注意:?
- 从节点返回 pong 的时间阈值默认为 60秒
- 如果 60秒内主节点都没收到 从节点返回的 pong,此时就判定从节点 已挂
总结
主从复制解决的问题
- 单点问题
- 单个 Redis 节点可用性不高
- 单个 Redis 节点性能有限、支持的并发量有限???????
主从复制的特点
- Redis 通过复制功能,实现主节点的多个副本
- 主节点用来写,从节点用来读,这样做可以降低主节点的访问压力
- 复制支持多种拓扑结构,可以在适当的场景选择合适的拓扑结构
- 复制分为全量复制,部分复制和实时复制
- 主从节点之间通过心跳机制保证主从节点通信正常和数据一致性
主从复制配置的过程
- 主节点配置不需要改动
- 从节点在配置文件中加入 slaveof 主节点ip 主节点端口 的形式即可
主从复制的缺点
- 从节点多了,复制数据的延时非常明显
- 主节点挂了,从节点不会升级成主节点,只能通过人工干预的方式恢复
注意:
- 主从复制,最大的问题还是在主节点上
- 主节点挂了,从节点便会十分迷茫
- 虽然能够提供读操作,但是从节点不能自动的升级成主节点
- 即不能替换原有主节点所对应的角色
解决方法
- 程序员 手工恢复主节点,该方法十分非常繁琐且难以预料
- Redis 哨兵 自动的对挂了的主节点进行替换
从节点是否晋升成主节点问题
- 从节点和主节点之间断开连接有两种情况
1、从节点主动和主节点断开连接
- 通过 slaveof no one 命令?
- 这个时候 从节点能够晋升成主节点
- 但是这种情况一般意味着程序员需要主动修改 Redis 的主从结构
2、节点挂了
- 这个时候 从节点不会晋升成主节点
- 必须通过人工干预的方式,恢复主节点
- 这个是脱离咱们掌控的,属于 高可用下的一个典型问题
补充知识点三
- 上文所讲的主从配置存在一个问题
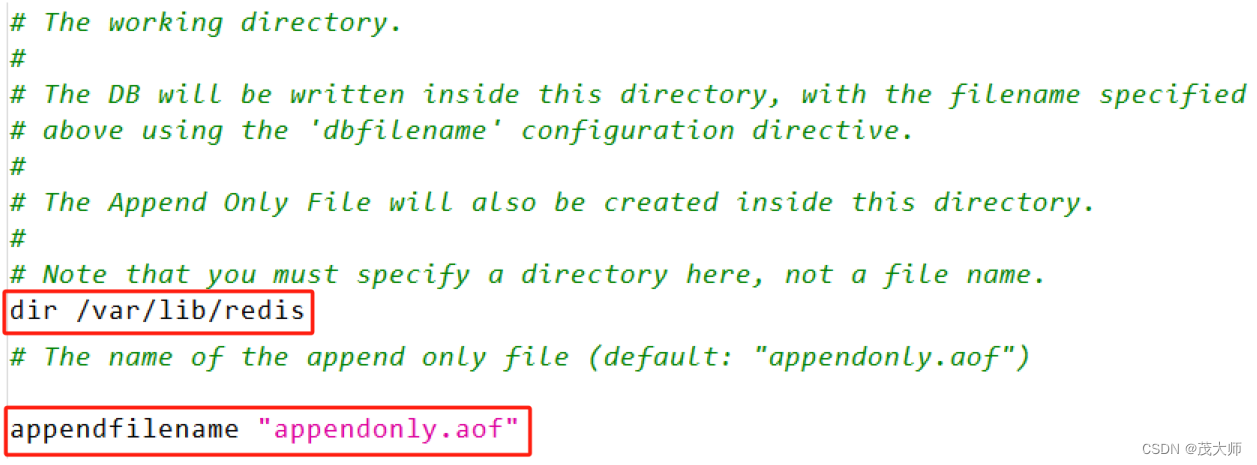
- 即 6379、6380、6381 端口 Redis 服务器 共用同一个 appendonly.aof 文件
- 因为最开始创建从节点的配置文件时,并未修改 dir 和?appendfilename 选项
- 导致三个 Redis 服务器生成的 aof 文件路径 和 文件名 都是同一个
- 但是这三个 Redis 里面的数据是不一样的,所以最好还是各自记录各自的!
注意:
- 之前都是直接通过 手动启动的方式运行的 主节点 和 从节点
- 即 root 用户下启动 redis 服务器,于是生成的 aof 文件也是 root 用户的文件
- 如果需要通过 service redis-server start 命令来启动 Redis 服务器就存在问题
- 因为该方式是通过一个 redis 这样的用户来启动的(所属用户是 redis 用户)
- service redis-server start? 命令主要也是怕通过 root 启动 redis 权限太高,一旦 redis 被黑客攻破了,后果就比较严重
- service redis-server start 命令需要按照可读可写的方式打开这个 aof 文件,而这个文件对于 root 之外的用户只有读权限
- 因此通过?service redis-server start 命令来启动 Redis 服务器便可能因无法打开 aof 文件,进而导致 Redis 服务器启动失败
解决方法:
- 把三个 redis 服务器生成的文件区分开来
- 直接将三个 redis 服务器的工作目录区分开来,即修改配置文件中的 dir 选项
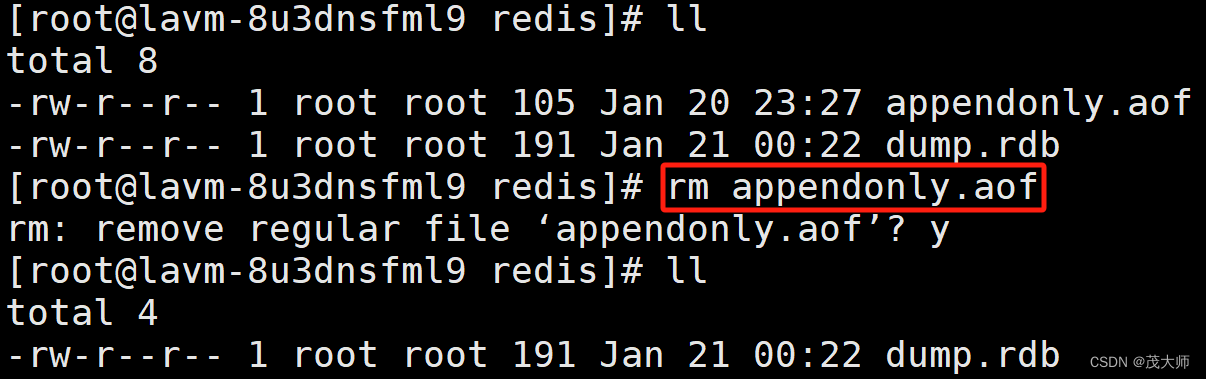
1、停止所有?Redis 服务器
2、删除之前工作目录下已经生成的 aof 文件
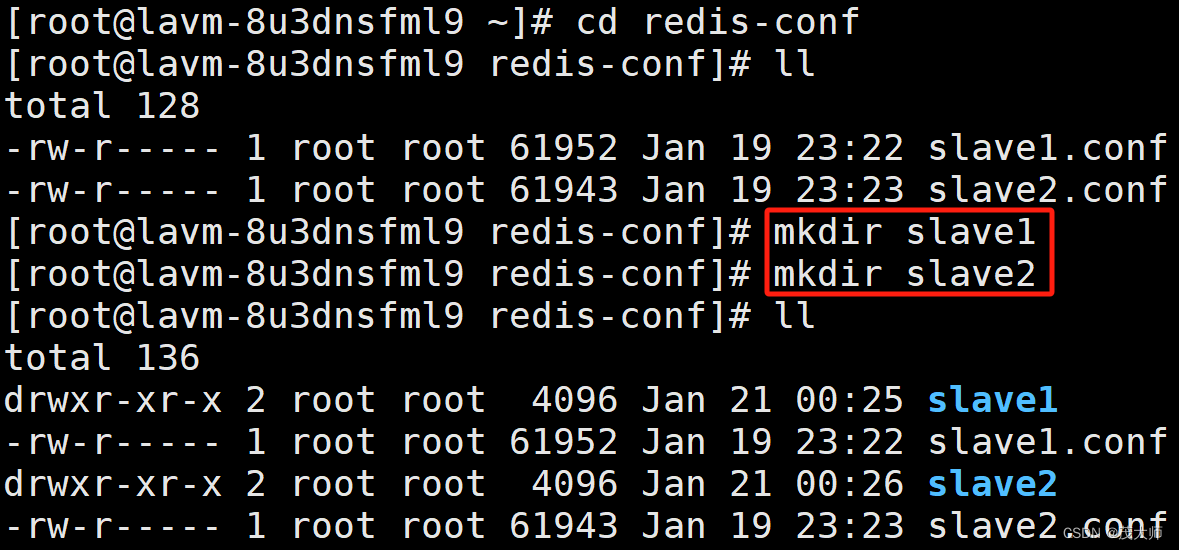
3、给从节点创建出新的目录~用来作为从节点的工作目录
4、修改 从节点的配置文件,设定 新创建的目录为工作目录
5、此时便可支持使用 service redis-server start 命令来启动 Redis 服务器
- 上图示例还是通过手动方式来启动的 Redis 服务器?



文章来源:https://blog.csdn.net/weixin_63888301/article/details/135744915
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 用c语言写个电脑ip更改程序
- GEE python—— MODIS 土地覆被 、MODIS地表温度 (LST) 和 USGS DEM数据进行时序分析/统计和影像裁剪下载
- iPhone抹掉数据后能恢复吗?看完这篇文章你就知道了!
- JavaWeb
- shell 变量
- 饥荒Mod 开发(二三):显示物品栏详细信息
- python基础 10 -- 元组&集合
- 有道翻译web端 爬虫, js
- 【INTEL(ALTERA)】使用Quartus出现系统错误:找不到 MSVCR120.dll
- Unity Binding冲突解决探究