【sklearn练习】模型评估
发布时间:2024年01月11日
一、交叉验证 cross_val_score 的使用
1、不用交叉验证的情况:
from __future__ import print_function
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
X = iris.data
y = iris.target
# test train split #
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=4)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test))输出结果:
0.97368421052631582、使用交叉验证
from sklearn.model_selection import cross_val_score
knn2 = KNeighborsClassifier(n_neighbors=5)
scores = cross_val_score(knn2, X, y, cv=5, scoring='accuracy')
print(scores)输出结果:
[0.96666667 1. 0.93333333 0.96666667 1. ]二、确定合适模型参数
1、迭代模型中n_neighbors参数
import matplotlib.pyplot as plt
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
## loss = -cross_val_score(knn, X, y, cv=10, scoring='mean_squared_error') # for regression
scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy') # for classification
k_scores.append(scores.mean())
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()画出scores为:

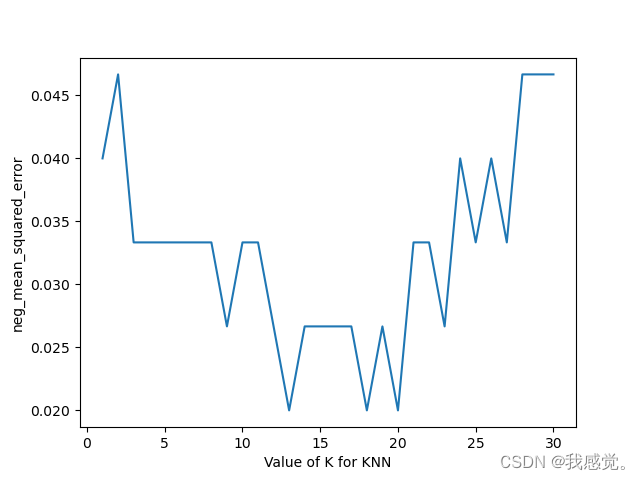
下面是画loss的代码:
k_range = range(1, 31)
k_loss = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
loss = -cross_val_score(knn, X, y, cv=10, scoring='neg_mean_squared_error') # for regression
## scores = cross_val_score(knn, X, y, cv=10, scoring='accuracy') # for classification
k_loss.append(loss.mean())
plt.plot(k_range, k_loss)
plt.xlabel('Value of K for KNN')
plt.ylabel('neg_mean_squared_error')
plt.show()画出loss为:
三、cross_val_score? 中的??scoring参数(本标题内容可删,可以是一个链接插入解释这个参数即可)
cross_val_score 函数中的 scoring 参数用于指定评估模型性能的评分指标。评分指标是用来衡量模型预测结果与真实结果之间的匹配程度的方法。在机器学习任务中,选择合适的评分指标对于模型的评估和选择非常重要,因为不同的任务和数据可能需要不同的评估标准。以下是一些常见的评分指标以及它们在 cross_val_score 中的使用方式:
-
分类问题的评分指标:
scoring="accuracy":用于多类分类问题,计算正确分类的样本比例。scoring="precision":计算正类别预测的精确度,即正类别的真正例与所有正类别预测的样本之比。scoring="recall":计算正类别预测的召回率,即正类别的真正例与所有真实正类别的样本之比。scoring="f1":计算 F1 分数,它是精确度和召回率的调和均值,用于综合考虑模型的性能。
示例使用方法:
from sklearn.model_selection import cross_val_score scores_accuracy = cross_val_score(estimator, X, y, cv=5, scoring="accuracy") scores_precision = cross_val_score(estimator, X, y, cv=5, scoring="precision") scores_recall = cross_val_score(estimator, X, y, cv=5, scoring="recall") scores_f1 = cross_val_score(estimator, X, y, cv=5, scoring="f1") -
回归问题的评分指标:
scoring="neg_mean_squared_error":用于回归问题,计算负均方误差(Negative Mean Squared Error),即平均预测值与真实值的平方差。scoring="r2":计算决定系数(R-squared),用于度量模型对目标变量的解释方差程度,取值范围在0到1之间。
示例使用方法:
from sklearn.model_selection import cross_val_score scores_mse = cross_val_score(estimator, X, y, cv=5, scoring="neg_mean_squared_error") scores_r2 = cross_val_score(estimator, X, y, cv=5, scoring="r2") -
其他评分指标:
- 除了上述常见的评分指标外,还可以使用其他自定义评分函数或指标,例如 AUC、log损失等,只需将评分函数传递给
scoring参数即可。
示例使用方法:
from sklearn.metrics import roc_auc_score from sklearn.model_selection import cross_val_score scoring_function = make_scorer(roc_auc_score) scores_auc = cross_val_score(estimator, X, y, cv=5, scoring=scoring_function) - 除了上述常见的评分指标外,还可以使用其他自定义评分函数或指标,例如 AUC、log损失等,只需将评分函数传递给
根据任务和数据类型,选择适当的评分指标非常重要,它有助于衡量模型的性能,确定模型是否满足预期的要求,并在不同模型之间进行比较和选择。不同的评分指标可以反映模型性能的不同方面,因此需要根据具体情况进行选择。
文章来源:https://blog.csdn.net/m0_56997192/article/details/135516401
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- <Articles v-if=“!loading“ :articles=“props.articles“ />的区分
- Java中的Servlet你了解吗?
- mysqlcheck 数据完整性检查与修复
- 计算机专业校招常见面试题目总结
- 解决kindle返回不了主页的问题
- 数据结构与算法之美学习笔记:42 | 动态规划实战:如何实现搜索引擎中的拼写纠错功能?
- MySQL计算碎片化比率并优化表
- 戴维南等效(诺顿等效)电路分析
- 代码随想录算法训练营第十天|232 用栈实现队列、225 用队列实现栈
- 矩阵微分笔记(1)