强化学习与推荐系统结合

强化学习与推荐系统结合,是在智能体的学习过程中,会根据外部反馈信息,改变自身状态,在根据自身状态进行决策,就是行动反馈,状态更新,在行动的循环。
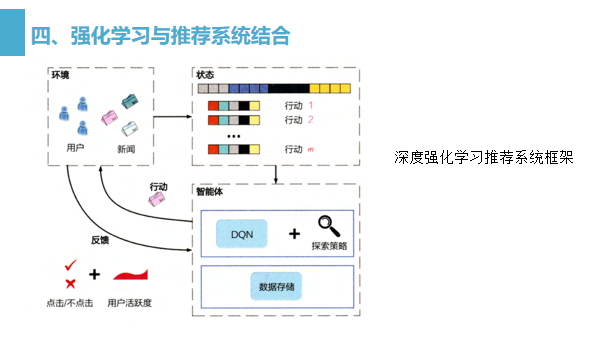
深度强化学习推荐系统框架是基于强化学习的经典过程提出的,
如图 所示,框架图非常清晰地展示了深度强化学习推荐系统框架的各个组成部分,
智能体:推荐系统本身,它包括基于深度学习的推荐模型、探索 (explore)策略,以及相关的数据存储(memory )。
环境:由新闻网站或 App、用户组成的整个推荐系统外部环境。在环境中用户接收推荐的结果并做出相应反馈
行动:对一个新闻推荐系统来说,“行动”指的就是推荐系统进行新闻排序后推送给用户的动作。
反馈:用户收到推荐结果后,进行正向的或负向的反馈。例如,点击行为被认为是一个典型的正反馈,曝光未点击则是负反馈的信号。此外,用户的活跃程度,用户打开应用的间隔时间也被认为是有价值的反馈信号。
状态:状态指的是对环境及自身当前所处具体情况的刻画。在新闻推荐场景中,状态可以被看作已收到所有行动和反馈,以及用户和新闻的所有相关信息的特征向量表示。站在传统机器学习的角度,“状态”可以被看作已收到的、可用于训练的所有数据的集合。
在这样的强化学习框架下,模型的学习过程可以不断地迭代,迭代过程主要有如下几步:
(1)始化荐系统(能体)。
(2)推荐系统基于当前已收集的数据(状)进行新闻排序(行动),并推送到网站或 App(环境)中。
(3)用户收到推荐列表,点击或者忽略(反馈)某推荐结果
(4)推荐系统收到反馈,更新当前状态,或通过模型训练更新模型
( 5) 然后再基于收集到的数据进行探索,这就是整体的一个循环。
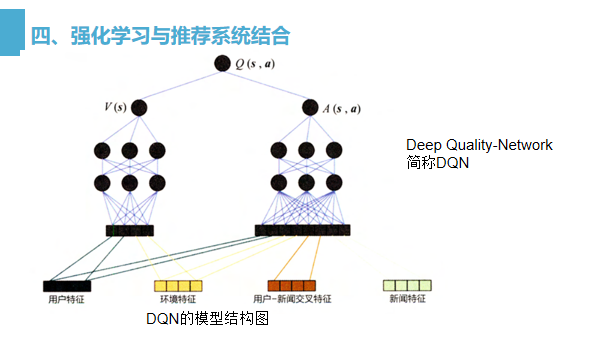
DQN是指通过对行动进行质量评估,以此进行行动决策,DQN 的网络结构如图 所示,在特征工程中套用强化学习状态向量和行动向量的概念,把用户特征(user features ) 和环境特征 ( context features )归为状态向量,因为它们与具体的行动无关;把用户-新闻交叉特征和新闻特征归为行动特征,因为其与推荐新闻这一行动相关。
用户特征和环境特征经过左侧多层神经网络的拟合生成价值 (value ) 得分V(s),利用状态向量和行动向量生成优势 (advantage) 得分 A(s,a),最后把两部分得分综合起来,得到最终的质量得分 Q(s,a)。
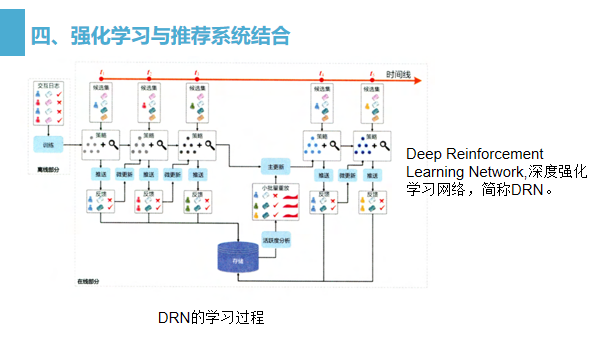
DRN 的学习过程是整个强化学习推荐系统框架的重点,正是由于可以在线更新,才使得强化学习模型相比其他“静态”深度学习模型有了更多实时性上的优势。图中以时间轴的形式形象地描绘了 DRN的学习过程。
按照从左至右的时间顺序,依次描绘 DRN 学习过程中的重要步骤
(1)在离线部分,根据历史数据训练好 模型,作为智能体的初始化模型
(2)在 t1-t2 阶段,用初始化模型进行一段时间的推送(push) 服务,积累反馈 ( feedback)数据。
(3)在t2时间点,利用t1-t2阶段累的用户点击数据进行模型微更新( minorupdate ).
(4)在 t4时间点,利用t1-t4阶的用户点击数据及用户活跃度数据进行模型的主更新(major update )。
(5)重复第 2~4 步
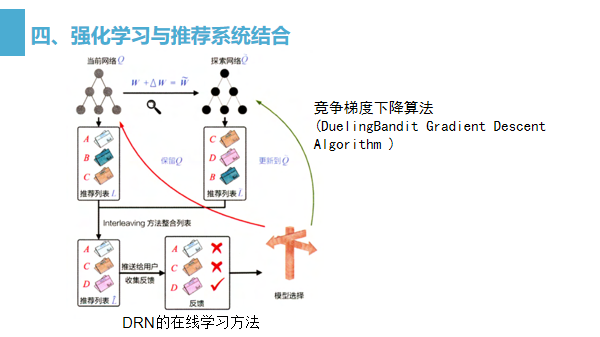
在上一步模型主更新操作可以理解为利用历史数据的重新训练,用训练好的模型替代现有模型。
那么在第 3 步中提到的模型微调,这就牵扯到 DRN 使用的一种新的在线训练方法一竞争梯度下降算法(DuelingBandit Gradient Descent Algorithm )
(1)对于已经训练好的当前网络 ,对其模型参数 w 添加一个较小的随机扰动W,得到新的模型参数W,这里称W对应的网络为探索网络Q。
(2)对于当前网络 O和探索网络分别生成推荐列表 L和用Interleaving将两个推荐列表组合成一个推荐列表后推送给用户
(3)实时收集用户反馈。如果探索网络生成内容的效果好于当前网络 .则用探索网络代替当前网络,进入下一轮迭代;反之则保留当前网络。
这就是竞争梯度下降算法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- hcip实验2
- 在浏览器中进行深度学习:TensorFlow.js (八)生成对抗网络 (GAN)
- 《动手学深度学习》学习笔记 第5章 深度学习计算
- K-th Beautiful String
- 【ARM学习】Cortex- A系列程序员学习指南
- labelimage标注label批量修改标签
- SOCKET
- git拉取远程分支到本地
- RK3568驱动指南|第十二篇 GPIO子系统-第136章 实战:实现动态切换引脚复用功能
- 关于MySQL源码的学习 这里是一些建议