Control-oriented meta-learning
- 系统辨识:
- 在对输入和输出观测的基础上,从一组给定的模型中,确定一个与所测系统等价的模型——Zadeh
- 系统辨识是数据、模型类和准则三个要素的一个集合,输入输出数据是作为辨识的必要条件,评价准则是辨识所依靠的依据,模型类决定了辨识的范围,因此系统辨识即是按照一定的评价准则在选定的模型类中找到一个与输入输出数据拟合得最好的模型——1978 Ljung

系统辨识的效果受到几个因素制约:待辨识 对象的动态特性;选取的模型结构和参数化方式;系 统辨识的实验条件等


- 非线性系统Nonlinear System:输出的变化与输入的变化不成比例的系统
- 在线学习/离线学习
- 数据驱动 : ,规避建模的复杂过程,利用系统的输入输出数据等信息来直接设计控制器
- 面向控制的辨识是指以控制器设计作为系统辨识的目 的,以控制性能的优劣作为评价辨识模型优劣的标准,而进 行的系统模型建立的过程
- 如果一个控制器能够镇定不确定模型集合中所有的模型,那么这个控制器就通过稳定性验证 —— 以模型集来代替一个确定的模型用于控制设计能够满足鲁棒性的要求,这个模型集就称为不确定模型集
- 鲁棒辨识:鲁棒辨识是指从系统的输人输出数据及一定的先验信息得到体现系统不确定性的模型集估计
- 迭代辨识:通过重复的控制器设计来改善闭环控制性能
- 迭代辨识的发展主要有三个原因,第一是计算原因,真实模型对象未知,单纯的优化方法对该问题的处理往往使用高阶模型近似,这可能导致计算复杂度问题;第二个原因是对于闭环系统而言,一个更为有效的控制器所控制的系统,在此条件下进行的辨识实验所得到的模型,能够用于改善控制器的性能,设计更为理想的控制器,因此如果迭代过程实现了这个目的,则迭代方法是好的;第三,鲁棒辨识过程往往是离线的,这与辨识与控制一体化还有很长的距离,通过迭代过程可以在线调整辨识结果,控制器也可根据辨识结果进行间歇地调整,从而有助于整合辨识与控制过程,实现面向控制的目的
- 迭代辨识的缺点:不能保证收敛性
Abstract
背景: 对于在复杂动态环境中运行的机器人,实时自适应控制 (real-time adaptation)是必不可少的
问题:
- 理论上,假定任何不确定的动力学项(dynamics terms)都是已知非线性特征(konown nonlinear features)的线性参数,那么自适应控制规律(adaptive control laws)可以赋予非线性系统良好的轨迹跟踪性能(trajectory performance)
- 实际上,很难预先指定这些特征
想法:
- 使用神经网络进行数据驱动(data-driven)建模,从过去的数据中 离线(offline)学习具有这些非线性特征的内部参数模型的自适应控制器 (adaptive controller)
- 关键见解:在闭环仿真(closed-loop simulation)中对特征进行面向控制(control-oriented)的元学习,而不是对特征进行回归的元学习(regression-oriented)以拟合输入输出数据,从而更好地为控制器的部署做好准备
- 具体想法 : 以闭环跟踪仿真(closed-loop tracking simulation)为 b a s e ? l e a r n e r base-learner base?learner,以平均跟踪误差(average tracking error)为元目标 m e t a ? o b j e c t i v e meta-objective meta?objective,对自适应控制器进行元学习
1 Introduction
机器人的性能控制(performat control)受到由机器人本身(即其非线性运动方程)及其与环境的相互作用组成的 动力学系统(dynamical system)的复杂性 的阻碍
以往做法1:
- 机器人专家(Roboticists)通常可以先 推导出一个基于物理的机器人模型(physics-based robot model)
- 然后从一组非线性控制律(nonlinear)中进行选择 —— 每个非线性控制律在已知的简单环境中都能提供理想的控制理论特性(control-theoretic properties)(例如,良好的跟踪性能)
以往做法2:
- 面对模型的不确定性(无法推导出?),只要不确定性以
已知的结构化方式进入系统,非线性控制仍然可以通过在线测量(online measurements)的实时自适应(real-time adaptation)产生这种控制理论特性
现在问题: 当机器人部署在复杂场景(complex scenarios)中时,通常很难知道机器人可能经历的所有可能配置和交互(configurations and interactions)的结构
现在解决方式: 基于系统辨识(system identification)和数据驱动(data driven)的控制试图从过去的测量(measurements)中学习一个准确的输入输出模型(input-output model)
- 近年来,机器学习用于控制的研究也急剧增加——通过利用强大的近似结构(powerful approximateion architectures)来预测和优化动态系统的行为(估计误差,假设空间)
但是机器学习的方式存在问题:
- 这些丰富的模型(models)需要
大量的数据和计算来反向传播多层参数的梯度,因此通常不能用于快速非线性控制回路 - 作用在动力系统模型的机器学习通常优先拟合输入输出数据,即它是面向回归 (regression-oriented)的,其基本原理是为高度精确的模型设计控制器,在实际系统上产生更好的闭环性能。然而,几十年的系统辨识和自适应控制工作认识到这一点,由于学习模型通常是为了控制,因此学习过程本身应该针对下游控制目标进行 (downstream control objective)调整。这种
控制导向(control-oriented)学习的概念在自适应控制理论的基本结果中得到了证明:在不使参数估计收敛于真实系统的情况下,可以保证跟踪收敛 —— 不拟合当前数据,能够更好适应各个控制任务?
1.1 Contributions
- 认识到面向回归学习和面向控制学习之间的区别,并提出了一种面向控制的方法来学习参数自适应控制器 (parametric adaptive controller),该控制器在测试时在闭环中表现良好
- 提出的方法侧重于从过去的轨迹数据中离线学习 (offline learning)
- 将训练自适应控制器形式化为半监督的双层元学习 (semi-supervised , bi-level meta-learning)问题 —— 以所选目标轨迹的平均综合跟踪误差(average integrated tracking error)作为元目标(meta-objective),以自适应控制器作为基础学习器(base-learnner),进行闭环模拟训练
- 讨论了方法是可以应用于广泛动态系统 (general dynamical systems)的自适应控制器,可以将其专门用于不同类型的非线性系统(specialize it to different classes of nonlinear systems)—— 可以抵御复杂环境,具有泛化性
- 通过实验表明,通过将下游控制目标注入自适应控制器的离线元学习,在存在广泛变化的干扰的情况下,提高了测试时的闭环轨迹跟踪性能
2 Related Work
2.1 Control-Oriented System Identification
- 学习用于闭环控制(closed-loop)的系统模型(system model)是线性系统辨识(linear system identification)的一个标志(halmark)
- 在非线性系统辨识中,有一个新兴的文献主体是关于动态系统的数据驱动、约束学习(data-driven、constrained learning),鼓励学习后的模型和控制器在闭环中表现良好
当前的工作是关注学习到一个固定的模型-控制器对,相反,通过离线元学习,我们训练了一个自适应控制器,它可以在线更新其内部动态表示
2.2 Adaptive Control
- 从广义上讲,自适应控制涉及参数控制器与自适应律配对,该律规定了参数如何在线调整以响应动力系统中的信号
- 非线性系统的稳定自适应控制通常依赖于具有已知 非线性基函数(即特征) 的线性参数化动力学,以及当参数准确已知时,通过控制输入稳定地消除这些非线性的能力
- 当这些特征不能先验地导出时,可以使用神经网络、高斯过程和随机傅里叶特征等函数逼近器(function approximators),并在自适应控制回路中在线更新
然而,具有复杂函数逼近器的快速闭环自适应控制受到训练它们所需的计算工作量的阻碍;控制器增益调优的实际需求加剧了这个问题。在我们的论文中,我们专注于神经网络特征的离线元训练和从收集的数据中获得的控制器增益,控制器结构可以在快速闭环中运行
2.3 Meta-Learning
- 一般来说,用于解决特定任务的算法是基础学习器,而用于优化元目标的算法是元学习器【过程】
- 当试图让一个动力系统跟踪几个目标轨迹时,每个轨迹都与一个“任务”相关联,自适应跟踪控制器是基础学习器,所有这些轨迹的平均跟踪误差是我们想要最小化的元目标
- 许多工作尝试离线元学习动态模型,该模型可以最适合在特定任务期间收集的新输入-输出数据。也就是说,基学习器和元学习器是面向回归的
我们通过离线闭环模拟反向传播梯度的方式训练自适应控制器,以实现在线快速实现
3 Problem Statement
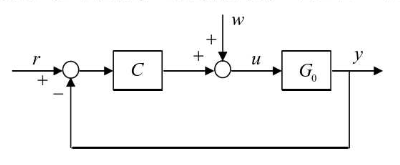
本文主要研究连续时间非线性动力系统(continuous-time,nonlinear dynamical system)的控制问题
自适应控制中的学习是在“需要知道”的基础上完成的,在闭环中消除扰动,而不是开环中估计未知参数
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 科研学习|论文解读——超准确性反馈:使用眼动追踪来检测阅读过程中的可理解性和兴趣
- unity—UGUI 点击按钮后,持续点击空格键会持续出发按钮
- 全网最低价——组合预测模型全家桶
- 如何使用 Ray 开发万能面板(万字 全流程 手把手教学)
- conda环境下FutureWarning: Pass sr=16000, n_fft=800 as keyword args问题解决
- Camtasia2024中文绿色版本下载安装详细步骤教程
- 连接服务器出现内部错误的原因与解决方案
- 算法训练营Day45(完全背包)
- 轻松搭建:用 Docker 快速配置强大的 MinIO 存储
- mysql无法连接问题及其环境变量配置