redis的那些事(二)——布隆过滤器
发布时间:2023年12月25日
什么是布隆过滤器?
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
布隆过滤器实现原理
布隆过滤器是一个bit向量或者说是一个bit数组(下面的数字为索引)。如下所示:

- 其最小单位为bit,初始化时全部置为0添加元素;
- 更新元素,利用K个Hash函数,将元素传入这K个Hash函数得到k个数字对应bit向量数组的K个下标,然后将这K个下标对应位置的值置为1。
- 查询元素:利用K个Hash函数,将元素传入这K个Hash函数得到k个数字对应bit向量数组的K个下标,如果这些下标对应的位置中有任何一个值为0,则被检测的元素一定不存在;如果这些位置的值都为1,则被检测的元素很可能(因为布隆过滤器存在误差)存在,但是不一定百分百存在。
- 删除元素:布隆过滤器不支持删除元素。如果我们因为某一个元素而将其对应的bit位的值变为0,那么如果这些bit位也是其他元素正在使用的,那么其他元素在查询时就会返回0,从而认为元素不存在而造成误判
举个例子
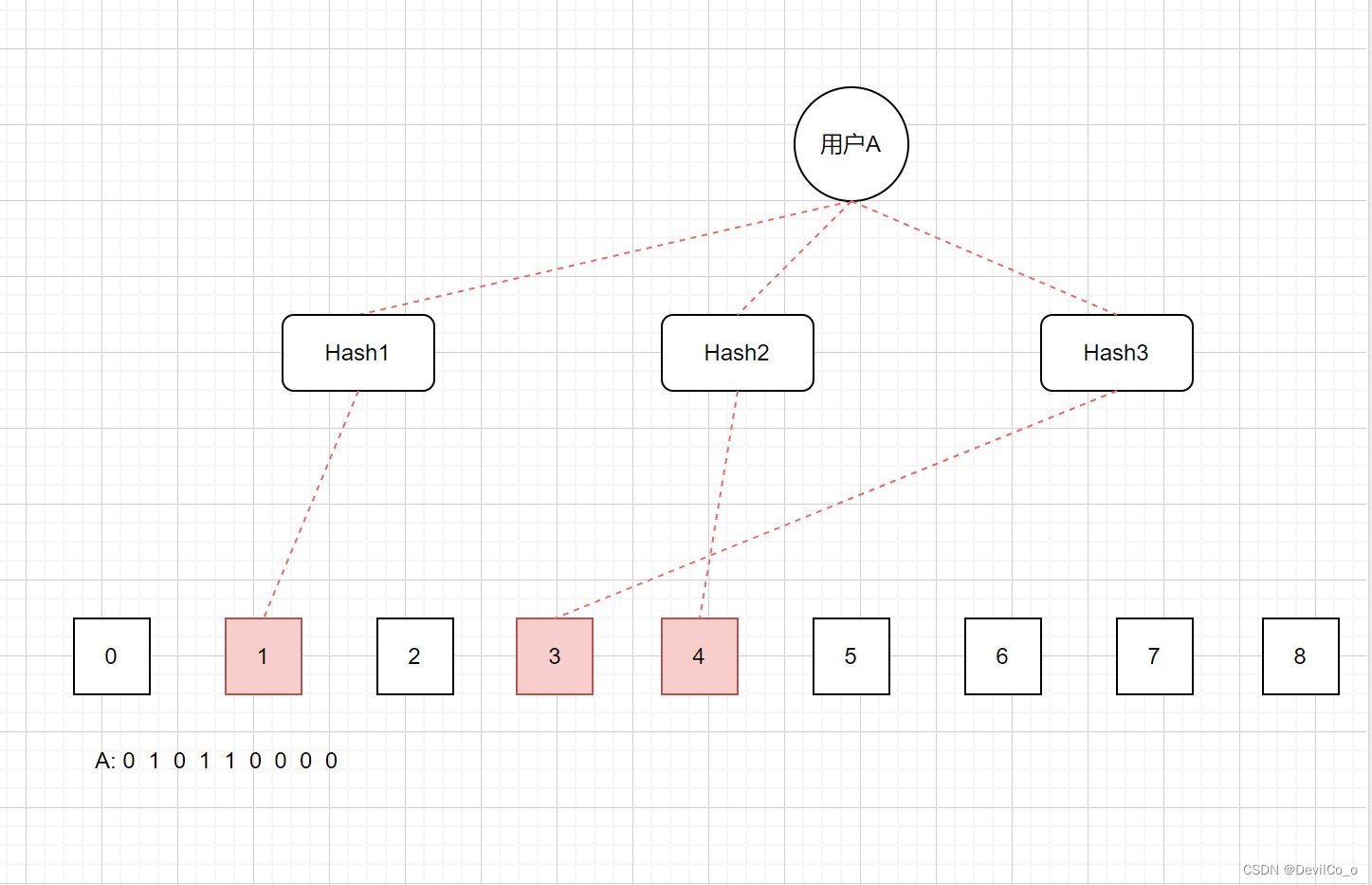
如何降低误判率?
使用多个Hash函数。
hash函数越多,误判的概率就越小。
但是,同时占用的空间也会越大,查询和插入操作的耗时也会更长,一般hash函数为3-5个。
常见的应用比较广的hash函数有MD5, SHA1, SHA256等。
布隆过滤器用在哪里?
优点
- 布隆过滤器可以高效地进行查询,用来告诉你“某样东西一定不存在或者可能存在”。
- 相比于传统的List、Set、Map等数据结构,它占用空间更少;3.
- 更新时更高效,布隆过滤器是位操作,而集合类型结构是操作对象。
缺点
- 其返回的结果判断存在的时候是存在误差的,判断不存在才是准确的;
- 不能提供删除操作;
文章来源:https://blog.csdn.net/weixin_42440637/article/details/135188490
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- TCP四次挥手
- nodejs+vue+微信小程序+python+PHP国漫推荐系统-计算机毕业设计推荐
- SpringBoot 更新业务场景下,如何区分null是清空属性值 还是null为vo属性默认值?
- 植物神经功能紊乱到底是什么疾病?今天来告诉你原因和治疗方法!
- 苹果电脑RAW图像处理软件Capture One Pro 22 mac软件介绍
- 数据结构:二叉树
- 小程序怎么开发自己的小程序?
- LeetCode刷题--- 第 N 个泰波那契数
- Python3,压箱底的代码片段,提升工作效率稳稳的。
- [算法与数据结构][c++][python]:C++与Python中的赋值、浅拷贝与深拷贝