AI大模型中的编码和解码
发布时间:2024年01月21日
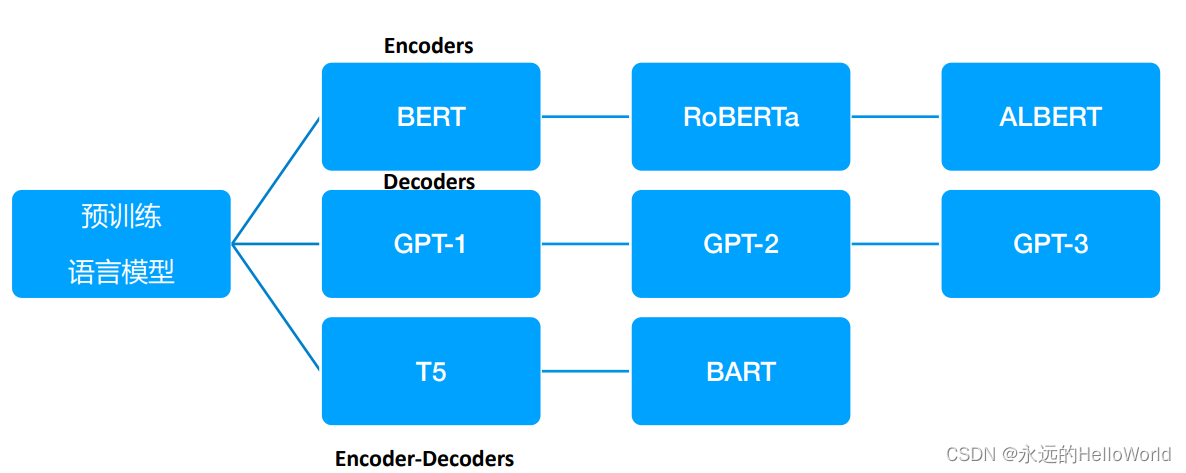
编码器:编码器主要用于处理和理解输入信息。这些模型可以获得双向 的上下文,即可以同时考虑一个词的前面和后面的信息。由于编码器可 以考虑到未来的信息,它们非常适合用于需要理解整个句子的任务,如 文本分类、命名实体识别等。预训练编码器需要使其能够构建强大的表 示,这通常通过预测某个被遮蔽的单词、预测下一个句子或者其它的预 训练任务来实现。BERT就是一种典型的预训练编码器。
解码器:解码器主要用于生成输出信息。它们是语言模型的基础,用于 预测下一个单词。解码器只能考虑到过去的词,而不能考虑到未来的 词,这使得它们非常适合于生成任务,如文本生成、对话系统等。 GPT就是一种典型的预训练解码器。
编码器-解码器:编码器-解码器结构结合了编码器和解码器的优点。编 码器首先处理输入信息,然后解码器生成输出信息。这种结构可以考虑 到全局的上下文信息,因此非常适合于需要理解输入信息并生成相应的 输出的任务,如机器翻译、文本摘要等。如何预训练编码器-解码器模 型是一个开放的问题,因为需要考虑到如何有效地使用编码器和解码器 的特点。T5和BART都是典型的预训练编码器-解码器模型。
文章来源:https://blog.csdn.net/weixin_43882788/article/details/135729496
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 动态规划问题
- WebGL在教育和培训的应用
- Vue+Element Ui实现el-table自定义表头下拉选择表头筛选
- 东方通中间件使用IDEA进行远程打debug
- Java多线程&并发篇----第十六篇
- Django(七)
- 从AMI镜像恢复AWS Amazon Linux 2实例碰到的VNC服务以及Chrome浏览器无法启动的问题
- springboot+mysql+mybatis如何实现控制台打印sql
- SpringCloud微服务架构,适合接私(附源码)
- MT1155-1163总结