目标检测-Owo Stage-YOLOv2
发布时间:2024年01月02日
前言
根据前文目标检测-One Stage-YOLOv1可以看出YOLOv1的主要缺点是:
- 和Fast-CNN相比,速度快,但精度下降。(边框回归不加限制)
YOLOv2提出了一些改进策略,如anchor-based等
提示:以下是本篇文章正文内容,下面内容可供参考
一、YOLOv2的网络结构和流程
- 将影像输入卷积网络(DarkNet-19+残差连接)得到13 × 13特征图
- 引入anchor机制,与SSD不同的是,每个特征点对应5个anchor,且anchor的大小是由VOC 和 COCO数据集聚类得到的
ps:由于变为anchor-based算法,预测框由YOLOv1的98个变为845(13 × 13 × 5)个,mAP由69.5略微降到69.2,召回率却由81大大提升至88
- 将上一步得到的anchor输入分类和边框回归器
- 使用非极大值抑制NMS去除冗余窗口
下图可以比较清晰的看出YOLOv2的主要结构
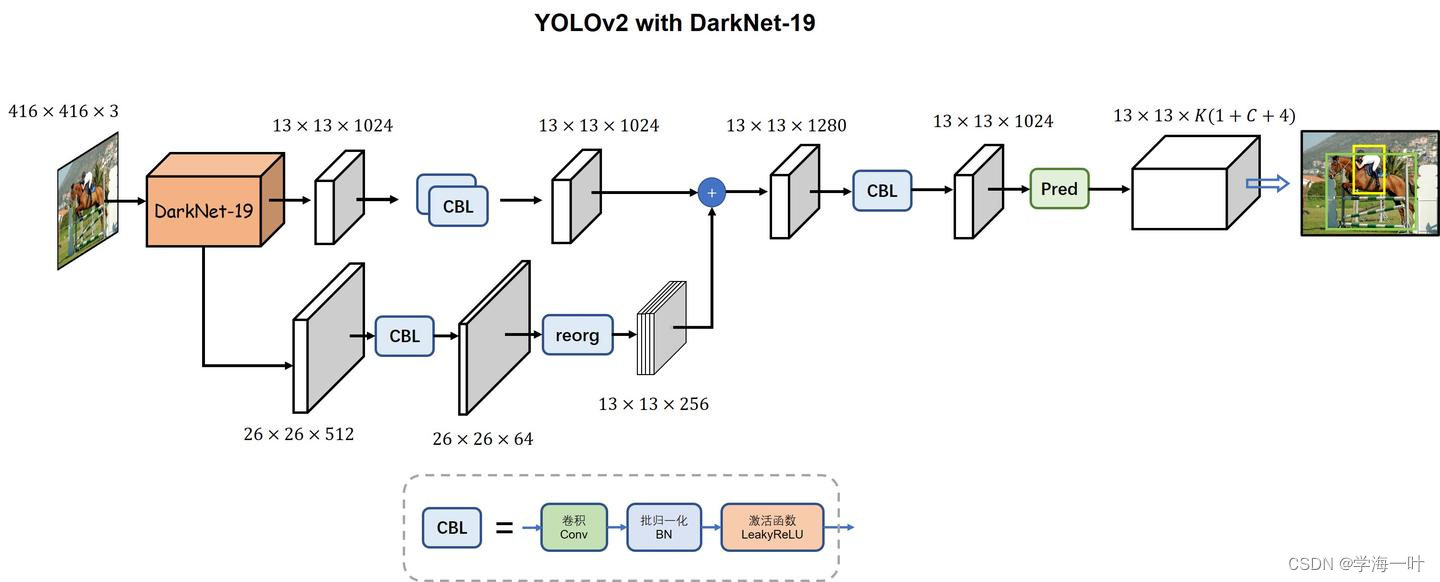
其中,DarkNet-19的结构如下:

更详细的参数如下:
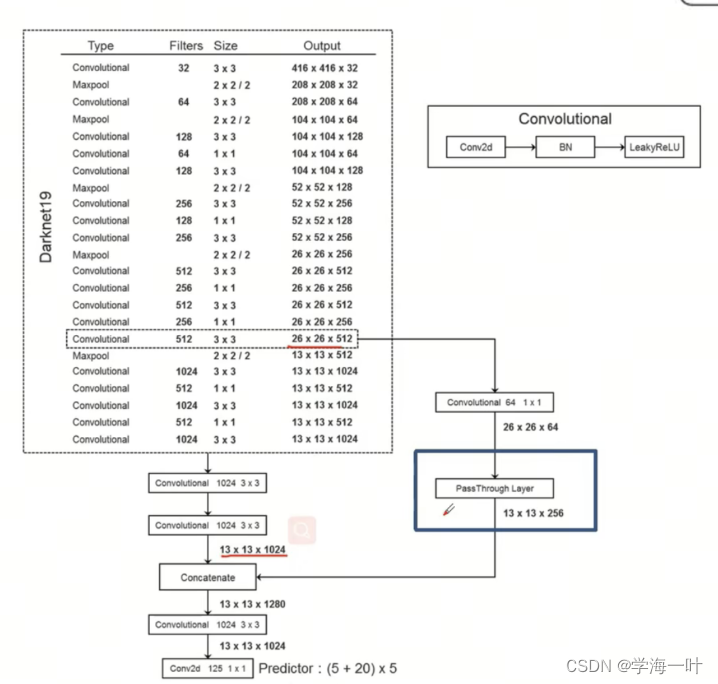
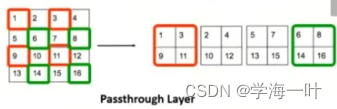
ps:上图中可以看出,残差连接时要保证两个特征图w,h的一致(从通道上进行拼接),这里通过PassThrough层将之前层的特征图进行了w,h的缩放,以和更深层特征图保持一致,PassThrough层的基本原理如下图:
之所以不用池化下采样,是想通过PassThrough保留featureMap的更多细节
二、YOLOv2的创新点
预处理
- 使用了标准的数据增强方法:随机裁剪、旋转(random crops, rotations);色调、饱和度(hue, saturation);曝光偏移(exposure shifts)
网络结构
- backbone:改为Darknet-19,Darknet-19 的性能基本与 Resnet34 差不多,使得网络更轻量更快
- 引入了BN(Batch normalization),其优点如下:
- 加快收敛;
- 改善梯度,远离饱和区;
- 允许大的学习率;
- 对初始化不敏感;
- 相当于正则化,使得有BN层的输入都有相近的分布;
- 有了BN之后,就可以不用dropout了,或者说不能像原来一样用dropout了,这会导致训练和测试的方差偏移。
- 加入了anchor机制
- 细粒度特征(Fine-Grained Features):将最后一个最大池化层前的特征图经过Pass Through与后面的卷积特征图进行合并,Pass Through就是四分后再concat
训练
- 高分辨率的预训练,采用了448的输入进行微调,以便网络更好地处理更高分辨率的输入
- 多尺度训练:Yolov2每10个batches就会随机换一下输入的尺度({320, 352, …, 608}),使得模型泛化于不同尺度的输入,这得益于adaptive pooling层。高分辨率的输入速度慢,但是对小目标的检测效果要好很多,低分辨率的输入速度快
- loss略微改动:(真阳样本的定位误差、confidence误差、分类误差)、预测框和anchor定位误差、负样本置信度误差,且5个子loss均有一个权重超参数
- 预测输入从448变为416,目的是让得到的feature map的size是一个奇数。这样的好处是,许多图片的中心点都是某个物体的中心,奇数保证中间是一个格子,而不是偶数那样四个格子抢占中心点
- 尝试了一种分类和检测的联合训练策略,类别数据集用于分类训练,检测数据集用于边框回归和分类,同时为了统一COCO数据集和ImageNet数据集类别,提出了一种层级分类方法
总结
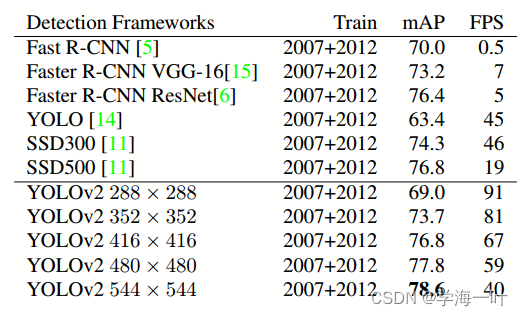
通过网络结构和改进和一些tricks,YOLOv2精度大大提升,同时通过多尺度训练,使得相同的YOLOv2模型可以在不同的大小下运行,从而轻松实现速度和精度之间的折衷。
- 在67 FPS的速度下,YOLOv2在VOC 2007上达到76.8mAP。
- 在40 FPS的速度下,YOLOv2在VOC 2007上达到78.6mAP,性能优于当时的SOTA,如SSD和Faster RCNN ResNet,同时运行速度更快。
文章来源:https://blog.csdn.net/long11350/article/details/135286340
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 43.5k star Android架构最佳实践项目
- 如何解决安装Windows11时出现“这台电脑无法运行Windows11”
- MULTISCALE DOMAIN ADAPTIVE YOLO FOR CROSS-DOMAIN OBJECT DETECTION
- C与C++队列实现
- JS新手入门笔记整理:JS语法基础
- (每日持续更新)jdk api之ByteArrayInputStream基础、应用、实战
- 我是如何实现长期被动引流的,学会这招永不过时
- Jetson Orin AGX 64GB更新 Jetpack6.0
- 移动端对大批量图片加载的优化方法(四)
- 你能描述下你对vue生命周期的理解?在created和mounted这两个生命周期中请求数据有什么区别呢?