PointNet人工智能深度学习简明图解
PointNet 是一种深度网络架构,它使用点云来实现从对象分类、零件分割到场景语义解析等应用。 它于 2017 年实现,是第一个直接将点云作为 3D 识别任务输入的架构。
本文的想法是使用 Pytorch 实现 PointNet 的分类模型,并可视化其转换以了解模型的工作原理。
如果你不知道点云是什么……它只是对象或场景的 3D 表示,通常从 LiDAR(光检测和测距)传感器收集。 这些传感器发射光脉冲,然后测量它们返回传感器所需的时间。 此信息可用于创建对象或场景的 3D 模型,如上面的模型。 LiDAR 传感器变得越来越流行,你可以在自动驾驶汽车、无人机、测绘飞机甚至某些智能手机中找到它们!
1、Pointnet训练数据集
为了简单起见,我们将使用著名的 MNIST 数据集,我们可以直接使用 Pytorch 下载该数据集。
MNIST 包含 60,000 张手写数字图像,从 0 到 9。

PointNet 处理由三个坐标 (x, y, z) 表示的点,因此我们将把 2D 图像转换为 3D 点云,如下图所示。

MNIST 样本是 28 x 28 像素的灰度图像。 像素值是范围从 0(黑色)到 255(白色)的整数。 我们想要将数字的每个像素转换为一个点。 函数transform_img2pc过滤图像中值高于127的像素并获取它们的索引。
import numpy as np
def transform_img2pc(img):
img_array = np.asarray(img)
indices = np.argwhere(img_array > 127)
return indices.astype(np.float32)一旦我们将像素转换为点,我们需要所有点云具有相同数量的点,以便我们可以将它们输入到 PointNet 中。 PointNet 的作者使用每个对象 2500 个点,我们将绘制每个数字的点的直方图来确定阈值。
from torchvision.datasets import MNIST
import matplotlib.pyplot as plt
dataset = MNIST(root='./data', train=True, download=True)
len_points = []
# loop over samples
for idx in range(len(dataset)):
img,label = dataset[idx]
pc = transform_img2pc(img)
len_points.append(len(pc))
h = plt.hist(len_points)
plt.title('Histogram of amount of points per number')
我们将点数固定为 200,因为最大点数为 312,并且大多数点都在 200 以下。我们可能面临两种情况,点云高于 200 点和点云低于此阈值。
- 当点数超过 200 时,我们将对点进行随机采样。
- 相反,我们将随机复制现有点。
最后,我们将向所有产生均值为零、标准差为 0.05 的高斯噪声的点添加第三个分量 z。
让我们将数据处理包装在自定义 Dataset 类中。
from torch.utils.data import Dataset
class MNIST3D(Dataset):
"""3D MNIST dataset."""
NUM_CLASSIFICATION_CLASSES = 10
POINT_DIMENSION = 3
def __init__(self, dataset, num_points):
self.dataset = dataset
self.number_of_points = num_points
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
img,label = dataset[idx]
pc = transform_img2pc(img)
if self.number_of_points-pc.shape[0]>0:
# Duplicate points
sampling_indices = np.random.choice(pc.shape[0], self.number_of_points-pc.shape[0])
new_points = pc[sampling_indices, :]
pc = np.concatenate((pc, new_points),axis=0)
else:
# sample points
sampling_indices = np.random.choice(pc.shape[0], self.number_of_points)
pc = pc[sampling_indices, :]
pc = pc.astype(np.float32)
# add z
noise = np.random.normal(0,0.05,len(pc))
noise = np.expand_dims(noise, 1)
pc = np.hstack([pc, noise]).astype(np.float32)
pc = torch.tensor(pc)
return pc, labelDataset存储预处理后的样本及其相应的标签,现在我们需要定义一个DataLoader来迭代训练循环中的数据。
下载 MNIST 数据后,我们将连接默认分区(训练和测试)并将数据输入到我们的自定义 MNIST3D 数据集中。 然后,我们将数据集分为训练(80%)、验证(10%)和测试(10%),并为每个分区生成一个 DataLoader,批量大小为 128。
train_dataset = MNIST(root='./data/MNIST', download=True, train=True)
test_dataset = MNIST(root='./data/MNIST', download=True, train=False)
dataset = torch.utils.data.ConcatDataset([train_dataset, test_dataset])
dataset_3d = MNIST3D(dataset, number_of_points)
l_data = len(dataset_3d)
train_dataset, val_dataset, test_dataset = random_split(dataset_3d,
[round(0.8*l_data), round(0.1*l_data), round(0.1*l_data)],
generator=torch.Generator().manual_seed(1))
train_dataloader = DataLoader(train_dataset, batch_size=128, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=128, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=128, shuffle=False)最后,我们绘制一些样本来检查点云是否正确生成。 你还可以使用我们笔记本的实现来生成类似上面的很酷的 3D gif。
pc = train_dataset[5][0].numpy()
label = train_dataset[5][1]
fig = plt.figure(figsize=[7,7])
ax = plt.axes(projection='3d')
sc = ax.scatter(pc[:,0], pc[:,1], pc[:,2], c=pc[:,0] ,s=80, marker='o', cmap="viridis", alpha=0.7)
ax.set_zlim3d(-1, 1)
plt.title(f'Label: {label}')
现在数据已经准备好了,我们可以专注于模型了!
2、Pointnet的体系结构和属性
PointNet由分类网络和分割网络组成。 分类网络以n个点(x,y,z)作为输入,使用T-Net应用输入和特征变换,然后通过最大池化聚合点特征。 输出是 k 个类别中每个类别的分类分数。 分割网络是分类网络的扩展。 它连接全局和局部特征并输出每点分数。

pointNet 的架构受到点集属性的启发,它们是一些设计选择的关键……让我们来检查一下!
1、无序。 与图像中的像素阵列不同,点云是一组没有特定顺序的点。
- 要求:模型需要对点的排列保持不变。
- 解决方案:使用最大池化层作为对称函数来聚合所有点的信息。 最大池化,如 * 和 +,是对称函数,因为输入的顺序不会改变结果。
2、点之间的交互。 这些点来自具有距离度量的空间。 这意味着点不是孤立的,相邻点形成一个有意义的子集。
- 要求:模型需要能够捕获附近点的局部结构。
- 解决方案:结合局部和全局特征进行分割。
3、变换下的不变性。 学习到的点集表示对于某些变换应该是不变的。
- 要求:同时旋转和平移点不应修改全局点云类别或点的分割。
- 解决方案:使用空间转换器网络,尝试在 PointNet 处理数据之前将数据转换为规范形式。 T-Net 是一种用于对齐输入点和点特征的神经网络。
可以在下面的代码中看到 T-Net(输入变换和 feature_transform)、最大池化(MaxPool1d)和特征生成(局部和全局)的使用。 ClassificationPointNet 返回每个点云的对数概率、损失正则化所需的特征变换以及用于绘图目的的最后两个元素(tnet_out、ix_maxpool)。
在下一节中,我们将更详细地介绍 T-Net 的实施、它的工作原理以及提供的好处。
class BasePointNet(nn.Module):
def __init__(self, point_dimension):...
def forward(self, x, plot=False):
num_points = x.shape[1]
input_transform = self.input_transform(x) # T-Net tensor [batch, 3, 3]
x = torch.bmm(x, input_transform) # Batch matrix-matrix product
x = x.transpose(2, 1)
tnet_out=x.cpu().detach().numpy()
x = F.relu(self.bn_1(self.conv_1(x)))
x = F.relu(self.bn_2(self.conv_2(x)))
x = x.transpose(2, 1)
feature_transform = self.feature_transform(x) # T-Net tensor [batch, 64, 64]
x = torch.bmm(x, feature_transform) # local point features [batch, 200, 64]
x = x.transpose(2, 1)
x = F.relu(self.bn_3(self.conv_3(x)))
x = F.relu(self.bn_4(self.conv_4(x)))
x = F.relu(self.bn_5(self.conv_5(x)))
x, ix = nn.MaxPool1d(num_points, return_indices=True)(x) # max-pooling
x = x.view(-1, 1024) # global feature vector [batch, 1024]
return x, feature_transform, tnet_out, ix
class ClassificationPointNet(nn.Module):
def __init__(self, num_classes, dropout=0.3, point_dimension=3):...
def forward(self, x):
x, feature_transform, tnet_out, ix_maxpool = self.base_pointnet(x)
x = F.relu(self.bn_1(self.fc_1(x)))
x = F.relu(self.bn_2(self.fc_2(x)))
x = self.dropout_1(x)
return F.log_softmax(self.fc_3(x), dim=1), feature_transform, tnet_out, ix_maxpool出于空间原因,init?函数已被省略,但您可以在笔记本中查看它们。
3、训练Pointnet
我们使用经典的 Pytorch 训练循环来训练我们的模型。 我们将学习率设置为 0.001,最大 epoch 数设置为 80。您可以在上面的链接中找到 PointNet 的更轻版本(在 Google Colab 中实现)来使用它。 PointNet 包含多个 MLP,因此它具有大量可训练参数 (3.472.339)。 PointNet 的轻量级版本是通过减少每层神经元数量来减少训练时间来实现的,从而产生 910.611 个可训练参数。
该模型通过负对数似然损失 (NLL) 和正则化项进行优化,使其更加稳定。 NLL 是训练具有多个类别的分类问题时的典型损失。
一旦我们看到损失已经收敛,验证损失不会减少,我们就可以停止训练并测试我们的模型。

Test Accuracy
0.967Alert?? 如果模型没有经过完全训练,它可能无法保证排列的不变性。
3、可视化 T-Net 的输入和输出
T-Net 在特征提取之前将所有输入集对齐到规范空间。 它是如何做到的? 它预测将应用于输入点 (x, y, z) 坐标的 3x3 仿射变换矩阵。

这个想法可以进一步扩展到特征空间的对齐。 在PointNet架构图中可以看到,第二个T-Net预测了64x64的特征转换矩阵,用于对齐来自不同输入点云的特征。
正如你在下面的代码块中看到的,T-Net 由用于点无关特征提取的一维卷积层、最大池化和全连接层组成。 结果是一个变换矩阵,我们直接将其应用于输入点的坐标。
class TransformationNet(nn.Module):
def __init__(self, input_dim, output_dim):
super(TransformationNet, self).__init__()
self.output_dim = output_dim
self.conv_1 = nn.Conv1d(input_dim, 64, 1)
self.conv_2 = nn.Conv1d(64, 128, 1)
self.conv_3 = nn.Conv1d(128, 1024, 1)
self.bn_1 = nn.BatchNorm1d(64)
self.bn_2 = nn.BatchNorm1d(128)
self.bn_3 = nn.BatchNorm1d(1024)
self.bn_4 = nn.BatchNorm1d(512)
self.bn_5 = nn.BatchNorm1d(256)
self.fc_1 = nn.Linear(1024, 512)
self.fc_2 = nn.Linear(512, 256)
self.fc_3 = nn.Linear(256, self.output_dim * self.output_dim)
def forward(self, x):
num_points = x.shape[1]
x = x.transpose(2, 1)
x = F.relu(self.bn_1(self.conv_1(x)))
x = F.relu(self.bn_2(self.conv_2(x)))
x = F.relu(self.bn_3(self.conv_3(x)))
x = nn.MaxPool1d(num_points)(x)
x = x.view(-1, 1024)
x = F.relu(self.bn_4(self.fc_1(x)))
x = F.relu(self.bn_5(self.fc_2(x)))
x = self.fc_3(x)
identity_matrix = torch.eye(self.output_dim)
if torch.cuda.is_available():
identity_matrix = identity_matrix.cuda()
x = x.view(-1, self.output_dim, self.output_dim) + identity_matrix
return x注意📝 T-Net 通过学习变换矩阵将所有输入集对齐到规范空间
通过绘制 T-Net 输出乘以输入点的结果,我们可以看到对输入点云执行的规范变换。

PointNet 的特性之一是它对点的排列具有不变性。 我们来测试一下! 我们将打乱点并比较转换和预测。 我们将使点大小更小,以更好地识别两种转换之间的差异。

我们可以看到,对于这个例子,使用不同的点顺序,我们得到非常相似的表示和相同的预测。
所有测试样本都会保留它吗? 让我们比较所有测试样本上的打乱点和非打乱点之间的预测。
(results==results_shuffle)
False我们从 7000 个样本(测试集大小)中得到 6 个样本,在洗牌时得到不同的结果。 我们存储这些样本的索引以比较转换和预测。 在这里你可以看到几个示例:

我们发现转换非常相似,并且通过查看 T-Net 转换来猜测这些数字时我们也可能是错误的。 您认为为什么同一个模型会预测不同的数字? 我们可以绘制对最大池化有贡献的点来获得一个想法。
4、可视化 PointNet 关键点
PointNet 学习通过一组稀疏的关键点(作者称为关键点)来总结输入点云。 关键点是那些对最大池化特征有贡献的点。

我们存储了最大池化层的索引,我们绘制了混洗和非混洗点云的这些点,并获得了下图:

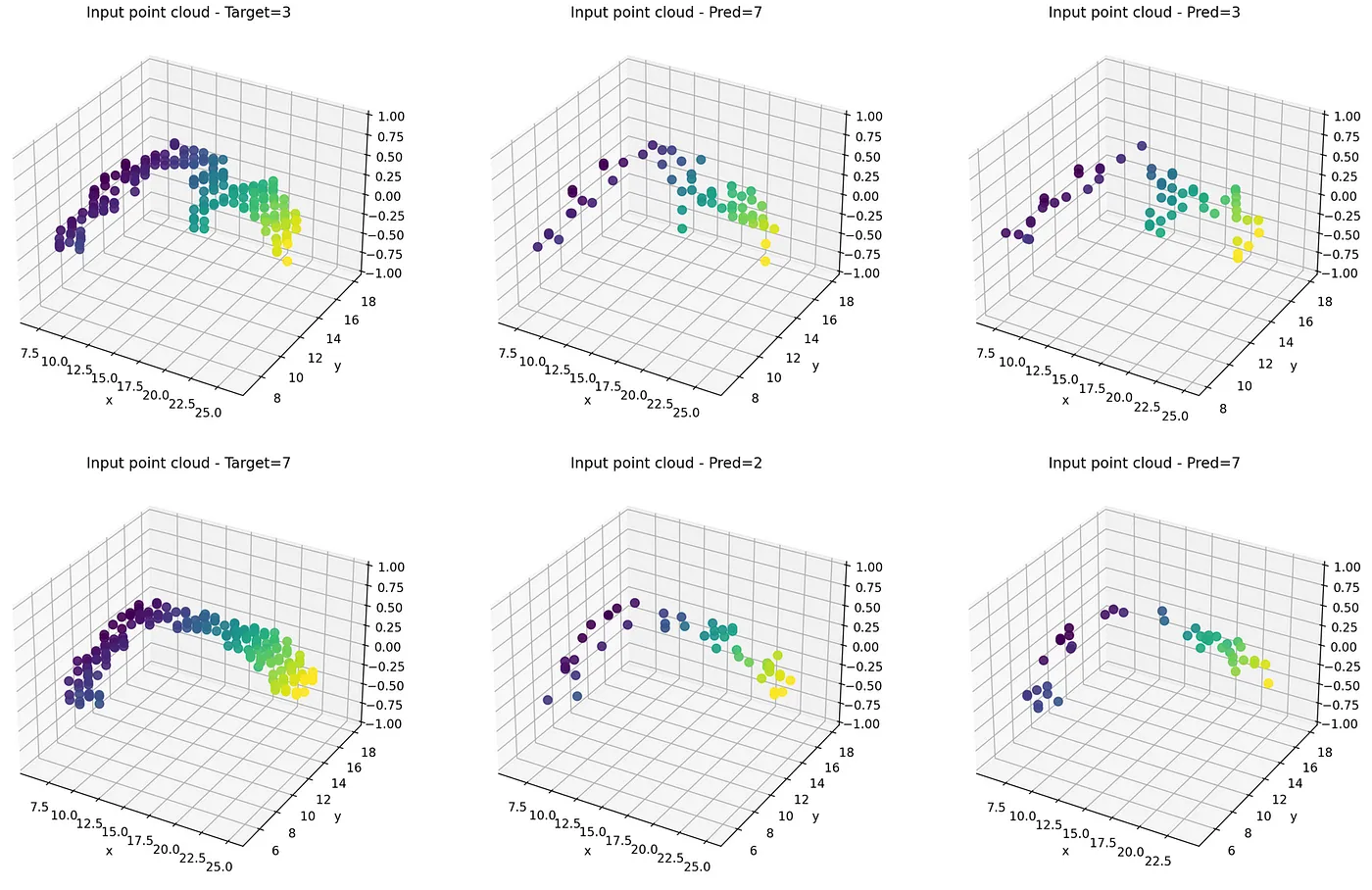
我们看到临界点集对应于数字的骨架,并且在混洗和非混洗点云之间是不同的,这导致模型预测一个或另一个类别!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!