RNN:Long Short-term Memory(中)
目录
原视频:李宏毅 2020:Recurrent Neural Network (Part I)
1? LSTM 的简图
LSTM 实际上就是一种特殊的神经元,只是长得比较复杂罢了。可以看出,它就是在 memory 的基础上加了三个门:输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate),四者关系如下图所示:
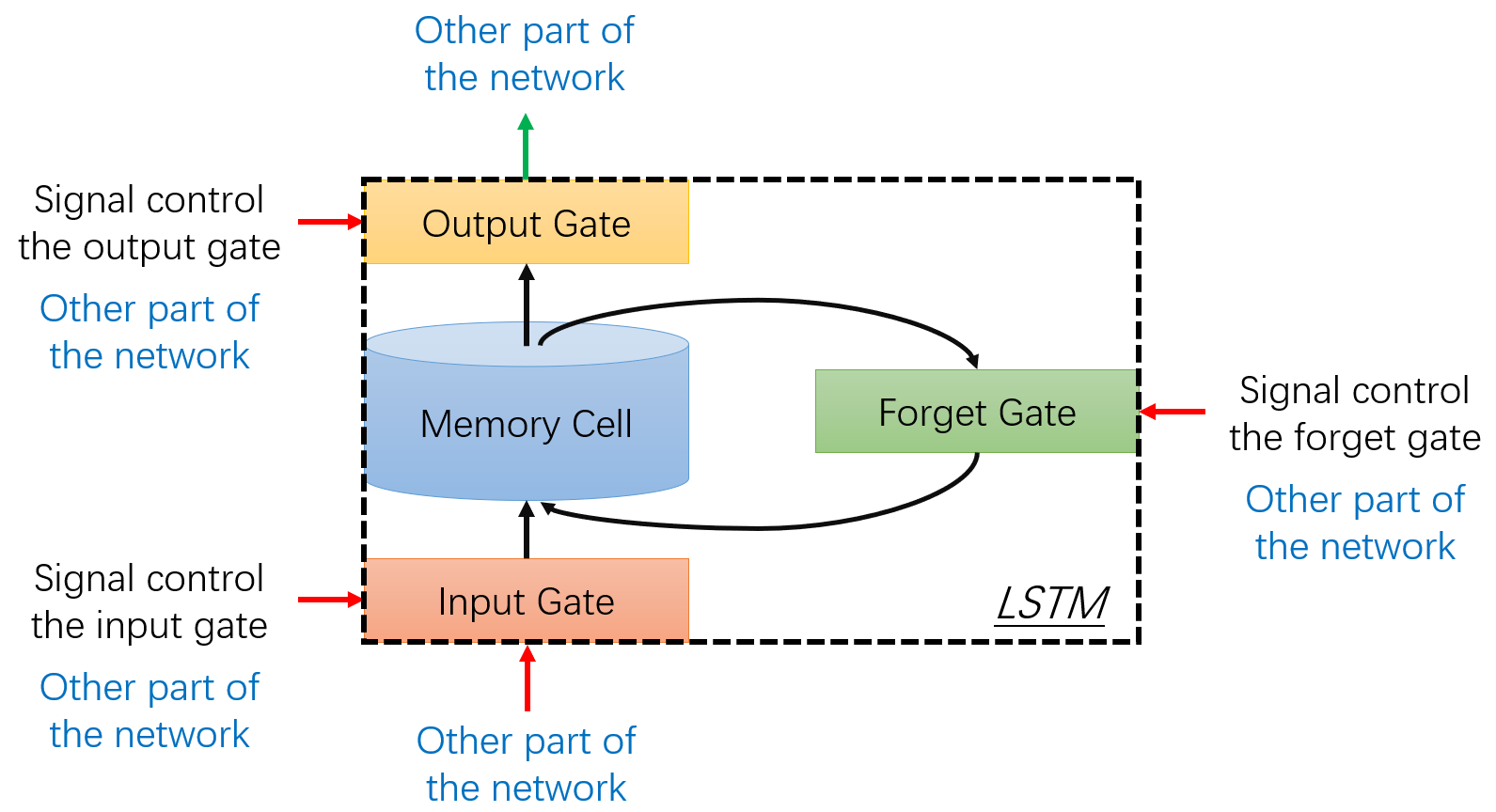
LSTM 三个门的作用:
- 输入门(Input Gate):控制 LSTM 是否接收当前的输入
- 遗忘门(Forget Gate):控制 LSTM 是否丢掉 memory 中的内容
- 输出门(Output Gate):控制 LSTM 是否允许对处理结果进行输出
三个门的开或闭均由信号(signal)控制,这些信号均来自网络的其他部分。
LSTM 的特点是:
- 四个输入,图中用红线表示,输入均来自网络的其他部分
- 一个输出,图中用绿线表示,输出也将送往网络的其他部分
如何理解 Long Short-term Memory 这个名称?它的意思就是 Long 的 Short-term 的 Memory,即虽然长但毕竟还是短期的记忆。在 RNN 中,一旦计算出当前时刻隐层的输出,那么 memory 中的内容会立马被冲掉或者说是被替换掉。而在 LSTM 中,有了输入门(Input Gate)和遗忘门(Forget Gate)的控制,memory 中的内容可能不变,也可能只变一部分。因此在一定程度上,LSTM 延长了对某些信息的记忆时间,所以是 Long 的。
2? LSTM 的整体结构
这一节来看 LSTM 具体长啥样。
2.1? 结构图
下图就是把 LSTM 中的内容细化了,没有想象的那么复杂:
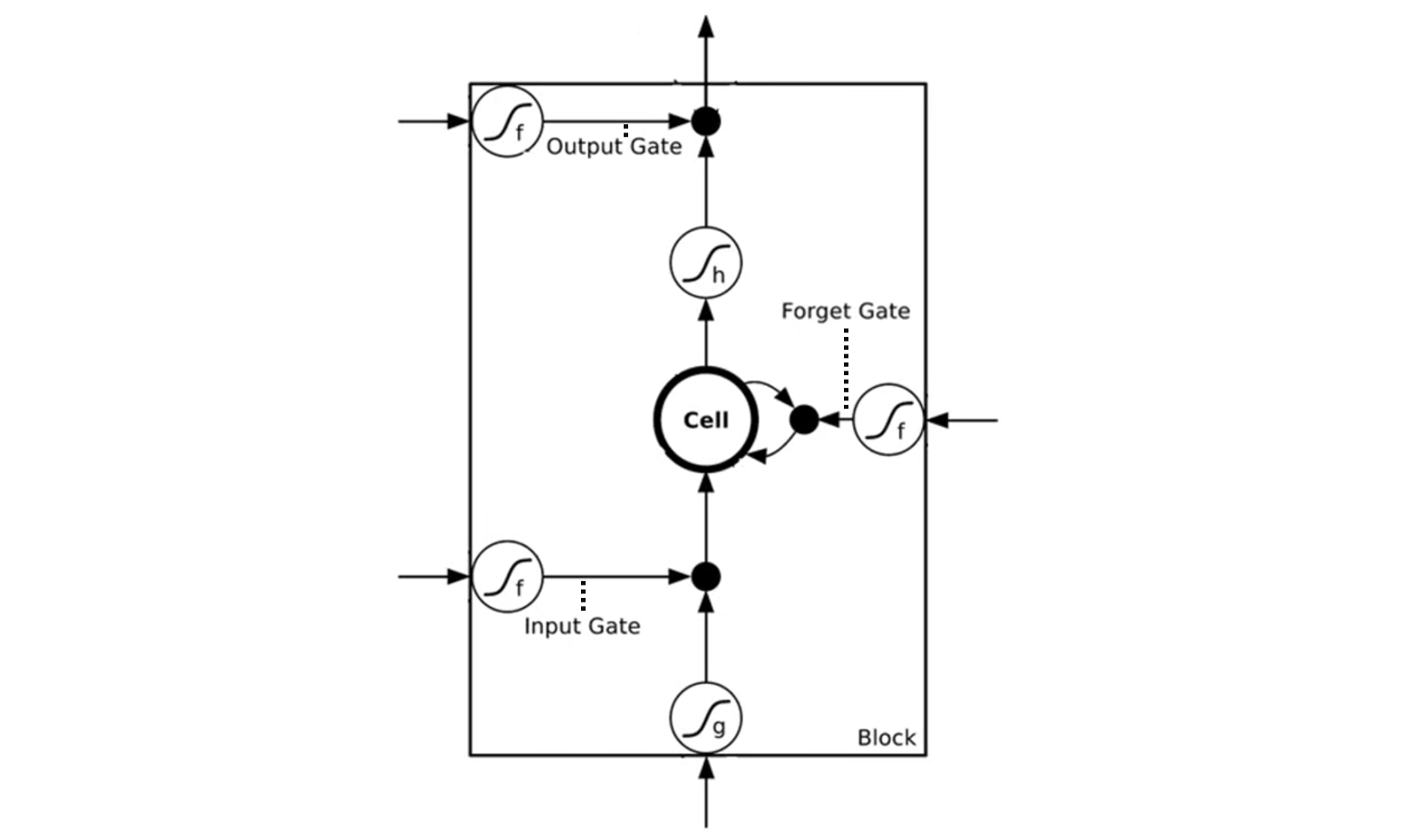
图中的黑色虚线指明了输入门(Input Gate)、遗忘门(Forget Gate)和输出门(Output Gate)其实就是激活函数的输出。这里的激活函数用的是 Sigmod,输出的值在 0 到 1 之间,用于表示开门的程度。
门不是想象中的要么开要么闭,而是可以半开半闭。
2.2? 流程图
下图使用各种变量符号标注了 LSTM 的处理流程:
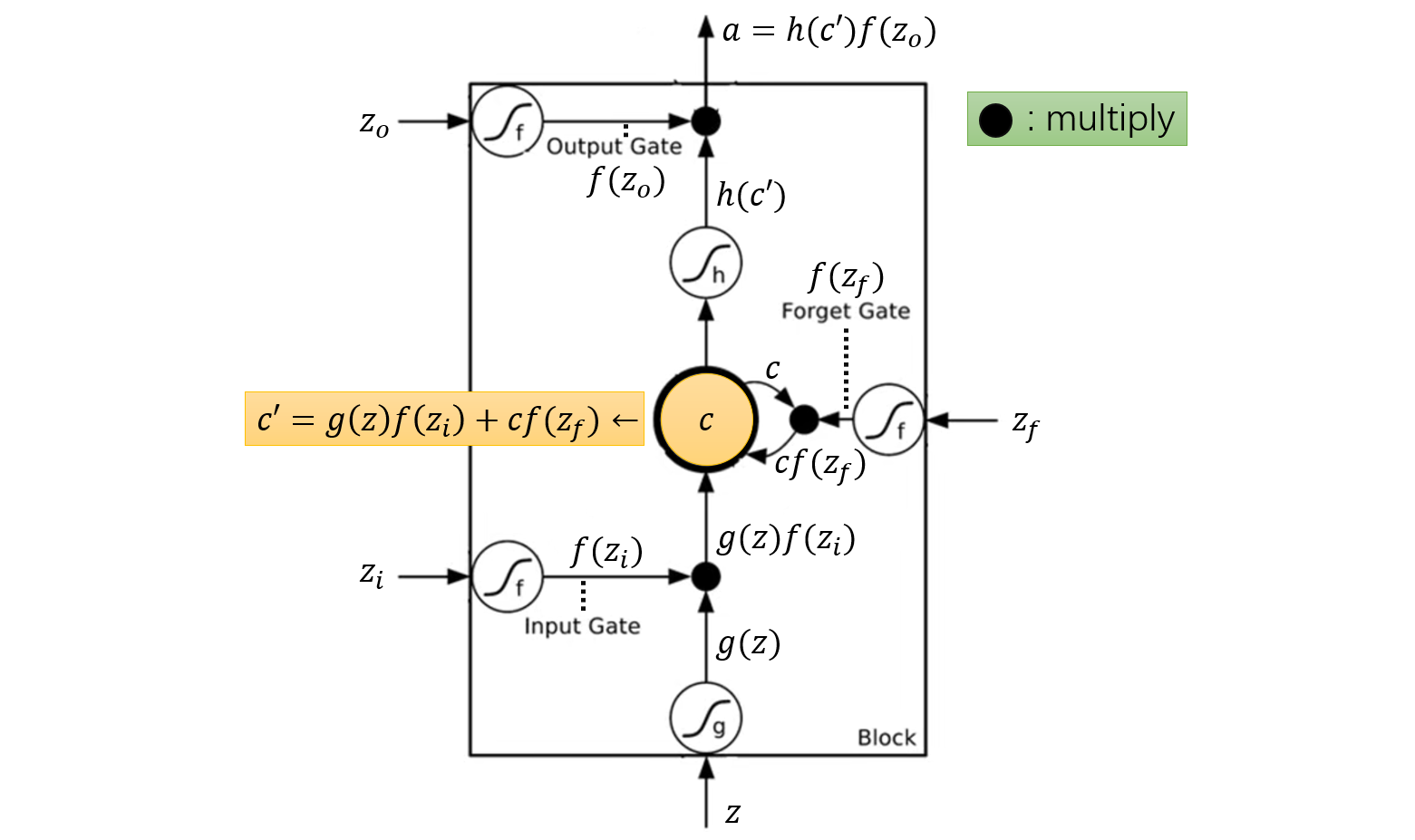
可以看出,LSTM 门控的方式就是 “乘法”(multiply)。乘的数字越接近于 1,输入、记住、或输出的越多;乘的数字越接近于 0,输入、记住、或输出的越少。
遗忘门(Forget Gate)是反着来的,越接近于 1 遗忘的越少,越接近于 0 遗忘的越多。
3? 举个例子
李宏毅老师先是直接让我们感受各个门的作用,然后才是代入 LSTM 中进行说明。
3.1? 简单看看
下图中,x_1、x_2 和 x_3 是一个输入向量的不同维度,并不是三个输入。这里没有让我们通过激活函数算各个门的值,而是用底部的三句话指明了处理规则:

三句话的含义:
- 若 x_2 = 1,则把 x_1 的值送入 memory 中与其内容相加
- 若 x_2 = -1,则把 memory 中的内容清空,即进行遗忘
- 若 x_3 = 1,则输出处理结果,否则不输出
根据这三条规则,我们便画出了上图。
3.2? 代入 LSTM
假设这是我们训练好的 LSTM,黑色箭头上的数字表示这条线权重:
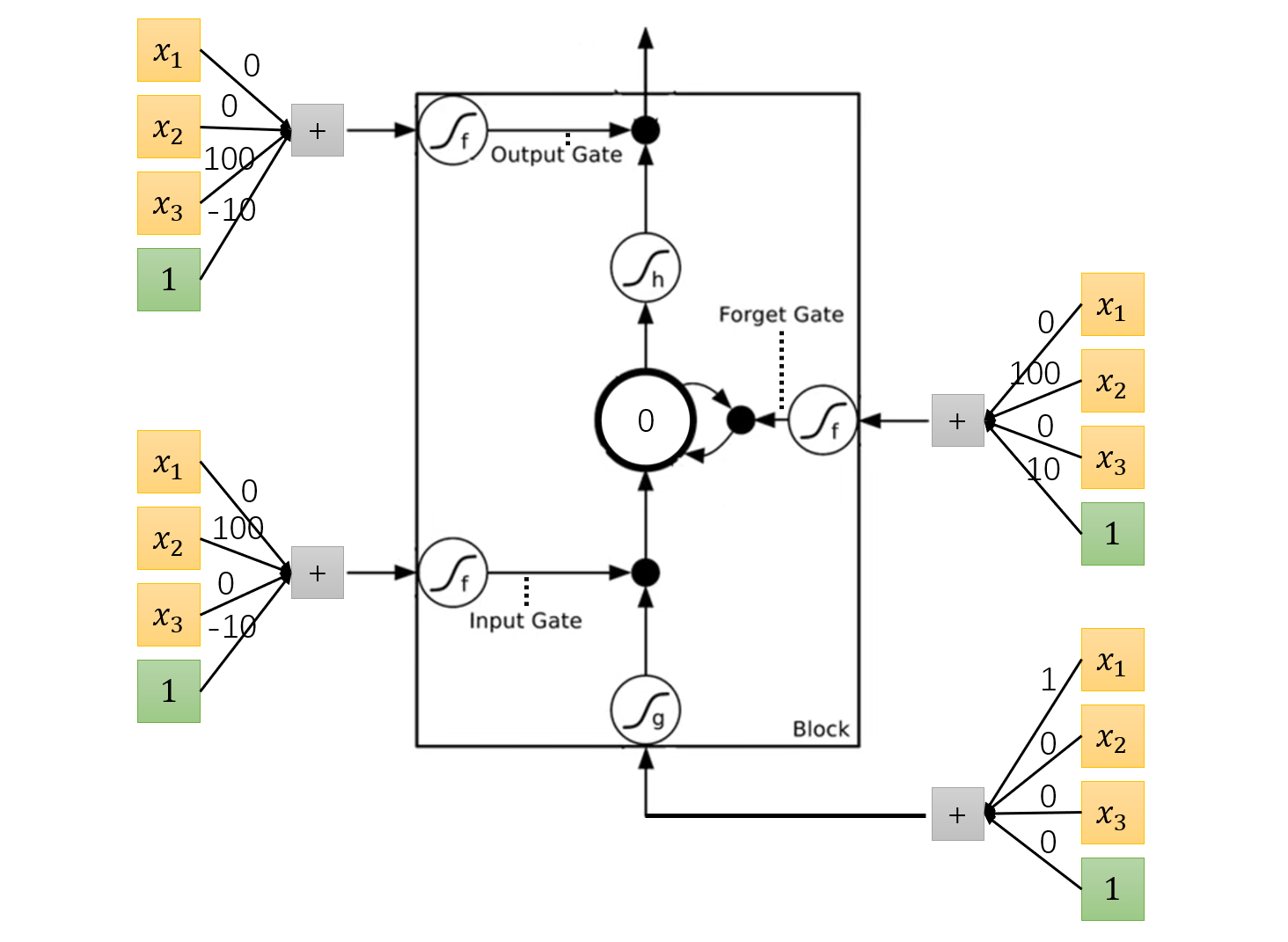
我们可以先来看看。对于左上角的那组权重,如果 x_3 较大,那么经 Sigmoid 处理的结果就会接近于 1,表示输出门(Output Gate)打开。反之,如果 x_3 较小,那么经 Sigmoid 处理的结果就会接近于 0,表示输出门(Output Gate)关闭。
由于画图过于痛苦,所以这里只演示一组处理过程:
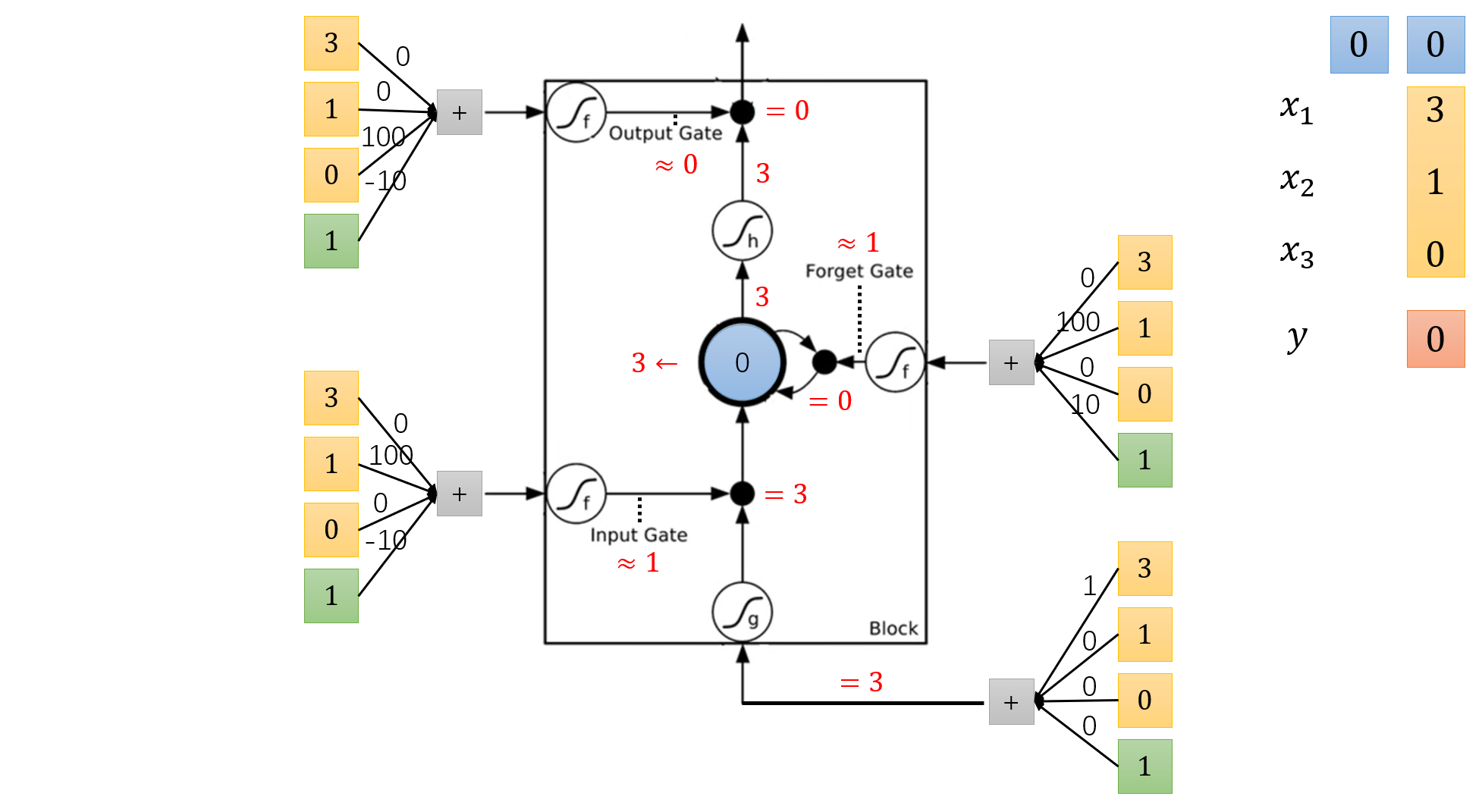
为了简化例子,李宏毅老师还是假设除 Sigmoid 以外的激活函数均为线性函数,并且权重均为 1 。
4? Original Network v.s. LSTM
或许我们会认为 LSTM 这么复杂,看起来和 FFN 没有什么关系啊?事实上,LSTM 只是把 FFN 中的神经元替换为了 LSTM 单元罢了,并且 LSTM 单元也就是个特殊的神经元。
在 FFN 中,一个神经元只要求 x_1 和 x_2 输入一次。而在 LSTM 中,一个 LSTM 单元要求 x_1 和 x_2 输入四次:
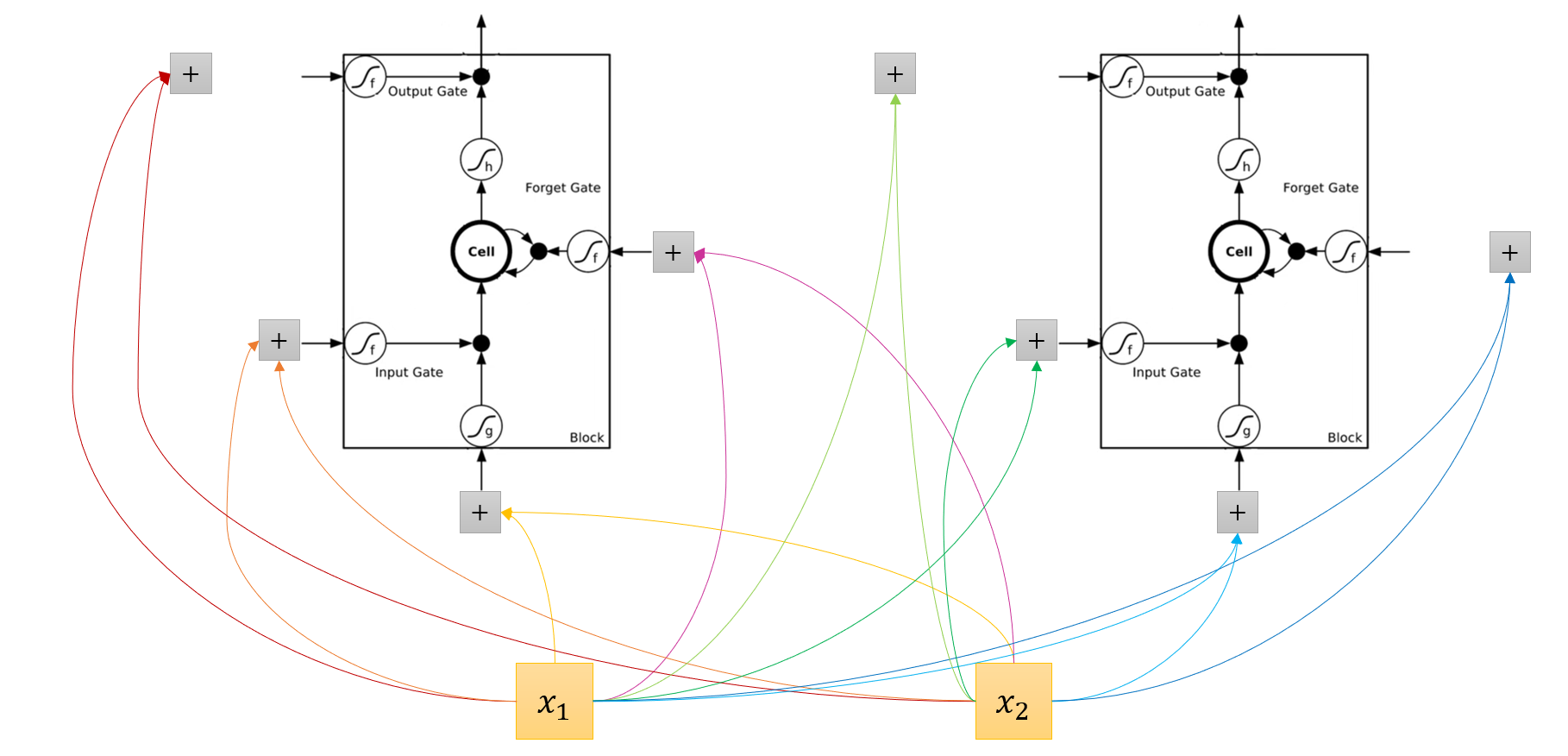
同样地,x_1 和 x_2 是一个输入向量的不同维度,而不是两个输入。此外,图中相同颜色的连线,只表示 x_1 和 x_2 使用的是同一组权重,而不代表它们各自乘的权值相同。
5? 细看 LSTM
t 时刻的输入 x_t 是一个输入向量,而不是一个维度。x_t 与不同的权值矩阵相乘后得到 z_f、z_i、z、z_o,z_f、z_i、z、z_o 也是一个向量而不是一个维度。最后分别把 z_f、z_i、z、z_o 的各个维度送入到各个 LSTM 单元的不同门处:
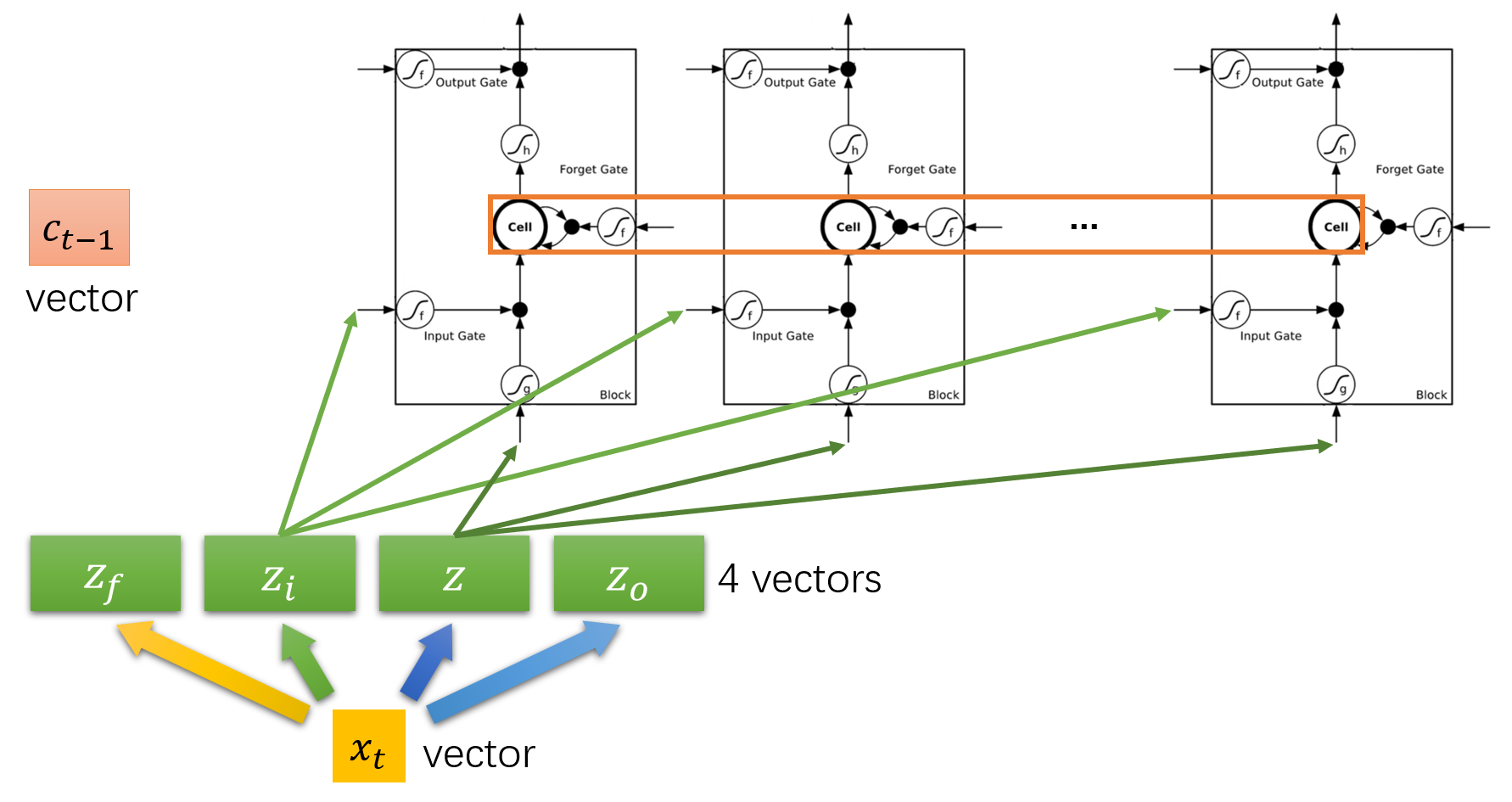
c_{t-1} 也是一个向量而不是一个维度,它是 t-1 时刻所有 memory 内容的集合。
有请神图 1 号登场:

通过这张图可以看出,从输入 x_t 到输出 y_t 都是用的矩阵运算。即每次处理的对象都是整个矩阵,而不是挨个输入 x_t 的每个维度,再挨个计算。
有请神图 2 号登场:
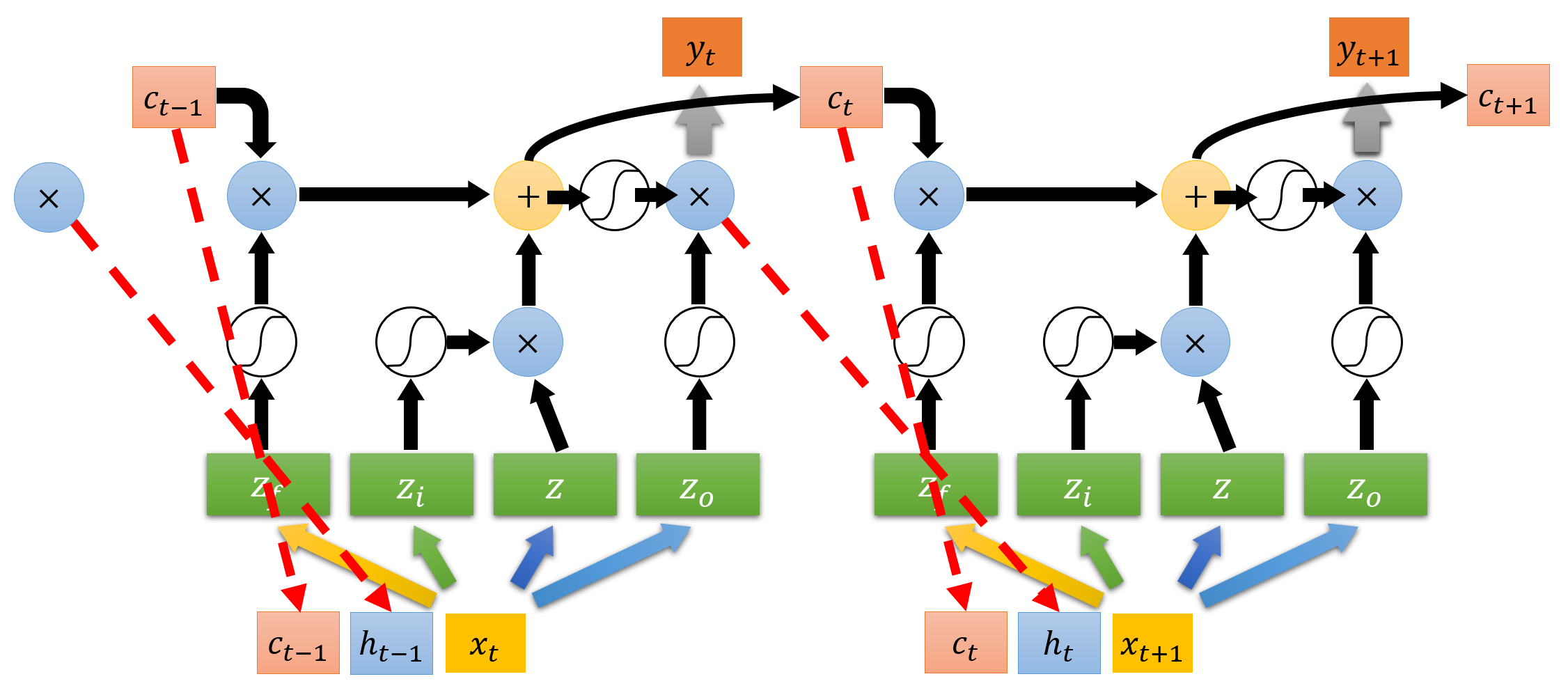
这张图完美诠释了 LSTM 是怎么将不同时刻的输入关联起来的。
图中的红色虚线是指,在高级的 LSTM 中,memory 的内容 c_t 和隐层输出 h_t 也会被拉来和 x_{t+1} 一起当输入。
写完这篇再也不想画图了(bushi)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- charles使用指南
- hadoop之HDFS文件系统命令操作
- shell实现折线图
- 正点原子RV1126编译环境搭建+rkmedia编译
- C语言操作符if语句好习惯 详解分析操作符(详解4)
- C++学习——LocalCTP踩坑之 what(): locale::facet::_S_create_c_locale name not valid
- 【机组期末速成】CPU的结构与功能|CPU结构|指令周期概述|指令流水线|中断系统
- 四种自动化测试模型实例及优缺点
- 103、GAUDI: A Neural Architect for Immersive 3D Scene Generation
- 动态分配内存与释放