并发编程之并发容器
目录
读多写少场景使用CopyOnWriteArrayList举例
并发容器
? ? ? ? java中常用的集合ArrayList、LinkedList、HashMap这些容器都是非线程安全的。Java先提供了同步容器供使用。同步容器可以简单地理解为通过synchronized来实现同步的容器,比如Vector、Hashtable以及SynchronizedList等容器。这样做的代价是削弱了并发性,当多个线程共同竞争容器级的锁时,吞吐量就会降低。
? ? ? ?为了解决同步容器的性能问题,有了并发容器,java.util.concurrent包中提供了多种并发类容器。以下以部分并发容器详细介绍。
CopyOnWriteArrayList
应用场景
1. 读多写少的情况
? ? ? 当对列表的读操作远远多于写操作时,CopyOnWriteArrayList可以提供良好的性能。由于读操作不涉及锁,多个线程可以同时读取,而写操作只需要在复制时进行同步。
2. 避免读写冲突
? ? ? ?在某些情况下,使用传统的同步容器可能会导致读写冲突,因为读取和写入操作同时进行时可能会引发竞态条件。CopyOnWriteArrayList避免了这种冲突,通过牺牲内存来保证读取的一致性。
3.?不需要实时更新的情况
? ? ? ?如果对实时性要求不高,即时写操作会导致列表被复制,但读取操作仍然可以在原始列表上进行,从而保持一致性。
4. 稳定的数据集
? ? ? ?当数据集相对稳定,且写操作相对较少时,CopyOnWriteArrayList是一个合适的选择。写操作不频繁的情况下,复制列表的开销相对较小。
常用方法
CopyOnWriteArrayList copyOnWriteArrayList= new CopyOnWriteArrayList();
// 新增
copyOnWriteArrayList.add(1);
// 设置(指定下标)
copyOnWriteArrayList.set(0, 2);
// 获取(查询)
copyOnWriteArrayList.get(0);
// 删除
copyOnWriteArrayList.remove(0);
// 清空
copyOnWriteArrayList.clear();
// 是否为空
copyOnWriteArrayList.isEmpty();
// 是否包含
copyOnWriteArrayList.contains(1);
// 获取元素个数
copyOnWriteArrayList.size();读多写少场景使用CopyOnWriteArrayList举例
? ? ? ?假设有一个任务调度器,其中包含了多个定时任务,每个任务都有一个执行时间。多个线程同时读取任务列表以查看下一个要执行的任务,而写入操作仅在添加、删除任务时发生。?
import java.util.concurrent.CopyOnWriteArrayList;
public class TaskScheduler {
// 使用CopyOnWriteArrayList作为任务列表
private CopyOnWriteArrayList<Task> taskList = new CopyOnWriteArrayList<>();
// 添加任务
public void addTask(Task task) {
taskList.add(task);
}
// 删除任务
public void removeTask(Task task) {
taskList.remove(task);
}
// 获取下一个要执行的任务
public Task getNextTask() {
if (!taskList.isEmpty()) {
// 获取第一个任务(最早执行的任务)
return taskList.get(0);
}
return null;
}
// 其他与任务调度相关的操作
// ...
}
class Task {
private String name;
private long executionTime;
// 构造方法、getter、setter等
// ...
}
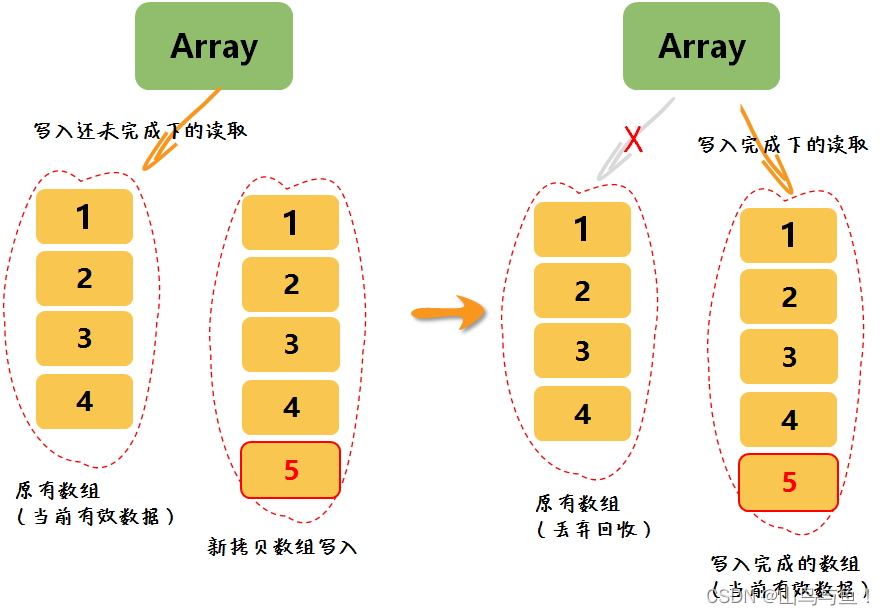
??CopyOnWriteArrayList原理
? ? ? ?CopyOnWriteArrayList 内部使用了一种称为“写时复制”的机制。当需要进行写操作时,它会创建一个新的数组,并将原始数组的内容复制到新数组中,然后进行写操作。因此,读操作不会被写操作阻塞,读操作返回的结果可能不是最新的,但是对于许多应用场景来说,这是可以接受的。此外,由于读操作不需要加锁,因此它可以支持更高的并发度。
? ? ? ? ? ??
CopyOnWriteArrayList 的缺陷
1. 内存开销大
? ? ? ?每次写入操作都会创建一个列表的副本,这导致了较大的内存开销。在数据集很大的情况下,频繁的写入操作可能占用大量内存,这可能成为一个问题。
2. 不适合写入频繁的场景
? ? ? ? 如果写入操作非常频繁,复制列表的开销可能会变得显著,并且可能会导致性能问题。适用于写多读少或写入相对较少的场景。
3. 不适合实时性要求高的场景
? ? ? ?由于写入操作会导致复制整个列表,而且复制操作不是原子的,因此在写入过程中,读取操作可能会看到部分修改或者不一致的状态。这使得 CopyOnWriteArrayList 不适合对实时性要求很高的场景。
4. 不支持并发修改迭代
? ? ? ?CopyOnWriteArrayList 的迭代器是不可修改的,因此在使用迭代器遍历列表时,不允许修改列表。虽然这是为了确保线程安全设计的,但对于某些应用可能会限制灵活性。
5. 不适用于元素更新频繁的情况
? ? ? ?如果在列表中的元素需要频繁更新,CopyOnWriteArrayList 可能不是最佳选择,因为每次更新都会导致整个列表的复制,开销较大。
扩展迭代器fail-fast与fail-safe机制
fail-fast 机制
? ? ? ?fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生 fail-fast 事件。例如:当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了。那么线程A访问集合时,就会抛出 ConcurrentModificationException异常,产生fail-fast事件。
fail-fast解决方案
方案一
? ? ? ?在遍历过程中所有涉及到改变modCount 值的地方全部加上synchronized 或者直接使用 Collection#synchronizedList,这样就可以解决问题,但是不推荐,因为增删造成的同步锁可能会阻塞遍历操 作。
方案二
? ? ? ?使用CopyOnWriteArrayList 替换 ArrayList,推荐使用该方案(即fail-safe)。
fail-safe机制
? ? ? ?任何对集合结构的修改都会在一个复制的集合上进行,因此不会抛出ConcurrentModificationException。在 java.util.concurrent 包中的集合,如? CopyOnWriteArrayList、ConcurrentHashMap 等,它们的迭代器一般都是采用 Fail-Safe 机制。
缺点
1. 采用 Fail-Safe 机制的集合类都是线程安全的,但是它们无法保证数据的实时一致性,它们只能保证数据的最终 一致性。在迭代过程中,如果集合被修改了,可能读取到的仍然是旧的数据。
2. Fail-Safe 机制还存在另外一个问题,就是内存占用。由于这类集合一般都是通过复制来实现读写分离的,因此它 们会创建出更多的对象,导致占用更多的内存,甚至可能引起频繁的垃圾回收,严重影响性能。
ConcurrentHashMap
? ? ? ? ConcurrentHashMap是Java中线程安全的哈希表,它支持高并发并且能够同时进行读写操作。 在JDK1.8之前,ConcurrentHashMap使用分段锁以在保证线程安全的同时获得更大的效率。JDK1.8开始舍弃了分段锁,使用自旋+CAS+synchronized关键字来实现同步。官方的解释中:一是节省内存空间 ,二是分段锁需要更多的内存空间。
应用场景
1. 高并发的数据存储
? ? ? ?当多个线程需要同时访问和修改一个共享的哈希表时,ConcurrentHashMap 提供了一种线程安全的方式,避免了在读取和写入操作上的锁竞争。
2. 缓存管理
? ? ? ? 用作缓存的存储结构,特别是在读多写少的情况下。由于 ConcurrentHashMap 具有分段锁机制,多个线程可以并发地访问不同的段,从而提高并发性能。
3. 并发计数器
? ? ? ? 当需要进行多线程并发计数时,可以使用 ConcurrentHashMap 的原子操作方法,如 compute、merge 等,以确保计数的一致性。
4. 分布式系统中的协调
? ? ? ? 在分布式系统中,ConcurrentHashMap 可以用于协调不同节点之间的数据共享。它提供了一种线程安全的方式来管理共享数据,以避免并发访问问题。
5. 任务调度和执行管理
? ? ? ?在多线程的任务调度和执行场景中,ConcurrentHashMap 可以用来存储和管理任务的状态、结果等信息,确保在并发情况下的正确性。
6. 实时性要求不高的场景
? ? ? ?相较于传统的 HashMap,ConcurrentHashMap 在保证线程安全的同时,提供了更高的并发性。因此,在对实时性要求不是非常高的场景下,可以使用它来提高并发性能。
7. 在线程池中的任务管理
? ? ? ?当多个线程池中的任务需要共享数据时,ConcurrentHashMap 可以作为一个线程安全的数据结构来确保并发访问的正确性。
常用方法
// 创建一个 ConcurrentHashMap 对象
ConcurrentHashMap<Object, Object> concurrentHashMap = new ConcurrentHashMap<>();
// 添加键值对
concurrentHashMap.put("key", "value");
// 添加一批键值对
concurrentHashMap.putAll(new HashMap());
// 使用指定的键获取值
concurrentHashMap.get("key");
// 判定是否为空
concurrentHashMap.isEmpty();
// 获取已经添加的键值对个数
concurrentHashMap.size();
// 获取已经添加的所有键的集合
concurrentHashMap.keys();
// 获取已经添加的所有值的集合
concurrentHashMap.values();
// 清空
concurrentHashMap.clear();并发场景下线程安全举例
import java.util.concurrent.ConcurrentHashMap;
public class CacheManager {
// 使用ConcurrentHashMap作为缓存存储
private static ConcurrentHashMap<String, String> cache = new ConcurrentHashMap<>();
public static void main(String[] args) {
// 模拟多个线程同时访问缓存
for (int i = 0; i < 5; i++) {
String key = "Key" + i;
Thread readerThread = new Thread(() -> readFromCache(key));
readerThread.start();
String newKey = "NewKey" + i;
String value = "Value" + i;
Thread writerThread = new Thread(() -> addToCache(newKey, value));
writerThread.start();
}
}
// 从缓存读取数据的方法
private static void readFromCache(String key) {
// 使用get方法从缓存读取数据
String value = cache.get(key);
System.out.println(Thread.currentThread().getName() + ": Reading from cache - Key: " + key + ", Value: " + value);
}
// 向缓存添加数据的方法
private static void addToCache(String key, String value) {
// 使用put方法向缓存添加数据
cache.put(key, value);
System.out.println(Thread.currentThread().getName() + ": Adding to cache - Key: " + key + ", Value: " + value);
}
}
? ? ? ? ?在上述案例中,多个线程可以同时读取和写入缓存项,而ConcurrentHashMap会确保在多线程并发访问的情况下不会发生数据不一致或线程安全问题。
ConcurrentHashMap底层结构
在jdk1.7及其以下的版本中,结构是用Segments数组 + HashEntry数组 + 链表实现的。
? ? ??
jdk1.8抛弃了Segments分段锁的方案,而是改用了和HashMap一样的结构操作,也就是数组 + 链表 + 红黑树结构,比jdk1.7中的ConcurrentHashMap提高了效率,在并发方面,使用了cas + synchronized的方式保证数据的一致性。
? ? ? ??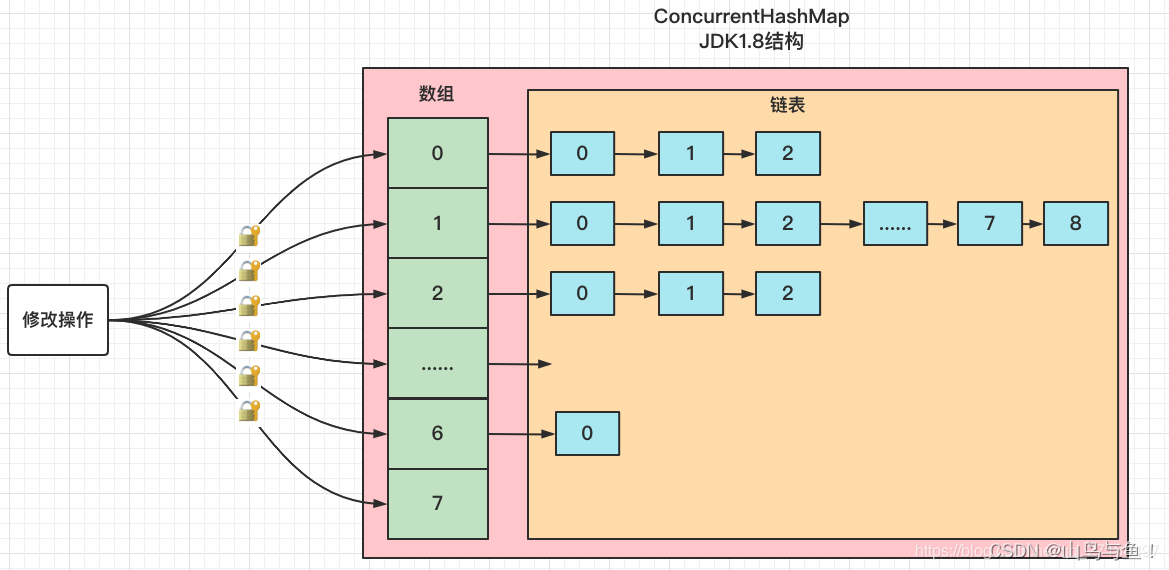
链表转化为红黑树需要满足2个条件:
1. 链表的节点数量大于等于树化阈值8
2. Node数组的长度大于等于最小树化容量值64
#树化阈值为8
static final int TREEIFY_THRESHOLD = 8;
#最小树化容量值为64
static final int MIN_TREEIFY_CAPACITY = 64;
?ConcurrentSkipListMap
? ? ? ?ConcurrentSkipListMap 是 Java 中的一种线程安全、基于跳表实现的有序映射(Map)数据结构。 它是对 TreeMap 的并发实现,支持高并发读写操作。 ConcurrentSkipListMap适用于需要高并发性能、支持有序性和区间查询的场景,能够有效地提高系 统的性能和可扩展性。
应用场景
1. 并发映射
???????ConcurrentSkipListMap 实现了 ConcurrentMap 接口,可以被用作并发映射(key-value映射)的数据结构。多个线程可以安全地同时访问和修改映射。
2. 有序性要求
???????由于底层是基于跳表实现的,ConcurrentSkipListMap 中的元素是有序的。如果你需要按照键的自然顺序或者自定义的比较器顺序来存储和访问数据,这个类就是一个很好的选择。
3. 高并发读写
???????跳表的结构允许多个线程并发地进行读取和写入操作,而不会导致锁竞争。这使得 ConcurrentSkipListMap 在高并发环境下的读写性能表现相对较好。
4. 范围查询
???????跳表的结构使得范围查询变得高效。ConcurrentSkipListMap 提供了一些方法,如 subMap,可以用于获取键范围内的子映射。
5. 替代传统的并发映射实现
???????在某些情况下,ConcurrentSkipListMap 可以作为对传统的基于锁的并发映射实现的一种替代。它的设计允许更高的并发性。
常用方法
添加元素:
put(K key, V value): 将指定的键值对添加到映射中。
putIfAbsent(K key, V value): 如果指定的键尚未与值关联,则将其与给定的值关联。
获取元素:
get(Object key): 返回指定键所映射的值,如果该键不存在,则返回 null。
firstKey(): 返回映射中的第一个(最小的)键。
lastKey(): 返回映射中的最后一个(最大的)键。
lowerKey(K key): 返回严格小于给定键的最大键,如果不存在则返回 null。
higherKey(K key): 返回严格大于给定键的最小键,如果不存在则返回 null。
删除元素:
remove(Object key): 从映射中删除指定键的映射。
pollFirstEntry(): 移除并返回映射中的第一个(最小的)映射。
pollLastEntry(): 移除并返回映射中的最后一个(最大的)映射。
范围查询:
subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive): 返回映射中键的部分视图,其键范围从 fromKey 到 toKey。
遍历:
entrySet(): 返回包含映射中所有映射的 Set 视图。
keySet(): 返回包含映射中所有键的 NavigableSet 视图。
values(): 返回包含映射中所有值的 Collection 视图。
其他操作:
size(): 返回映射中的键值对数量。
isEmpty(): 如果映射不包含键值对,则返回 true。
clear(): 从映射中移除所有映射。跳表
跳表是一种基于有序链表的数据结构,支持快速插入、删除、查找操作,其时间复杂度为O(log n), 比普通链表的O(n)更高效。

 ?跳表的特性
?跳表的特性
一个跳表结构由很多层数据结构组成。每一层都是一个有序的链表,默认是升序。也可以自定义排序方法。 最底层链表(图中所示Level1)包含了所有的元素。 如果每一个元素出现在LevelN的链表中(N>1),那么这个元素必定在下层链表出现。 每一个节点都包含了两个指针,一个指向同一级链表中的下一个元素,一个指向下一层级别链表中的相同值元素。
跳表的查找

?跳表的插入
跳表插入数据的流程如下:
找到元素适合的插入层级K,这里的K采用随机的方式。若K大于跳表的总层级,那么开辟新的一层,否则在对应 的层级插入。 申请新的节点。 调整对应的指针。?
假设我要插入元素13,原有的层级是3级,假设K=4:
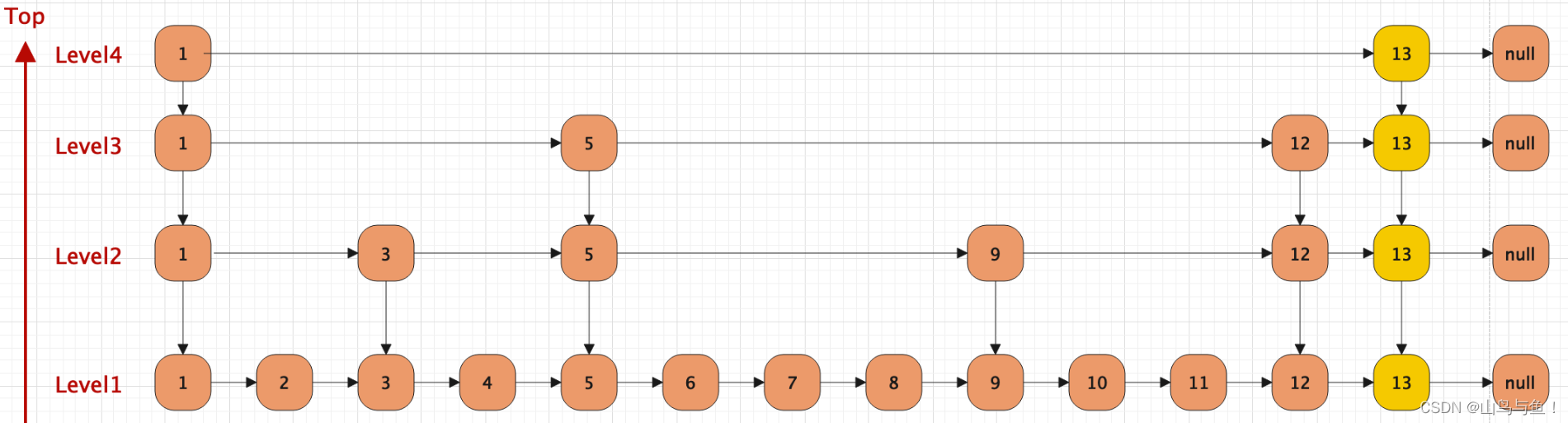
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- HCIP自学笔记—ospf特殊区域配置
- 定时器PWM控制RGB彩灯案例
- 【C++】理解string类的核心理念(实现一个自己的string类)
- 国产芯片ACL16_S 系列 ,低成本物联网安全,可应用物联网认证、 SIM、防抄板和设备认证等产品上
- Python Pandas DataFrame对象数据的排序(第13讲)【sort_values()&rank()】
- C++ Qt开发:自定义Dialog对话框组件
- 乱签电子合同“吃大亏”
- 清除conda和pip缓存的方法
- qml中获取Loader加载的顶层对象
- 基于Java (spring-boot)的停车场管理系统