string部分接口的简单使用以及模拟实现
1.为什么学习string类?
1.1 C语言中的字符串
C语言中,字符串是以'\0'结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
2.标准库中的string类?
2.1 string类的了解
CPP官网有很好的说明string - C++ Reference (cplusplus.com)
总结:
????????1. string是表示字符串的字符串类
????????2. 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
????????3. string在底层实际是:
basic_string模板类的别名,typedef basic_string<char, char_traits, allocator>string;
????????4. 不能操作多字节或者变长字符的序列。
在使用string类时,必须包含#include头文件以及using namespace std;
2.2 string类的常用接口说明?
| (constructor)函数名称 | 功能说明 |
|---|---|
| string() (重点) | 构造空的string类对象,即空字符串 |
| string(const char* s) (重点) | 用C-string来构造string类对象 |
| string(size_t n, char c) | string类对象中包含n个字符c |
| string(const string&s) (重点) | 拷贝构造函数 |
void test_string1()
{
string s1; //构造空的string类对象s1
string s2("hello C++"); //用C格式字符串构造string类对象s2
string s3(s2); //拷贝构造s3
}
1.这四个掌握好,其他的也可以去了解一下,可能有这个功能查查能用就行。?
2.连蒙带猜看别人写的接口。程序员看基本的英文文档是最基本的,好好看好好读,不认识的单词搜一下,string的用法可以都去看看。去看文档说明,其次意思猜猜也可以知道。
3.析构函数,自动调用一般都不用写
4.赋值
| 函数名称 | 功能说明 |
|---|---|
| operator[] (重点) | 返回pos位置的字符,const string类对象调用 |
| begin + end | begin获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭代器 |
| rbegin + rend | begin获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭代器 |
| 范围for | C++11支持更简洁的范围for的新遍历方式 |
void Teststring2()
{
string s("hello C++");
// 3种遍历方式:
// 需要注意的以下三种方式除了遍历string对象,还可以遍历是修改string中的字符,
// 另外以下三种方式对于string而言,第一种使用最多
// 1. for+operator[]
for (size_t i = 0; i < s.size(); i++)
{
cout << s[i] << endl;
}
// 2.迭代器
string::iterator it = s.begin();
while (it != s.end())
{
cout << *it << endl;
++it;
}
// string::reverse_iterator rit = s.rbegin();
// C++11之后,直接使用auto定义迭代器,让编译器推到迭代器的类型
auto rit = s.rbegin();
while (rit != s.rend())
{
cout << *rit << endl;
}
// 3.范围for
for (auto ch : s)
{
cout << ch << endl;
}
}几种迭代方式:
- 下标+[](像杀马特不是主流)
迭代器(真正主流,最核心的)
普通迭代器
const迭代器(只读)
反向迭代器
const反向迭代器
传参的时候容易出现const对象
区别:不能修改,const修饰的是指针指向的内容不能修改
auto用起来虽然爽但是可读性下降。
范围for
补充:
? ? ? ? i. 最简单的方式:下标+[] :像杀马特不是主流
????????length和size意思是一样的(获取下标)更喜欢用size,历史发展导致的。底层调用了operator重载。
? ? ? ? ii. 迭代器(iterator):
? ? ? ??用法:
? ? ? ? 1.就像是用指针的方式进行遍历访问。在string里可能用处不大,因为有[]
? ? ? ? 2.下标+[]只适用于部分容器,底层物理有一定连续性。链式结构、树形、哈希结构,只能用迭代器,迭代器才是容器访问主流形态。
? ? ? ? 3.区间都是左闭右开
? ? ? ? 4.[]提供了两个版本(普通版本:可读可写,const版本:只读
????????????????(1)本质是各自调用各自的。
? ? ? ? ? ? ? ? (2)const_iterator 和 const iterator不同
????????????????????????_:本质保护迭代器指向的数据 *it不能修改
? ? ? ? ? ? ? ? ? ? ? ? ??:保护的迭代器本身不能修改,it不能修改。不符合我们需求不能遍历
? ? ? ? ? ? ? ? (3)都能支持范围for,现阶段非常舒服。
| 函数名称 | 功能说明 |
|---|---|
| size(重点) | 返回字符串有效字符长度 |
| length | 返回字符串有效长度 |
| capacity | 返回空间总大小 |
| empty (重点) | 检测字符串释放为空串,是返回true,否则返回false |
| clear (重点) | 清空有效字符 |
| reserve (重点) | 为字符串预留空间** |
| resize (重点) | 将有效字符的个数该成n个,多出的空间用字符c填充 |
简单举例:?
void Teststring1()
{
//string类对象支持直接使用cin和cout进行输入和输出
string s("hello C++!!!");
cout << s.size() << endl;
cout << s.length() << endl;
cout << s.capacity() << endl;
cout << s << endl;
//将s中的字符串清空,只是将size清0,不改变底层空间的大小
s.clear();
cout << s.size() << endl;
cout << s.capacity() << endl;
//将s中的有效字符个数增加到10哥,多出位置用'x'进行填充
//xxxxxxxxxx
//此时s中有效字符个数已经增加到15个
s.resize(10, 'x');
cout << s.size() << endl;
cout << s.capacity() << endl;
//将s中有效字符个数增加到15个,多出位置用缺省值'\0'进行填充
s.resize(15);
cout << s.size() << endl;
cout << s.capacity() << endl;
cout << s << endl;
//将有效字符个数缩小到5个
s.resize(5);
cout << s.size() << endl;
cout << s.capacity() << endl;
cout << s << endl;
}?resize和reserve的区别:
reserve:最大价值知道多少空间提前去扩容。只影响容量,不影响数据。
//reserve只影响容量,不会影响数据 void Teststring2() { string s1; cout << s1.capacity() << endl; s1.reserve(); cout << s1.capacity() << endl; string s2("hello C++!!!"); cout << s2.capacity() << endl; s2.reserve(10); cout << s2.capacity() << endl; }注意:VS里面不会,缩容代价很大,缩容能分段释放
resize:?既影响容量,也影响数据。
void Teststring3() { string s1("hello C++"); cout << s1.size() << endl; cout << s1.capacity() << endl; cout << s1 << endl; }运行结果:
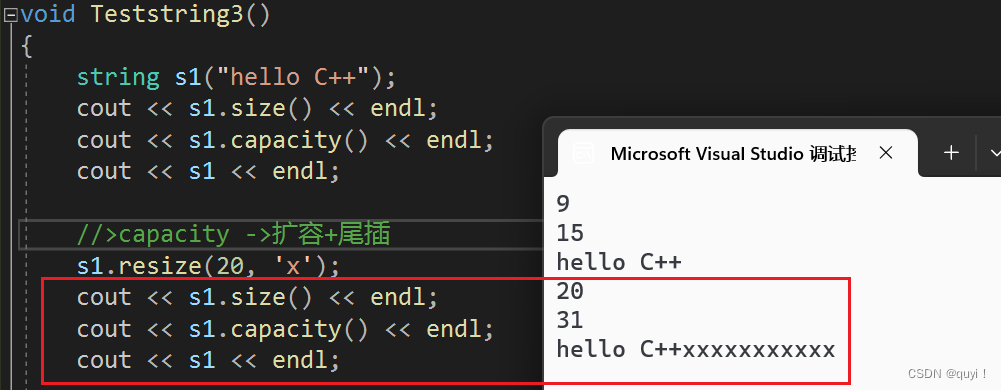
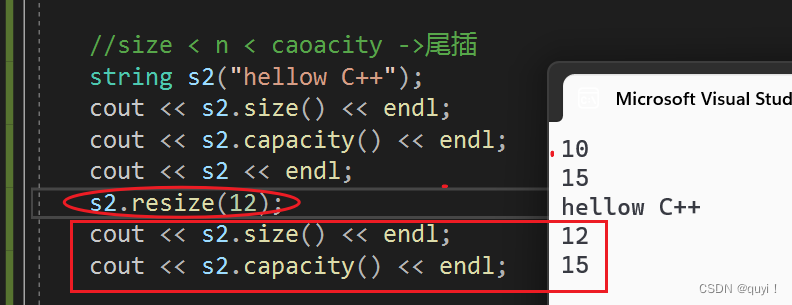
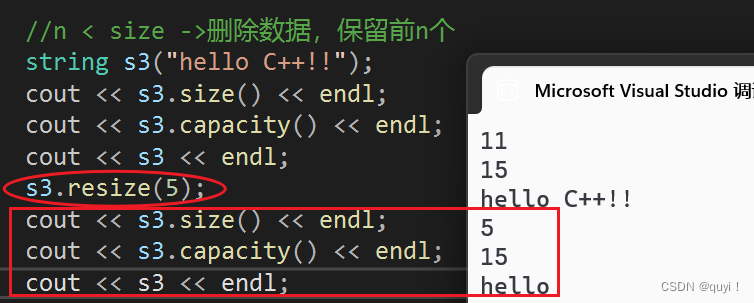
void Teststring3() { string s1("hello C++"); cout << s1.size() << endl; cout << s1.capacity() << endl; cout << s1 << endl; //>capacity ->扩容+尾插 s1.resize(20, 'x'); cout << s1.size() << endl; cout << s1.capacity() << endl; cout << s1 << endl; //size < n < caoacity ->尾插 string s2("hellow C++"); cout << s2.size() << endl; cout << s2.capacity() << endl; cout << s2 << endl; s2.resize(12); cout << s2.size() << endl; cout << s2.capacity() << endl; //n < size ->删除数据,保留前n个 string s3("hello C++!!"); cout << s3.size() << endl; cout << s3.capacity() << endl; cout << s3 << endl; s3.resize(5); cout << s3.size() << endl; cout << s3.capacity() << endl; }运行结果:
1.?n > capacity?扩容+尾插
2.size < n < caoacity ->尾插
3.n < size ->删除数据,保留前n个

注意事项:
1.size()和length()方法用法一样,引入size()的原因是为了与其他容器的接口保持一
致,一般情况下基本都是用size()。2.clear()只是将string中有效字符清空,不改变底层空间大小。
3.resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时::resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。
4. reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小。
| 函数名称 | 功能说明 |
|---|---|
| push back | 在字符串后尾插字符c |
| append | 在字符串后追加一个字符 |
| operator+=(重点) | 在字符串后追加字符串str |
| c_str (重点) | 返回C格式字符串 |
| find + npos (重点) | 从字符串pos位置开始往后找字符C,返回该字符串在字符串中的位置 |
| rfind? | 从字符串pos位置开始往前找字符C,返回该字符串在字符串中的位置 |
| substr | 在str中从pos位置开始,截取n个字符,然后将其返回 |
?接口的简单使用
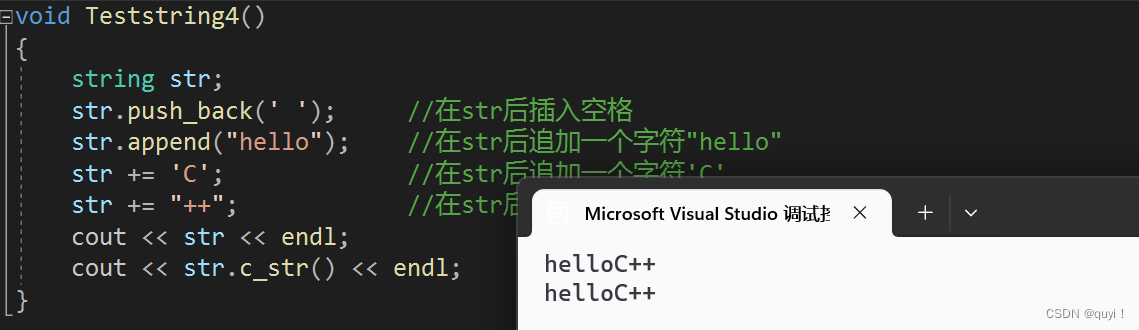
push_back 和?append? 还有operator+=以及c_str的简单使用void Teststring4() { string str; str.push_back(' '); //在str后插入空格 str.append("hello"); //在str后追加一个字符"hello" str += 'C'; //在str后追加一个字符'C' str += "++"; //在str后追加一个字符串'++' cout << str << endl; cout << str.c_str() << endl; }
运行结果:
 ?
?
?
?find + npos 和 rfind的简单使用
void Teststring5() { string s1("Test.cpp"); string s2("Test.tar.zip"); size_t pos1 = s1.find('.'); if (pos1 != string::npos) { //string suff = s1.substr(pos1, s1.size() - pos1);//是一种用法 string suff = s1.substr(pos1); cout << suff << endl; } size_t pos2 = s2.rfind('.'); if (pos2 != string::npos) { string suff = s2.substr(pos2); cout << suff << endl; } }?运行结果:
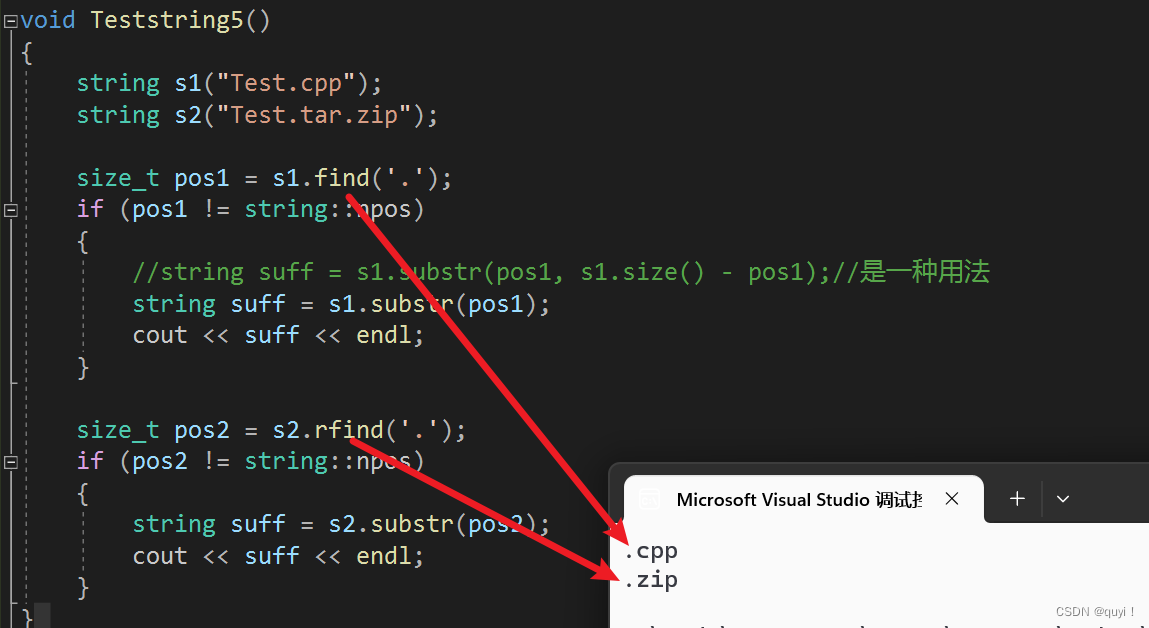
substr的简单使用
void Teststring6() { string str("https://legacy.cplusplus.com/reference/string/string/substr/"); string sub1, sub2, sub3; size_t pos1 = str.find(':'); sub1 = str.substr(0, pos1 - 0); cout << sub1 << endl; size_t pos2 = str.find('/', pos1 + 3); sub2 = str.substr(pos1 + 3, pos2 - (pos1 + 3)); cout << sub2 << endl; sub3 = str.substr(pos2 + 1); cout << sub3 << endl; }运行结果:
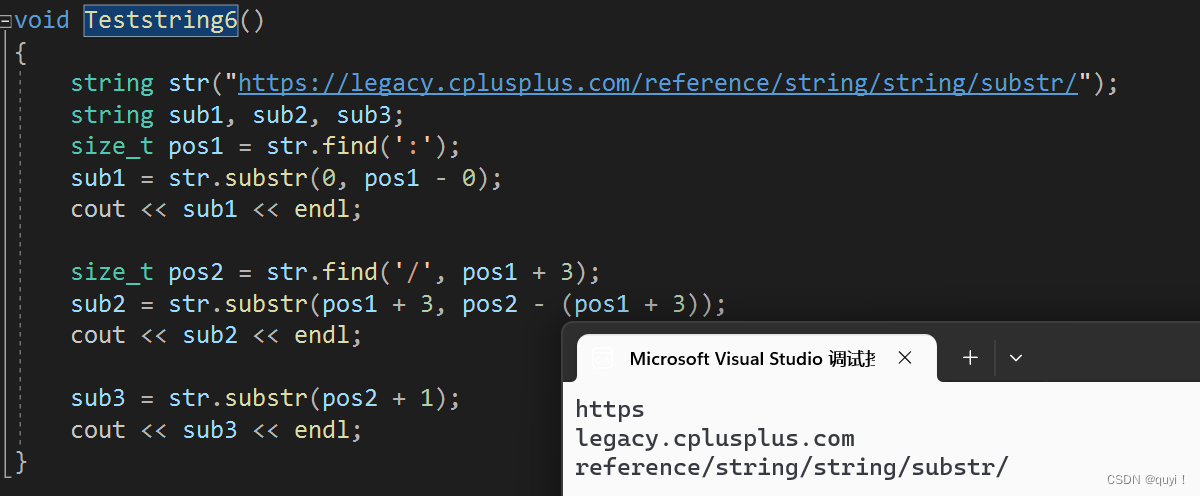
?
| 函数 | 功能说明 |
|---|---|
| operator+ | 尽量少用,因为传值返回,导致深拷贝效率低 |
| operator>>(重点) | 输入运算符重载 |
| operator<<(重点) | 输出运算符重载 |
| getline(重点) | 获取一行字符 |
| relational operator(重点) | 大小比较 |
?3.string的模拟实现
3.1经典的string类型问题
namespace quyi { class string { public: string(const char* str = "") { _size = strlen(str); _capacity = _size; _str = new char[_capacity + 1]; strcpy(_str, str); } ~string() { delete[] _str; _str = nullptr; _capacity = 0; _size = 0; } private: size_t _capacity; size_t _size; char* _str; }; void TestString() { string s1("hello C++"); string s2(s1); } }; int main() { quyi::TestString(); return 0; }运行时会报错为什么呢?
说明:上述String类没有显式定义其拷贝构造函数与赋值运算符重载,此时编译器会合成默认的,当用s1构造s2时,编译器会调用默认的拷贝构造。最终导致的问题是,s1、s2共用同一块内存空间,在释放时同一块空间被释放多次而引起程序崩溃,这种拷贝方式,称为浅拷贝。
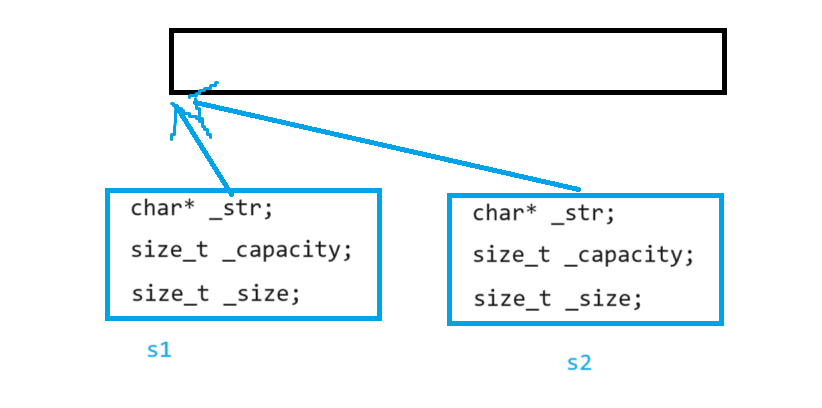
3.2浅拷贝
浅拷贝:也称位拷贝,编译器只是将对象中的值拷贝过来。如果对象中管理资源,最后就会导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该资源已经被释放,以为还有效,所以当继续对资源进项操作时,就会发生发生了访问违规。
就像是双胞胎,如果父母买了一个玩具,两个孩子都愿意一起玩,则万事大吉,万一不想分享就你争我抢,玩具损坏。
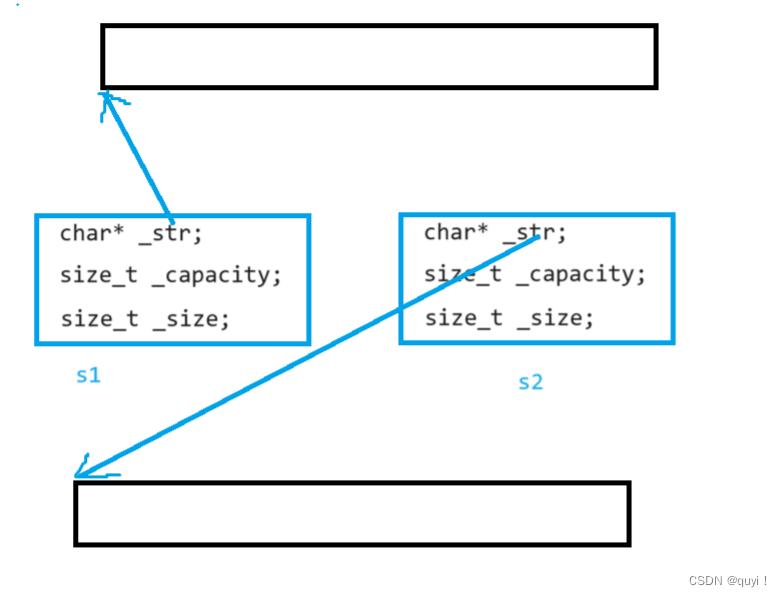
可以采用深拷贝的解决浅拷贝的问题,即:每个对象都有一份独立的资源,不要和其他对象共享。父母给每个孩子都买一份玩具,各自玩各自的就不会有问题了。
3.3深拷贝
如果一个类中涉及到资源的管理,其拷贝构造函数、赋值运算符重载以及析构函数必须要显式给出。一般情况都是按照深拷贝方式提供。
深拷贝:给每个对象独立分配资源,保证多个对象之间不会因共享资源而造成多次释放造成程序崩溃。
// s2(s1) //传统写法 string(const string& s) { _str = new char[s._capacity + 1]; strcpy(_str, s._str); _size = s._size; _capacity = s._capacity; }结论:_str指向常量字符串不能扩容修改,所以要new一个char,记得+1(字符长度要+1)给\0开的。都要strlen一下,开空间多开一个。
3.3.1传统版写法的string类
public:
string(const char* str = "")
{
_size = strlen(str);
_capacity = _size;
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// s2(s1)
//传统写法
string(const string& s)
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}
//s1 = s3
string& operator=(const string& s)
{
if (this != &s)
{
char* tmp = new char(_capacity + 1);
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
}
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
_capacity = 0;
_size = 0;
}
private:
size_t _capacity;
size_t _size;
char* _str;3.3.1现代版写法的string类
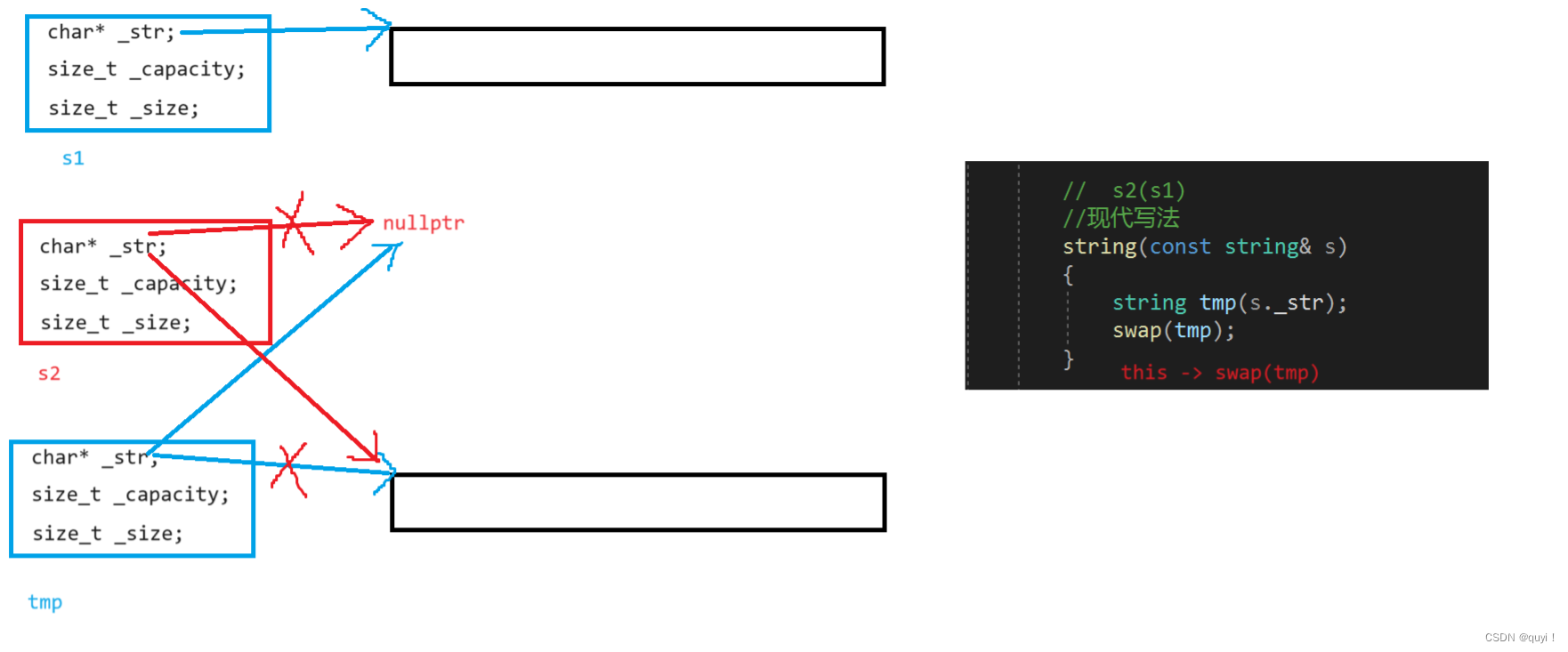
public: string(const char* str = "") { _size = strlen(str); _capacity = _size; _str = new char[_capacity + 1]; strcpy(_str, str); } // s2(s1) //现代写法 string(const string& s) { string tmp(s._str); swap(tmp); } //s1 = s3 string& operator=(string s) { swap(s); return *this; } ~string() { delete[] _str; _str = nullptr; _capacity = 0; _size = 0; } void swap(string& s) { std::swap(_str, s._str); std::swap(_size, s._size); std::swap(_capacity, s._capacity); } private: size_t _capacity = 0; size_t _size = 0; char* _str = nullptr; };现代拷贝(两头吃)
1.老乡叫做tmp,s就是s1
2.先构造,之后交换。
3.思路是什么?tmp(老乡去干活)和s1一样的空间一样的值,让后和s2交换一下。如果s2指向nullptr还好说如果出了作用域要调用析构一下,private中缺省值都给上(初始化列表也可以)
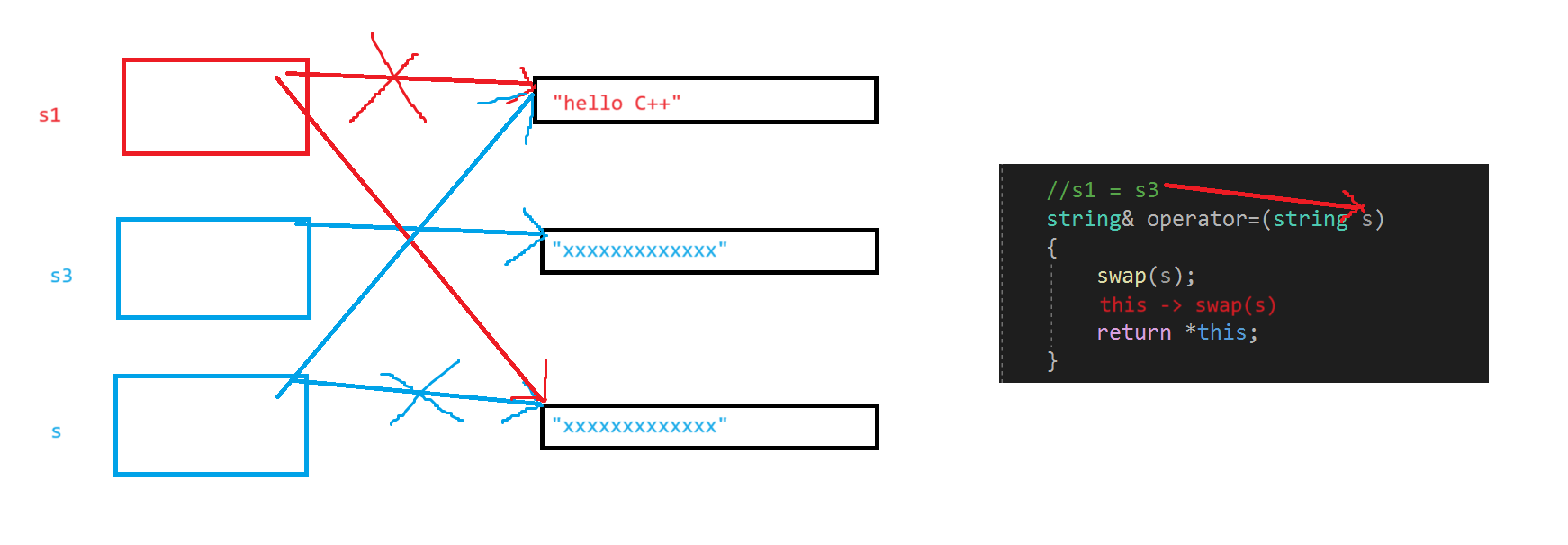
赋值的现代写法:
1.参数是传值,传参会复用拷贝构造。this是s1,s是s3的拷贝,s1和s进行交换
2.s1原来的空间还要释放,谁释放的?s会释放这段空间,s出了作用域会调用析构函数,s1原来的空间就会被销毁
3.参数中只给引用为什么编不过?临时对象具有常性,给引用尽量给const,涉及权限放大
3.4浅尝写时拷贝
写时拷贝就是一种拖延症,是在浅拷贝的基础之上增加了引用计数的方式来实现的。
引用计数:用来记录资源使用者的个数。在构造时,将资源的计数给成1,每增加一个对象使用该资源,就给计数增加1,当某个对象被销毁时,先给该计数减1,然后再检查是否需要释放资源,如果计数为1,说明该对象时资源的最后一个使用者,将该资源释放;否则就不能释放,因为还有其他对象在使用该资源。
意义:意义:有时候拷贝后不会写,就赚了。 就在博弈赌它不拷贝。

到这了就结束了,给出的代码都是重要的代码,所以main函数就没有写了,主要是理解重点?他所包含的意思。记不完的,根本记不完,重点放在理解,理解到位了手搓一个不是简简单单。写这篇博客的初衷也是怕自己在将来记不清某个知识点的时候希望可以再一次点开这篇博客再次唤醒“前世”记忆。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python:解决with打开文件错误UnicodeDecodeError
- element-plus日期选择器英文改成中文
- 分享66个NodeJs项目源码总有一个是你想要的
- vue使用ElementUI搭建精美页面入门
- 互联网加竞赛 基于机器视觉的行人口罩佩戴检测
- Linkage Mapper 工具参数详解——Climate Linkage Mapper
- 浙江科聪完成A轮近亿元融资:持续领跑移动机器人控制系统市场
- 基于SPI的插件式开发实现方案之@AutoService+ServiceLoader介绍及Dolphinscheduler中的实际应用
- OpenTiny 2023年度共建者榜单大曝光!!!
- 关于超大目录数据异常增长的问题排查