强化学习6——动态规划置策略迭代算法,以悬崖漫步环境为例
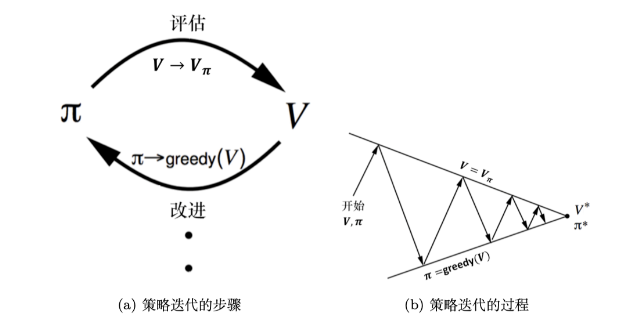
策略迭代算法
通过策略评估与策略提升不断循环交替,得到最优策略。
策略评估
固定策略 π \pi π 不变,估计状态价值函数V
一个策略的状态价值函数,在马尔可夫决策过程中提到过:
V
π
(
s
)
=
∑
a
∈
A
π
(
a
∣
s
)
(
r
(
s
,
a
)
+
γ
∑
s
′
∈
S
p
(
s
′
∣
s
,
a
)
V
π
(
s
′
)
)
V^{\pi}(s)=\sum_{a\in A}\pi(a|s)\left(r(s,a)+\gamma\sum_{s'\in S}p(s'|s,a)V^{\pi}(s')\right)
Vπ(s)=a∈A∑?π(a∣s)(r(s,a)+γs′∈S∑?p(s′∣s,a)Vπ(s′))
π
(
a
∣
s
)
\pi(a|s)
π(a∣s) 是在状态
s
s
s 下采取动作
a
a
a 的概率。在知道奖励函数和状态转移函数后,可以用下一个状态的价值来计算当前状态的价值,更一般的,考虑所有的状态,就变成了用上一轮的状态价值函数来计算当前这一轮的状态价值函数。
V
k
+
1
(
s
)
=
∑
a
∈
A
π
(
a
∣
s
)
(
r
(
s
,
a
)
+
γ
∑
s
′
∈
S
P
(
s
′
∣
s
,
a
)
V
k
(
s
′
)
)
V^{k+1}(s)=\sum_{a\in A}\pi(a|s)\left(r(s,a)+\gamma\sum_{s'\in S}P(s'|s,a)V^k(s')\right)
Vk+1(s)=a∈A∑?π(a∣s)(r(s,a)+γs′∈S∑?P(s′∣s,a)Vk(s′))
可以选取初始值
V
0
V^0
V0 ,当
V
k
=
V
π
V^k=V^\pi
Vk=Vπ 时,停止更新,若
k
→
∞
k\to \infty
k→∞ ,
V
k
V^k
Vk 会收敛到
V
π
V^{\pi}
Vπ ,若
max
?
s
∈
S
∣
V
k
+
1
(
s
)
?
V
k
(
s
)
∣
\max_{s\in\mathcal{S}}|V^{k+1}(s)-V^{k}(s)|
maxs∈S?∣Vk+1(s)?Vk(s)∣ 非常小,则也可以认为完成收敛。
策略提升
根据估计好的状态价值函数V结合策略推算出动作价值函数Q,并对?Q?函数优化然后进一步改进策略
假设确定存在一个确定性策略
π
′
\pi '
π′ ,在任意一个状态下,都满足:
Q
π
(
s
,
π
′
(
s
)
)
≥
V
π
(
s
)
Q^{\pi}(s,\pi'(s))\geq V^{\pi}(s)
Qπ(s,π′(s))≥Vπ(s)
V
π
(
s
)
≤
Q
π
(
s
,
π
′
(
s
)
)
=
E
π
′
[
R
t
+
γ
V
π
(
S
t
+
1
)
∣
S
t
=
s
]
≤
E
π
′
[
R
t
+
γ
Q
π
(
S
t
+
1
,
π
′
(
S
t
+
1
)
)
∣
S
t
=
s
]
=
E
π
′
[
R
t
+
γ
R
t
+
1
+
γ
2
V
π
(
S
t
+
2
)
∣
S
t
=
s
]
≤
E
π
′
[
R
t
+
γ
R
t
+
1
+
γ
2
R
t
+
2
+
γ
3
V
π
(
S
t
+
3
)
∣
S
t
=
s
]
≤
E
π
′
[
R
t
+
γ
R
t
+
1
+
γ
2
R
t
+
2
+
γ
3
R
t
+
3
+
?
∣
S
t
=
s
]
=
V
π
′
(
s
)
\begin{aligned} V^{\pi}(s)& \leq Q^{\pi}(s,\pi^{\prime}(s)) \\ &=\mathbb{E}_{\pi^{\prime}}[R_t+\gamma V^{\pi}(S_{t+1})|S_t=s] \\ &\leq\mathbb{E}_{\pi^{\prime}}[R_t+\gamma Q^{\pi}(S_{t+1},\pi^{\prime}(S_{t+1}))|S_t=s] \\ &=\mathbb{E}_{\pi^{\prime}}[R_t+\gamma R_{t+1}+\gamma^2V^\pi(S_{t+2})|S_t=s] \\ &\leq\mathbb{E}_{\pi^{\prime}}[R_t+\gamma R_{t+1}+\gamma^2R_{t+2}+\gamma^3V^\pi(S_{t+3})|S_t=s] \\ &\leq\mathbb{E}_{\pi^{\prime}}[R_t+\gamma R_{t+1}+\gamma^2R_{t+2}+\gamma^3R_{t+3}+\cdots|S_t=s] \\ &=V^{\pi^{\prime}}(s) \end{aligned}
Vπ(s)?≤Qπ(s,π′(s))=Eπ′?[Rt?+γVπ(St+1?)∣St?=s]≤Eπ′?[Rt?+γQπ(St+1?,π′(St+1?))∣St?=s]=Eπ′?[Rt?+γRt+1?+γ2Vπ(St+2?)∣St?=s]≤Eπ′?[Rt?+γRt+1?+γ2Rt+2?+γ3Vπ(St+3?)∣St?=s]≤Eπ′?[Rt?+γRt+1?+γ2Rt+2?+γ3Rt+3?+?∣St?=s]=Vπ′(s)?
通过选取动作从而得到新的策略的过程称为策略提升,当
π
′
\pi '
π′ 与
π
\pi
π 一样好时,可以证明策略迭代达到了收敛:
π
′
(
s
)
=
arg
?
max
?
a
Q
π
(
s
,
a
)
=
arg
?
max
?
a
{
r
(
s
,
a
)
+
γ
∑
s
′
P
(
s
′
∣
s
,
a
)
V
π
(
s
′
)
}
\pi'(s)=\arg\max_aQ^\pi(s,a)=\arg\max_a\{r(s,a)+\gamma\sum_{s'}P(s'|s,a)V^\pi(s')\}
π′(s)=argamax?Qπ(s,a)=argamax?{r(s,a)+γs′∑?P(s′∣s,a)Vπ(s′)}
策略迭代算法的实现
- 随机初始化策略 π ( s ) \pi(s) π(s)与价值函数 V ( s ) V(s) V(s)
- while
Δ
>
θ
\Delta >\theta
Δ>θ do:(状态评估)
- Δ ← 0 \Delta \gets 0 Δ←0
- 对于每个状态
s
∈
S
s \in S
s∈S :
- v ← V ( S ) v \gets V(S) v←V(S)
- V ( s ) ← r ( s , π ( s ) ) + γ ∑ s ′ P ( s ′ ∣ s , π ( s ) ) V ( s ′ ) V(s)\leftarrow r(s,\pi(s))+\gamma\sum_{s'}P(s'|s,\pi(s))V(s') V(s)←r(s,π(s))+γ∑s′?P(s′∣s,π(s))V(s′)
- Δ ← m a x ( Δ , ∣ v ? V ( s ) ∣ ) \Delta \gets max(\Delta,|v*V(s)|) Δ←max(Δ,∣v?V(s)∣)
- end while
- π o l d ← π \pi_{old} \gets \pi πold?←π
- 对于每个状态
s
∈
S
s \in S
s∈S:
- π ( s ) ← arg ? max ? a r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) V ( s ′ ) \pi(s)\leftarrow\arg\max_ar(s,a)+\gamma\sum_{s^{\prime}}P(s^{\prime}|s,a)V(s^{\prime}) π(s)←argmaxa?r(s,a)+γ∑s′?P(s′∣s,a)V(s′)
- 如果 π o l d = π \pi_{old}=\pi πold?=π,则停止算法并返回V和 π \pi π ,否则转到策略评估循环
class PolicyIteration:
def __init__(self,env,theta,gamma):
self.env=env
# 初始化价值为0
self.v=[0]*self.env.ncol*self.env.nrow
# 初始化为均匀随机策略
self.pi=[[0.25,0.25,0.25,0.25] for i in range(self.env.ncol*self.env.nrow)]
self.theta=theta # 策略评估收敛阈值
self.gamma=gamma # 折扣因子
# 策略评估
def policyEvaluation(self):
cnt =1 #计数
while 1:
maxDiff=0
newV=[0] * self.env.ncol * self.env.nrow
for s in range(self.env.ncol*self.env.nrow):
#计算每一个状态s下所有Q(s,a)之和的价值
qsaList=[]
# 有四个动作
for a in range(4):
qsa=0
for transition in self.env.P[s][a]:
p,nextState,r,done=transition
qsa+=p*(r+self.gamma*self.v[nextState]*(1-done))
# 策略*Q(s,a)=对应的价值
# 本章环境比较特殊,奖励和下一个状态有关,所以需要和状态转移概率相乘
qsaList.append(self.pi[s][a]*qsa)
# 求和后得到状态s的状态价值
newV[s]=sum(qsaList)
maxDiff=max(maxDiff,abs(newV[s]-self.v[s]))
self.v=newV
#满足收敛条件,退出评估迭代
if maxDiff<self.theta:
break
cnt +=1
print(f'policyEvaluation 次数为{cnt}')
def policyImprovement(self):
# 策略提升
for s in range(self.env.ncol*self.env.nrow):
qsaList=[]
for a in range(4):
qsa=0
for transition in self.env.P[s][a]:
p,nextState,r,done=transition
qsa+=p*(r+self.gamma*self.v[nextState]*(1-done))
# 策略*Q(s,a)=对应的价值
qsaList.append(qsa)
maxq=max(qsaList)
cntq=qsaList.count(maxq)# 计算有几个动作得到了最大的Q值
self.pi[s]=[1/cntq if q==maxq else 0 for q in qsaList]
print('policyImprovement')
return self.pi
def policyIteration(self):
# 策略迭代
while 1:
self.policyEvaluation()
oldPi=copy.deepcopy(self.pi)
newPi=self.policyImprovement()
if oldPi==newPi:
break
为了更好地展现最终的策略,接下来增加一个打印策略的函数,用于打印当前策略在每个状态下的价值以及智能体会采取的动作。对于打印出来的动作,我们用^o<o表示等概率采取向左和向上两种动作,ooo>表示在当前状态只采取向右动作。
def print_agent(agent, action_meaning, disaster=[], end=[]):
print("状态价值:")
for i in range(agent.env.nrow):
for j in range(agent.env.ncol):
# 为了输出美观,保持输出6个字符
print('%6.6s' % ('%.3f' % agent.v[i * agent.env.ncol + j]), end=' ')
print()
print("策略:")
for i in range(agent.env.nrow):
for j in range(agent.env.ncol):
# 一些特殊的状态,例如悬崖漫步中的悬崖
if (i * agent.env.ncol + j) in disaster:
print('****', end=' ')
elif (i * agent.env.ncol + j) in end: # 目标状态
print('EEEE', end=' ')
else:
a = agent.pi[i * agent.env.ncol + j]
pi_str = ''
for k in range(len(action_meaning)):
pi_str += action_meaning[k] if a[k] > 0 else 'o'
print(pi_str, end=' ')
print()
env = CliffWalkingEnv()
action_meaning = ['^', 'v', '<', '>']
theta = 0.001
gamma = 0.9
agent = PolicyIteration(env, theta, gamma)
agent.policy_iteration()
print_agent(agent, action_meaning, list(range(37, 47)), [47])
策略评估进行51轮后完成
policyImprovement
策略评估进行78轮后完成
policyImprovement
策略评估进行39轮后完成
policyImprovement
策略评估进行11轮后完成
policyImprovement
策略评估进行1轮后完成
policyImprovement
状态价值:
-7.458 -7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710 -1.900
-7.176 -6.862 -6.513 -6.126 -5.695 -5.217 -4.686 -4.095 -3.439 -2.710 -1.900 -1.000
-7.458 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
策略:
ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovo> ovoo
ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ooo> ovoo
^ooo ^v<> ^v<> ^v<> ^v<> ^v<> ^v<> ^v<> ^v<> ^v<> ^v<> ^v<>
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 再见2023,你好2024!
- SpringBoot的启动器——spring-boot-starter介绍和常见启动器说明
- 搜索引擎优化终极指南
- 函数式编程的Java编码实践:利用惰性写出高性能且抽象的代码
- html/css实现简易圣诞贺卡
- 二分查找(二)
- 排序:计数排序
- react native项目从创建到运行,以及一些常用命令和可能出现的问题
- stm32 pwm输出
- 如何解决错误代码0xc0000428,这里提供几种方法