深度学习弱光图像增强入门学习贴及相关可参考工作推荐
0 引言
先表明身份,在过去三年的时间里,发表弱光图像增强的SCI工作多篇,后续会在Github的代码库构建好之后,分享代码链接,欢迎关注(由于工作过于垃圾,因此咱还是以大佬的工作作为参考
首先,弱光图像增强,就是把暗图像增强为亮图像。
这里有一个很大的误区,就是弱光增强并不是仅仅把灰度值调亮,而是把亮度提高的同时,必须保证对比度的一致,同时!色彩的饱和度高并且纹理细节的还原也必须优秀!
因此,弱光图像增强其实还是挺有难度的。
接下来,我们将分块进行弱光图像-深度的学习。
1 深度学习部分
首先,深度学习您是否掌握?深度学习我们这里仅仅要求您掌握神经网络的基础框架即可。在我看来,您想快速入门深度学习,最好的不是去看B站上任何的垃圾课程,而是专注于您的第一个网络的复现工作。
首先,您需要了解神经网络的基本工作原理;简明扼要,它是使用多个卷积核,通过对图像进行多尺度的分解,分解成一个一个的特征图。之后,在对其进行叠加即可。
说白了,你可以很玄学的去认为,它就是一堆卷积核穿起来,构成了一个可以改变图像灰度值的线性+非线性映射。
当然,知乎和CSDN上有大量的大佬,写了很多关于神经网络和卷积核的讲解,大家可以自己去搜。这里我就不再多将。
我推荐您复现这两个网络:VGG16和Resnet的任何版本。
您必须学会构建您的全连接网络,学会跳跃连接的操作,以及明白池化层,以及上下采样的意义。
最重要的,您必须会开启您的训练,必须知道如何用现有数据集开启训练,我这里指的是有监督学习。
有个大概的概念之后,我们将进入下一步!
2 弱光图像增强基础:
弱光图像增强你需要指导它存在3个核心问题:亮度低,对比度差、图像质量低(可以理解为色彩饱和度很垃圾,很难提取有用信息),OK,我们从3个方面来讲讲图像领域如何处理这种情况
2.1 亮度增亮
亮度增强中,在Opencv包括Photoshop里最喜欢用的,就是直接用灰度值去提升亮度。但是这种全局的增强有一个很大的问题。全局亮度提升,这玩意儿导致了所有的像素点都提升了,你还是看不见任何的区别。你可以看见,从直方图分布来看,弱光图像的像素分布问题在于:像素过于集中在左右两极。单纯的灰度值拉升,只会导致图像的信息没有得到任何有效增强。
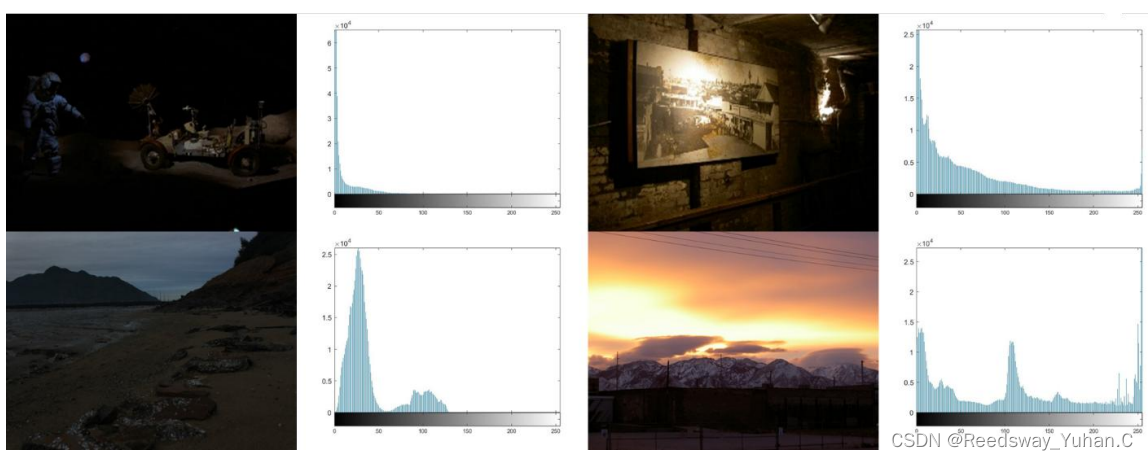
因此,直接采用亮度提升,肯定是不行的,必须使用局部的亮度提升,才是最好的结果。
在这方面,我推荐一下近年来最经典的工作:ZERO-DCE
这篇工作的效果几乎堪称轰动。为啥呢?因为它在本领域的效果几乎是王炸。极其简单且效果拔群。
 论文链接:
论文链接:代码链接:https://github.com/Li-Chongyi/Zero-DCE
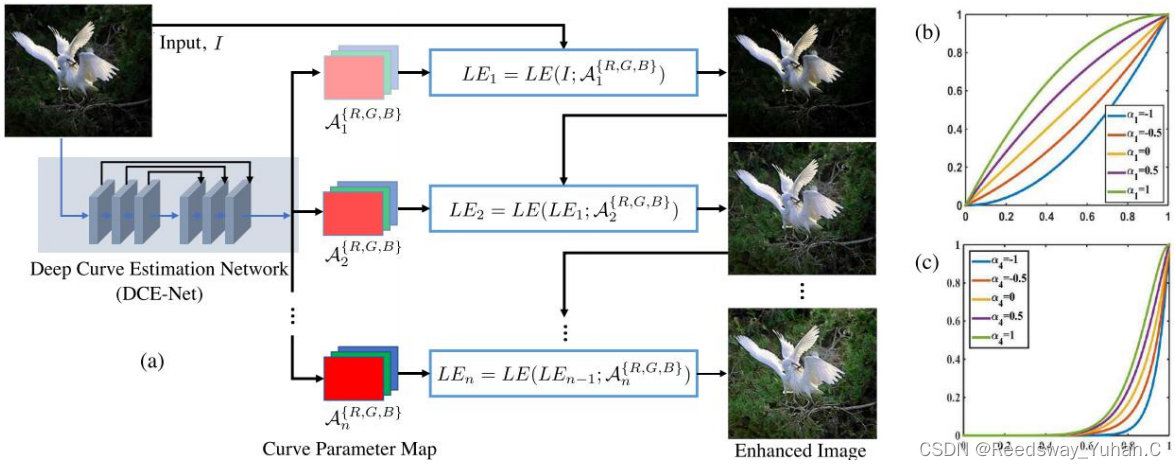
简单讲解就是,Guo使用了一个深度网络对图像特征进行疯狂分解,然后,重点来了。他构建了一个零参考数据集。这个数据集很牛逼。每一张图像,存在不同的亮度等级。它通过让网络学习这些亮度等级的分布,从而到达取中间值的效果。如下所示,你可以看见,他为了取数据集中所有亮度的中间值,在里面甚至加入了极暗和曝光的情况。
为啥不是全局增强呢,因为他使用split,将图像分为了很多个部分进行函数迭代。
这里的函数迭代,来源于调光曲线的灵感,他构建了如下的二次乘法式子:
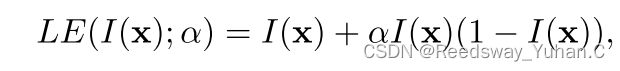
这里的α也就是上述使用split分割的局部特征。然后将这个局部特征放入网络中进行迭代增强。最终达到保持对比度的全局增强的效果。
最终取得的效果也很牛逼!我强烈建议您将其纳入您的第一个复现工作,因为它的代码极度简单,并且极好复现,最重要的是,它的代码参数量,仅有0.003M的大小。

它的同类工作,特别多。
我将推荐下面几个基于Zero-dce的改进作为您打开思路的参考。
2.1.1 STAR:A Structure-aware Lightweight Transformer for Real-time Image Enhancement
使用Transformer对图像特征进行增强,但大体的增强逻辑,基于Zero-DCE的迭代函数
论文链接:https://ieeexplore.ieee.org/document/9710083
代码链接:https://github.com/zzyfd/STAR-pytorch

2.1.2 FLW-NET:A Fast and Lightweight Network for Low-Light Image Enhancement
一种魔改的轻量化Zero-DCE,加了一个全局感受野的Moudle,整体还行。我觉得可以作为参考。
论文链接:https://arxiv.org/pdf/2304.02978v1.pdf
代码链接:FLW-Net/model.py at main · hitzhangyu/FLW-Net (github.com)
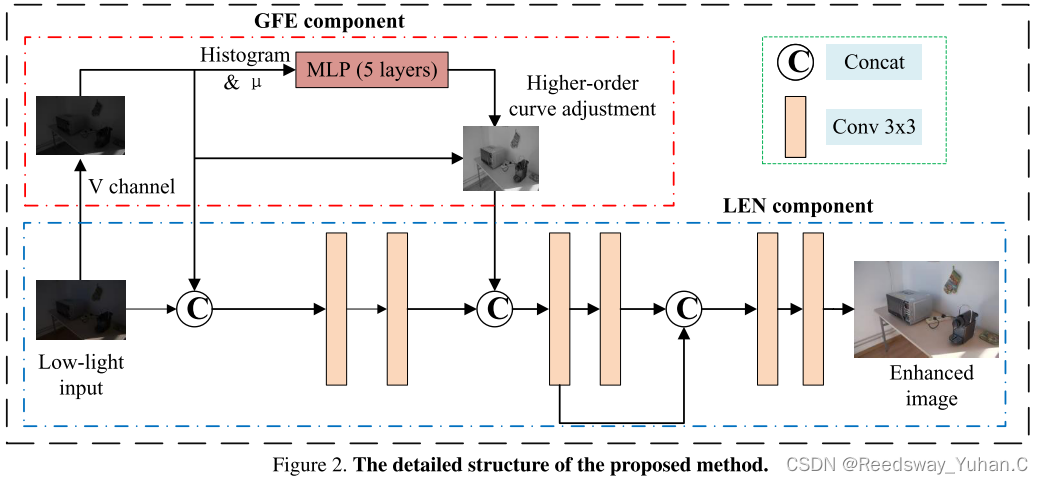
2.1.3 LUT-GCE: Lookup Table Global Curve Estimation for Fast Low-light Image Enhancement
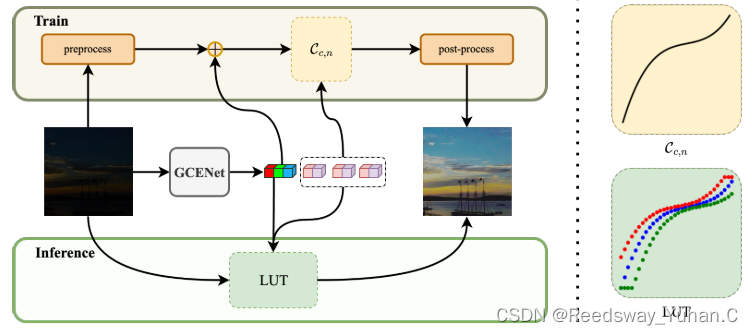
这个改进我自己觉得比前面这些对Moudle进行改进的都要更好一些。这篇文章主要的改进,是把Zero-DCE里的二次函数改成了一个三次函数,我觉得这篇paper的点很好,但是没有提供多余的代码。说实话有点遗憾。而且它摘要说它们的网络参数量25.4k,我觉得并不太行,因为现在的轻量化模型基本来到了10k以下的战场,仍在25.4k,其实并不算一个特色:
文章链接:https://arxiv.org/abs/2306.07083
代码:没公布
2.2 对比度增强
对比度增强主要来源于一个公式:

对比度增强在早期的工作,主要是源于直方图的调整。但是大家都知道,直方图,太老了,说实话,这年头还搞直方图实在有点没有亮点了。而且其实你自己编程会发现,直方图转为Tensor与神经网络进行交互实在有些太麻烦了。因此,我们最好就别用直方图。
接下来,我将介绍两篇。这两篇是我觉得在对比度增强上还算不错的工作。
2.2.1?The linear contrast enhancement formula is given as follows Linear Contrast Enhancement Network for Low-Illumination Image Enhancement?
这篇工作特别好。虽然他在模型构建上来说似乎没有特别大的特色。但是呢,我非常推荐它里面提出的残差块,它取名叫LCE-Resblock。如下图所示,它使用神经网络取模拟我们上面提到的对比度增强公式,效果确实不错。
文章链接:https://ieeexplore.ieee.org/document/10001830
代码链接:https://ieeexplore.ieee.org/document/10001830
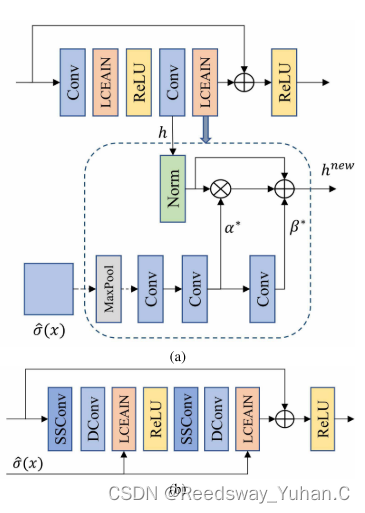
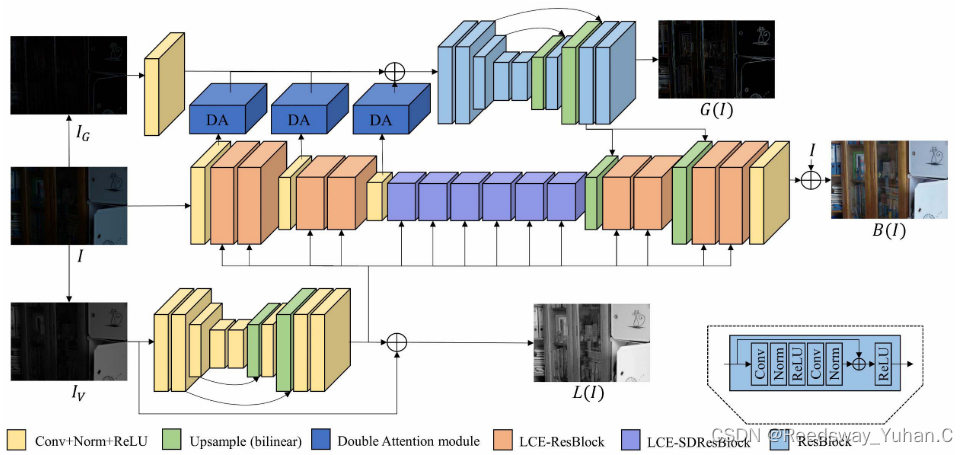
其他的创新,我觉得不算太亮眼,主要是针对特征提取的部分。但LCE-ResBlock我是觉得很不错的即插即用的模块。
2.2.2?The linear contrast enhancement formula is given as follows Linear Contrast Enhancement Network for Low-Illumination Image Enhancement
这篇文章我觉得还可以,效果也不错。只不过它是专门针对对比度增强提出的双分支网络。其实相对于上面的LCE-NET有一点繁琐了。
文章链接:https://ieeexplore.ieee.org/document/10001830
代码链接:https://github.com/zhuyr97/GLCE
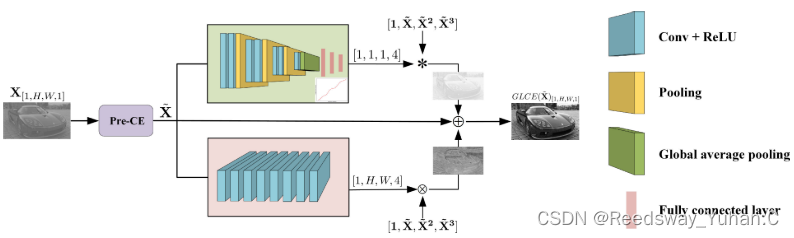
2.3 特征提取及色彩恢复
其实到这个环节,就很抽象了。因为其实无论特征提取还是色彩恢复,这都是一个有监督学习的过程。当我们不考虑使用生成对抗网络GAN和后续的Diffusion Model这类生成式技术的时候,特征提取这个环节,几乎任何任务都能做是吧。
特征提取模型,灌水重灾区,魔改版本众多。超分领域、图像增强领域、目标识别领域、图像分割领域………………特征提取模块实在是过于抽象。
我这里从两个方面来推荐工作。一个是注意力模块来推荐,一个是传统的特征融合来推荐。
2.3.1 注意力模块
太多了,实在是太多了
早年的大水文,AFF,其实它的结构和传统的通道注意力,以及空间注意力就很像了。我推荐一个高速的轻量化注意力结构,来自超分算法FMEN。其余的大家自行去搜索一下。其实注意力模块每年都有大量的魔改。你可以看看有多少人在YOLO里加注意力的魔改,就可以知道这部分的水分其实还是挺大的,
文章链接:https://ieeexplore.ieee.org/document/9856988
代码链接:https://github.com/NJU-Jet/FMEN
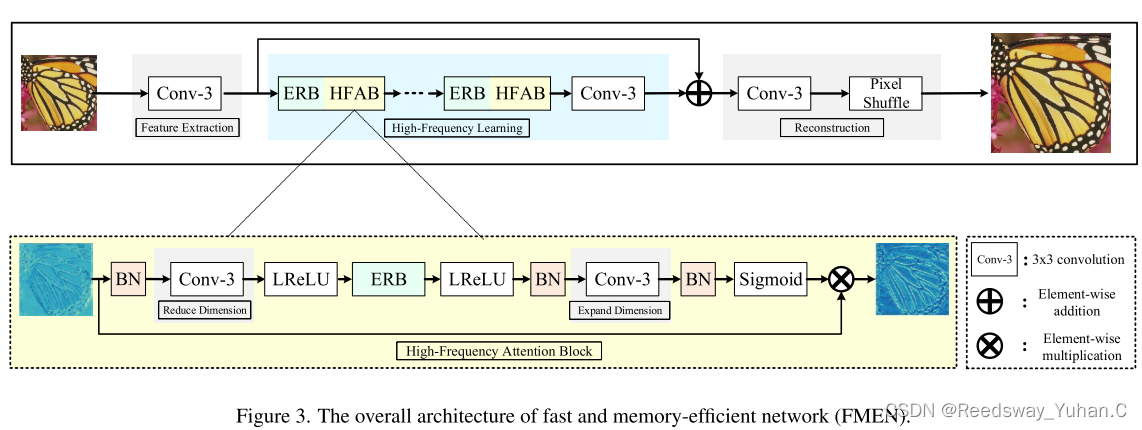
FMEN提出了一个高效的注意力模块HFAB。这个模块可以直接插入到您的网络结构中,我试了下,在图像恢复里,其实效果还可以。
2.3.2 特征提取模块
好家伙,如果说注意力模块是灌水重灾区,那么特征提取模块,将成为真正的王炸级深海!这个部分简直抽象得令人发指。近年来得抽象主义魔改太多了。
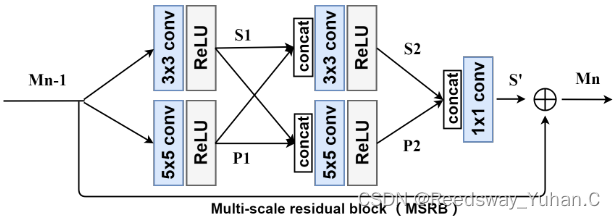
早年ECCV得多尺度超分算法魔改:
文章链接:http://Multi-scale Residual Network for Image Super-Resolution
代码链接:https://github.com/MIVRC/MSRN-PyTorch
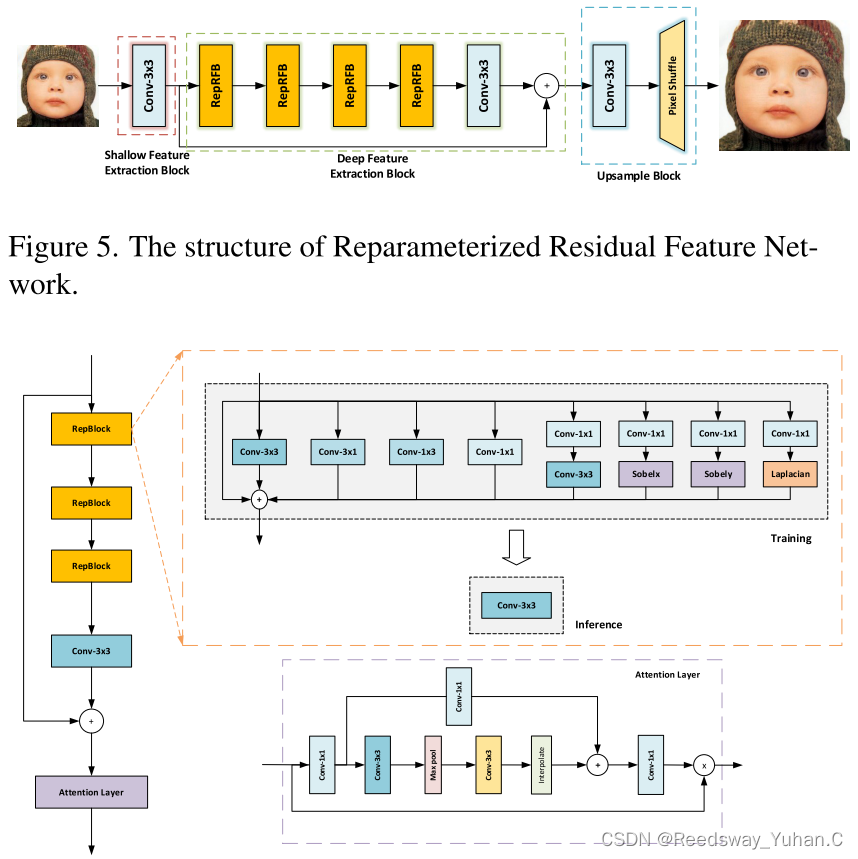
去年的抽象代表,重参数残差块:
文章链接:https://ieeexplore.ieee.org/document/10208691
代码链接:https://github.com/laonafahaodange/RepRFN
当然,还有如下的抽象主义(我真的无语了当时,可能我自己不太懂这个行业吧。。。这是仿生鹰眼结构。。。。是长得像鹰眼吗。。。
文章链接:https://link.springer.com/article/10.1007/s11063-022-11030-1

3 近期全新赛道
近期的发展其实在弱光增强领域,就是跟着新技术混呗。我太想将GAN的应用,以为其实发展到现在,EnlightenGAN还是最好的GAN算法。其次,在轻量化赛道,SCI这篇文章已经把参数量卷到300个了,真的太抽象了。
EnlightenGAN:
文章:https://arxiv.org/abs/1906.06972
代码:https://github.com/VITA-Group/EnlightenGAN
SCI:
文章:https://arxiv.org/abs/2204.10137
代码:https://github.com/vis-opt-group/SCI
后续我会专门开一个轻量化弱光图像增强的文章,具体讲一讲近年来的发展,欢迎各位监督和催促(求关注~
然后,从CVPR2023开始,全新的赛道,特就是NERF的赛道也打开了:
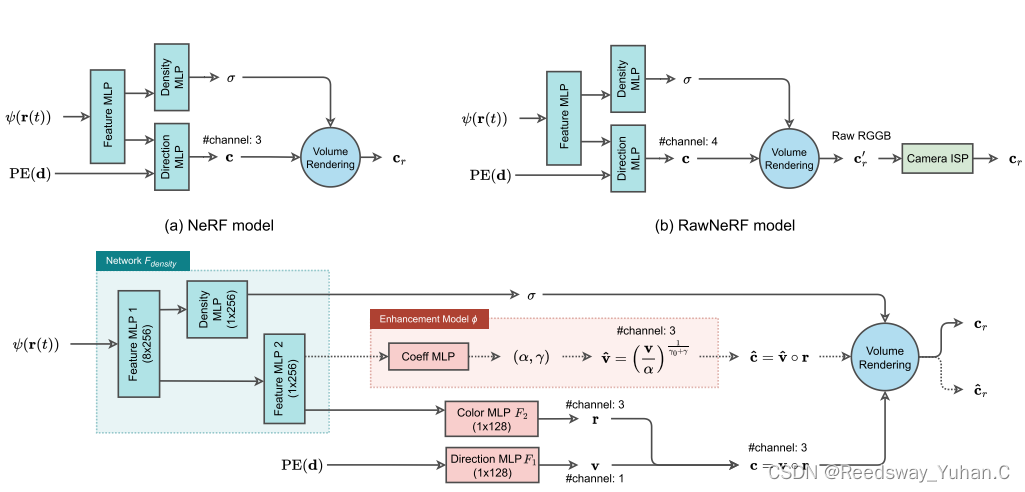
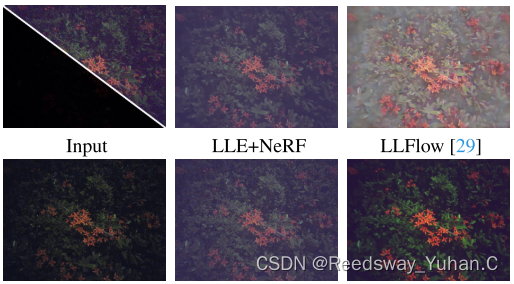
基于Nerf的弱光图像增强,其实今年有一篇还不错叫LLNerf,也公布了代码,我自己觉得还挺好的。
文章链接:https://arxiv.org/abs/2307.10664
代码链接:https://github.com/onpix/LLNeRF
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用 C++/WinRT 的集合
- android studio 打包签名apk时报kotlin版本错误
- 【无标题】
- JAVA+mysql体育馆场地预约系统app25510-计算机毕业设计项目选题推荐(免费领源码)
- ETL 数据抽取有哪些常见的应用场景?
- 大模型实战:使用 LoRA(低阶适应)微调 LLM
- BeanUtils工具类简介
- was not migrated due to partial or ambiguous match.
- python pillow(PIL)库使用介绍
- MySQL常用连接工具