datawhale 大模型学习 第四章-新模型架构
发布时间:2024年01月22日
一、现状
GPT3 是一个通过96个Transformer block堆叠在一起的神经网络.即: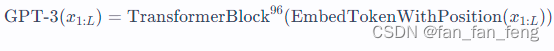
每一个TransformerBlock是一个多头注意力层的Block

目前大模型的规模已经到了极限(模型越大,需要训练资源和时间也就越长)
二、混合专家模型
混合专家模型通俗点讲就是:有N个专家,每个专家有各种的不同领域能力和模型参数,通过一个 门控制机制来给不同专家分配权重,最终汇总所有专家的结果。

优点:
1.专家与专家之间独立,可以并行计算
2.每个专家模型可以放置在不同的GPU机器上
三、基于检索的模型
3.1 去噪目标训练
就是在输入里面mask一些单子,然后在模型的输出里面吧mask掉的单词预测出来
输入: Thank you <X> me to your party <Y> week
输出:<X> for inviting? <Y> last
3.2 检索方法? ? ? ?
有一个文档集合库,里面是一群文档的集合:
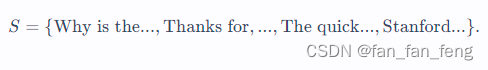
基于检索的模型直观的生成过程:
- 基于输入?xx?,检索相关序列?zz?。
- 给定检索序列?zz?和输入?xx?,生成输出?yy?。
示例(开放问答):
- 输入?xx?:What is the capital of Canada?
- 检索?zz?:Ottawa is the capital city of Canada.
- 输出?yy?:Ottawa
最近邻是最常用的一种检索方法:
- SS?是训练集。
- 检索?(x',y') \in S(x′,y′)∈S?,使得?x'x′?和?xx最相似。
- 生成?y = y'y=y′?。
? ???
文章来源:https://blog.csdn.net/fan_fan_feng/article/details/135737965
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Allure04-用例失败截图
- SSR服务端渲染解决了什么问题?有做过SSR吗?
- NodeJs第十三章 cookie
- easyx基础操作总结
- springboot/java/php/node/python高级婚纱定制系统【计算机毕设】
- SCC212 Javascript
- DataFunSummit:2023年知识图谱在线峰会-核心PPT资料下载
- Java瑞格题库
- SpringBoot测试类提示没有发现测试(JUnit4和JUnit5注解)
- python&selenium自动化测试实战项目