大数据学习之Flink,Flink部署
Flink部署
一、了解它的关键组件
-
客户端(Client)
-
作业管理器(JobManager)
-
任务管理器(TaskManager)
我们的代码,实际上是由客户端获取并做转换,之后提交给 JobManger 的。所以 JobManager 就是 Flink 集群里的“领导者”,对作业进行中央调度管理; 而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的 TaskManager。这里 的 TaskManager,就是真正“干活的人”,数据的处理操作都是它们来做的,如图所示。
二、配置环境
-
部署在Linux上,使用 CentOS 7
-
安装hadoop集群
-
三台节点之间配置免密,关闭防火墙
1. 本地启动
1.1 下载Flink的安装包 和所对应的 scala版本存放在/opt/software
1.2 解压在bigdata1下的/opt/module目录下
tar -zxvf /opt/software/flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/1.3 启动
进入/opt/module/flink目录下
bin/start-cluster.sh使用jps命令查看它的进程
jps
1.4 访问web页面
在浏览器中输入 bigdata1:8081 进入web页面
1.5 关闭集群
bin/stop-cluster.sh 2.集群启动
集群启动就有了主从节点的区别,Flink也是典型的 Master-Slave 架构 的分布式数据处理框架
-
Master 对应着 JobManager
-
Slave 对用着 TaskManager
三台节点服务器角色分配为
| 节点服务器 | bigdata1 | bigdata2 | bigdata3 |
|---|---|---|---|
| 角色 | JobManager | TaskManager | TaskManager |
具体步骤如下:
2.1下载并安装
与上述操作一样,不展示了
2.2修改集群配置
-
进入conf 目录下,修改flink-conf.yaml 文件中的 jobmanager.rpc.address的参数为bigdata1
指定JobManager节点
# JobManager 节点地址. jobmanager.rpc.address: bigdata1 -
修改workers文件
指定TaskManager节点
bigdata2 bigdata3 -
优化 JobManager 和 TaskManager 配置
-
jobmanager.memory.process.size:
对 JobManager 进程可使用到的全部内存进行配置, 包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
-
taskmanager.memory.process.size:
对 TaskManager 进程可使用到的全部内存进行配置, 包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
-
taskmanager.numberOfTaskSlots:
对每个 TaskManager 能够分配的 slots 数量进行配置, 默认为 1,可根据 TaskManager 所在的机器能够提供给 Flink 的 CPU 数量决定。所谓 slots 就是 TaskManager 中具体运行一个任务所分配的计算资源。
-
parallelism.default:
Flink 任务执行的默认并行度配置,优先级低于代码中进行的并行 度配置和任务提交时使用参数进行的并行度数量配置
-
2.3 分发安装目录
将目录分发给其他两个节点
2.4启动集群
bin/start-cluster.sh用jps命令查看
2.5访问web页面
3.部署模式
-
会话模式(Session Mode)
-
单作业模式(Per-Job Mode)
-
应用模式(Application Mode)
3.1 概念
3.1.1会话模式
会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业,如图所示。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
会话模式比较适合于单个规模小、执行时间短的大量作业
3.1.2 单作业模式
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个 提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式,如图所示。
需要注意的是,Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管 理平台来启动集群,比如 YARN、Kubernetes。
3.1.3 应用模式
前面提到的两种模式下,应用代码都是在客户端上执行,然后由客户端提交给 JobManager 的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给 JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的 资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到 JobManger 上运行。而这也就 代表着,我们需要为每一个提交的应用单独启动一个 JobManager,也就是创建一个集群。这 个 JobManager 只为执行这一个应用而存在,执行结束之后 JobManager 也就关闭了,这就是所 谓的应用模式,如图所示。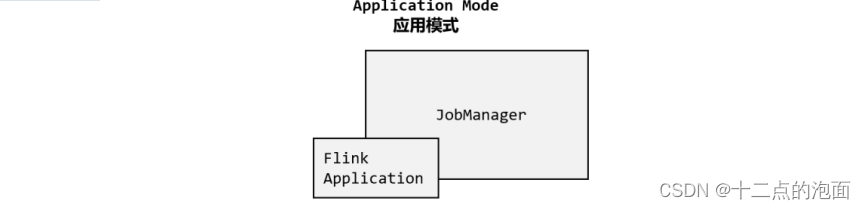
应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交 的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应 用程序的,并且即使应用包含了多个作业,也只创建一个集群。
3.2 部署
具体的查看我的另一篇CSDN的文章 大数据学习之Flink,了解Flink的多种部署模式上,点击查看
3.2.1独立模式(Standalone)
3.2.2 YARN 模式
3.2.3 K8S 模式
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!