Text2SQL学习整理(四)将预训练语言模型引入WikiSQL任务
导语
上篇博客:Text2SQL学习整理(三):SQLNet与TypeSQL模型简要介绍了WikiSQL数据集提出后两个早期的baseline,那时候像BERT之类的预训练语言模型还未在各种NLP任务中广泛应用,因而作者基本都是使用Bi-LSTM作为基本组件搭建模型。
本篇博客将介绍两个借助预训练语言模型BERT来解决WIkiSQL数据集挑战的方法:SQLOVA和X-SQL模型。其中,SQLOVA这篇工作更是发表在了2019年的NIPS上,可以看出这个任务被越来越多人所关注。
A Comprehensive Exploration on WikiSQL with Table-AwareWord Contextualization
创新点
SQLOVA工作的创新点有两个:
- 借助预训练模型,达到人类表现;
- 给出了WikiSQL数据集上的人类表现。
模型架构
整个框架包含两个部分:
- Table-aware Encoding Layer,用于获取表和上下文感知的question word表示;
- NL2SQL Layer,用于从编码表示生成SQL查询。
输入模块
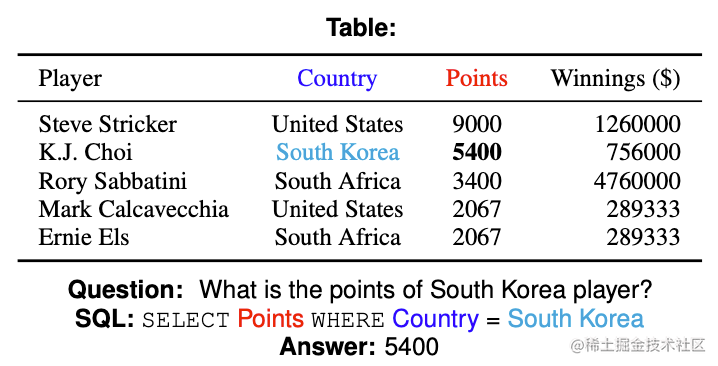
上图为一个WikiSQL数据集中的问题-SQL示例。表格的schema(即图中的表名、列名等)是一种结构性信息,而在利用BERT之类的预训练模型时,需要将所有输入全部转为一个序列。SQLOVA的转换方式如下:
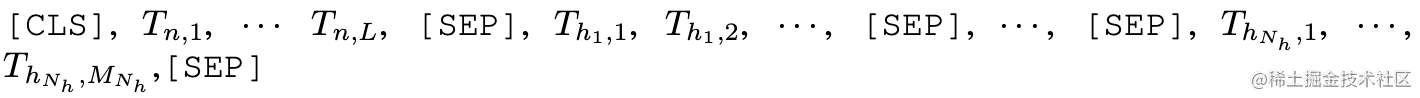
可以看到,序列的开始部分是query(也即用户的自然语言问句Question),之后是数据库的各个列的名字。因为WIkiSQL是单表的数据库,所以不需要编码表名。在序列化过程中,SQLOVA利用了BERT中的[CLS]、[SEP]等特殊token作为分隔符。
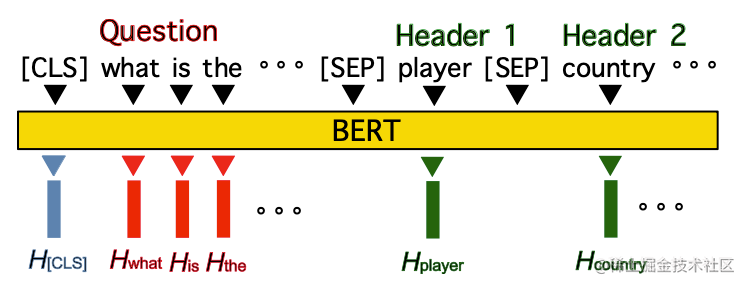
如上图所示,输入Table-aware Encoding Layer将自然语言查询与整个表的所有header放在一起进行编码,用来表示问题与表两者信息之间存在交互。
NL2SQL模块
与之前的SQLNet类似,SQLOVA在生成SQL语句时采用slot filling的思想,还是分别用6个子模块来生成SQL语句的各个部分。
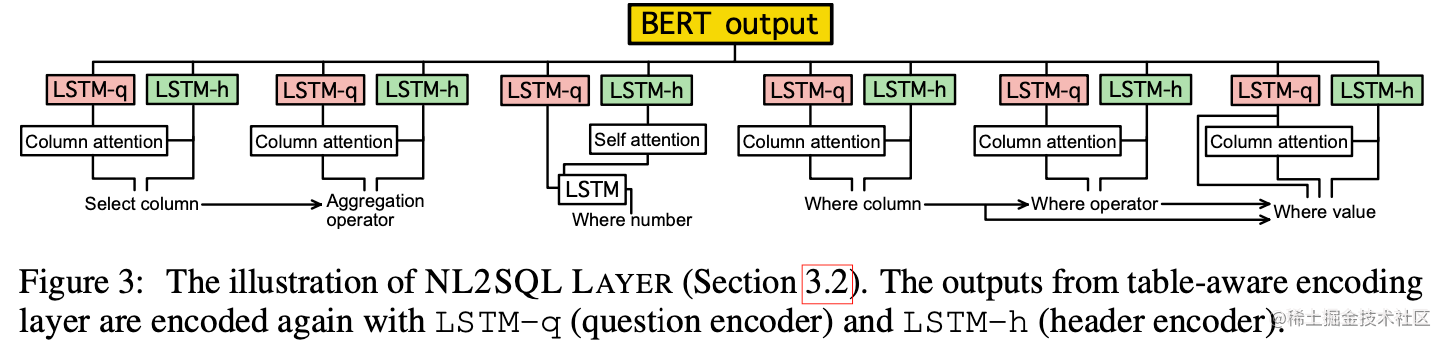
NL2SQL层的6个子模块不共享参数、代替使用pointer network推断Where_val,这里训练一个模块来推断start和end、where_val不仅依赖于where_col还依赖于where_op(比如text的类型不存在>或<)、当要结合question和header时,采用的是拼接操作而不是求和操作。
Execution-guided decoding
SQLOVA使用了Execution-guided decoding技术,以减少不可执行的query语句。
所谓Execution-guided decoding就是在输出返回结果时对检查生成的SQL序列是否是一条语法正确的SQL语句,使模型最终输出的SQL语句一定是可以无语法错误执行的。它是通过将候选列表中的SQL查询按顺序提供给执行器来执行的,并丢弃那些执行失败或返回空结果的查询。该技术可以参考论文Robust Text-to-SQL Generation with Execution-Guided Decoding.
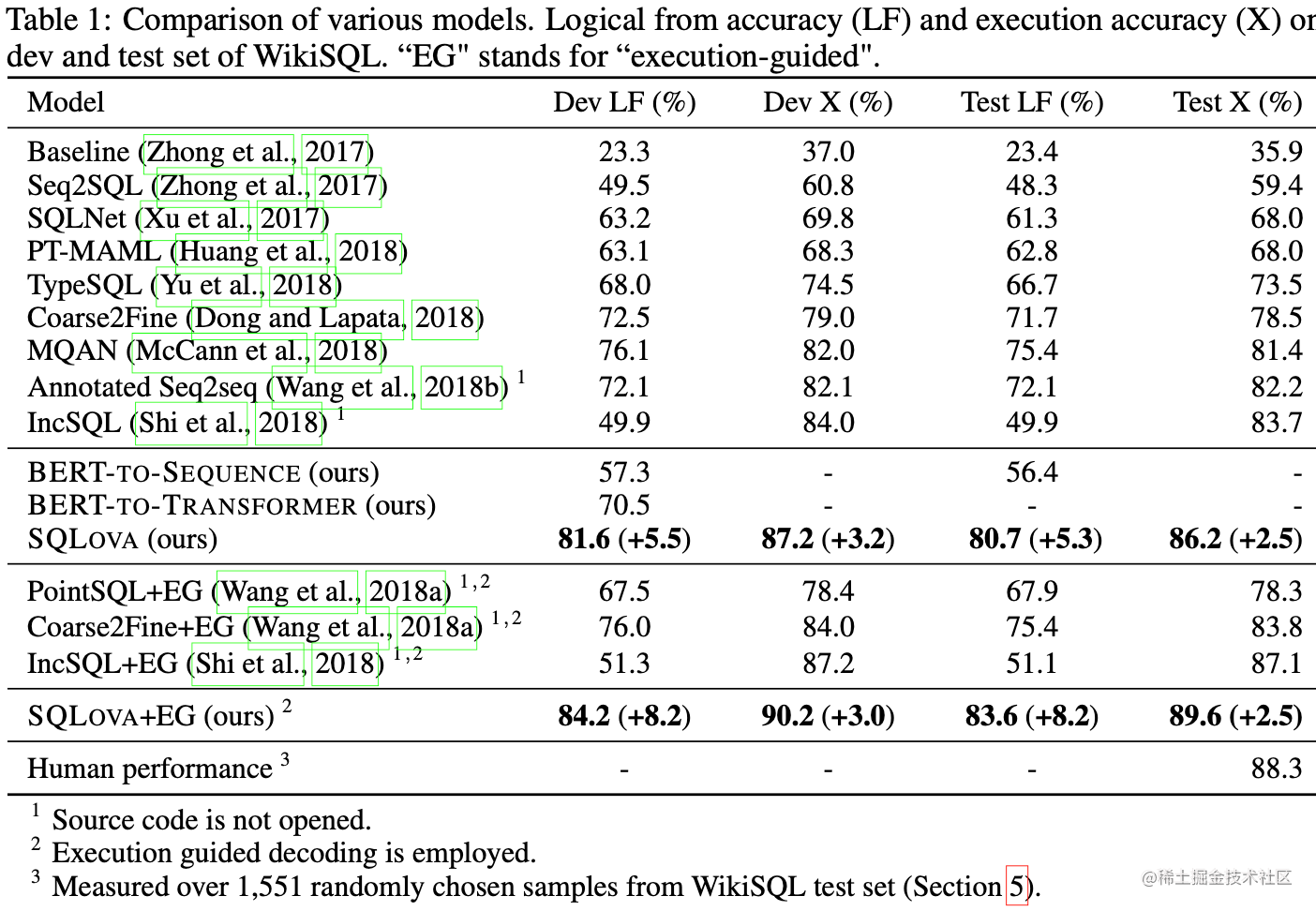
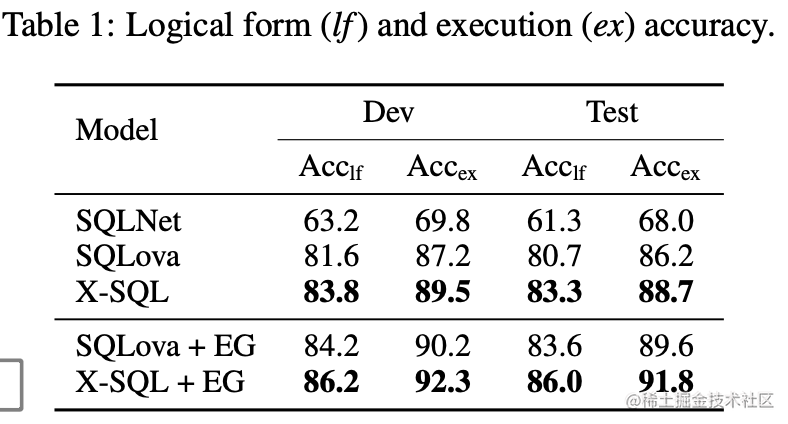
实验结果
文章还给出了human的performance,从结果来看,SQLova已超过了人类表现。
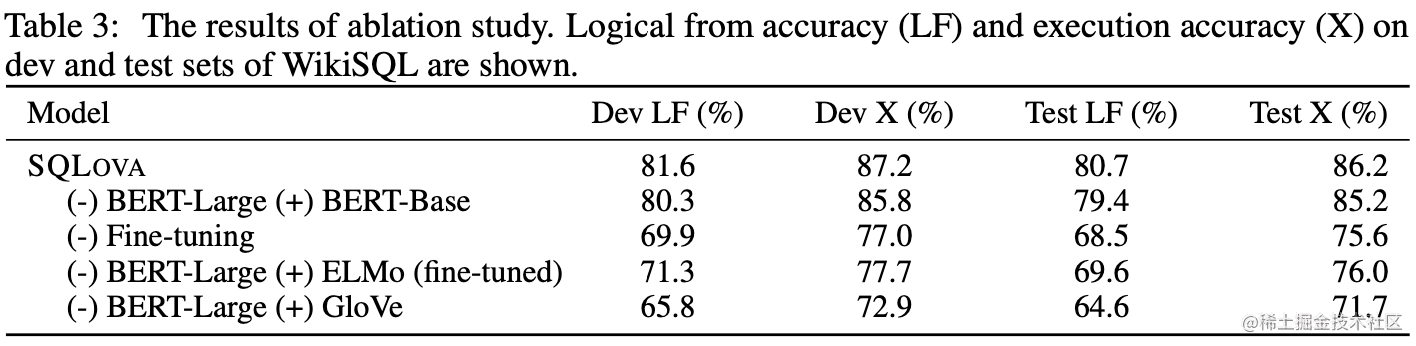
Ablation Study
同时,文章还进行了充分的消融实验以检验各个模块的有效性。可以看出,预训练模型BERT的引入对结果有很大提升。即使用词语的上下文对logical form的acc有很大贡献。
X-SQL: reinforce schema representation with context
创新点
X-SQL也是利用预训练语言模型的方法。它使用BERT风格预训练模型的上下文输出来增强结构化schema表示,并在下游任务中与类型信息一起学习一个新的schema表示。同时,这里不再使用BERT,而是使用MT-DNN(Multi-Task Deep Neural Networks for Natural Language Understanding一种多任务学习出来的语言模型,详见https://fyubang.com/2019/05/23/mt-dnn/)预训练模型。
模型架构
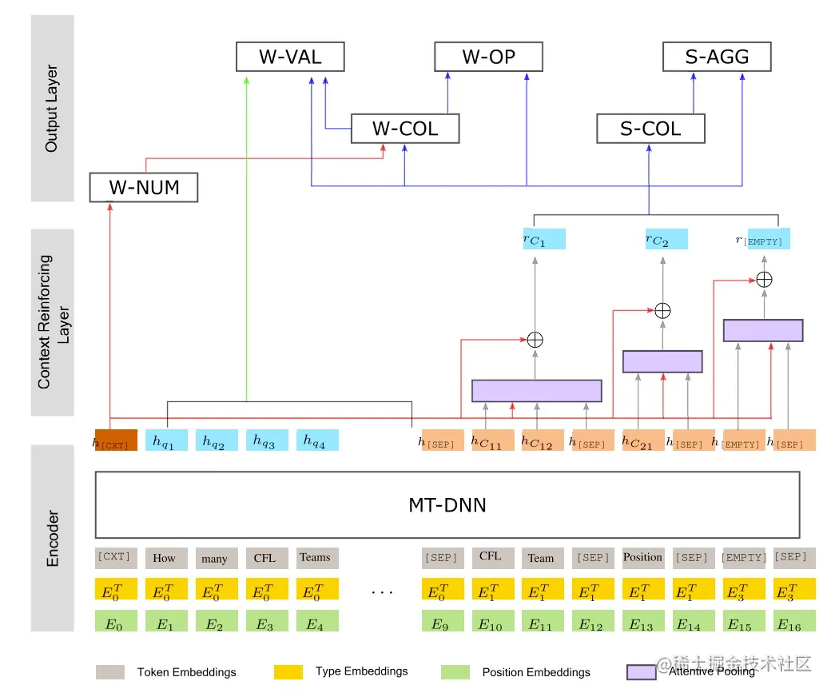
模型的整体架构如上图所示。
模型包括三个部分:
- 序列编码器:
- 上下文增强的schema编码器
- 输出层
序列编码器
序列编码器部分类似BERT,但主要改动如下:
- 给每个表增加了一个特殊的空列[EMPTY];
- 将segment embedding替换为type embeding,包括问题、类别列、数字列、特殊空列,共4种类型;
- 采用MT-DNN而不是BERT-Large来初始化。
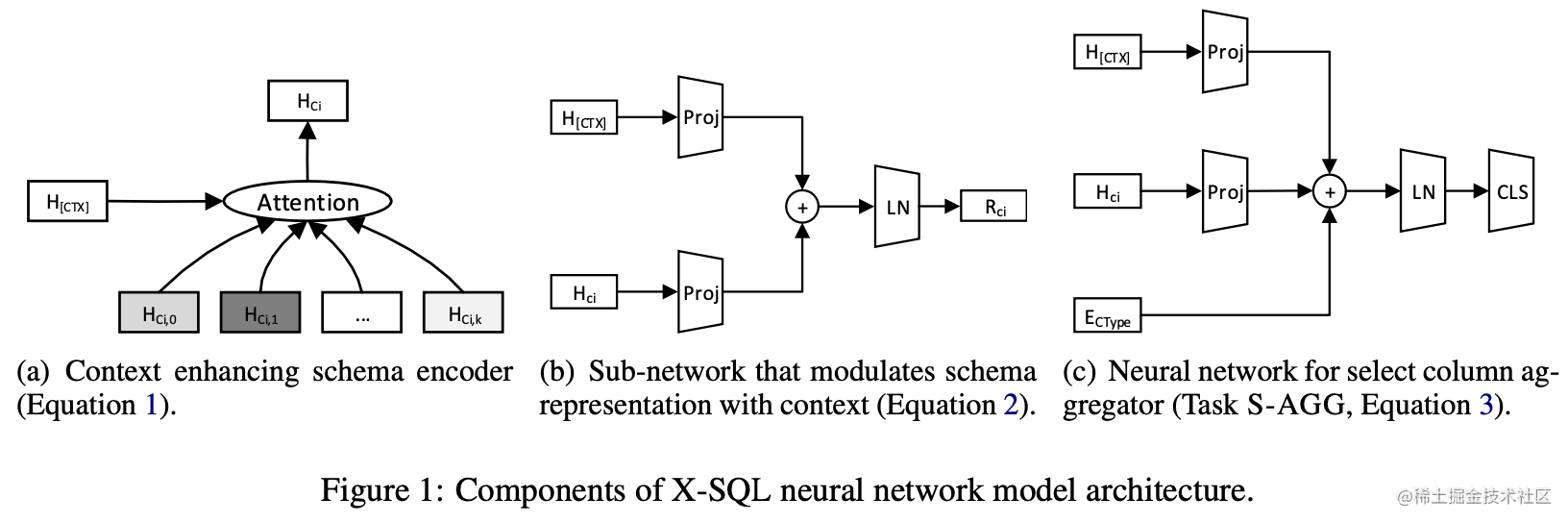
上下文增强的schema编码器:
该模块根据表格每列的tokens的编码来得到相应列的表示hCi,利用attention。将每个列名对应的多个token输出的向量聚合并且在混入[CTX] token中的信息。
输出层
采用与之前同样的做法,最终输出时将任务分解为6个子任务,每个均采用更简单的结构,采用LayerNorm,输入为schema的表示hCi和上下文表示hCTX。
结果
通过这些改进,X-SQL将性能表现提升至90%以上,超过了SQLOVA。
总结
本文介绍了两个借助预训练语言模型BERT(MT-DNN)来表示schem和Question之间上下文关系表示的方法,通过预训练语言模型强大的表示能力,模型第一次在数据集上的表现超越了人类。足以见证当今NLP技术发展之迅速。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SAAS家政预约小程序源码系统 商业运营版+在线预约 源码开源可二次开发 带完整的搭建教程
- Linux Capabilities 基础概念与基本使用
- 测试开发体系介绍——测试体系介绍-L2
- Java 并发编程中的线程池
- C语言运算符
- C++继承与派生——(1)继承的层次关系
- mybatis高级查询和注解开发
- 外汇天眼:仿冒汇丰──高收益投资方案诱入金,控账户提领异常骗缴费
- HTML小白入门学习-列表标签
- 社招面试题:说一说SPI是什么,有哪些使用场景?