机器学习——中文分词
【说明】文章内容来自《机器学习——基于sklearn》,用于学习记录。若有争议联系删除。
1、简介
????????中文分词是指将汉字序列按照一定规则逐个切分为词序列的过程。在英文中,单词间以空格为自然分隔符,分词时自然以空格为单位进行切分,而中文分词则需要依靠技术和方法寻找类似英文中空格作用的分隔符。
示例:
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
data = cv.fit_transform(['我来到济南山东大学'])
print('单词数:{}'.format(len(cv.vocabulary_)))
print('分词:{}'.format(cv.vocabulary_))
print(cv.get_feature_names_out())
print(data.toarray())【运行结果】

【结果分析】
????????程序无法对中文句子进行分词,将整个句子当成了一个词。中文与英文不同,英文的单词之间有空格作为天然的分隔符,而中文却没有。因此,“我来到济南山东大学”需要添加空格进行分隔,将文本内容变成“我? 来到? 济南? 山东大学”。
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
data = cv.fit_transform(['我 来到 济南 山东大学'])
print('单词数:{}'.format(len(cv.vocabulary_)))
print('分词:{}'.format(cv.vocabulary_))
print(cv.get_feature_names_out())
print(data.toarray())【运行结果】

2、jieba分词库
????????当文本内容很多,不可能采用空格进行分词,可以使用jieba分词库进行处理。
安装:
pip install jiebajieba分词库支持3中分词模式:
- 全模式(full mode):把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义问题。
- 精确模式(default mode):试图将句子最精确地切开,适用于文本分析。
- 搜索引擎模式(cut_for_search mode):在精确模式的基础上,对长词再次切分,提高召回率,适用于搜索引擎分词。
2.1 全模式
语法:
jieba.cut(str, cut_all=True)
示例:
import jieba
seg_list = jieba.cut('我来到济南山东大学', cut_all = True)
print('full mode:'+'/'.join(seg_list))2.2 精确模式
语法:
jieba.cut(str, cut_all = False)示例:
import jieba
seg_list = jieba.cut('我来到济南山东大学', cut_all = False)
print('full mode:'+'/'.join(seg_list))2.3 搜索引擎模式
语法:
jieba.cut_for_search(str)示例:
import jieba
seg_list = jieba.cut_for_search('我来到济南山东大学')
print('full mode:'+'/'.join(seg_list))3、自定义词典
????????当分词结果不符合开发者的预期时,可以通过自定义的词典包含jieba词库里没有的词,从而提高分词正确率。自定义词典有如下两种方式。
3.1添加词典文件
????????添加词典文件,定义分词最小单位,文件要有特定格式,并且采用UTF-8编码。语法如下:
jieba.load_userdict(file_name)示例:
import jieba
seg_list = jieba.cut('许元铭老师是python技术讲师',cut_all = True)
print('/'.join(seg_list))【运行结果】
![]()
【结果分析】“许/元/铭”被分割为‘许’‘元’‘铭’,不符合开发者预期。添加自定义词典,在E盘根目录下,新建userdict.txt文件,另存为——选择UTF-8编码。内容遵循如下规则:
????????一个词占一行;每一行分为3部分,分别为词语、词频(可省略)和词性(可省略),用空格隔开。顺序不可颠倒。如“许元铭 3 n”。
示例:
import jieba
jieba.load_userdict('E:\\userdict.txt')
seg_list = jieba.cut('许元铭老师是python技术讲师',cut_all = True)
print('/'.join(seg_list))【运行结果】
![]()
3.2 动态修改词频
????????调节单个词语的词频,使其能(或者不能)被分出来。语法如下:
jieba.suggest_freq(segment, tune = True)示例:
import jieba
jieba.suggest_freq('许元铭', tune= True)
seg_list1 = jieba.cut('许元铭老师是python技术讲师',cut_all = True)
print('/'.join(seg_list1))【运行结果】
![]()
4、词性标注
????????每个词语都有词性,如“许元铭”是n(名词),“是”是v(动词),等等。词性标注命令如下:
jieba.posseg.cut()示例:
import jieba.posseg as pseg
words = pseg.cut('许元铭老师是python技术讲师')
for word,flag in words:
print('%s %s' % (word, flag))【运行结果】

5、断词位置
????????断词位置用于返回每个分词的起始和终止位置,语法如下:
jieba.Tokenizer()示例:
import jieba
result = jieba.tokenize('许元铭老师是python技术讲师')
print('默认模式为:')
for tk in result:
print('word %s\t\t start: %d \t\t end: %d'%(tk[0],tk[1],tk[2]))【运行结果】

6、基于TF-IDF算法的关键词抽取
????????基于TF-IDF算法计算文本中词语的权重,命令如下:
jieba.analyse.extract_tags(line, topk = 20, withWeigt = False, allowPOS=())【参数说明】
- Lines:待提取的文本
- topk:返回TF/IDF权重最大的关键词个数,默认为20
- withWeight:是否一并返回关键词权重值,默认为False
- allowPOS :仅包括指定词性的词,默认为空,即不筛选。
示例:
import jieba.analyse as analyse
lines = '许元铭老师是python技术讲师'
keywords = analyse.extract_tags(lines,topK = 20, withWeight = True, allowPOS = ())
for item in keywords:
print('%s= %f '%(item[0],item[1]))【运行结果】

7、自定义IDF
????????jieba给每个分词标出IDF,如果希望某个关键词的权重突出(或降低),可以将IDF设定的高一些(或低一些)。jieba的IDF一般为9~12,自定为2~5。
????????创建自定IDF文件,在D盘根目录下创建idf.txt文件,内容遵守如下规则:
一个词占一行;每一行分为两个部分,分别是词和权重,用空格分开。顺序不可颠倒,文件采用UTF-8编码。
示例:
import jieba
import jieba.analyse as analyse
lines = '许元铭老师是python技术讲师'
print('default idf' + '-'*40)
keywords = analyse.extract_tags(lines, topK = 10, withWeight = True, allowPOS = ())
for item in keywords:
print('%s= %f'%(item[0],item[1]))
print('set_idf_path'+'-'*40)
jieba.analyse.set_idf_path('e:/idf.txt')
keywords = analyse.extract_tags(lines, topK = 10,withWeight = True,allowPOS = ())
#print('topK = TF/IDF, TF= %d'%len(keywords))
for item in keywords:
# print('s=%f'%(item[0].item[1]))
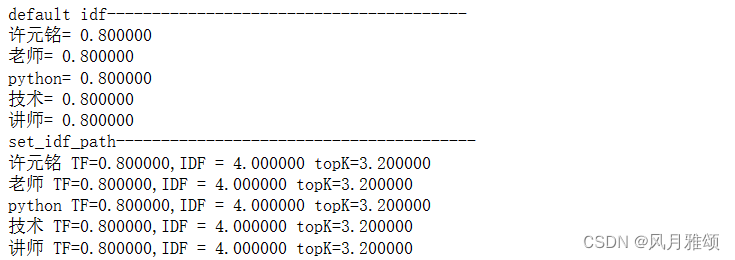
print('%s TF=%f,IDF = %f topK=%f\
'%(item[0],item[1],len(keywords) * item[1],item[1]*len(keywords)*item[1]))?【运行结果】
8、排列最常出现的分词
????????将每个分词当成Key,将其在文中出现的次数作为value,最后进行降序排序
示例:
import jieba
text = '许元铭老师是python技术讲师,许元铭老师是软件测试技术讲师'
dic = {}
for ele in jieba.cut(text):
if ele not in dic:
dic[ele] = 1
else:
dic[ele] = dic[ele] + 1
for w in sorted(dic,key = dic.get, reverse = True):
print('%s %i'%(w,dic[w]))【运行结果】

9、停用词表
????????停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为 Stop Words(停用词)。
这些停用词都是人工输入、非自动化生成的,生成后的停用词会形成一个停用词表。
文件链接:https://pan.baidu.com/s/1ojTmZnVJ-Ynoy0ZqfxRDUA?
提取码:p68r
示例:使用jieba分析刘欣慈小说《三体》中出现次数最多的词。《三体》保存在E:\\santi.txt中,采用UTF-8编码。
import jieba
txt = open('e:\\santi.txt',encoding= 'utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key = lambda x:x[1], reverse = True)
for i in range(30):
word, count = items[i]
print('{0:<10}{1:>5}'.format(word, count))【运行结果】

9.1 添加停用词表
文件链接:https://pan.baidu.com/s/14ZSKwv4PT5XC3QqQ1ynHBw?
提取码:gxyt
修改代码:
import jieba
txt = open('e:\\santi.txt',encoding = 'utf-8').read()
#加载停用词表
stopwords = [line.strip() for line in open('stopwords.txt',encoding = 'utf-8').\
readlines()]
words = jieba.lcut(txt)
counts = {}
for word in words:
#不在停用词表中
if word not in stopwords:
#不统计字数为1的词
if len(word)==1:
continue
else:
counts[word]=counts.get(word,0)+1
items = list(counts.items())
items.sort(key = lambda x:x[1],reverse= True)
for i in range(30):
word, count = items[i]
print('{:<10}{:>7}'.format(word,count))【运行结果】

9.2 引入jieba和停用词表,进行中文特征提取。
from sklearn.feature_extraction.text import CountVectorizer
import jieba
text = '今天天气真好,我要去西安大雁塔玩,玩完之后,游览兵马俑'
#进行jieba分词,精确模式
text_list = jieba.cut(text, cut_all=False)
text_list = ','.join(text_list)
context = []
context.append(text_list)
print(context)
con_vec = CountVectorizer(min_df = 1, stop_words = ['之后','玩完'])
X = con_vec.fit_transform(context)
feature_name = con_vec.get_feature_names_out()#类别名称
print(feature_name)
print(X.toarray())【运行结果】

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于SpringBoot的养老院管理系统
- APM链路监控: Linux 部署 pinpoint
- 是时候扔掉cmder, 换上Windows Terminal
- VUE随机洗牌,JS随机排序数组/洗牌函数
- Mybatis插件入门
- Page268~270 11.3.4 wxWidgets项目配置
- Linux进程
- 【51单片机系列】DS18B20温度传感器模块
- 优思学院|RTY直通率/流通合格率是什么意思?
- ThreeJs通过canvas和Sprite添加标签