布隆过滤器-使用原理和场景
一、概述
????布隆过滤器(Bloom Filter)主要用来检索一个元素是否在一个集合中。它是一种数据结构bitMap,优点是高效的插入和查询,而且非常节省空间。缺点是存在误判率和删除困难。
二、应用场景
????1、避免缓存穿透,当redis做缓存,没有命中会查询数据库,若量很大,流量打在数据库,会造成压力。若缓存空值避免穿透,量大需要缓存大量的key,若空值过期,造成不一致情况,故不推荐。另外一种用hashMap存储,但是key值量大,会占用内存飙升,也不建议。推荐使用 Bloom Filter,节省空间,也是当前主流做法
????2、判断用户是否是刷单用户,是否在黑名单池内。如1一亿 个垃圾 email ,5kw+黑名单池。存数据库耗空间,查询速度慢且高频查询。哈希表查询效率O(1),哈希表的做法:首先,哈希函数将一个email地址映射成8字节信息指纹;考虑到哈希表存储效率通常小于50%(哈希冲突);因此消耗的内存:8 * 2 * 1亿 字节 = 1.6G 内存。非常大,故布隆过滤器(Bloom Filter)就解决此类问题
????3、RocketMQ通过布隆过滤器防止消息重复消费:防止RocketMQ消息重复消费,我们发送消息时可以对每个消息设置唯一的key,然后在消费者处利用布隆过滤器对消息的key检索,如果存在则说明消息已经消费过,不消费。不存在则进行消费,然后插入布隆过滤器
二、布隆过滤器Bloom Filter原理和数据结构
数据结构:
????布隆过滤器是由很长的二进制向量(即可以理解成很长的0、1数组)与一系列随机映射函数(Hash函数)构成。BloomFilter 是由一个固定大小的二进制向量或者位图(bitmap)和一系列映射函数组成的。在初始状态时,对于长度为 m 的位数组,它的所有位都被置为0。因此我们可以将布隆过滤器理解成下图这种很长的一个二进制数组:
优点:布隆过滤器的数据结构仅需要存储“0”或“1”,因此所占用内存极少
检索和插入原理:
????1、Hash函数:把输入值通过特定方式(hash函数) 处理后 生成一个值,这个值等同于存放数据的地址
????2、插入(增加)数据的原理:Hash函数是 y=x2&(len-1),这里y是指最终在布隆过滤器的数据结构(二进制数组)中存放的下标位置,x指我们传入的值,len指数组的长度。那么如果当数组长度为100(举个例子,实际上数组长度是很长的),传入的值为5,则我们通过Hash函数得到的下标为25。那么此时我们便将下标25的值从0标为1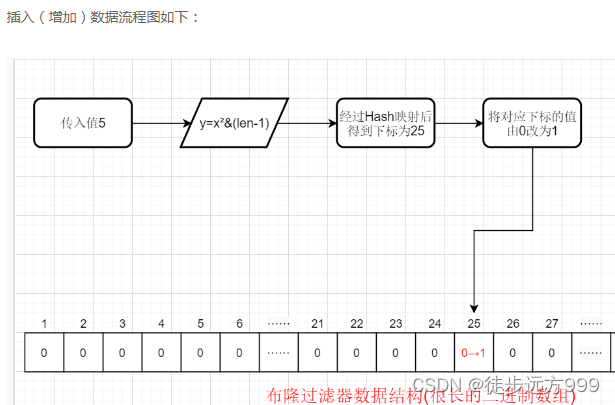
3、检索原理:当我们下次再输入这个值的时候,我们会得到当前数组对应下标的值为1,说明我们有这个数字
误判原理:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 线性渐变linear-gradient——线性渐变实现虚线斜线条纹
- springboot(ssm小区团购管理系统 社区团购平台系统 Java系统
- Pandoc:markdown转word
- 【绪论】数字通信和模拟通信,信息量,信道
- 基于振弦采集仪的地下建筑监测研究
- 扫地机器人(二分算法+贪心算法)
- 机器人电机综述 — 电机分类、舵机、步进与伺服、物理性质和伺服控制系统
- Spring boot - Task Execution and Scheduling & @Async
- 找不到msvcr100.dll怎么办?msvcr100.dll丢失的解决方法
- 广联达Linkworks GetAuthorizeKey.ashx 文件上传漏洞复现