GoLang学习之路,对Elasticsearch的使用,一文足以(包括泛型使用思想)(一)
这几天没有更新,其主要的的原因是,在学习对Elasticsearch的使用。Elasticsearch是一个非常强大的数据库索引工具。是一个基于Lucene库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎,具有HTTP Web接口和无模式JSON文档。Elasticsearch是用Java开发的,并在Apache许可证下作为开源软件发布。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
所以你可以不用,但是你不能不知道,不可谓重要。
文章目录
Elasticsearch概念
ElasticSearch是一个分布式、RESTful风格的搜索和数据分析引擎,在国内简称为ES;使用Java开发的,底层基于Lucene是一种全文检索的搜索库,直接使用使用Lucene还是比较麻烦的,Elasticsearch在Lucene的基础上开发了一个强大的搜索引擎。
主要功能有:
- 分布式的搜索引擎和数据分析引擎
- 全文检索、结构化检索、数据分析
- 对海量数据进行近实时的处理
Elastic 是Lucene的封装,提供了REST API的操作接口,开箱即用
Lucene:是单机应用,只能在单台服务器上使用,最多只能处理单台服务器可以处理的数据量。Elasric:ES自动可以将海量数据分散到多台服务器上去存储和检索海量数据的处理:- 分布式以后,就可以采用大量的服务器去存储和检索数据,自然而然就可以实现海量数据的处理了,近实时;在秒级别对数据进行搜索和分析。
- 国外
- 维基百科,类似百度百科,全文检索,高亮,搜索推荐
-Stack Overflow(国外的程序异常讨论论坛) GitHub(开源代码管理)- 电商网站,检索商品
- 日志数据分析,
logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana) - BI系统,商业智能,
Business Intelligence
- 维基百科,类似百度百科,全文检索,高亮,搜索推荐
- 国内
- 站内搜索(电商,招聘,门户)
- IT系统搜索(
OA,CRM,ERP) - 数据分析(ES热门的一个使用场景)
优点:
Elasticsearch,将全文检索、数据饭呢西、分布式技术合并到了一起。lucene(全文检索),商用的数据分析软件(也是有的),分布式数据库(mycat)- 数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型的操作);特殊的功能,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;Elasticsearch作为传统数据库的一个补充,提供了数据库所不不能提供的很多功能
- 可以作为一个大型分布式集群(数百台服务器)技术,处理
PB级数据,服务大公司;也可以运行在单机上,服务小公司 - 对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下
ES,就可以作为生产环境的系统来使用了,数据量不大,操作不是太复杂
安装
现在的安装并不像之前的版本那样,包括对Elasticsearch使用。主要存在的问题是密钥。说到密钥,这个就不得不说一个东西。
Elasticsearch其实有三个方面构成:
- 调用的服务器,这个服务器指代的是,你通过API去使用Elasticsearch引擎的服务器。
- Elasticsearch服务器。这个服务器就是搭载Elasticsearch的云服务器
- Elasticsearch可视化工具。这个可视化工具功能最齐全的就是Kibana,这个是Elacsticsearch官方指定的可视化工具。除了这个我推荐一个更加轻量的可视化工具
es-client,当然对于Kibana的来说,是比不上的,但是轻量啊。安装没有那么复杂。执行需要在浏览器的插件管理中下载就可以用了,非常方便
这里建议安装用docker去安装。这里献上官方文档(官网的不一定能成,主要是看你的虚拟机是什么)
注意:如果是按照别人博客上的安装的话,跟着就行。诺是按照官网的上的,你就注意:
- 密钥的生成。这个密钥的生成非常重要,Kibana在登录的时候是需要的。这个密钥是安全密钥,在配置的时候是可以取消的。(一定要注意不然在后面是非常弄的)
- 在用安全组中将相应的端口开放。可视化工具链接的接口与服务器调用端口是一致的。
这里不放我如何去安装的因为我怕更不上时代,到时候误人子弟,官网是一直在变的。
使用ElasticSearch
使用前提
- 必须要有一个
ElasticSearch服务器 - 必须要有一个可视化工具
- 安装API包,
"github.com/elastic/go-elasticsearch/v8"
import "github.com/elastic/go-elasticsearch/v8"
但是这个包下面其实还有一些包,这些包非常的重要。当时我在使用的时候,根本不知道,走了不少的弯路的,找了官网的文档,又找了一些博客,都没有详细的说明情况和要点。要不就少些,要不就只把部分给列出来。但是现在我将这些无私的奉献给各位。
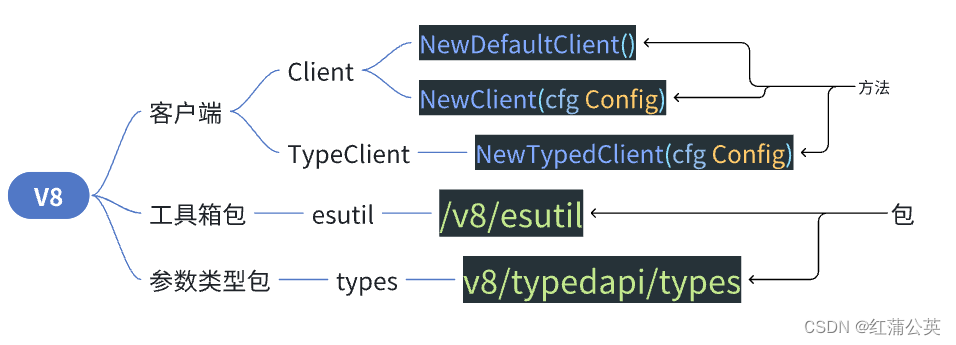
因为这个v8的包非常的多,所以很难将所有的放进去。这里我做一些解释:
- 客户端:
- 调用
NewDefaultClient()和NewClient(cfg Config)方法会返回一个普通客户端NewDefaultClient()不需要去配置链接时的配置参数,默认参数链接,并返回一个普通客户端NewClient(cfg Config)需要按照总共需要的配置需求去配置参数,并返回一个普通客户端
- 调用
NewTypedClient(cfg Config)会返回一个属性客户端(相比普通客户端强大,但是有局限,后面再说)
- 调用
- 工具包:
- 这个工具包主要是
普通客户端进行调用的,使用的范围是对于批量处理数据的情况
- 这个工具包主要是
- 参数类型包:
- 我们在对
ElasticSearch进行处理的时候会有很多中情况:- 首先是对于语法的选择,
ElasticSearch有独属于他自己的一套语法。 - 查询时会有很多选择,比如对于字段是模糊查询,还是精确查询,还是对地图进行查询。这些参数都有,也有对于
AI进行处理的参数。(建议下一个翻译软件,去看看。那个参数太多了。。。也就是说功能非常齐全)
- 首先是对于语法的选择,
- 我们在对
存储结构
| ES存储结构 | Mysql存储结构 |
|---|---|
| Index(索引) | 表 |
| document(文档) | 行,一行数据 |
| Field(字段) | 表字段 |
| mapping(映射) | 表结构定义 |
indexES中索引(index)就像mysql中的表一样,代表着文档数据的集合,文档就相当于ES中存储的一条数据
typetype也就是文档类型,不过在Elasticsearch7.0以后的版本,已经废弃文档类型了。- 在
Elasticsearch老的版本中文档类型,代表一类文档的集合,index(索引)类似mysql的数据库、文档类型类似Mysql的表。 - 新的版本文档类型没什么作用了,那么
index(索引)就类似mysql的表的概念,ES没有数据库的概念了。
documentES是面向文档的数据库,文档是ES存储的最基本的存储单元,文档类似mysql表中的一行数据。- 其实在
ES中,文档指的就是一条JSON数据 - ES中文档使用JSON格式存储,因此存储上要比mysql灵活的很多,
ES支持任意格式的json数据-
要注意:虽然说, 一个索引就理解成一个表,但是这个表是可以存任意数据的,也就是说,不遵从约定的一开始的索引也是可以的。(所以索引名一定不能错否则,会有脏数据)
-
一个
document的数据
{
"_index" : "order",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"productName": "12370",
"masterPic": "12345650",
"categoryId": 1,
"desc": "12345640",
"price": "12345630",
"tags": null,
"startProvinceCode": "12345690",
"startCityCode": "12345680",
"destinationProvinceCode": "12345640",
"destinationCityCode": "12345670",
"startDate": null
}
}
文档中的任何json字段都可以作为查询条件。并且文档的json格式没有严格限制,可以随意增加,减少字段,甚至每个文档的格式都不一样也可以。
值得注意的是:
_index:代表当前json文档所属的文档名字(重要)_type:代表当前json文档所属的类型。不过在es7.0以后废弃了type用法,但是元数据还是可以看到的(API可以)(重要)_id:文档唯一ID,如果我们没有为文档指定id,系统自动生成。(重要,一定要自己去控制)_source:代表我们插入进入json数据_version:文档的版本号,每修改一次文档数据,字段就会加1,这个字段新版es也给取消了_seq_no:文档的编号,替代老的version字段_primary_term:文档所在主分区,这个可以跟seq_no字段搭配实现乐观锁(重要)
Field
文档由多个json字段,这个字段跟mysql中的表的字段是类似的。ES中的字段也是有类型的:
-
数值类型(long、integer、short、byte、double、float) -
Date日期类型 -
boolean布尔类型 -
Text支持全文搜索 -
Keyword不支持全文搜索,例如:phone这种数据,用一个整体进行匹配就ok了,也不要进行分词处理 -
Geo这里主要用于地理信息检索、多边形区域的表达。
mapping:
Elasticsearch的mapping类似于mysql中的表结构体定义,每个索引都有一个映射的规则,我们可以通过定义索引的映射规则,提前定义好文档的json结构和字段类型,如果没有定义索引的映射规则,ElasticSearch会在写入数据的时候,根据我们写入的数据字段推测出对应的字段类型,相当于自动定义索引的映射规则。
这里献上一篇我在学习时看见的一篇非常详细的文章:
mappingTpl = `{
"mappings":{
"properties":{
"categoryId": {
"type": "long"
},
"productName": {
"type": "keyword"
},
"masterPic": {
"type": "text"
},
"desc": {
"type": "keyword"
},
"price": {
"type": "long"
},
"startProvinceCode": {
"type": "text"
},
"startCityCode": {
"type": "text"
},
"update_time": {
"type": "long"
},
"create_time": {
"type": "long"
}
}
}
}`
这样我们就定义好了,一个索引的结构
Elasticsearch语法
在使用ES时,查询是我们经常使用的
GET /{索引名}/_search
{
"from" : 0, // 搜索结果的开始位置
"size" : 10, // 分页大小,也就是一次返回多少数据
"_source" :[ ...需要返回的字段数组... ],
"query" : { ...query子句... },
"aggs" : { ..aggs子句.. },
"sort" : { ..sort子句.. }
}
ES查询分页:通过from和size参数设置,相当于MYSQL的limit和offset结构query:主要编写类似SQL的Where语句,支持布尔查询(and/or)、IN、全文搜索、模糊匹配、范围查询(大于小于)aggs:主要用来编写统计分析语句,类似SQL的group by语句sort:用来设置排序条件,类似SQL的order by语句source:用于设置查询结果返回什么字段,相当于select语句后面指定字段
查询语句:GET /{索引名}/_search
查询 GET /test/_search
返回结果:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1006,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "test",
"_id": "bZ8TfIwBuOjgAaUNdD1u",
"_score": 1,
"_source": {
"productName": "123",
"masterPic": "123456",
"categoryId": 1,
"desc": "123456",
"price": "123456",
"tags": null,
"startProvinceCode": "123456",
"startCityCode": "123456",
"destinationProvinceCode": "123456",
"destinationCityCode": "123456",
"startDate": null
}
}
}
常见的几种查询方法
匹配单个字段
通过match实现全文索引,全文搜索是ES的关键特性之一,我们平时使用搜索一些文本、字符串是否包含指定的关键词,但是如果两篇文章,都包含我们的关键词。
GET /{索引名}/_search
{
"query": {
"match": {
"{FIELD}": "{TEXT}"
}
}
}
-
{FIELD} 就是我们需要匹配的字段名
-
{TEXT} 就是我们需要匹配的内容
精确匹配单个字段
当我们需要根据手机号、用户名来搜索一个用户信息时,这就需要使用精确匹配了。可以使用term实现精确匹配语法
GET /{索引名}/_search
{
"query": {
"term": {
"{FIELD}": "{VALUE}"
}
}
}
-
{FIELD} - 就是我们需要匹配的字段名
-
{VALUE}- 就是我们需要匹配的内容,除了
TEXT类型字段以外的任意类型
多值匹配
多值匹配,也就是想mysql中的in语句一样,一个字段包含给定数组中的任意一个值匹配。上文使用term实现单值精确匹配,同理terms就可以实现多值匹配
GET /{索引名}/_search
{
"query": {
"terms": {
"{FIELD}": [
"{VALUE1}",
"{VALUE2}"
]
}
}
}
-
{FIELD}- 就是我们需要匹配的字段名
-
{VALUE1}, {VALUE2} … {VALUE N} - 就是我们需要匹配的内容,除了TEXT类型字段以外的任意类型。
范围查询
使用range就可以实现范围查询,相当于SQL语句的>,>=,<,<=表达式
GET /{索引名}/_search
{
"query": {
"range": {
"{FIELD}": {
"gte": 100,
"lte": 200
}
}
}
}
- {FIELD} - 字段名
- gte范围参数 - 等价于>=
- lte范围参数 - 等价于 <=
- 范围参数可以只写一个,例如:仅保留 “gte”: 100, 则代表 FIELD字段 >= 100
范围参数有如下:
-
gt - 大于 ( > )
-
gte - 大于且等于 ( >= )
-
lt - 小于 ( < )
-
lte - 小于且等于 ( <= )
bool组合查询
前面的查询都是设置单个字段的查询条件,实际项目中这么应用是很少的,基本都是多个字段的查询条件。
GET /{索引名}/_search
{
"query": {
"bool": { // bool查询
"must": [], // must条件,类似SQL中的and, 代表必须匹配条件
"must_not": [], // must_not条件,跟must相反,必须不匹配条件
"should": [] // should条件,类似SQL中or, 代表匹配其中一个条件
}
}
}
- must条件:类似SQL的and,代表必须匹配的条件。
- must_not条件:跟must作用刚好相反,相当于sql语句中的 !=
- should条件:类似SQL中的 or, 只要匹配其中一个条件即可
排序
假设我们现在要查询订单列表,那么返回符合条件的列表肯定不会是无序的,一般都是按照时间进行排序的,所以我们就要使用到了排序语句。
ES的默认排序是根据相关性分数排序,如果我们想根据查询结果中的指定字段排序。
sort子句支持多个字段排序,类似SQL的order by。
GET /{索引名}/_search
{
"query": {
...查询条件....
},
"sort": [
{
"{Field1}": { // 排序字段1
"order": "desc" // 排序方向,asc或者desc, 升序和降序
}
},
{
"{Field2}": { // 排序字段2
"order": "desc" // 排序方向,asc或者desc, 升序和降序
}
}
....多个排序字段.....
]
}
聚合查询
ES中的聚合查询,类似SQL的SUM/AVG/COUNT/GROUP BY分组查询,主要用于统计分析场景。
一般统计分析主要分为两个步骤:
分组:- 对查询的数据首先进行一轮分组,可以设置分组条件
- 例如:新生入学,把所有的学生按专业分班,这个分班的过程就是对学生进行了分组。
- 对查询的数据首先进行一轮分组,可以设置分组条件
组内聚合:- 组内聚合,就是对组内的数据进行统计
- 例如:计算总数、求平均值等等,接上面的例子,学生都按专业分班了,那么就可以统计每个班的学生总数, 这个统计每个班学生总数的计算,就是组内聚合计算。
- 组内聚合,就是对组内的数据进行统计
一些概念:
1. 桶:
- 桶的就是一组数据的集合,对数据分组后,得到一组组的数据,就是一个个的桶。
- ES中桶聚合,指的就是先对数据进行分组。
指标:指标指的是对文档进行统计计算方式,又叫指标聚合。桶内聚合,说的就是先对数据进行分组(分桶),然后对每一个桶内的数据进行指标聚合。- 其实就是,前面将数据经过一轮桶聚合,把数据分成一个个的桶之后,我们根据上面计算指标对桶内的数据进行统计。
- 常用的指标有:
SUM、COUNT、MAX等统计函数。
{
"aggregations" : {
"<aggregation_name>" : {
"<aggregation_type>" : {
<aggregation_body>
}
[,"aggregations" : { [<sub_aggregation>]+ } ]? // 嵌套聚合查询,支持多层嵌套
}
[,"<aggregation_name_2>" : { ... } ]* // 多个聚合查询,每个聚合查询取不同的名字
}
}
aggregations- 代表聚合查询语句,可以简写为aggs
<aggregation_name>- 代表一个聚合计算的名字,可以随意命名,因为ES支持一次进行多次统计分析查询,后面需要通过这个名字在查询结果中找到我们想要的计算结果。
<aggregation_type>- 聚合类型,代表我们想要怎么统计数据,主要有两大类聚合类型,桶聚合和指标聚合,这两类聚合又包括多种聚合类型
- 例如:指标聚合:
sum、avg, 桶聚合:terms、Date histogram等等。
<aggregation_body>- 聚合类型的参数,选择不同的聚合类型,有不同的参数。
aggregation_name_2- 代表其他聚合计算的名字,意思就是可以一次进行多种类型的统计。
例子:
GET /order/_search
{
"size" : 0, // 设置size=0的意思就是,仅返回聚合查询结果,不返回普通query查询结果。
"aggs" : { // 简写
"count_store" : { // 聚合查询名字
"terms" : { // 聚合类型为,terms,terms是桶聚合的一种,类似SQL的group by的作用,根据字段分组,相同字段值的文档分为一组。
"field" : "store_name" // terms聚合类型的参数,这里需要设置分组的字段为store_name,根据store_name分组
}
}
}
}
count函数
Value Count:值聚合,主要用于统计文档总数,类似SQL的count函数。
GET /sales/_search?size=0
{
"aggs": {
"types_count": { // 聚合查询的名字,随便取个名字
"value_count": { // 聚合类型为:value_count
"field": "type" // 计算type这个字段值的总数
}
}
}
}
cardinality
基数聚合,也是用于统计文档的总数,跟Value Count的区别是,基数聚合会去重,不会统计重复的值,类似SQL的count(DISTINCT 字段)用法。
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : { // 聚合查询的名字,随便取一个
"cardinality" : { // 聚合查询类型为:cardinality
"field" : "type" // 根据type这个字段统计文档总数
}
}
}
}
avg求平均值
POST /exams/_search?size=0
{
"aggs": {
"avg_grade": { // 聚合查询名字,随便取一个名字
"avg": { // 聚合查询类型为: avg
"field": "grade" // 统计grade字段值的平均值
}
}
}
}
Sum求和计算
POST /sales/_search?size=0
{
"aggs": {
"hat_prices": { // 聚合查询名字,随便取一个名字
"sum": { // 聚合类型为:sum
"field": "price" // 计算price字段值的总和
}
}
}
}
max求最大值
POST /sales/_search?size=0
{
"aggs": {
"max_price": { // 聚合查询名字,随便取一个名字
"max": { // 聚合类型为:max
"field": "price" // 求price字段的最大值
}
}
}
}
min求最小值
POST /sales/_search?size=0
{
"aggs": {
"min_price": { // 聚合查询名字,随便取一个
"min": { // 聚合类型为: min
"field": "price" // 求price字段值的最小值
}
}
}
}
到了这里查询语法就全部结束了,但是语法只是语法,如何去用包的API去调用就是一个非常重要的问题。这里我说明一下。无论是什么Elasticsearch语句,最后都会转换成相应的接口API去实现的。所以调用也会变得简单。
具体API调用方式请看这个文章:GoLang学习之路,对Elasticsearch的使用,一文足以(包括泛型使用思想)(二)
本来是想继续写下去,但是超过一万字真的好卡啊。。。。。csdn什么扩充一下啊。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CentOS忘记root密码重置方法
- Pytest成魔之路 —— fixture 之大解剖!
- 力扣(leetcode)第482题密钥格式化(Python)
- 每日一题——链表的回文结构
- 大路灯护眼灯哪个牌子好?好用护眼大路灯推荐
- NumPy 高级教程——性能优化
- ssm基于Javaweb的物流信息管理系统的设计与实现论文
- ES6学习(五):async和await的使用
- day24_java的反射机制
- Python爬虫系列-有道批量翻译英文单词-注音标版