数据结构期末复习(fengkao课堂)
学习数据结构时,以下建议可能对您有所帮助:
-
理解基本概念:首先,确保您理解数据结构的基本概念,例如数组、链表、栈、队列、树、图等。了解它们的定义、特点和基本操作。
-
学习时间复杂度和空间复杂度:了解如何分析算法的时间复杂度和空间复杂度,这有助于评估不同数据结构和算法的效率。
-
实践编码:通过编写代码来实现各种数据结构。尝试使用不同的编程语言来实现它们,并亲自编写插入、删除、搜索等操作。
-
比较和选择:比较不同的数据结构,了解它们的优缺点以及适用场景。例如,数组适用于快速访问元素,而链表适用于频繁插入和删除操作。
-
解决问题:尝试使用不同的数据结构来解决实际问题。练习使用栈求解括号匹配问题,使用队列实现广度优先搜索等。
-
学习算法:数据结构和算法是相辅相成的。学习一些常见的算法,如排序、搜索、图算法等,这将帮助您更好地理解数据结构的应用。
-
阅读教材和参考资料:有很多经典的教材和在线资源可供学习数据结构和算法。阅读这些教材,参考相关的学习资料,可以帮助您深入理解和掌握这些概念。
-
实践项目:尝试在项目中应用所学的数据结构和算法。从简单的项目开始,逐渐挑战更复杂的问题,这样可以加深对数据结构的理解和应用。
-
刷题练习:刷题是巩固数据结构和算法知识的有效方法。尝试解决不同难度的编程题,并学习常见的优化技巧和算法思想。
-
参与讨论和交流:加入数据结构和算法的学习群体,参与讨论和交流,与他人分享经验和解决方案,相互学习和进步。
当您继续学习数据结构时,以下是一些建议和方法:
-
深入研究经典数据结构:在您已经了解基本数据结构的情况下,可以进一步深入研究各种经典的数据结构,如堆、哈希表、图等。学习它们的原理、实现方式和应用场景。
-
理解高级数据结构:探索一些高级数据结构,如红黑树、AVL树、B+树等。这些数据结构在现实中的应用非常广泛,如数据库系统中常用的索引结构。
-
学习算法设计技巧:除了数据结构,学习不同的算法设计技巧也很重要。例如,贪心算法、动态规划、回溯算法、分治算法等。了解这些算法的原理和应用,可以帮助您解决更复杂的问题。
-
阅读经典教材:寻找一些经典的教材,如《算法导论》、《数据结构与算法分析:C语言描述》等。这些教材深入浅出地介绍了数据结构和算法的概念,适合深入学习和理解。
-
参加在线课程和培训:有很多在线课程和培训可以帮助您系统地学习数据结构和算法。例如,Coursera上的《算法和数据结构》课程、LeetCode上的算法专题等。参加这些课程可以获得更系统化的学习体验。
-
解决实际问题:挑战自己解决一些实际的问题。可以在开源项目中贡献代码,解决一些与数据结构相关的问题。这样可以将理论知识应用于实践,并提高自己的编程能力。
-
参与编程竞赛:参加编程竞赛如ACM、Google Code Jam等,这是锻炼数据结构和算法能力的绝佳机会。与其他参赛者切磋、解决难题,对思维能力和算法实现能力都是一种很好的锻炼。
-
使用可视化工具和调试器:使用可视化工具和调试器来帮助您理解和调试数据结构。这些工具可以可视化数据结构的构建过程,以及揭示其中的细节和运行过程。
-
加强实践和反思:做更多的编程练习,尝试不同的数据结构和算法,并思考它们的适用性和优化方法。反思自己的解决方案,寻找改进和优化的空间。
-
培养良好的编码习惯:在实现数据结构时,注重代码的可读性、可维护性和性能。编写清晰、简洁和高效的代码是一个好的习惯,也是一个高级程序员的标志。
持续学习和实践是掌握数据结构和算法的关键。通过不断地挑战自己,解决问题并与他人交流,您将逐渐提高自己的技能水平。祝您在数据结构学习中取得成功!
数据结构期末总复习(gaois课堂版)
数据结构的概念
数据结构是计算机科学中的一个重要概念,它指的是组织和存储数据的方式。数据结构可以帮助我们高效地操作和管理数据,使得计算机程序能够更加有效地执行各种任务。
数据结构有很多种类,常见的包括数组、链表、栈、队列、树、图等。每种数据结构都有其特定的特点和适用场景。
数组是一种线性数据结构,它由一系列相同类型的元素组成,通过索引来访问元素。数组的主要优点是可以快速随机访问元素,但插入和删除元素的操作相对较慢。
链表也是一种线性数据结构,它由一系列节点组成,每个节点包含自身的数据和指向下一个节点的指针。链表的优点是插入和删除元素的操作比较快,但访问特定位置的元素需要遍历整个链表。
栈是一种后进先出(LIFO)的数据结构,只允许在栈顶进行插入和删除操作。栈常用于实现函数调用、表达式求值等场景。
队列是一种先进先出(FIFO)的数据结构,只允许在队尾插入元素,在队头删除元素。队列常用于实现任务调度、缓冲区等场景。
树是一种非线性数据结构,由节点和边组成。每个节点可以有多个子节点,从根节点开始遍历整个树。树常用于实现搜索、排序、存储层次关系等场景。常见的树结构包括二叉树、二叉搜索树、平衡树等。
图是一种由节点和边组成的非线性数据结构,节点之间的连接关系可以是任意的。图常用于表示网络、社交关系、路径搜索等场景。
选择合适的数据结构对于解决具体问题非常重要,不同的数据结构具有不同的性能特点和适用场景,需要根据具体的需求进行选择和应用。
在数据结构中,(D, S) 表示一个数据结构 D 和相应的操作集合 S。通常情况下,D 是指数据结构的定义和存储方式,而 S 则包括了可以对该数据结构进行的各种操作。
举例来说,对于栈这种数据结构,可以表示为 (Stack, {push, pop, isEmpty, peek}),其中 Stack 是栈的定义,{push, pop, isEmpty, peek} 是可以对栈执行的操作集合。
- push:将元素压入栈顶。
- pop:从栈顶弹出元素。
- isEmpty:判断栈是否为空。
- peek:查看栈顶元素但不移除。
通过定义数据结构和操作集合,我们可以清楚地描述出数据结构的特性和可用的操作,更方便地进行程序设计和实现。不同的数据结构可能有不同的操作集合,适用于不同的场景和问题解决方式。
-
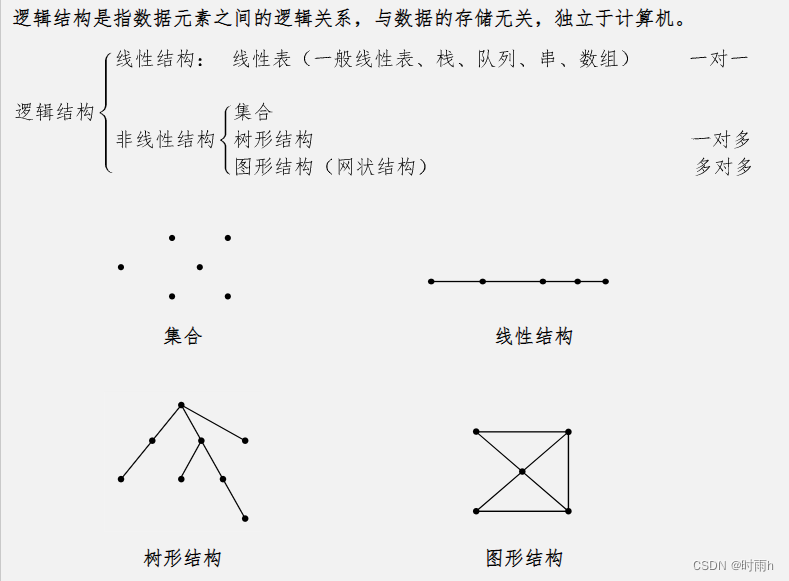
线性结构:数据元素之间存在一对一的关系,线性结构可以分为线性表、栈和队列等。线性表中的数据元素排成一条直线,栈和队列则是线性表的特殊形式。
-
非线性结构:数据元素之间存在一对多或多对多的关系,非线性结构可以分为树和图等。树结构中的数据元素呈现出层次关系,图结构中的数据元素之间可以是任意关系。
-
集合结构:数据元素之间没有特定的关系,集合结构中的元素是无序的,每个元素都是独立的。
逻辑结构主要用于描述数据元素之间的关系和组织方式,而与具体的存储方式无关。根据实际需求,我们可以选择不同的逻辑结构来组织和处理数据,以便更好地满足问题的要求。

常见的数据结构存储结构有以下几种:
-
顺序存储结构:也称为数组存储结构,是将元素按照一定的顺序依次存放在一段连续的内存空间中。通过下标可以直接访问元素,具有随机访问的特点。但是插入和删除操作需要移动大量元素,效率较低。
-
链式存储结构:是将元素存储在不连续的内存空间中,并通过指针连接起来。插入和删除操作仅需要修改指针,效率较高,但是访问元素需要遍历整个链表,效率较低。
-
树形存储结构:是一种层次结构,每个节点有零个或多个子节点。通常有二叉树、B树、B+树等。二叉树最常用的存储方式是链式存储,B树和B+树则采用了顺序存储和链式存储的结合方式。
-
散列表:也称为哈希表,是一种根据关键字直接进行访问的数据结构。它通过关键字的哈希值映射到对应的位置上,查找、插入和删除的时间复杂度都为 O(1)。
-
图形存储结构:是一种由节点和边组成的非线性结构,通常有邻接矩阵和邻接表两种存储方式。邻接矩阵用一个二维数组来表示节点之间的连接关系,邻接表则是用链表的形式表示。
-
索引存储是一种常用的数据存储结构,它通过使用索引来提高数据的检索效率。索引是一种数据结构,它包含了关键字和对应数据位置的映射关系,可以快速定位到所需数据的位置。
在索引存储结构中,通常存在两种主要的索引类型:
-
主索引:主索引是基于数据表的主键或唯一键构建的索引。主索引中的关键字与数据记录一一对应,通过主索引可以直接访问到具体的数据记录,因此具有很高的检索效率。
-
辅助索引:辅助索引是基于非主键的其他列构建的索引。辅助索引中的关键字并不与数据记录一一对应,而是指向对应数据记录的物理地址或指针。通过辅助索引可以快速定位到满足特定条件的数据记录,但需要通过进一步的查找才能获得完整的数据。
索引存储结构的优点是可以大大提高数据的检索效率,减少了查找整个数据集的时间复杂度。同时,索引还可以提供排序功能和加速数据的插入、更新和删除操作。但索引也需要占用额外的存储空间,并且在数据的插入、更新和删除时需要维护索引结构,会增加一定的开销。
在实际应用中,根据具体的数据特点和查询需求,我们需要合理地选择和设计索引存储结构,以提高系统的性能和响应速度。
不同的存储结构适用于不同的场景和问题解决方式。我们需要在实际应用中,根据需求选择最合适的存储结构,以便更好地满足问题的要求。
算法

算法是一组解决特定问题的有限步骤。它是一种精确的、明确的、自动的计算过程,通过输入数据并处理它们来产生输出结果。算法是计算机科学中最基本的概念之一,也是计算机程序的核心部分。
算法具有以下几个重要的特点:
-
精确性:算法必须是精确的,即每个步骤都必须明确、无歧义地定义。
-
有限性:算法必须能在有限的时间和空间内完成计算。
-
可行性:算法必须是可行的,即能够在计算机等计算设备上执行。
-
输入输出:算法必须有输入和输出,即将输入转换为输出的过程。
-
通用性:算法必须是通用的,即能够解决一类问题而不是特定的单个问题。
-
可读性:算法必须是可读的,即容易理解和实现,并且易于维护和修改。
算法可以分为多种类型,常见的分类方式包括:
-
按照解决问题的领域分类,如图像处理、网络优化、数据挖掘等。
-
按照算法设计思想分类,如贪心算法、分治算法、动态规划算法、回溯算法等。
-
按照算法的性质分类,如排序算法、查找算法、字符串匹配算法等。
在实际应用中,我们需要根据具体问题的特点和需求选择合适的算法以提高计算效率,并且对算法进行优化以满足不同的性能要求。

算法效率通常可以通过时间复杂度和空间复杂度来度量
时间复杂度指的是算法执行所需要的时间,通常使用大O符号来表示。例如,一个算法的时间复杂度为O(n),表示随着输入规模n的增加,算法执行所需要的时间以线性方式增长。
空间复杂度指的是算法执行所需要的内存空间,同样也使用大O符号来表示。例如,一个算法的空间复杂度为O(n),表示算法在执行期间最多需要占用n个单位的内存空间。
在实际应用中,我们需要根据具体问题的特点和要求,选择合适的算法以满足时间复杂度和空间复杂度的要求。通常情况下,时间复杂度和空间复杂度之间存在一定的权衡关系,有时需要进行折中取舍。例如,在一些对计算速度要求较高的场景中,我们可能更愿意牺牲一定的内存空间来提高执行效率;而在一些内存受限的场景中,我们可能更愿意使用空间复杂度较小的算法。
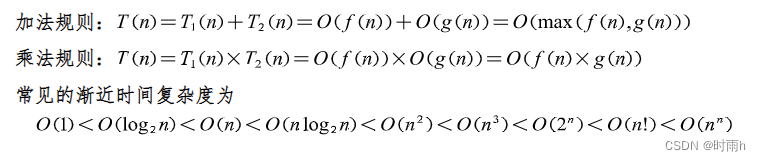
算法效率通常可以通过时间复杂度和空间复杂度来度量和评估。时间复杂度是指算法解决问题所需的时间量级,它描述了算法的运行时间随着输入规模增长时的增长率。常见的时间复杂度有常数时间 O(1)、线性时间 O(n)、对数时间 O(log n)、平方时间 O(n^2)等。
空间复杂度是指算法解决问题所需的存储空间量级,它描述了算法所需的额外空间随着输入规模增长时的增长率。常见的空间复杂度有常数空间 O(1)、线性空间 O(n)、对数空间 O(log n)等。
评估算法的时间复杂度和空间复杂度可以帮助我们比较不同算法之间的效率,选择最优的算法来解决问题。通常情况下,我们希望找到时间复杂度尽可能低且空间复杂度较小的算法,以提高程序的执行效率和节省资源的使用。
时间复杂度的频度计算
*是指对于算法中每个基本操作的执行次数进行统计和计算,从而得出算法的总执行次数。*具体地说,可以通过以下步骤来计算算法的时间复杂度:
-
确定算法中需要执行的基本操作。基本操作通常包括算术运算、比较运算、赋值操作等。
-
对于每个基本操作,估算它在算法中被执行的次数。这通常需要根据问题的规模和算法的实现方式进行分析和推导,并结合实际代码进行验证。
-
将每个基本操作的执行次数相加,并用大 O 记号表示算法的时间复杂度。这里的大 O 记号表示算法的最坏情况时间复杂度,即在所有可能的输入情况下,算法的最长执行时间。
例如,对于以下求解数组元素和的算法:
int sum = 0;
for(int i=0; i<n; i++){
sum += a[i];
}
其中,基本操作是一个加法操作 sum += a[i],它在循环中被执行了 n 次。因此,算法的总执行次数为 n 次,时间复杂度为 O(n)。
再例如,对于以下查找有序数组中是否存在某个元素的二分查找算法:
int binarySearch(int[] a, int x){
int low = 0, high = a.length - 1;
while(low <= high){
int mid = (low + high) / 2;
if(a[mid] == x){
return mid;
}else if(a[mid] < x){
low = mid + 1;
}else{
high = mid - 1;
}
}
return -1;
}
其中,基本操作包括一个比较运算 a[mid] == x 和两个赋值操作 low = mid + 1 和 high = mid - 1。每次循环中至少执行一次比较运算和一个赋值操作,因此总执行次数为 log n(以 2 为底),时间复杂度为 O(log n)。
需要注意的是,算法的时间复杂度并不是具体的执行时间,而是对算法执行时间的一种抽象描述。它只考虑了算法在不同输入规模下的增长趋势,而没有考虑实际运行过程中的常数因子、系数和常数项等因素。因此,两个时间复杂度相同的算法在具体执行时间上可能存在较大差异,需要根据具体情况进行选择。
线性表

线性表的类型定义可以根据具体的编程语言来进行,以下是一些常见编程语言中线性表的类型定义示例:
在C语言中,可以使用结构体来定义线性表类型:
typedef struct {
int data[MAX_SIZE]; // 存储线性表元素的数组
int length; // 线性表的当前长度
} LinearList;
在Java语言中,可以使用类来定义线性表类型:
public class LinearList {
private int[] data; // 存储线性表元素的数组
private int length; // 线性表的当前长度
public LinearList(int maxSize) {
data = new int[maxSize];
length = 0;
}
}
在Python语言中,可以使用类或者列表来定义线性表类型:
class LinearList:
def __init__(self, max_size):
self.data = [None] * max_size # 存储线性表元素的列表
self.length = 0
# 或者直接使用列表
linear_list = []

-
InitList(&L): 初始化表。这个操作用于构造一个空的线性表,即创建一个可以存储数据元素的容器。在具体实现时,可以根据编程语言的要求进行相应的初始化。
-
Length(L): 求表长。该操作用于返回线性表L中数据元素的个数,也就是表的长度。通过遍历线性表,计算元素个数即可得到表的长度。
-
LocateElem(L, e): 按值查找操作。该操作用于在线性表L中查找具有给定关键字值e的元素。它会返回第一个匹配到的元素的位置。需要遍历线性表,逐个比较元素的值与给定值e是否相等。
-
GetElem(L, i): 按位查找操作。该操作用于获取线性表L中第i个位置的元素的值。需要注意,线性表的索引通常从1开始。因此,该操作会返回第i个位置上的元素的值。
-
ListInsert(&L, i, e): 插入操作。该操作在线性表L的第i个位置上插入指定元素e。在插入之前,需要将第i个位置及其后面的所有元素后移一位,为新的元素腾出位置。
-
ListDelete(&L, i, &e): 删除操作。该操作用于删除线性表L中第i个位置的元素,并通过e返回被删除的元素的值。删除元素后,需要将第i个位置后面的所有元素前移一位,填补删除的空缺。
-
PrintList(L): 输出操作。该操作按照前后顺序输出线性表L的元素值。可以使用循环遍历线性表,并将每个元素的值依次输出。
-
Empty(L): 判空操作。该操作用于检查线性表L是否为空。如果线性表中没有任何元素,即为空表,则返回True;否则,返回False。
-
DestroyList(&L): 销毁操作。该操作用于销毁线性表L,释放相关的内存空间。在销毁之后,线性表将不再存在。
这些是线性表的基本操作,它们是实现线性表功能的基础。你可以根据需求选择并实现这些操作,以满足具体的编程需求。
顺序表的结构

顺序表是一种线性表的实现方式,它使用一段连续的存储空间来存储元素。在内存中,顺序表通常被表示为一个数组。下面是顺序表的结构:
typedef struct {
ElementType *data; // 指向存储元素的数组
int length; // 当前顺序表中的元素个数
int capacity; // 顺序表的容量,即数组的大小
} SeqList;
上面的结构体定义了一个顺序表的类型 SeqList。它包含了以下几个字段:
-
ElementType *data: 这是一个指针类型,指向存储元素的数组。每个数组元素可以存储一个数据元素,数据元素的类型由ElementType来定义,可以是任意类型。 -
int length: 这是一个整型变量,记录当前顺序表中的元素个数。初始时,length 为 0。 -
int capacity: 这是一个整型变量,表示顺序表的容量,即数组的大小。capacity 决定了顺序表能够容纳的最大元素个数。
顺序表的优点是可以快速根据位置访问元素,时间复杂度为O(1)。但是插入和删除操作可能需要移动大量元素,效率较低,时间复杂度为O(n)。
在具体编程实现中,还需要注意对顺序表容量的管理和动态扩容等问题。
顺序表随机查找
顺序表的主要特点之一就是支持随机存取,即通过元素的序号(或索引)可以在O(1)的时间复杂度内找到指定的元素。
这是因为顺序表的元素在存储时是按照一定的顺序依次排列在一块连续的内存空间中,每个元素占据一个固定大小的空间。因此,通过首地址和元素序号即可计算出指定元素在内存中的物理地址,从而实现随机存取。
与之相对比的是链表这种动态数据结构,它的元素在存储时并不是按照顺序存储在一块连续的内存空间中,而是通过指针链接起来的。因此,链表不支持随机存取,只能通过遍历整个链表来查找指定元素,时间复杂度为O(n),其中n为链表的长度。
总的来说,顺序表的随机存取特性使得它在某些场景下具有优势,例如需要频繁访问指定位置的元素或进行排序等操作时,而链表则更适合于插入、删除等动态操作较多的场景。
线性表的动态分配

线性表的动态分配是指在线性表操作过程中,需要根据实际情况动态地分配内存空间来存储数据元素。动态分配可以避免事先预留过多的存储空间,节约内存资源。在线性表的动态分配中,通常使用指针来实现。
对于顺序表,动态分配的方式已经在之前回答中提到,这里再简单总结一下:
-
初始时,可以通过
malloc函数动态分配一定大小的存储空间,存储元素的数组称为 data。 -
当存储空间不足以存放新元素时,需要通过
realloc函数重新分配更大的存储空间,并将原来的数据复制到新的空间中。 -
在释放存储空间前,需要使用
free函数将分配的内存空间释放。
对于链表,动态分配的方式通常是通过节点的动态分配来实现。每个节点包含一个数据元素和一个指向下一个节点的指针。初始时,可以通过 malloc 函数动态分配一个节点的内存空间,并将数据元素和指针赋值给节点。当需要插入或删除节点时,只需要修改相应节点的指针即可。
需要注意的是,在动态分配内存空间时,需要管理分配的内存空间,防止出现内存泄漏等问题。在释放存储空间前,需要确保所有指向该空间的指针都已经被清空或修改,以避免访问已经释放的内存空间。
具体实现动态分配的线性表,我们可以以顺序表和链表为例进行说明。
- 动态分配的顺序表实现:
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int* data; // 存储数据元素的数组
int length; // 当前存储的元素个数
int capacity; // 当前分配的存储空间容量
} SeqList;
void init(SeqList* list, int capacity) {
list->data = (int*)malloc(sizeof(int) * capacity); // 初始分配存储空间
list->length = 0;
list->capacity = capacity;
}
void insert(SeqList* list, int element) {
if (list->length >= list->capacity) {
// 存储空间已满,需要扩容
list->data = (int*)realloc(list->data, sizeof(int) * (list->capacity * 2));
list->capacity *= 2;
}
list->data[list->length] = element; // 在末尾插入新元素
list->length++;
}
void destroy(SeqList* list) {
free(list->data); // 释放动态分配的存储空间
list->data = NULL;
list->length = 0;
list->capacity = 0;
}
int main() {
SeqList list;
init(&list, 5); // 初始容量为5
insert(&list, 1);
insert(&list, 2);
insert(&list, 3);
insert(&list, 4);
insert(&list, 5);
insert(&list, 6); // 超过容量,进行扩容
for (int i = 0; i < list.length; i++) {
printf("%d ", list.data[i]); // 输出顺序表中的元素
}
printf("\n");
destroy(&list);
return 0;
}
- 动态分配的链表实现:
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data; // 数据元素
struct Node* next; // 指向下一个节点的指针
} Node;
typedef struct {
Node* head; // 头节点
} LinkedList;
void init(LinkedList* list) {
list->head = NULL; // 初始化为空链表
}
void insert(LinkedList* list, int element) {
Node* newNode = (Node*)malloc(sizeof(Node)); // 动态分配新节点的内存空间
newNode->data = element;
newNode->next = NULL;
if (list->head == NULL) {
list->head = newNode; // 空链表,新节点成为头节点
} else {
Node* current = list->head;
while (current->next != NULL) {
current = current->next; // 找到链表的最后一个节点
}
current->next = newNode; // 将新节点插入到最后
}
}
void destroy(LinkedList* list) {
Node* current = list->head;
while (current != NULL) {
Node* temp = current; // 临时保存当前节点
current = current->next; // 移动到下一个节点
free(temp); // 释放当前节点的内存空间
}
list->head = NULL;
}
int main() {
LinkedList list;
init(&list);
insert(&list, 1);
insert(&list, 2);
insert(&list, 3);
Node* current = list.head;
while (current != NULL) {
printf("%d ", current->data); // 输出链表中的元素
current = current->next;
}
printf("\n");
destroy(&list);
return 0;
}
以上是简单的动态分配线性表的实现示例,你可以根据自己的需求进行进一步的扩展和修改。
顺序表的实现
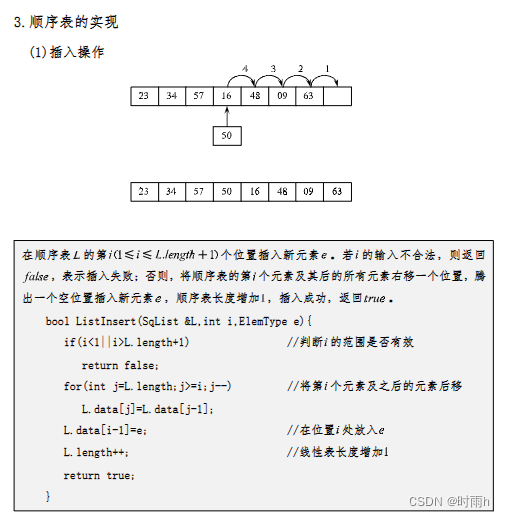
在长度为n的顺序表的第i个位置上插入一个元泰(1≤i≤n十1),元素的移动次数为().
在长度为n的顺序表的第i个位置上插入一个元素,元素的移动次数为n - i + 1。
插入元素后,原本在第i个位置及其后面的元素都需要向后移动一位,所以移动次数为n - i。
另外,插入元素本身需要移动一次,所以总的移动次数为n - i + 1。
因此,答案是 n - i + 1。
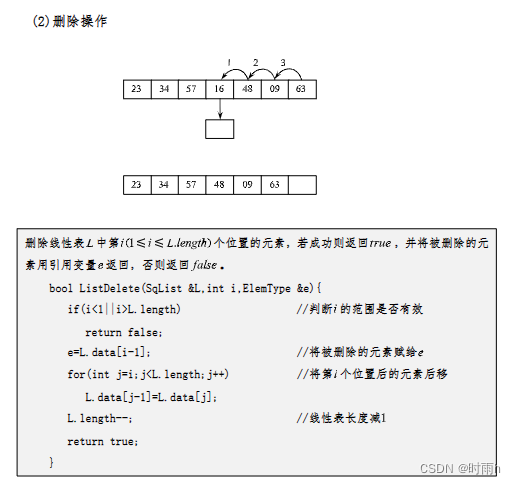
题2.设顺序线性表中有个数据元素,则删除表中第i个元素需要移动()个元素。
A.n-i
B.n-i-1
C.n-i+1
D.i
答案:A
题3.对于顺序存储的线性表,访问结点和增加、删除结点的时间复杂度为()。
A.O(n),O(n
B.O(n),O(1)
C.O(1),O(n)
D.O(1),O(1)
答案:C
题2的答案是A. n-i。
删除顺序线性表中的第i个元素时,需要将位于第i+1个位置及其后面的元素都向前移动一位,填补删除位置。因此,移动的元素个数为n-i。
题3的答案是C. O(1),O(n)。
对于顺序存储的线性表,访问结点的时间复杂度是O(1),因为可以直接通过下标访问。
增加结点和删除结点的时间复杂度是O(n),因为在顺序存储中,插入或删除一个元素后,需要移动该位置后面的所有元素,所以随着线性表长度的增加,时间复杂度也会增加。

按值查找操作是指在一个线性表中根据给定的值,查找该值在表中的位置或者判断该值是否存在。
具体实现方式可以是遍历整个线性表,逐个比较每个元素的值与目标值是否相等。如果找到了匹配的值,则返回其位置;如果遍历完整个表都没有找到匹配的值,则表示该值不存在。
时间复杂度为O(n),其中n为线性表的长度。最坏情况下需要遍历整个线性表才能找到目标值或确定目标值不存在。
按位查找操作是指根据给定的位置,获取线性表中对应位置的元素值。
具体实现方式是通过索引直接访问线性表中的元素,返回对应位置的值。
时间复杂度为O(1),因为不需要遍历整个线性表,只需要通过索引直接获取对应位置的值。
另外,对于有序线性表,可以使用二分查找来实现按值查找操作,这样可以将时间复杂度降为O(log n),其中n为线性表的长度。具体实现方式是每次取中间位置的元素进行比较,然后根据比较结果缩小查找范围,直到找到目标元素或者确定目标元素不存在。
按位查找操作在顺序存储结构中的时间复杂度为O(1),而在链式存储结构中时间复杂度为O(n),其中n为链表长度。这是因为链式存储结构需要依次遍历链表中的节点才能找到目标位置。
综上所述,按值查找操作和按位查找操作都是常见的线性表操作,具体实现方式和时间复杂度取决于线性表的实现方式和特点。在实际开发中,需要根据具体情况选择合适的实现方式,以达到更高效的查找效果。
题4.将两个有序顺序表A,B合并为一个新的有序顺序表C,并用函数返回结果顺序表。
算法思想:首先,按顺序不断取下两个顺序表表头较小的结点存入新的顺序表中。然后,看哪个表还有剩余,将剩下的部分添加到新的顺序表后面。
你可以使用C语言来实现将两个有序顺序表合并为一个新的有序顺序表的算法。以下是一个示例代码:
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100
// 定义顺序表结构体
typedef struct {
int data[MAX_SIZE];
int length;
} SeqList;
// 初始化顺序表
void initSeqList(SeqList *list) {
list->length = 0;
}
// 添加元素到顺序表
void insert(SeqList *list, int value) {
if (list->length >= MAX_SIZE) {
printf("顺序表已满,无法插入新元素。\n");
return;
}
int i;
for (i = list->length - 1; i >= 0 && list->data[i] > value; i--) {
list->data[i + 1] = list->data[i];
}
list->data[i + 1] = value;
list->length++;
}
// 合并两个有序顺序表
SeqList merge(SeqList listA, SeqList listB) {
SeqList listC;
initSeqList(&listC);
int i = 0, j = 0;
while (i < listA.length && j < listB.length) {
if (listA.data[i] <= listB.data[j]) {
insert(&listC, listA.data[i]);
i++;
} else {
insert(&listC, listB.data[j]);
j++;
}
}
// 将剩余部分添加到顺序表C中
while (i < listA.length) {
insert(&listC, listA.data[i]);
i++;
}
while (j < listB.length) {
insert(&listC, listB.data[j]);
j++;
}
return listC;
}
// 打印顺序表
void printSeqList(SeqList list) {
printf("顺序表的元素为:");
for (int i = 0; i < list.length; i++) {
printf("%d ", list.data[i]);
}
printf("\n");
}
int main() {
SeqList listA, listB, listC;
initSeqList(&listA);
initSeqList(&listB);
// 向顺序表A中添加元素
insert(&listA, 1);
insert(&listA, 3);
insert(&listA, 5);
// 向顺序表B中添加元素
insert(&listB, 2);
insert(&listB, 4);
insert(&listB, 6);
// 合并两个顺序表
listC = merge(listA, listB);
// 打印合并后的顺序表C
printSeqList(listC);
return 0;
}
这段代码会将两个有序顺序表A和B合并为一个新的有序顺序表C,并通过函数返回结果顺序表。你可以根据自己的需求修改顺序表的最大长度(MAX_SIZE),及在主函数中插入元素来测试算法的正确性。
链表
链表(Linked List)是一种常见的数据结构,用于存储一系列具有相同类型的元素。链表由节点(Node)组成,每个节点包含两部分:数据域(存储元素值)和指针域(指向下一个节点)。通过节点之间的指针连接,形成一个链式结构。
链表可以分为单向链表和双向链表两种类型。在单向链表中,每个节点只有一个指针,指向下一个节点;而在双向链表中,每个节点有两个指针,分别指向前一个节点和后一个节点。
链表的优点是插入和删除操作的时间复杂度为O(1),而不受数据规模的影响。但是,访问链表中的特定元素需要从头开始遍历链表,时间复杂度为O(n),其中n是链表的长度。
链表在实际应用中有广泛的用途,比如实现栈、队列、哈希表等数据结构,以及解决一些特定的问题,如反转链表、合并有序链表等。
需要注意的是,在使用链表时,我们需要额外的空间来存储指针,因此链表对内存的利用率较低。同时,在频繁插入和删除操作较多,而对访问操作要求不高的情况下,链表是一个较为合适的选择。

单链表(Singly Linked List)是一种常见的链表结构,由一系列节点按顺序连接而成。每个节点包含两个部分:数据域(存储元素值)和指针域(指向下一个节点)。最后一个节点的指针域指向空(NULL)。
以下是单链表的基本结构:
Node:
- 数据域(Data): 存储元素值
- 指针域(Next): 指向下一个节点
LinkedList:
- 头指针(Head): 指向链表的第一个节点
单链表的头指针(Head)用于标识链表的起始位置。通过头指针,可以遍历整个链表,或者在链表中插入、删除节点。
单链表的特点是每个节点只有一个指针域,指向下一个节点,最后一个节点的指针域为空。这意味着,在单链表中,只能从前往后遍历,无法直接访问前一个节点,因此对于某些操作,比如在给定节点之前插入一个新节点,需要额外的操作来处理指针。
需要注意的是,单链表中的节点可以动态地分配内存,这意味着可以根据需求灵活地扩展或缩小链表的长度。
下面是一个示例单链表的结构:
Head -> Node1 -> Node2 -> Node3 -> ... -> NULL
其中,Head是头指针,Node1、Node2、Node3等为节点,箭头表示指针域的指向关系,NULL表示链表的结束。
单链表的操作包括插入节点、删除节点、查找节点、遍历链表等,这些操作可以根据具体需求进行实现。

题1.若线性表采用链式存储,则表中各元素的存储地址()。
A.必须是连续的
B.部分地址是连续的
C.一定是不连续的
D.不一定是连续的
答案:D
题2.单链表中,增加一个头结点的目的是为了()。
A.使单链表至少有一个结点
B.标识表结点中首结点的位置
C.方便运算的实现
D.说明单链表是线性表的链式存储
答案:C
题1的答案是D. 不一定是连续的。
如果线性表采用链式存储方式,表中各元素的存储地址不需要连续。链式存储通过节点之间的指针连接,每个节点可以分配在内存的任意位置。节点的指针域存储着下一个节点的地址,通过指针的链接,实现了元素之间的逻辑关系。
题2的答案是C. 方便运算的实现。
增加一个头结点的目的是为了方便对单链表进行操作和实现一些常用的操作,如插入、删除、查找等。头结点不存储具体的数据,它的存在主要是为了简化操作,使得对链表的操作更加统一和方便。头结点可以作为操作的起点,避免了对空链表的特殊处理,提高了代码的可读性和可维护性。
引入头结点后,可以带来两个优点:
①由于第一个数据结点的位置被存放在头结点的指针域中,所以在链表的第一个位置上的操作和在表的其他位置上的操作一致,无需进行特殊处理。
②无论链表是否为空,其头指针都指向头结点的非空指针(空表中头结点的指针域为空)。
单链表的实现
以下是单链表的详细实现示例(使用C语言):
- 定义节点结构(Node):
struct Node {
int data;
struct Node *next;
};
- 定义链表结构(LinkedList):
struct LinkedList {
struct Node *head;
};
- 实现插入操作:
void insert(struct LinkedList *list, int data) {
struct Node *new_node = (struct Node *)malloc(sizeof(struct Node)); // 创建新节点
new_node->data = data;
new_node->next = NULL;
if (list->head == NULL) { // 如果链表为空,将新节点设为头节点
list->head = new_node;
} else {
struct Node *current = list->head;
while (current->next != NULL) { // 遍历到最后一个节点
current = current->next;
}
current->next = new_node; // 将新节点插入在最后一个节点之后
}
}
- 实现删除操作:
void delete(struct LinkedList *list, int target) {
if (list->head == NULL) { // 如果链表为空,无法删除
return;
}
if (list->head->data == target) { // 如果要删除的节点是头节点
struct Node *temp = list->head;
list->head = list->head->next;
free(temp);
} else {
struct Node *current = list->head;
while (current->next != NULL && current->next->data != target) { // 查找要删除节点的前一个节点
current = current->next;
}
if (current->next != NULL) { // 找到要删除的节点
struct Node *temp = current->next;
current->next = current->next->next;
free(temp);
}
}
}
- 实现查找操作:
int search(struct LinkedList *list, int target) {
struct Node *current = list->head;
while (current != NULL) {
if (current->data == target) { // 找到匹配的节点
return 1;
}
current = current->next;
}
return 0; // 遍历完链表未找到匹配的节点
}
- 实现遍历操作:
void traverse(struct LinkedList *list) {
struct Node *current = list->head;
while (current != NULL) {
printf("%d ", current->data); // 访问节点的数据域
current = current->next;
}
}
这是一个简单的单链表实现示例。由于C语言需要手动管理内存,因此在使用malloc函数分配内存时需要检查是否分配成功,并在删除节点时需要使用free函数释放内存。您可以根据这个示例进行自定义扩展和适应具体需求。



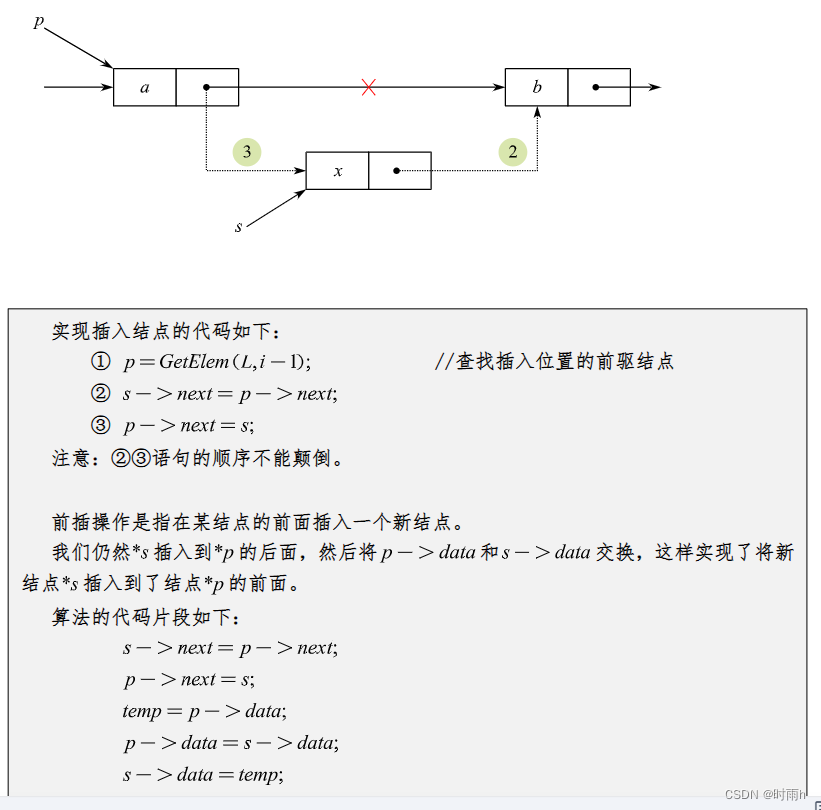
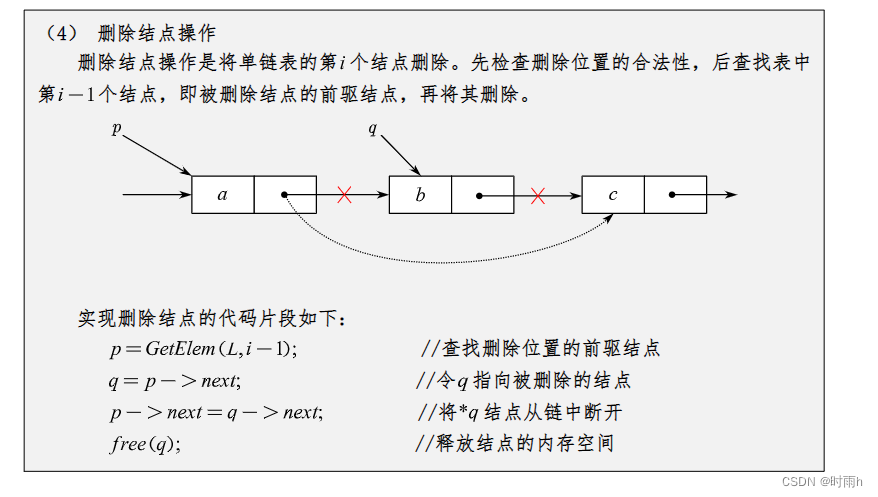
双链表

双链表(Doubly Linked List)是一种常见的数据结构,它与单链表相比,在每个节点中都有两个指针,分别指向前一个节点和后一个节点,因此可以实现双向遍历。这使得在双链表中插入、删除节点等操作更加高效。
下面是一个更详细的双链表的 C 代码实现:
#include <stdio.h>
#include <stdlib.h>
// 双链表节点结构
typedef struct Node {
int data;
struct Node* prev;
struct Node* next;
} Node;
// 创建新节点
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
if (newNode == NULL) {
printf("内存分配失败\n");
exit(1);
}
newNode->data = data;
newNode->prev = NULL;
newNode->next = NULL;
return newNode;
}
// 在链表头部插入节点
void insertFront(Node** head, int data) {
Node* newNode = createNode(data);
if (*head == NULL) {
*head = newNode;
} else {
newNode->next = *head;
(*head)->prev = newNode;
*head = newNode;
}
}
// 在链表末尾插入节点
void insertEnd(Node** head, int data) {
Node* newNode = createNode(data);
if (*head == NULL) {
*head = newNode;
} else {
Node* curr = *head;
while (curr->next != NULL) {
curr = curr->next;
}
curr->next = newNode;
newNode->prev = curr;
}
}
// 在指定位置插入节点
void insertAt(Node** head, int data, int position) {
if (position < 1) {
printf("无效的位置\n");
return;
}
if (position == 1) {
insertFront(head, data);
return;
}
Node* newNode = createNode(data);
Node* curr = *head;
int count = 1;
while (count < position - 1 && curr != NULL) {
curr = curr->next;
count++;
}
if (curr == NULL) {
printf("无效的位置\n");
return;
}
newNode->next = curr->next;
newNode->prev = curr;
if (curr->next != NULL) {
curr->next->prev = newNode;
}
curr->next = newNode;
}
// 删除链表头部节点
void deleteFront(Node** head) {
if (*head == NULL) {
printf("链表为空\n");
return;
}
Node* temp = *head;
*head = (*head)->next;
if (*head != NULL) {
(*head)->prev = NULL;
}
free(temp);
}
// 删除链表末尾节点
void deleteEnd(Node** head) {
if (*head == NULL) {
printf("链表为空\n");
return;
}
Node* curr = *head;
while (curr->next != NULL) {
curr = curr->next;
}
if (curr->prev != NULL) {
curr->prev->next = NULL;
} else {
*head = NULL;
}
free(curr);
}
// 删除指定位置节点
void deleteAt(Node** head, int position) {
if (*head == NULL || position < 1) {
printf("无效的位置\n");
return;
}
if (position == 1) {
deleteFront(head);
return;
}
Node* curr = *head;
int count = 1;
while (count < position && curr != NULL) {
curr = curr->next;
count++;
}
if (curr == NULL) {
printf("无效的位置\n");
return;
}
if (curr->prev != NULL) {
curr->prev->next = curr->next;
} else {
*head = curr->next;
}
if (curr->next != NULL) {
curr->next->prev = curr->prev;
}
free(curr);
}
// 打印链表
void printList(Node* head) {
Node* curr = head;
while (curr != NULL) {
printf("%d ", curr->data);
curr = curr->next;
}
printf("\n");
}
int main() {
Node* head = NULL;
// 插入节点
insertFront(&head, 1);
insertEnd(&head, 2);
insertEnd(&head, 3);
insertAt(&head, 4, 2);
// 打印链表
printf("双链表:");
printList(head);
// 删除节点
deleteFront(&head);
deleteEnd(&head);
deleteAt(&head, 1);
// 打印链表
printf("删除节点后的双链表:");
printList(head);
return 0;
}
这段代码实现了双链表的创建节点、在链表头部、末尾和指定位置插入节点,以及删除链表头部、末尾和指定位置节点,并且可以打印链表。你可以根据自己的需求进行扩展和修改。
双链表的插入操作
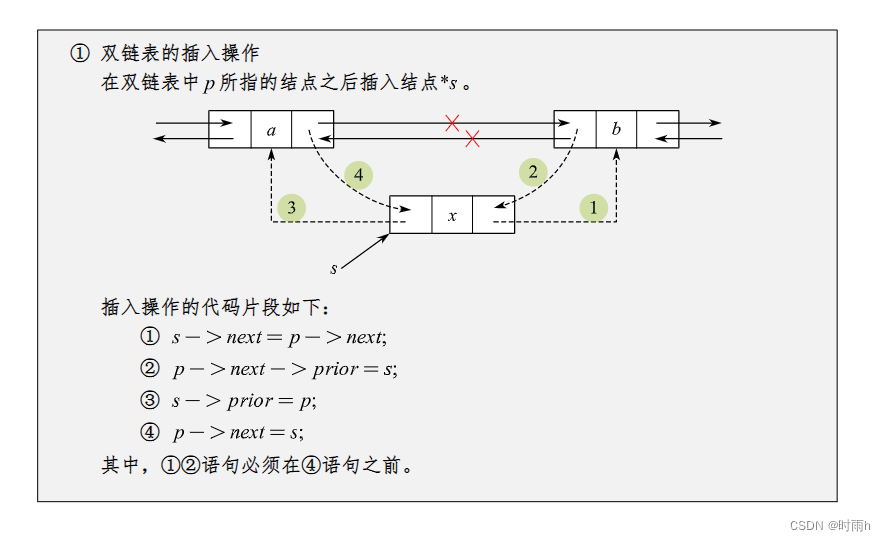
双链表的插入操作有三种情况:
- 在链表头部插入节点
- 在链表末尾插入节点
- 在指定位置插入节点
下面是这三种情况的详细说明和代码实现。
- 在链表头部插入节点
在链表头部插入节点,只需要将新节点插入到原头节点前面,并更新头节点的指针。
void insertFront(Node** head, int data) {
Node* newNode = createNode(data);
if (*head == NULL) {
*head = newNode;
} else {
newNode->next = *head;
(*head)->prev = newNode;
*head = newNode;
}
}
- 在链表末尾插入节点
在链表末尾插入节点,需要遍历整个链表,找到最后一个节点,并将新节点插入到最后一个节点后面。
void insertEnd(Node** head, int data) {
Node* newNode = createNode(data);
if (*head == NULL) {
*head = newNode;
} else {
Node* curr = *head;
while (curr->next != NULL) {
curr = curr->next;
}
curr->next = newNode;
newNode->prev = curr;
}
}
- 在指定位置插入节点
在指定位置插入节点,需要遍历链表,找到指定位置的节点,并将新节点插入到该节点的前面,并更新相邻节点的指针。
void insertAt(Node** head, int data, int position) {
if (position < 1) {
printf("无效的位置\n");
return;
}
if (position == 1) {
insertFront(head, data);
return;
}
Node* newNode = createNode(data);
Node* curr = *head;
int count = 1;
while (count < position - 1 && curr != NULL) {
curr = curr->next;
count++;
}
if (curr == NULL) {
printf("无效的位置\n");
return;
}
newNode->next = curr->next;
newNode->prev = curr;
if (curr->next != NULL) {
curr->next->prev = newNode;
}
curr->next = newNode;
}
注意,如果指定位置为1,则直接调用insertFront()函数插入节点。如果指定位置大于链表长度,则插入失败,输出错误信息。
上述代码中,createNode()函数创建一个新节点,Node** head表示指向头节点指针的指针,因为在插入操作中需要修改头节点指针的值,而头节点指针本身是一个指针变量,所以需要使用指向指针的指针来实现修改。
双链表的删除操作
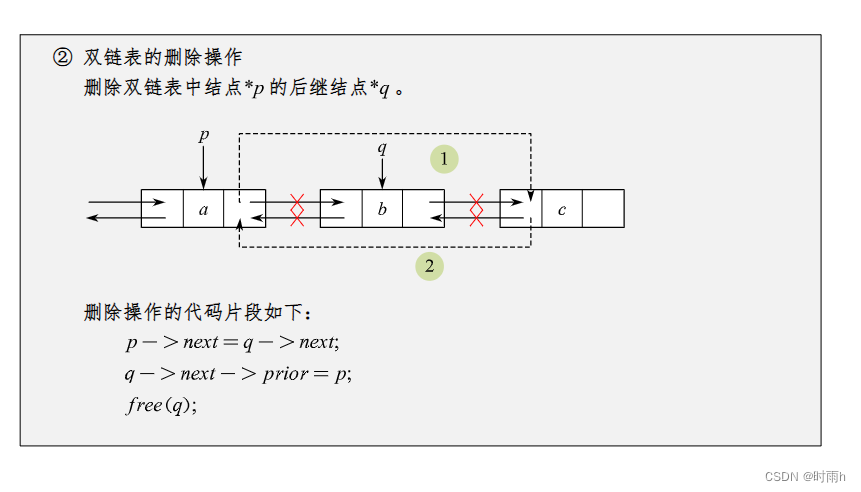
双链表的删除操作有三种情况:
- 删除链表头部节点
- 删除链表末尾节点
- 删除指定位置节点
下面是这三种情况的详细说明和代码实现。
- 删除链表头部节点
删除链表头部节点,只需要将头节点的下一个节点作为新的头节点,并释放原头节点的内存。
void deleteFront(Node** head) {
if (*head == NULL) {
printf("链表为空\n");
return;
}
Node* temp = *head;
*head = (*head)->next;
if (*head != NULL) {
(*head)->prev = NULL;
}
free(temp);
}
- 删除链表末尾节点
删除链表末尾节点,需要遍历整个链表,找到最后一个节点,并将倒数第二个节点的next指针置为NULL,并释放最后一个节点的内存。
void deleteEnd(Node** head) {
if (*head == NULL) {
printf("链表为空\n");
return;
}
Node* curr = *head;
while (curr->next != NULL) {
curr = curr->next;
}
if (curr->prev != NULL) {
curr->prev->next = NULL;
} else {
*head = NULL;
}
free(curr);
}
- 删除指定位置节点
删除指定位置节点,需要遍历链表,找到指定位置的节点,更新相邻节点的指针,并释放目标节点的内存。
void deleteAt(Node** head, int position) {
if (*head == NULL || position < 1) {
printf("无效的位置\n");
return;
}
if (position == 1) {
deleteFront(head);
return;
}
Node* curr = *head;
int count = 1;
while (count < position && curr != NULL) {
curr = curr->next;
count++;
}
if (curr == NULL) {
printf("无效的位置\n");
return;
}
if (curr->prev != NULL) {
curr->prev->next = curr->next;
} else {
*head = curr->next;
}
if (curr->next != NULL) {
curr->next->prev = curr->prev;
}
free(curr);
}
注意,如果指定位置为1,则直接调用deleteFront()函数删除头部节点。如果指定位置大于链表长度,则删除失败,输出错误信息。
上述代码中,Node** head表示指向头节点指针的指针,因为在删除操作中需要修改头节点指针的值,而头节点指针本身是一个指针变量,所以需要使用指向指针的指针来实现修改。
循环链表
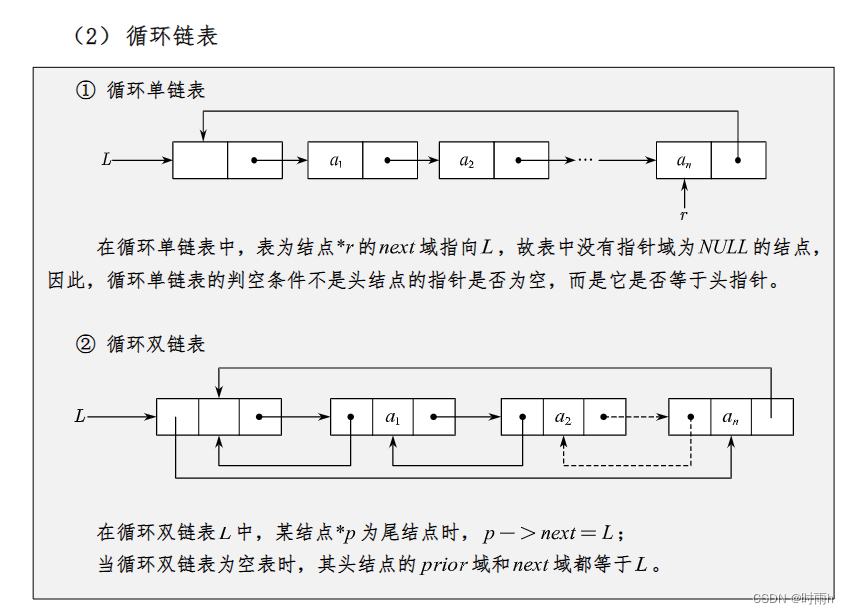
循环链表是一种特殊的链表,它与普通链表的区别在于,最后一个节点的next指针不是指向NULL,而是指向第一个节点,从而形成一个环形结构。
循环链表有两种基本类型:单向循环链表和双向循环链表。单向循环链表中每个节点只有一个指针域,即指向下一个节点的指针,而双向循环链表中每个节点有两个指针域,即分别指向前一个节点和后一个节点的指针。
下面是一个单向循环链表的定义:
typedef struct Node {
int data;
struct Node* next;
} Node;
typedef struct CircularLinkedList {
Node* head;
} CircularLinkedList;
在单向循环链表中,头节点的next指针指向第一个节点,而最后一个节点的next指针则指向头节点。
循环链表的插入和删除操作与普通链表类似,唯一的区别是在插入和删除末尾节点时需要特殊处理,因为末尾节点的next指针指向头节点而非NULL。
下面是一个简单的单向循环链表的插入和删除操作的示例代码:
// 创建新节点
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
return newNode;
}
// 在链表末尾插入节点
void insertEnd(CircularLinkedList* list, int data) {
Node* newNode = createNode(data);
if (list->head == NULL) {
list->head = newNode;
newNode->next = list->head;
} else {
Node* curr = list->head;
while (curr->next != list->head) {
curr = curr->next;
}
curr->next = newNode;
newNode->next = list->head;
}
}
// 删除指定位置的节点
void deleteAt(CircularLinkedList* list, int position) {
if (list->head == NULL) {
printf("链表为空\n");
return;
}
Node* curr = list->head;
Node* prev = NULL;
int count = 1;
while (count < position && curr->next != list->head) {
prev = curr;
curr = curr->next;
count++;
}
if (count < position) {
printf("无效的位置\n");
return;
}
if (prev == NULL) {
Node* tail = list->head;
while (tail->next != list->head) {
tail = tail->next;
}
list->head = curr->next;
tail->next = list->head;
} else {
prev->next = curr->next;
}
free(curr);
}
注意,上述代码中,在删除末尾节点时需要特判。如果目标节点是头节点,则需要更新头节点指针的值,并将最后一个节点的next指针指向新的头节点。如果目标节点不是头节点,则直接更新相邻节点的指针即可。
循环链表的遍历和其他操作与普通链表类似,只需要判断是否回到了头节点即可。
堆栈(stack)


堆栈(stack)是一种基于后进先出(LIFO,Last In First Out)原则的数据结构。它模拟了现实生活中的堆栈,类似于一摞盘子或一堆书。
堆栈有两个基本操作:入栈(push)和出栈(pop)。
- 入栈(push):将新元素添加到堆栈的顶部。新元素成为当前堆栈的最上面一个元素。
- 出栈(pop):从堆栈的顶部移除最上面的元素,并返回该元素的值。
除了这两个基本操作外,堆栈还可以支持其他常用操作,例如:
- 栈顶(top):获取堆栈的顶部元素,但不移除它。
- 判空(isEmpty):检查堆栈是否为空。
- 获取大小(size):获取堆栈中元素的数量。
实际上,堆栈可以通过数组或链表来实现。
使用数组实现的堆栈称为顺序堆栈(array-based stack)。在顺序堆栈中,数组的末尾被用作栈顶,每次入栈操作都会将元素放置在数组末尾,而出栈操作则会从数组末尾移除元素。

使用链表实现的堆栈称为链式堆栈(linked stack)。在链式堆栈中,每个节点包含一个元素和一个指向下一个节点的引用。入栈操作将在链表头部插入新节点,而出栈操作则会移除链表头部的节点。
堆栈在计算机科学中有广泛的应用。例如,在编程中,堆栈常用于函数调用的过程中,每当一个函数被调用时,其相关信息(如参数、局部变量等)都会被压入堆栈中,当函数执行完毕后,这些信息又会被弹出堆栈。这种方式使得程序可以追踪函数的嵌套调用,并正确恢复执行状态。
堆栈还被用于解决许多其他问题,如括号匹配、表达式求值、深度优先搜索算法、回溯算法等。其简单性和高效性使得堆栈成为一种重要的数据结构。
后缀表达式



堆栈的抽象数据描述
堆栈(stack)是一种抽象数据类型(ADT),用于描述具有后进先出(LIFO,Last In First Out)特性的数据结构。它定义了以下操作:
- 初始化(Initialize):创建一个空的堆栈。
- 入栈(Push):将一个新元素添加到堆栈的顶部。
- 出栈(Pop):从堆栈的顶部移除最上面的元素,并返回该元素的值。
- 栈顶(Top):获取堆栈的顶部元素,但不移除它。
- 判空(IsEmpty):检查堆栈是否为空。
- 获取大小(Size):获取堆栈中元素的数量。
这些操作定义了堆栈的基本行为和特点。使用这些操作,可以实现各种具体的堆栈实现,如基于数组或链表的实现。



[例] 如果三个字符按ABC顺序压入堆栈
? ABC的所有排列都可能
是出栈的序列吗?
? 可以产生CAB这样的序
列吗?
在递归的过程中,我们维护一个栈和一个指向原始字符序列的指针。如果当前栈顶元素与指针指向的元素相同,则可以将其出栈;否则,需要将指针指向的元素入栈。当原始字符序列中的所有元素都已经被入栈后,我们可以逐步将栈中的元素出栈,从而得到一种可能的出栈序列。
使用上述方法,我们可以得到所有可能的出栈序列。如果其中包含了以CAB为开头的序列,那么就说明CAB是一种可能的出栈序列。否则,就不能产生CAB这样的序列。
总结:按照ABC的顺序依次压入堆栈,其所有可能的出栈序列有6种,分别是ABC、ACB、BAC、BCA、CBA和CAB。因此,CAB是一种可能的出栈序列。
栈的顺序存储实现


#define MAXSIZE 100 // 定义栈的最大容量
typedef struct {
ElementType data[MAXSIZE]; // 用数组存储栈元素
int top; // 栈顶指针,指向当前栈顶元素的位置
} Stack;
// 初始化栈
void InitStack(Stack *S) {
S->top = -1; // 初始化栈顶指针为-1,表示空栈
}
// 判断栈是否为空
int IsEmpty(Stack *S) {
return (S->top == -1);
}
// 判断栈是否已满
int IsFull(Stack *S) {
return (S->top == MAXSIZE - 1);
}
// 入栈操作
void Push(Stack *S, ElementType item) {
if (IsFull(S)) {
printf("Stack is full. Cannot push element %d.\n", item);
} else {
S->data[++(S->top)] = item;
}
}
// 出栈操作
ElementType Pop(Stack *S) {
if (IsEmpty(S)) {
printf("Stack is empty. Cannot pop element.\n");
return ERROR; // ERROR可以是一个预定义的错误值
} else {
return S->data[(S->top)--];
}
}
// 获取栈顶元素
ElementType GetTop(Stack *S) {
if (IsEmpty(S)) {
printf("Stack is empty. No top element.\n");
return ERROR;
} else {
return S->data[S->top];
}
}

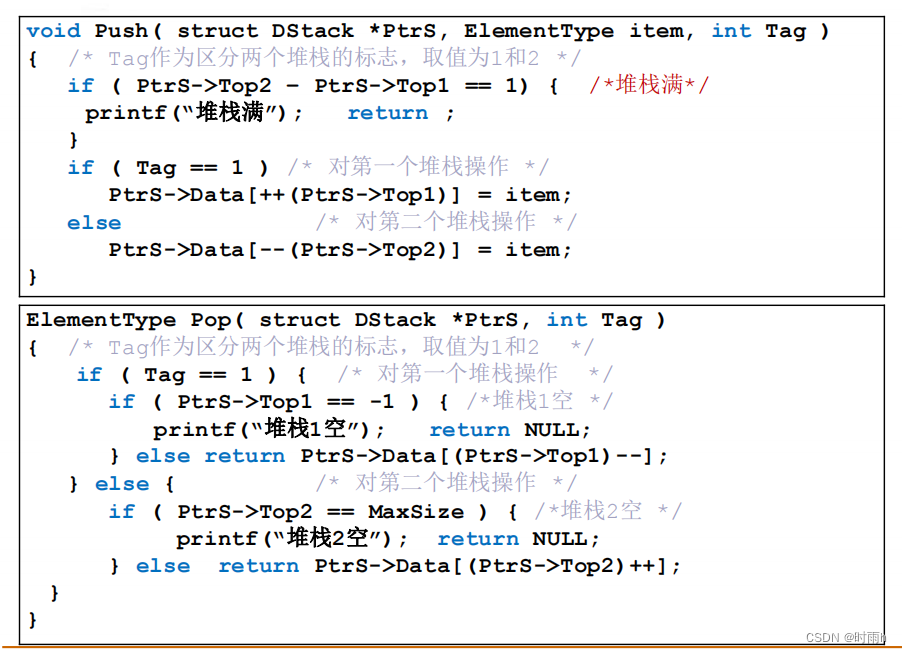
堆栈的链式存储实现
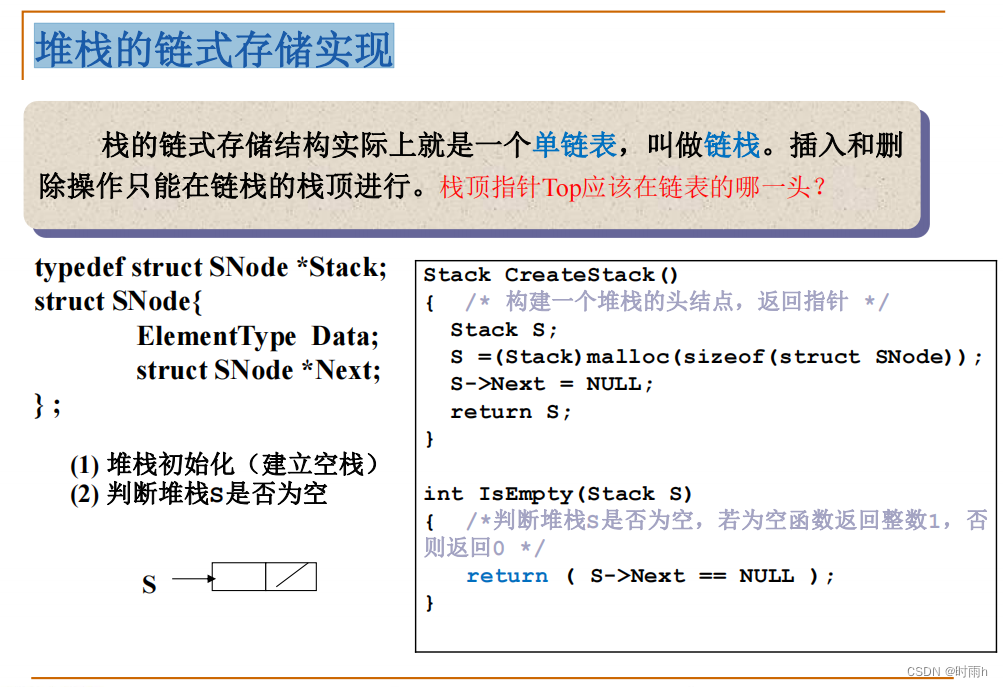
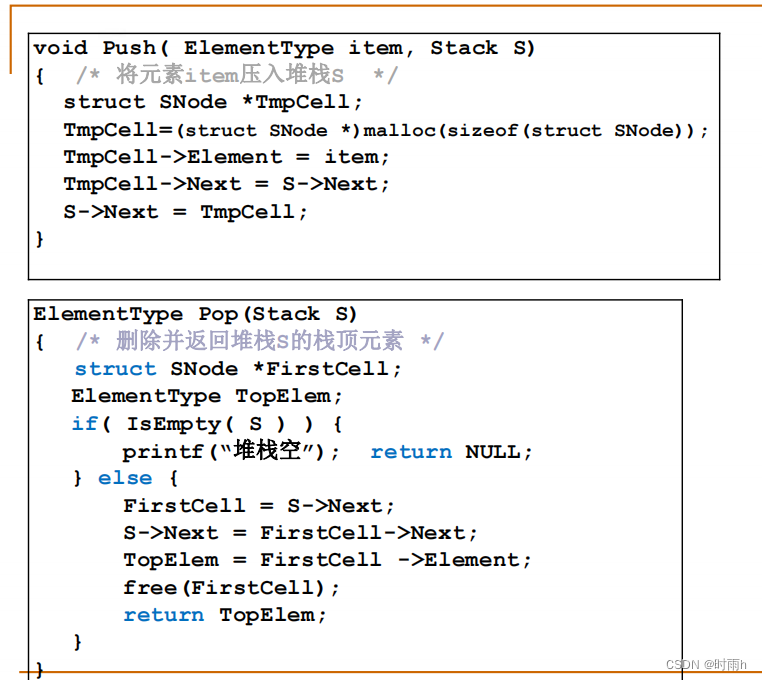
typedef struct StackNode {
ElementType data; // 数据域
struct StackNode *next; // 指针域,指向下一个节点
} StackNode;
typedef struct {
StackNode *top; // 栈顶指针,指向当前栈顶元素
} LinkedStack;
// 初始化栈
void InitStack(LinkedStack *S) {
S->top = NULL; // 初始化栈顶指针为空,表示空栈
}
// 判断栈是否为空
int IsEmpty(LinkedStack *S) {
return (S->top == NULL);
}
// 入栈操作
void Push(LinkedStack *S, ElementType item) {
StackNode *newNode = (StackNode *)malloc(sizeof(StackNode)); // 创建新节点
newNode->data = item; // 设置新节点的数据域为要入栈的元素
newNode->next = S->top; // 将新节点插入到栈顶
S->top = newNode; // 更新栈顶指针
}
// 出栈操作
ElementType Pop(LinkedStack *S) {
if (IsEmpty(S)) {
printf("Stack is empty. Cannot pop element.\n");
return ERROR; // ERROR可以是一个预定义的错误值
} else {
StackNode *temp = S->top; // 保存当前栈顶节点
ElementType item = temp->data; // 获取栈顶元素的值
S->top = temp->next; // 更新栈顶指针
free(temp); // 释放原栈顶节点
return item;
}
}
// 获取栈顶元素
ElementType GetTop(LinkedStack *S) {
if (IsEmpty(S)) {
printf("Stack is empty. No top element.\n");
return ERROR;
} else {
return S->top->data;
}
}
堆栈应用:表达式求值
当涉及到表达式求值时,我们可以考虑使用堆栈的应用。以下是一个更复杂的例子来演示如何使用堆栈进行中缀表达式的求值。
假设我们要求解的表达式为中缀表达式:(3 + 4) * 5 - 6 / 2
- 创建一个空栈和运算符优先级字典。
- 从左到右遍历中缀表达式中的每个元素。
- 如果当前元素是数字,则将其转换为整数并直接入栈。
- 如果当前元素是运算符,进行以下操作:
- 如果栈为空或者栈顶元素是左括号"(",则将当前运算符入栈。
- 如果栈不为空,并且当前运算符的优先级大于栈顶运算符的优先级,则将当前运算符入栈。
- 如果栈不为空,并且当前运算符的优先级小于等于栈顶运算符的优先级,则弹出栈顶运算符并进行计算,并将计算结果入栈。重复此步骤直到满足条件,然后将当前运算符入栈。
- 如果当前元素是右括号")“,则弹出栈顶运算符并进行计算,直到遇到左括号”(“。左括号”("从栈中弹出,但不进行计算。
- 当遍历完中缀表达式后,将栈中剩余的运算符依次弹出并进行计算。
- 栈中仅剩下一个元素,即为表达式的计算结果。
以下是对中缀表达式(3 + 4) * 5 - 6 / 2求值的具体步骤:
- 创建一个空栈和运算符优先级字典(加法和减法优先级为1,乘法和除法优先级为2)。
- 遍历到"(",将其入栈。
- 遍历到3,将其转换为整数并入栈。
- 遍历到"+“,栈顶是”(“,将”+"入栈。
- 遍历到4,将其转换为整数并入栈。
- 遍历到")“,弹出栈顶运算符”+"并进行计算,得到3+4=7,并将计算结果7入栈。
- 遍历到"“,栈顶元素是7,优先级大于”“,将”*"入栈。
- 遍历到5,将其转换为整数并入栈。
- 遍历到"-“,栈顶元素是”“,优先级小于等于”-“,弹出栈顶运算符”"并进行计算,得到7*5=35,并将计算结果35入栈。
- 遍历到6,将其转换为整数并入栈。
- 遍历到"/“,栈顶元素是6,优先级小于等于”/“,弹出栈顶运算符”/"并进行计算,得到6/2=3,并将计算结果3入栈。
- 遍历完中缀表达式后,栈中仅剩下一个元素35-3,即为表达式的计算结果。
因此,中缀表达式(3 + 4) * 5 - 6 / 2的值为32。
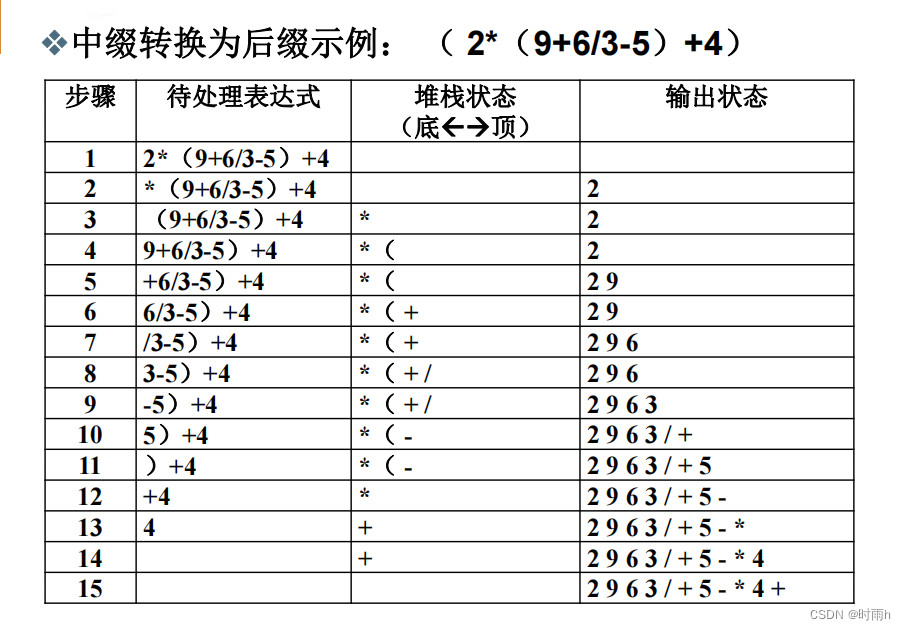
中缀表达式如何转换为后缀表达式
将中缀表达式转换为后缀表达式的一种常用方法是使用栈。
以下是转换过程的步骤:
- 创建一个空栈和一个空列表,用于存储后缀表达式。
- 从左到右遍历中缀表达式中的每个元素。
- 如果当前元素是数字或字母,则直接添加到后缀表达式列表的末尾。
- 如果当前元素是左括号"(",则将其入栈。
- 如果当前元素是右括号")“,则将栈中的元素弹出并添加到后缀表达式列表,直到遇到左括号”("。然后将左括号从栈中弹出,但不将其添加到后缀表达式列表中。
- 如果当前元素是运算符(如"+", “-”, “*”, "/"等),则进行以下操作:
- 如果栈为空,则将当前运算符入栈。
- 如果栈不为空,并且栈顶元素是左括号"(",则将当前运算符入栈。
- 如果栈不为空,并且当前运算符的优先级小于等于栈顶运算符的优先级,则将栈顶运算符弹出并添加到后缀表达式列表,重复此步骤直到满足条件,然后将当前运算符入栈。
- 如果栈不为空,并且当前运算符的优先级大于栈顶运算符的优先级,则将当前运算符入栈。
- 当遍历完中缀表达式后,将栈中剩余的运算符依次弹出并添加到后缀表达式列表。
- 后缀表达式列表即为转换后的后缀表达式。
以下是一个示例:
中缀表达式:2 + 3 * 4
转换过程:
- 遍历到2,直接添加到后缀表达式列表。
- 遍历到+,栈为空,将其入栈。
- 遍历到3,直接添加到后缀表达式列表。
- 遍历到*,栈不为空,栈顶是+,将*入栈。
- 遍历到4,直接添加到后缀表达式列表。
- 遍历完中缀表达式,将栈中剩余的运算符+和*依次弹出并添加到后缀表达式列表。
转换后的后缀表达式:2 3 4 * +
因此,中缀表达式2 + 3 * 4可以转换为后缀表达式2 3 4 * +。


队列
队列(Queue)是一种线性数据结构,它具有先进先出(FIFO)的特性。队列可以看作是一个有头有尾的队伍,新元素被添加到队尾,而删除元素则从队头进行。在队列中,数据元素的插入操作叫做入队(enqueue),删除操作则叫做出队(dequeue)。队列常用于操作系统调度、消息传递、任务处理等场景。
队列可以使用数组或者链表来实现。使用数组实现时,需要维护队头和队尾指针,以便快速进行入队和出队操作;使用链表实现时,则只需要维护队头和队尾节点即可。
在队列中,还有一些其他的操作,例如获取队头元素(peek)、判断队列是否为空(isEmpty)等。同时,队列还可以分为普通队列和优先级队列,后者可以根据元素的优先级来进行出队操作。


队列的基本操作

详细的队列操作如下:
- 初始化队列(initQueue):创建一个空队列,并进行必要的初始化工作,例如设置队头和队尾指针为 NULL。
void initQueue(Queue *q) {
q->front = q->rear = NULL;
}
- 入队操作(enqueue):将新元素插入到队列的队尾,使其成为新的队尾元素。
void enqueue(Queue *q, int data) {
Node *newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
if (q->front == NULL) { // 如果队列为空,新节点同时也成为队头节点
q->front = q->rear = newNode;
} else {
q->rear->next = newNode; // 将新节点插入到队尾
q->rear = newNode; // 更新队尾指针
}
}
- 出队操作(dequeue):删除队列的队头元素,并返回该元素的值。如果队列为空,则出队操作失败。
int dequeue(Queue *q) {
if (q->front == NULL) { // 如果队列为空,出队失败
printf("Queue is empty!\n");
return -1;
}
int data = q->front->data; // 获取队头元素的值
Node *temp = q->front;
q->front = temp->next; // 将队头指针指向下一个节点
free(temp); // 释放原队头节点的内存空间
if (q->front == NULL) { // 如果队列为空,更新队尾指针
q->rear = NULL;
}
return data;
}
- 获取队头元素(front):返回队列的队头元素的值,但不删除该元素。
int front(Queue *q) {
if (q->front == NULL) { // 如果队列为空,返回错误值
printf("Queue is empty!\n");
return -1;
}
return q->front->data; // 返回队头元素的值
}
- 判断队列是否为空(isEmpty):检查队列是否为空,即判断队列的队头指针是否为 NULL。
bool isEmpty(Queue *q) {
return (q->front == NULL); // 如果队头指针为空,则队列为空
}
- 清空队列(clearQueue):释放队列中所有节点的内存空间,并将队头和队尾指针设置为 NULL,使队列变为空队列。
void clearQueue(Queue *q) {
Node *temp;
while (q->front != NULL) {
temp = q->front;
q->front = temp->next;
free(temp);
}
q->rear = NULL; // 将队尾指针置为 NULL
}
这些是队列的详细操作,可以根据实际需求进行使用和扩展。注意,在使用完队列后,需要调用清空队列的函数来释放内存空间。
队列的存储结构

队列有两种常见的存储结构:数组(顺序队列)和链表(链式队列)。
- 数组实现的顺序队列:
顺序队列使用数组作为底层存储结构,通过数组的下标来表示元素在队列中的位置。需要两个指针,分别指向队头和队尾元素。队头指针指向队列的第一个元素,队尾指针指向队列最后一个元素的下一个位置。
优点:简单、易于实现和理解,占用连续的内存空间,访问元素方便。
缺点:如果队列长度不固定,会浪费一部分空间。
- 链表实现的链式队列:
链式队列使用链表作为底层存储结构,每个节点包含数据元素和指向下一个节点的指针。需要两个指针,分别指向队头和队尾节点。
优点:没有长度限制,可以动态地分配内存,节省空间。
缺点:访问元素时需要遍历链表,稍微复杂一些。
无论是顺序队列还是链式队列,它们都支持队列的基本操作,如入队、出队、获取队头元素、判断队列是否为空等。选择使用哪种存储结构取决于具体的需求和使用场景。
队列的假溢出
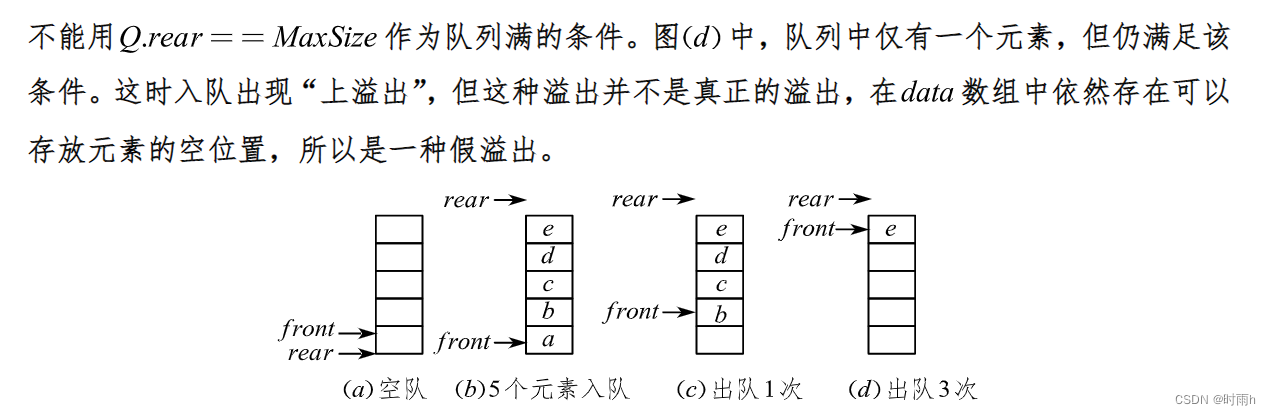
队列的假溢出(False Overflow)是指当队列未满时,仍然无法插入新元素的情况。这通常发生在使用数组实现的循环队列中,当队列尾指针 rear 指向数组的最后一个位置后,如果队头指针 front 也指向数组的最后一个位置,则队列被认为已满。
举个例子,假设有一个长度为5的循环队列,初始时 front = rear = 0,队列中已经存在3个元素。此时,队列的状态如下:
[1, 2, 3, _, _]
^ ^
front rear
如果此时要入队一个新元素,即使队列中还有空闲位置,也无法插入新元素,因为 rear 指针已经指向数组的最后一个位置,而 front 也指向了同样的位置,导致假溢出。
解决假溢出问题的方法是使用循环队列。当 rear 指针到达数组末尾时,将其重新指向数组的起始位置,使得队列能够循环利用数组空间。
在上述的例子中,如果要入队一个新元素,可以将 rear 指针从数组末尾位置移到数组起始位置,然后插入新元素:
[_, _, 3, 4, _]
^ ^
rear front
这样,假溢出的问题就得到了解决。循环队列的实现可以通过取模运算来实现,以保证 rear 和 front 指针始终在合法范围内。
循环队列

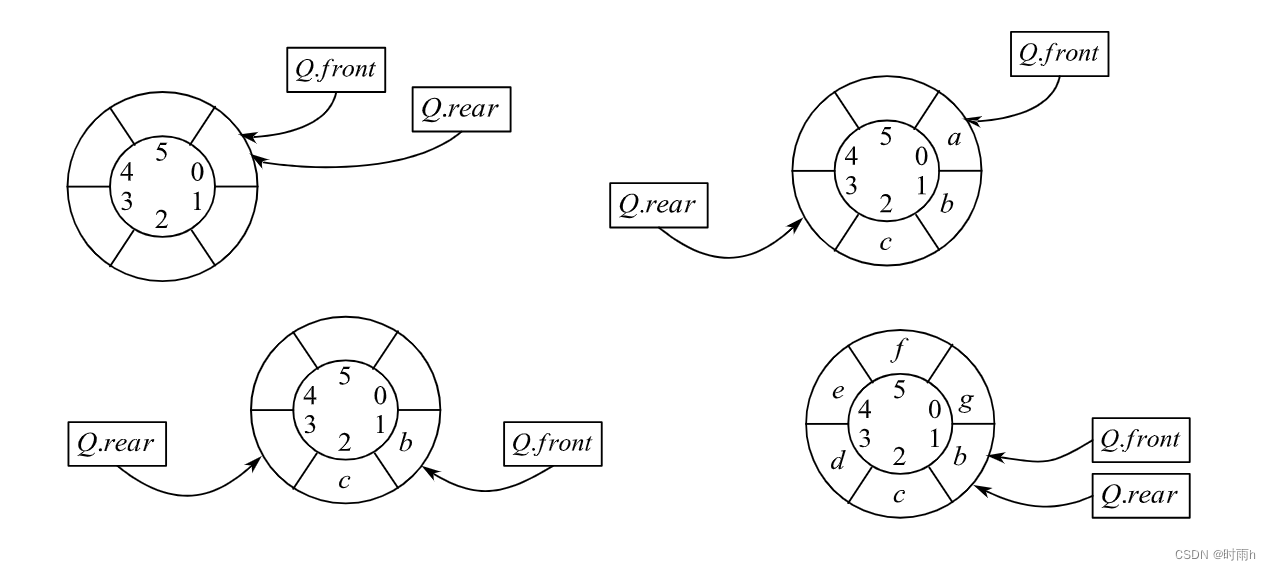

循环队列是一种使用数组实现的队列,通过循环利用数组的空间来解决假溢出的问题。循环队列的关键是要使用取模运算来计算队列的下标,以保证队列的循环性质。
循环队列通常由以下几个属性组成:
- 一个固定大小的数组,用于存储队列元素。
- 两个指针,分别指向队头和队尾元素在数组中的位置。
- 一个计数器,用于记录当前队列中元素的个数。
下面是循环队列的一些基本操作:
- 初始化队列(initQueue):创建一个空队列,并进行必要的初始化工作,例如设置队头和队尾指针为初始位置,计数器为零。
void initQueue(CircularQueue *q) {
q->front = 0;
q->rear = 0;
q->count = 0;
}
- 入队操作(enqueue):将新元素插入到队列的队尾,并更新队尾指针和计数器。
void enqueue(CircularQueue *q, int data) {
if (q->count == MAX_SIZE) { // 队列已满,无法插入新元素
printf("Queue is full!\n");
return;
}
q->data[q->rear] = data; // 插入新元素到队尾位置
q->rear = (q->rear + 1) % MAX_SIZE; // 更新队尾指针
q->count++; // 增加计数器
}
- 出队操作(dequeue):删除队列的队头元素,并返回该元素的值。如果队列为空,则出队操作失败。
int dequeue(CircularQueue *q) {
if (q->count == 0) { // 队列为空,无法删除元素
printf("Queue is empty!\n");
return -1;
}
int data = q->data[q->front]; // 获取队头元素的值
q->front = (q->front + 1) % MAX_SIZE; // 更新队头指针
q->count--; // 减少计数器
return data;
}
- 获取队头元素(front):返回队列的队头元素的值,但不删除该元素。
int front(CircularQueue *q) {
if (q->count == 0) { // 队列为空,返回错误值
printf("Queue is empty!\n");
return -1;
}
return q->data[q->front]; // 返回队头元素的值
}
- 判断队列是否为空(isEmpty):检查队列是否为空,即判断计数器是否为零。
bool isEmpty(CircularQueue *q) {
return (q->count == 0); // 如果计数器为零,则队列为空
}
循环队列的实现通过使用取模运算来循环利用数组空间,使得队列能够重复使用数组中的位置。这种实现方式可以有效地解决假溢出问题,并且在时间复杂度上具有较好的性能。
队伍的链式存储结构
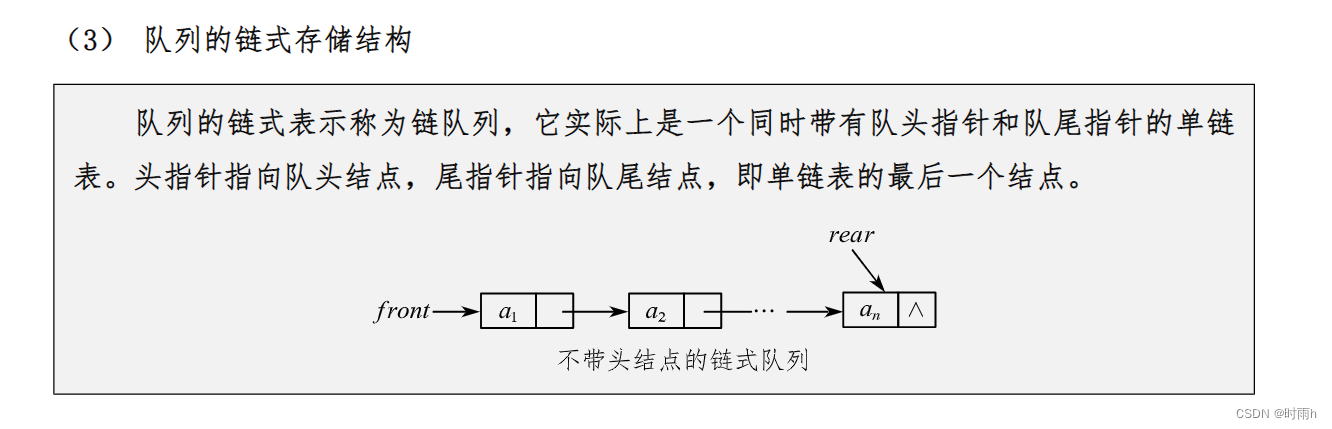
队列的链式存储结构使用链表来实现队列的基本操作。每个节点包含一个数据元素和一个指向下一个节点的指针。队列的头部指向链表的第一个节点,队列的尾部指向链表的最后一个节点。
链式存储结构的队列相比于数组实现的循环队列,具有更灵活的空间管理和动态扩展的能力。下面是队列链式存储结构的一些基本操作:
- 定义队列节点结构体:
typedef struct Node {
int data;
struct Node* next;
} Node;
- 初始化队列(initQueue):创建一个空队列,并进行必要的初始化工作,例如设置头部和尾部指针为空。
void initQueue(LinkedQueue* q) {
q->front = NULL;
q->rear = NULL;
}
- 入队操作(enqueue):创建一个新节点,并将其插入到队列的尾部。更新尾部指针。
void enqueue(LinkedQueue* q, int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
if (isEmpty(q)) { // 队列为空,更新头部指针
q->front = newNode;
} else { // 队列不为空,更新尾部指针
q->rear->next = newNode;
}
q->rear = newNode; // 更新尾部指针
}
- 出队操作(dequeue):删除队列的头部节点,并返回该节点的值。更新头部指针。
int dequeue(LinkedQueue* q) {
if (isEmpty(q)) { // 队列为空,出队操作失败
printf("Queue is empty!\n");
return -1;
}
Node* temp = q->front; // 保存头部节点
int data = temp->data; // 获取头部节点的值
q->front = q->front->next; // 更新头部指针
free(temp); // 释放头部节点的内存
if (isEmpty(q)) { // 队列为空,更新尾部指针
q->rear = NULL;
}
return data;
}
- 获取队头元素(front):返回队列的头部节点的值,但不删除该节点。
int front(LinkedQueue* q) {
if (isEmpty(q)) { // 队列为空,返回错误值
printf("Queue is empty!\n");
return -1;
}
return q->front->data; // 返回头部节点的值
}
- 判断队列是否为空(isEmpty):检查队列是否为空,即判断头部指针是否为空。
bool isEmpty(LinkedQueue* q) {
return (q->front == NULL);
}
需要注意的是,在使用链式存储结构的队列时,需要小心内存管理,确保在不需要的节点时进行及时的释放操作,以防止内存泄漏。
当使用链式存储结构实现队列时,可以根据需要进行进一步的扩展和优化。下面是一些可能的操作和注意事项:
-
判断队列是否已满(isFull):由于链式存储结构没有固定大小的限制,所以一般情况下不需要判断队列是否已满。但如果你想设置一个最大长度,可以通过计数器或者限制节点数量来判断队列是否已满。
-
清空队列(clearQueue):释放所有节点的内存,并将头部和尾部指针都置为空。
void clearQueue(LinkedQueue* q) {
while (!isEmpty(q)) {
dequeue(q);
}
// 重置头部和尾部指针
q->front = NULL;
q->rear = NULL;
}
- 遍历队列(traverseQueue):从队列的头部开始,依次访问每个节点的值。
void traverseQueue(LinkedQueue* q) {
if (isEmpty(q)) {
printf("Queue is empty!\n");
return;
}
Node* current = q->front;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
}
-
动态扩展队列:链式存储结构的队列天然具备动态扩展的能力。当队列需要存储更多元素时,只需创建新的节点并添加到尾部即可。这样可以避免数组存储结构中固定大小的限制。
-
内存管理:在使用链式存储结构时,需要注意及时释放不再需要的节点的内存,以防止内存泄漏。在出队操作时,需要释放被删除节点的内存。在清空队列或销毁队列时,需要释放所有节点的内存。
下面是一个完整的链式存储结构的队列示例(使用C语言实现):
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
typedef struct Node {
int data;
struct Node* next;
} Node;
typedef struct {
Node* front;
Node* rear;
} LinkedQueue;
void initQueue(LinkedQueue* q) {
q->front = NULL;
q->rear = NULL;
}
void enqueue(LinkedQueue* q, int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
if (isEmpty(q)) {
q->front = newNode;
} else {
q->rear->next = newNode;
}
q->rear = newNode;
}
int dequeue(LinkedQueue* q) {
if (isEmpty(q)) {
printf("Queue is empty!\n");
return -1;
}
Node* temp = q->front;
int data = temp->data;
q->front = q->front->next;
free(temp);
if (isEmpty(q)) {
q->rear = NULL;
}
return data;
}
int front(LinkedQueue* q) {
if (isEmpty(q)) {
printf("Queue is empty!\n");
return -1;
}
return q->front->data;
}
bool isEmpty(LinkedQueue* q) {
return (q->front == NULL);
}
void clearQueue(LinkedQueue* q) {
while (!isEmpty(q)) {
dequeue(q);
}
q->front = NULL;
q->rear = NULL;
}
void traverseQueue(LinkedQueue* q) {
if (isEmpty(q)) {
printf("Queue is empty!\n");
return;
}
Node* current = q->front;
while (current != NULL) {
printf("%d ", current->data);
current = current->next;
}
printf("\n");
}
int main() {
LinkedQueue queue;
initQueue(&queue);
enqueue(&queue, 1);
enqueue(&queue, 2);
enqueue(&queue, 3);
enqueue(&queue, 4);
printf("Front: %d\n", front(&queue));
traverseQueue(&queue);
dequeue(&queue);
dequeue(&queue);
printf("Front: %d\n", front(&queue));
traverseQueue(&queue);
clearQueue(&queue);
return 0;
}
串

在数据结构中,串是由零个或多个字符组成的有限序列。它是一种线性数据结构,常用于表示和处理文本、字符串等信息。
串的特点包括:
- 顺序性:串中的字符按照一定的先后顺序排列,每个字符都有一个唯一的位置。
- 有限性:串的长度是有限的,它由字符的个数决定。
- 可变性:串可以根据需要进行插入、删除和修改操作。
串的实现方式有多种,常见的有两种主要方式:
-
数组实现:使用字符数组来存储串的字符序列。通过定义一个固定大小的数组,将串中的字符依次存放在数组中,可以通过数组下标来访问和操作串中的字符。这种实现方式简单直观,但需要预先分配足够的内存空间,并且对于插入、删除等操作需要移动大量的字符,效率较低。
-
链表实现:使用链表结构来存储串的字符序列。每个节点包含一个字符和一个指向下一个节点的指针,通过将节点按顺序连接起来形成链表来表示串。这种实现方式不需要预先分配固定大小的内存空间,可以根据实际需要动态调整串的长度,插入、删除操作只需修改指针的指向,效率较高。
串的常见操作包括:
- 获取长度:获取串的字符个数。
- 判空:判断串是否为空。
- 比较:比较两个串是否相等或大小关系。
- 连接:将两个串连接成一个新的串。
- 子串:提取原串中的一部分作为子串。
- 查找:在串中查找指定字符或子串的位置。
- 插入、删除:在指定位置插入字符或删除字符。
串在实际应用中非常重要,常被用于文本处理、搜索引擎、编译器等领域。了解和熟练掌握串的相关知识对于编程和算法设计都非常有帮助。
串的基本操作

好的,我来详细介绍一下每一个字符串操作。
-
字符串初始化(String Initialization)
这个操作是将一个字符串常量或字符数组赋值给一个字符数组。可以用以下两种方式进行字符串初始化:char str[] = "Hello";或者
char str[6] = {'H', 'e', 'l', 'l', 'o', '\0'};在第一种方式中,字符串常量被自动转换为字符数组并复制到字符数组
str中。在第二种方式中,字符数组用字符常量的形式初始化,最后一个字符必须是空字符'\0',表示字符串的结尾。 -
字符串赋值(String Copy)
这个操作是将一个字符串复制到另一个字符串中。可以使用strcpy()函数进行字符串赋值:strcpy(dest, src);这里的
src是源字符串,dest是目标字符串。strcpy()函数会将src中的字符复制到dest中,直到遇到空字符'\0'为止。 -
字符串连接(String Concatenation)
这个操作是将一个字符串连接到另一个字符串的末尾。可以使用strcat()函数进行字符串连接:strcat(dest, src);这里的
src是源字符串,dest是目标字符串。strcat()函数会将src中的字符连接到dest的末尾,直到遇到空字符'\0'。 -
字符串长度(String Length)
这个操作是求一个字符串的长度。可以使用strlen()函数进行字符串长度计算:strlen(str);这里的
str是要计算长度的字符串。strlen()函数会返回str中的字符数,不包括空字符'\0'。 -
字符串比较(String Comparison)
这个操作是比较两个字符串是否相等。可以使用strcmp()函数进行字符串比较:strcmp(str1, str2);这里的
str1和str2是要比较的字符串。strcmp()函数会返回一个整数值,表示两个字符串的大小关系。如果str1大于str2,则返回一个正整数;如果str1小于str2,则返回一个负整数;如果两个字符串相等,则返回0。 -
字符串复制(String Copy with Length)
这个操作是将一个字符串的前n个字符复制到另一个字符串中。可以使用strncpy()函数进行字符串复制:strncpy(dest, src, n);这里的
src是源字符串,dest是目标字符串,n是要复制的字符数。strncpy()函数会将src中的前n个字符复制到dest中,如果src的字符数不足n,则在dest中填充空字符'\0'。 -
字符串查找(String Searching)
这个操作是在一个字符串中查找特定字符或子串。可以使用strchr()函数查找一个特定字符:strchr(str, ch);这里的
str是要查找的字符串,ch是要查找的字符。strchr()函数会返回一个指向第一个匹配字符的指针,如果未找到该字符,则返回NULL。
另外,如果要查找一个特定子串,可以使用strstr()函数:strstr(str, substr);这里的
str是要查找的字符串,substr是要查找的子串。strstr()函数会返回一个指向第一个匹配子串的指针,如果未找到该子串,则返回NULL。 -
字符串分割(String Tokenization)
这个操作是将一个字符串分割成多个子串。可以使用strtok()函数进行字符串分割:strtok(str, delimiters);这里的
str是要分割的字符串,delimiters是分割符字符串。strtok()函数会返回一个指向当前子串的指针,每次调用strtok()函数时,它都会返回下一个子串。可以使用NULL作为第一个参数来继续返回下一个子串,直到所有的子串都被遍历过。
2.串的简单模式匹配算法


串的简单模式匹配算法(也叫朴素模式匹配算法)是一种用来在一个文本串中查找一个模式串的算法。它的思想是从文本串的第一个字符开始,依次和模式串的每个字符进行比较,如果匹配成功,则继续比较下一个字符,否则将文本串向右移动一位,重新从文本串的下一个字符开始与模式串进行比较。
具体实现步骤如下:
- **从文本串的第一个字符开始,依次与模式串的第一个字符、第二个字符、第三个字符……进行比较。**替换
- 如果当前字符匹配成功,则继续比较下一个字符。
- 如果当前字符匹配失败,则将文本串向右移动一位,并从新的位置开始重新与模式串进行比较。
- 如果文本串已经被移动到了末尾,但是模式串还没有被完全匹配上,则说明匹配失败。
代码实现如下(以 C 语言为例):
int simpleMatch(char* text, char* pattern) {
int i,j;
int textLen = strlen(text);
int patternLen = strlen(pattern);
for (i = 0; i <= textLen - patternLen; i++) {
for (j = 0; j < patternLen; j++) {
if (text[i + j] != pattern[j]) break;
}
if (j == patternLen) return i;
}
return -1;
}
其中,text 表示文本串,pattern 表示模式串。函数返回第一次匹配成功的位置,如果没有匹配成功则返回 -1。
该算法的时间复杂度为 O ( n m ) O(nm) O(nm),其中 n n n 和 m m m 分别为文本串和模式串的长度。在最坏情况下,需要进行 n ? m + 1 n-m+1 n?m+1 次比较,因此该算法的效率并不高,但是在实际应用中,该算法可以作为其他更高效的字符串匹配算法的基础。
矩阵的压缩存储(》?)


矩阵的压缩存储是一种有效地存储稀疏矩阵(大部分元素为0)的方法,可以节省存储空间。常见的矩阵压缩存储方法有三种:行压缩存储、列压缩存储和坐标压缩存储。
-
行压缩存储(Compressed Row Storage, CRS):
在行压缩存储中,矩阵的非零元素按行存储,并且每一行的非零元素按照列索引的顺序排列。此外,还需要一个额外的数组记录每一行的起始位置和结束位置。这样,对于一个 m × n 的稀疏矩阵,需要三个数组来存储数据:val数组:保存非零元素的值。col_ind数组:保存非零元素所在的列索引。row_ptr数组:保存每一行的起始位置和结束位置的索引。
-
列压缩存储(Compressed Column Storage, CCS):
在列压缩存储中,矩阵的非零元素按列存储,并且每一列的非零元素按照行索引的顺序排列。与行压缩存储类似,需要三个数组来存储数据:val数组:保存非零元素的值。row_ind数组:保存非零元素所在的行索引。col_ptr数组:保存每一列的起始位置和结束位置的索引。
-
坐标压缩存储(Coordinate Storage, COO):
在坐标压缩存储中,可以简单地将每个非零元素的行号、列号和值存储在一个三元组中。因此,需要三个数组来存储数据:row_ind数组:保存非零元素的行号。col_ind数组:保存非零元素的列号。val数组:保存非零元素的值。
这些压缩存储方法适用于大部分元素为0的稀疏矩阵,可以显著减少存储空间的使用,并且在某些计算中可以提高计算效率。选择哪种压缩存储方法取决于具体应用场景和对存储和计算效率的需求。






当矩阵是稀疏矩阵(大部分元素为0)时,传统的二维数组存储方式会造成大量的存储空间浪费,而压缩存储方法可以有效地减少存储空间的使用。
-
行压缩存储(CRS):
在行压缩存储中,矩阵的非零元素按行存储,并且每一行的非零元素按照列索引的顺序排列。此外,还需要一个额外的数组记录每一行的起始位置和结束位置。例如,对于以下稀疏矩阵:1 0 0 0 0 0 2 0 3 4 0 5对应的行压缩存储如下:
val数组:[1, 2, 3, 4, 5],保存非零元素的值。col_ind数组:[0, 2, 0, 1, 3],保存非零元素所在的列索引。row_ptr数组:[0, 1, 3, 5],保存每一行的起始位置和结束位置的索引。
在行压缩存储中,对于第 i 行的元素,其非零元素的位置范围是
row_ptr[i]到row_ptr[i+1]-1。 -
列压缩存储(CCS):
在列压缩存储中,矩阵的非零元素按列存储,并且每一列的非零元素按照行索引的顺序排列。与行压缩存储类似,需要三个数组来存储数据。以同样的稀疏矩阵为例:val数组:[1, 3, 2, 4, 5],保存非零元素的值。row_ind数组:[0, 2, 0, 2, 2],保存非零元素所在的行索引。col_ptr数组:[0, 1, 2, 4, 5],保存每一列的起始位置和结束位置的索引。
在列压缩存储中,对于第 j 列的元素,其非零元素的位置范围是
col_ptr[j]到col_ptr[j+1]-1。 -
坐标压缩存储(COO):
在坐标压缩存储中,可以简单地将每个非零元素的行号、列号和值存储在一个三元组中。因此,需要三个数组来存储数据。以同样的稀疏矩阵为例:row_ind数组:[0, 2, 2, 0, 2],保存非零元素的行号。col_ind数组:[0, 2, 3, 0, 3],保存非零元素的列号。val数组:[1, 3, 5, 2, 4],保存非零元素的值。
在坐标压缩存储中,每个三元组表示一个非零元素的位置和值。
这些压缩存储方法对于稀疏矩阵的存储可以大大节省存储空间。同时,在进行稀疏矩阵的运算时,这些压缩存储方法也能够提高计算效率。选择哪种压缩存储方法取决于具体应用场景和对存储和计算效率的需求。
当处理稀疏矩阵时,选择适合的压缩存储方法可以提高存储效率和计算效率。下面是一些选择压缩存储方法的考虑因素:
-
稀疏度:稀疏度是指矩阵中非零元素占总元素数量的比例。如果矩阵非常稀疏,即非零元素很少,那么压缩存储方法可以更好地节省存储空间。行压缩存储和列压缩存储在稀疏度较高时表现较好。
-
存储需求:根据实际存储需求选择压缩存储方法。如果需要快速访问某一行或某一列的元素,行压缩存储和列压缩存储可能更合适。如果需要随机访问元素,坐标压缩存储可能更适用。
-
计算需求:根据对矩阵的操作和计算需求选择压缩存储方法。不同的压缩存储方法对于不同的矩阵运算操作(如矩阵乘法、矩阵加法等)具有不同的计算效率。通常情况下,行压缩存储和列压缩存储在矩阵乘法等操作中表现较好。
-
内存限制:考虑可用内存大小,选择适当的压缩存储方法。行压缩存储和列压缩存储通常需要额外的数组来存储索引信息,因此可能需要更多的内存空间。
需要注意的是,选择压缩存储方法时需要综合考虑上述因素,并根据具体应用场景进行权衡。不同的压缩存储方法在不同的情况下可能会有不同的性能表现。
树和二叉树
前驱 后继
树和二叉树都是常见的数据结构,用于组织和表示具有分层结构的数据。下面是它们的介绍:
-
树(Tree):
- 树是由节点(Node)组成的集合,每个节点可以有零个或多个子节点。
- 树的一个节点被称为根节点(Root),它没有父节点。
- 其他节点都有且只有一个父节点,形成父子关系。
- 除了根节点外,其他节点可以分为内部节点和叶节点(Leaf)。内部节点有至少一个子节点,而叶节点没有子节点。
- 节点之间的连接称为边(Edge)。
- 树的常见应用包括文件系统、组织结构、图算法等。
-
二叉树(Binary Tree):
- 二叉树是一种特殊的树结构,其中每个节点最多有两个子节点,分别称为左子节点和右子节点。
- 二叉树的子节点位置固定,不能超过两个。
- 二叉树可以为空,即不包含任何节点,或者是由根节点和左子树、右子树组成的。
- 二叉树的遍历方式包括前序遍历(先访问根节点,然后递归地访问左子树和右子树)、中序遍历(先递归地访问左子树,然后访问根节点,最后递归地访问右子树)和后序遍历(先递归地访问左子树和右子树,最后访问根节点)等。
二叉树是树的一种特殊情况,在很多应用中具有重要作用。它可以用于实现搜索和排序算法,例如二叉搜索树(Binary Search Tree);也可以用于构建表达式树、哈夫曼树等。树和二叉树在计算机科学中有广泛的应用,对于理解和解决各种问题都具有重要意义。
树的基本概念介绍
树是一种具有分层结构的数据结构,它由节点和边组成,每个节点可以有零个或多个子节点,除了根节点外,每个节点都有一个父节点。下面是树的一些基本概念:
-
根节点(Root):树的顶部节点,没有父节点。
-
内部节点(Internal Node):除了根节点和叶节点外,其他节点都是内部节点,即有至少一个子节点的节点。
-
叶节点(Leaf):没有子节点的节点,也称为终端节点。
-
子节点(Child):一个节点的直接下属节点。
-
父节点(Parent):一个节点的直接上级节点。
-
兄弟节点(Sibling):具有相同父节点的节点,即同级节点。
-
子树(Subtree):以一个节点为根节点,它的所有后代节点组成的树。
-
深度(Depth):根节点到某个节点的路径长度,根节点的深度为 0,其余节点深度为其父节点深度加 1。
-
高度(Height):从某个节点到它的最远叶节点的路径长度,叶节点的高度为 0,树的高度为根节点的高度。
-
层次(Level):根节点为第一层,其子节点为第二层,以此类推。
-
森林(Forest):由多棵树组成的集合。
树在计算机科学中有许多应用,例如解析表达式、查找和排序数据、构建文件系统和数据库等。了解树的基本概念可以帮助我们更好地理解它们的实现和应用。
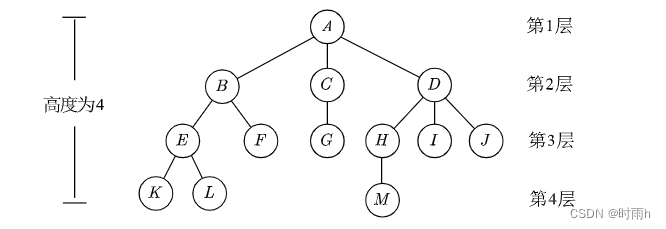



二叉树
二叉树是一种特殊的树结构,其中每个节点最多有两个子节点,分别称为左子节点和右子节点。以下是二叉树的一些基本概念:
-
根节点(Root):二叉树的顶部节点,没有父节点。
-
内部节点(Internal Node):除了根节点外,其他节点都是内部节点,即有至少一个子节点的节点。
-
叶节点(Leaf):没有子节点的节点,也称为终端节点。
-
子节点(Child):一个节点的直接下属节点。
-
父节点(Parent):一个节点的直接上级节点。
-
兄弟节点(Sibling):具有相同父节点的节点,即同级节点。
-
左子节点和右子节点:一个节点的直接下属节点,分别称为左子节点和右子节点。
-
子树(Subtree):以一个节点为根节点,它的所有后代节点组成的二叉树。
-
二叉树的属性:
- 对于每个节点,最多有两个子节点。
- 左子节点和右子节点的顺序是固定的,左边的子节点先于右边的子节点。
- 二叉树可以为空,即不包含任何节点。
-
二叉树的遍历方式:
- 前序遍历(Preorder Traversal):先访问根节点,然后递归地访问左子树和右子树。
- 中序遍历(Inorder Traversal):先递归地访问左子树,然后访问根节点,最后递归地访问右子树。
- 后序遍历(Postorder Traversal):先递归地访问左子树和右子树,最后访问根节点。
二叉树在计算机科学中具有广泛的应用,例如二叉搜索树、哈夫曼树、表达式树等。它们对于表示和操作数据以及解决各种问题都非常重要。
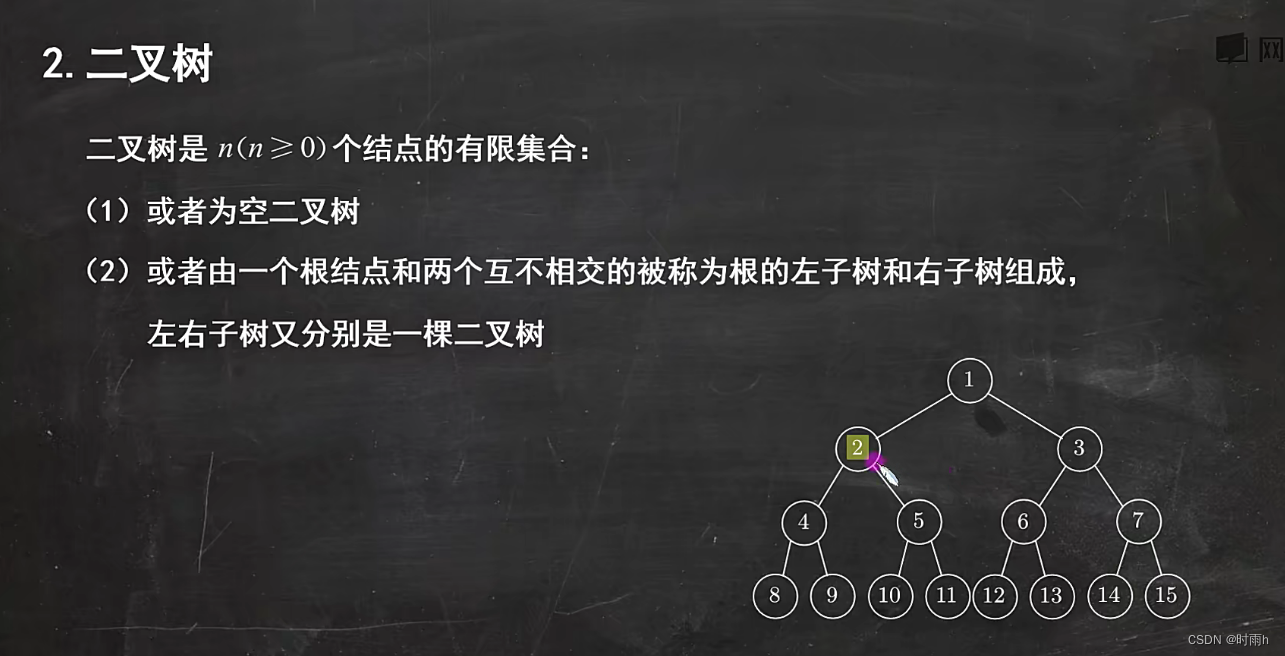
几个特殊的二叉树
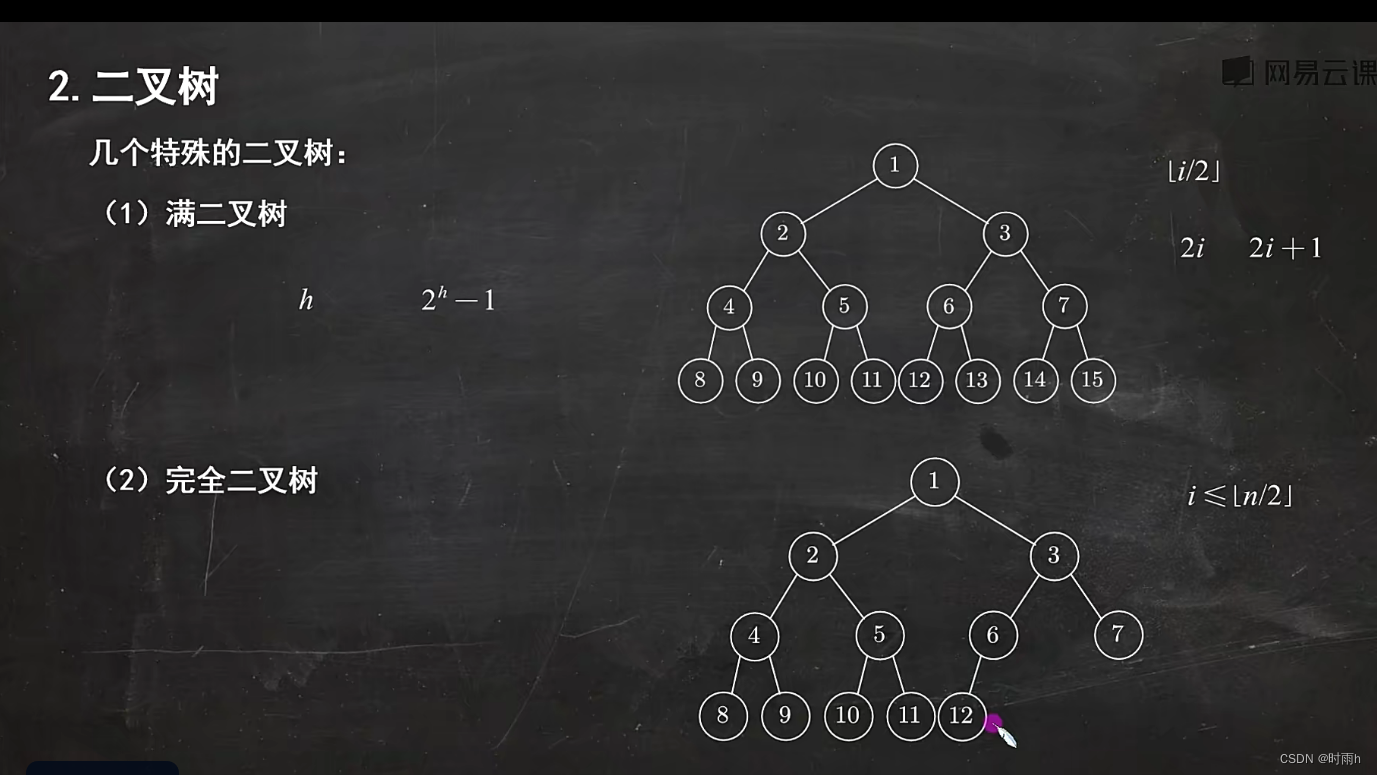
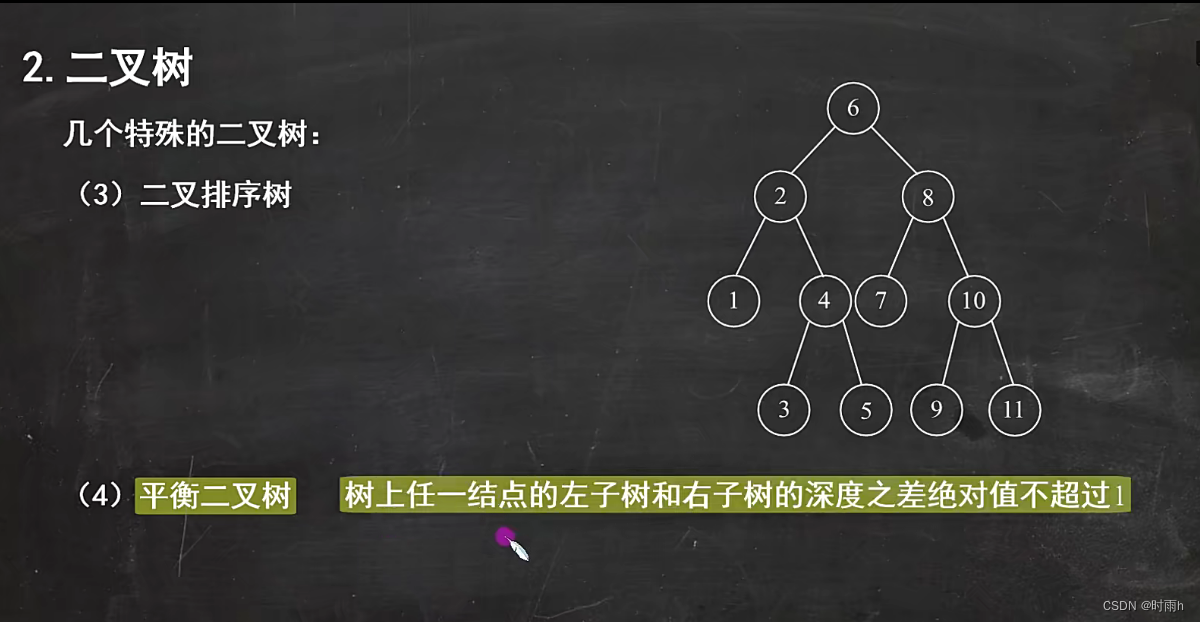
二叉树的性质

二叉树是一种常见的数据结构,它由节点组成,每个节点最多有两个子节点(左子节点和右子节点)。以下是二叉树的一些性质:
-
根节点:二叉树的顶部节点称为根节点。它是树的起始点,没有父节点。
-
子节点:一个节点的直接下级节点称为其子节点。一个节点最多可以有两个子节点,分别为左子节点和右子节点。
-
叶子节点:没有子节点的节点称为叶子节点,也称为终端节点。
-
父节点:一个节点的直接上级节点称为其父节点。
-
兄弟节点:具有相同父节点的节点称为兄弟节点。
-
深度:节点到根节点的层数称为深度。根节点的深度为0,其子节点的深度为1,依次递增。
-
高度:节点到叶子节点的最长路径的边数称为高度。叶子节点的高度为0,根节点的高度为树的高度。
-
路径:从一个节点到另一个节点的通路称为路径。
-
层次遍历:按照从上到下、从左到右的顺序遍历二叉树的节点。
-
前序遍历:先访问根节点,然后递归地遍历左子树和右子树。
-
中序遍历:先递归地遍历左子树,然后访问根节点,最后递归地遍历右子树。
-
后序遍历:先递归地遍历左子树和右子树,最后访问根节点。
这些性质是二叉树的一些基本概念和遍历方式,可以帮助我们理解和操作二叉树数据结构。

二叉树的存储结构
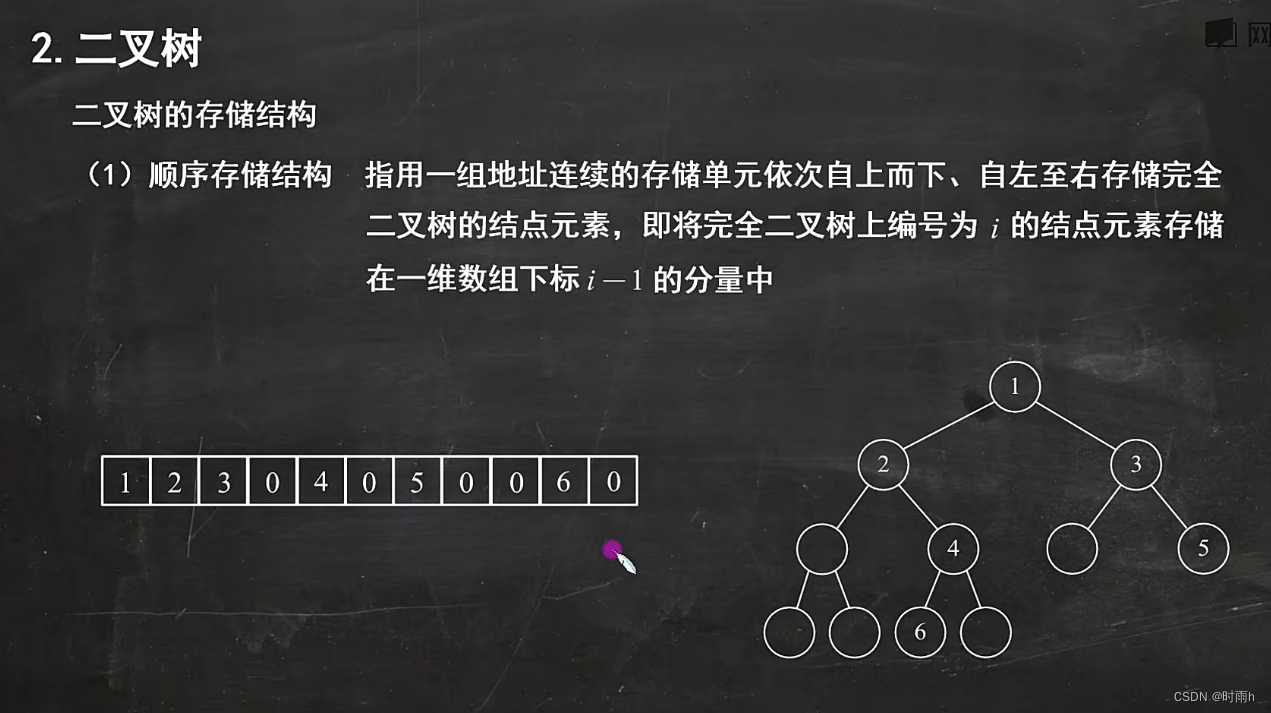

二叉树的存储结构有两种常见的方式:顺序存储和链式存储。
-
顺序存储:
在顺序存储结构中,可以使用数组来表示二叉树。通常按照完全二叉树的形式进行存储,即从上到下、从左到右依次存储节点。具体描述如下:// 定义二叉树节点 struct TreeNode { int data; struct TreeNode* left; struct TreeNode* right; }; // 定义顺序存储结构 struct SeqBinaryTree { struct TreeNode** nodes; int capacity; int size; };在初始化二叉树时,需要为顺序存储结构分配足够的空间,并将二叉树的节点指针存储在对应的位置上。
注意:由于顺序存储结构要求按照完全二叉树的形式存储节点,因此在实际使用中可能会浪费一部分空间。
-
链式存储:
在链式存储结构中,通过定义节点结构体,利用指针来表示二叉树节点之间的关系。具体描述如下:// 定义二叉树节点 struct TreeNode { int data; struct TreeNode* left; struct TreeNode* right; };在链式存储结构中,每个节点包含了数据以及指向左子树和右子树的指针。通过指针的链接,可以形成完整的二叉树结构。
-
双亲孩子表示法:
在双亲孩子表示法中,每个节点除了包含数据和指向左右子节点的指针外,还包含一个指向父节点的指针。具体描述如下:// 定义二叉树节点 struct TreeNode { int data; struct TreeNode* parent; struct TreeNode* left; struct TreeNode* right; };这种表示法可以方便地通过父节点指针访问节点的父节点,但相应地增加了空间的开销。
-
孩子兄弟表示法:
在孩子兄弟表示法中,每个节点包含了数据以及指向第一个孩子节点和右兄弟节点的指针。具体描述如下:// 定义二叉树节点 struct TreeNode { int data; struct TreeNode* firstChild; struct TreeNode* nextSibling; };这种表示法适用于任意多叉树,通过孩子节点和兄弟节点的链接,可以形成复杂的树结构。
除了以上介绍的存储结构,还有其他一些衍生的存储结构,如线索二叉树、哈夫曼树等。具体选择哪种存储结构,取决于对二叉树操作的需求和空间效率的考量。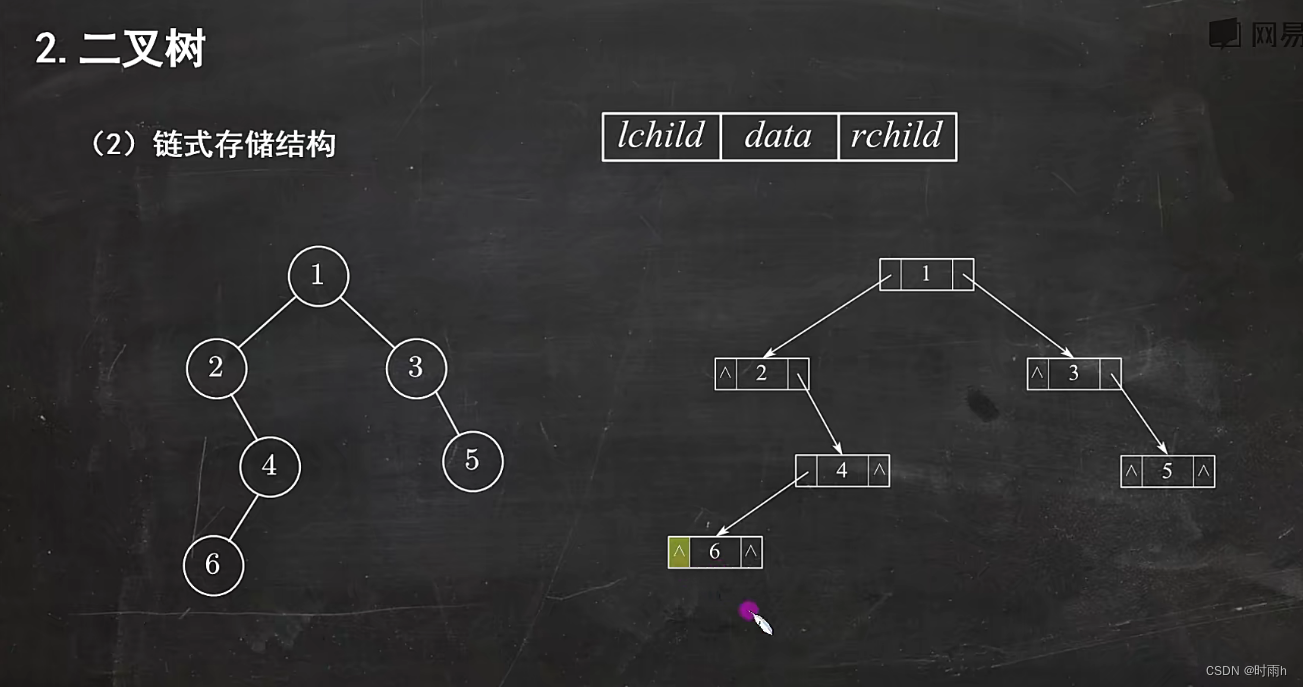
二叉树的遍历



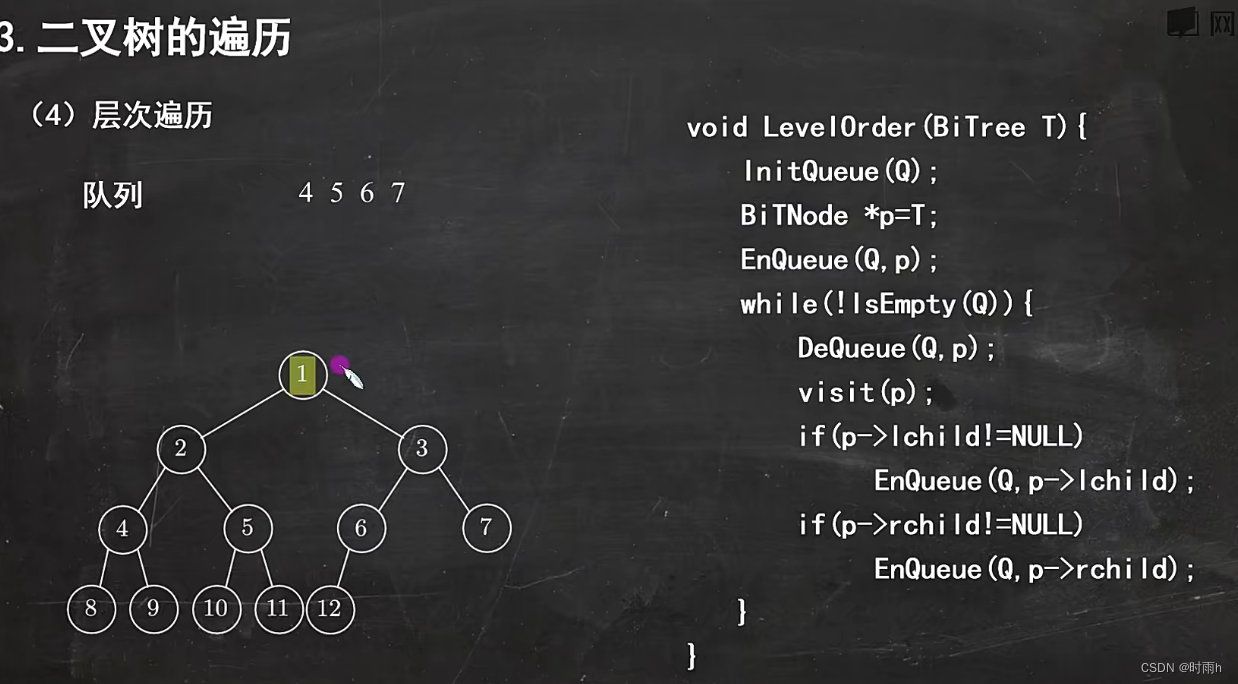
在二叉树中,遍历是指按照一定的顺序访问所有节点,包括遍历所有根节点、遍历所有左子树和遍历所有右子树。常见的二叉树遍历方式有三种:前序遍历、中序遍历和后序遍历。
-
前序遍历:
在前序遍历中,先访问当前节点,然后遍历左子树,最后遍历右子树。具体实现如下:void preOrderTraversal(struct TreeNode* root) { if (root == NULL) { return; } printf("%d ", root->data); // 访问当前节点 preOrderTraversal(root->left); // 遍历左子树 preOrderTraversal(root->right); // 遍历右子树 } -
中序遍历:
在中序遍历中,先遍历左子树,然后访问当前节点,最后遍历右子树。具体实现如下:void inOrderTraversal(struct TreeNode* root) { if (root == NULL) { return; } inOrderTraversal(root->left); // 遍历左子树 printf("%d ", root->data); // 访问当前节点 inOrderTraversal(root->right); // 遍历右子树 } -
后序遍历:
在后序遍历中,先遍历左子树,然后遍历右子树,最后访问当前节点。具体实现如下:void postOrderTraversal(struct TreeNode* root) { if (root == NULL) { return; } postOrderTraversal(root->left); // 遍历左子树 postOrderTraversal(root->right); // 遍历右子树 printf("%d ", root->data); // 访问当前节点 }
以上是常见的三种二叉树遍历方式。在实际使用中,可以根据需要进行适当的修改和扩展,例如增加层序遍历等其他遍历方式。

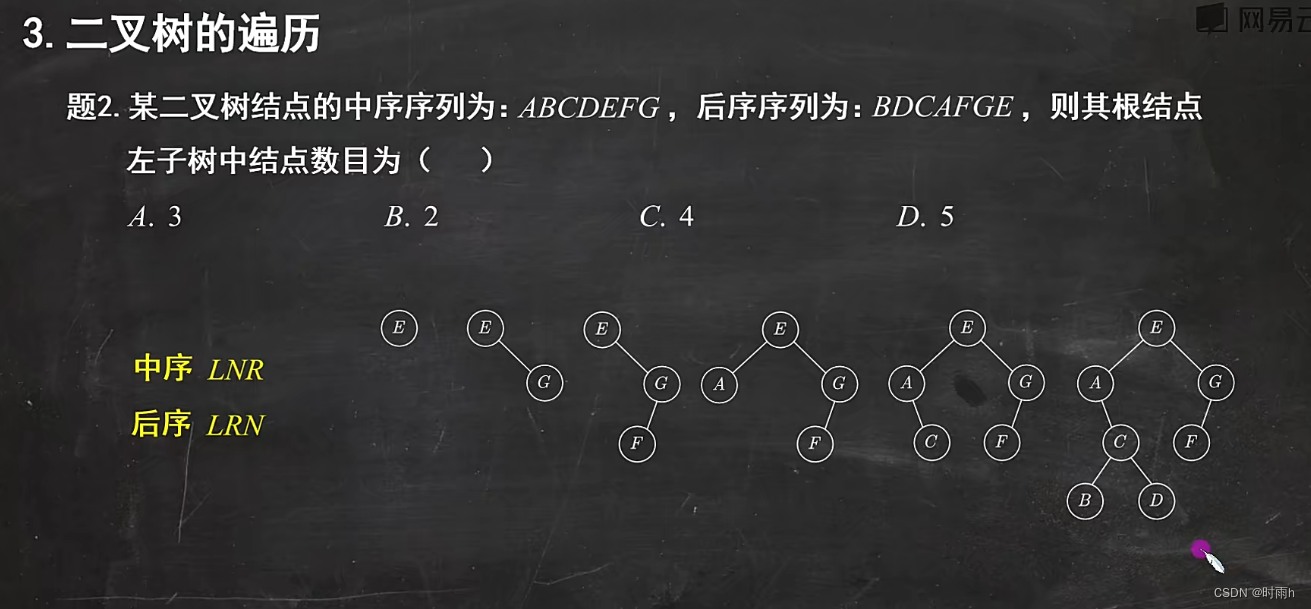

二叉树的先序序列和后序序列,无法唯一确定一棵二叉树
二叉树的先序序列和后序序列无法唯一确定一棵二叉树。这是因为在先序序列和后序序列中,只有节点的相对顺序,而没有直接的线索可以确定每个节点的父节点和子节点之间的关系。
例如,考虑以下两棵二叉树:
1 1
/ \ / \
2 3 2 3
/ \
4 4
这两棵二叉树的先序序列和后序序列都是不同的。第一棵二叉树的先序序列是 [1, 2, 3, 4],后序序列是 [2, 4, 3, 1];而第二棵二叉树的先序序列是 [1, 2, 3, 4],后序序列是 [2, 4, 3, 1]。可以看到,它们的先序序列和后序序列是相同的,但它们的结构是不同的。
因此,要唯一确定一棵二叉树,需要额外的信息,例如中序序列或者节点之间的连接方式。通常情况下,我们会使用先序序列和中序序列或者中序序列和后序序列来唯一确定一棵二叉树。
使用中序序列可以唯一确定一棵二叉树的原因是,中序遍历是一种按照节点值从小到大的顺序进行遍历的方式,每个节点的左子树都包含比它小的节点,右子树都包含比它大的节点。因此,在中序序列中,当前节点的左侧所有节点都应该是其左子树中的节点,右侧所有节点都应该是其右子树中的节点。这样,我们就可以通过先序序列和中序序列确定根节点,然后通过递归的方式确定左子树和右子树。
以一个例子来说明。
假设有如下一棵二叉树:
5
/ \
3 7
/ \ \
1 4 9
它的先序序列为 [5, 3, 1, 4, 7, 9],中序序列为 [1, 3, 4, 5, 7, 9]。
根据先序序列,我们知道根节点是 5。然后,在中序序列中找到 5 的位置,可以知道左子树的中序序列为 [1, 3, 4],右子树的中序序列为 [7, 9]。接下来,我们递归的求解左子树和右子树。对于左子树,它的先序序列为 [3, 1, 4],中序序列为 [1, 3, 4];对于右子树,它的先序序列为 [7, 9],中序序列为 [7, 9]。我们可以通过递归的方式构建这棵二叉树。
使用后序序列来唯一确定一棵二叉树的原理类似。后序序列是指在遍历二叉树时,先遍历左子树和右子树,最后遍历根节点。因此,在后序序列中,每个节点的左右子树都已经被访问完毕,我们可以通过这个性质从后往前递推出每个节点的左右子树的范围,然后递归的方式构造二叉树。
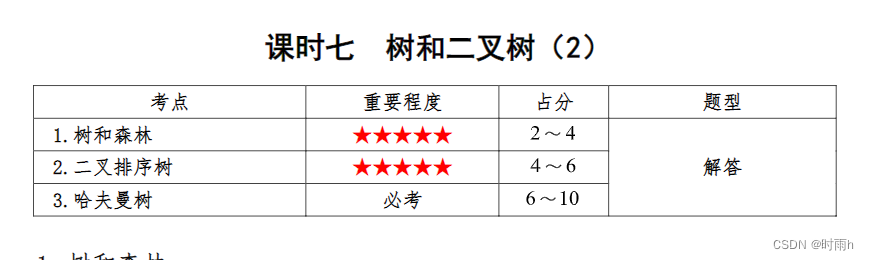
将树转换成二叉树

将一棵树转换成二叉树可以有多种方法,这里介绍一种常见的方法,即将每个节点的孩子节点按照从左到右的顺序连接起来。
假设我们有以下一棵树:
A
/ \
B C
/ \ \
D E F
我们可以将它转换成以下的二叉树:
A
/
B
/ \
D E
\
C
\
F
转换的步骤如下:
- 对于每个节点,将其第一个孩子作为其左孩子,并将其兄弟节点作为其右孩子。
- 对于每个节点的右孩子,将其右孩子的兄弟节点作为它的右孩子的右孩子,以此类推。
具体操作如下:
- 对于节点 A,将 B 作为其左孩子,C 作为其右孩子。
- 对于节点 B,将 D 作为其左孩子,E 作为其右孩子。
- 对于节点 C,将 F 作为其右孩子。
- 对于节点 E,将 C 作为其右孩子。
- 对于节点 F,没有孩子节点。
按照以上操作,我们就成功地将一棵树转换成了二叉树。
需要注意的是,转换后的二叉树可能不是二叉搜索树或平衡二叉树等特殊类型的二叉树,它只是将树的结构改造成了二叉树的形式。转换后的二叉树的遍历顺序可能与原树不同,所以在具体应用中可能需要根据情况进行相应的调整。
将森林转换成二叉树
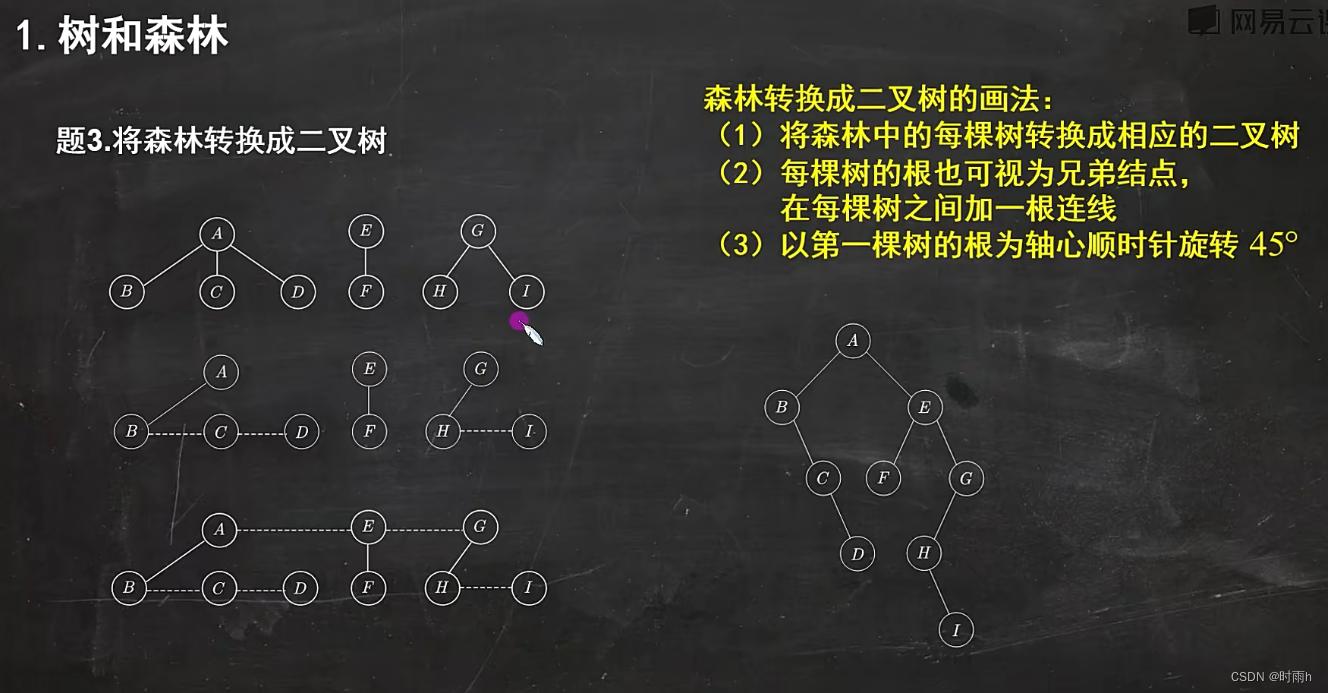
将一棵森林转换成二叉树的方法类似于将一棵树转换成二叉树,我们可以按照以下步骤进行转换:
- 对于每个有左兄弟的节点,将其左兄弟作为其左孩子,并将其右兄弟作为其右孩子。
- 对于每个没有左兄弟的节点,将其右兄弟作为其右孩子。
具体操作如下:
- 对于节点 A,将 B 作为其左孩子,C 作为其右孩子。
- 对于节点 B,将 D 作为其左孩子,E 作为其右孩子。
- 对于节点 F,将 G 作为其右孩子。
转换后的二叉树如下:
A
/ \
B C
/ \ \
D E F
/
G
需要注意的是,转换后的二叉树可能不是二叉搜索树或平衡二叉树等特殊类型的二叉树,它只是将森林的结构改造成了二叉树的形式。转换后的二叉树的遍历顺序可能与原森林不同,所以在具体应用中可能需要根据情况进行相应的调整。

二叉树转换成对应的森林

将一棵二叉树转换成对应的森林可以按照以下步骤进行:
- 对于每个节点,如果它有左孩子,则将其左孩子作为一个新的树。
- 对于每个节点,如果它有右孩子,则将其右孩子作为一个新的树,并将其父节点与右孩子之间的连接断开。
具体操作如下:
假设我们有以下的二叉树:
A
/ \
B C
/ \ \
D E F
/
G
我们可以将它转换成以下的森林:
A C F
/ \ \
B E G
/
D
转换的步骤如下:
- 对于节点 A,将其左孩子 B 作为一个新的树。
- 对于节点 B,将其左孩子 D 作为一个新的树。
- 对于节点 C,将其右孩子 F 作为一个新的树。
- 对于节点 F,将其左孩子 G 作为一个新的树。
按照以上操作,我们成功地将一棵二叉树转换成了对应的森林。
需要注意的是,转换后的森林中每个树的根节点可能不是原二叉树的根节点,而是二叉树中的某个节点。转换后的森林的遍历顺序可能与原二叉树不同,所以在具体应用中可能需要根据情况进行相应的调整。
树的遍历
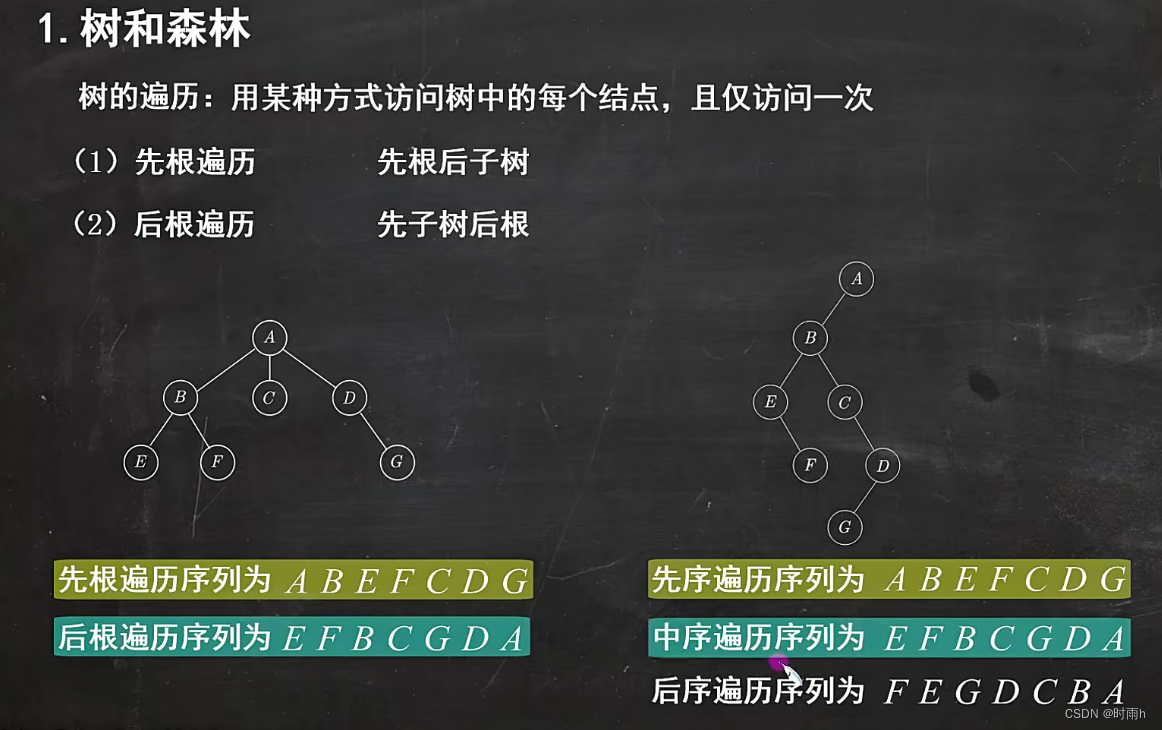
树的遍历是指按照一定规则访问树中的所有节点。常见的树的遍历方式有三种:前序遍历、中序遍历和后序遍历。下面我将逐一介绍这三种遍历方式的操作步骤:
-
前序遍历(Preorder Traversal):
- 访问根节点。
- 递归地前序遍历左子树。
- 递归地前序遍历右子树。
-
中序遍历(Inorder Traversal):
- 递归地中序遍历左子树。
- 访问根节点。
- 递归地中序遍历右子树。
-
后序遍历(Postorder Traversal):
- 递归地后序遍历左子树。
- 递归地后序遍历右子树。
- 访问根节点。
需要注意的是,以上是针对二叉树的遍历方式,对于多叉树或森林,你可以将其看作一组独立的子树,分别按照相应的遍历方式进行遍历。
以下是一个示例树的结构,我们以此来演示三种遍历方式:
A
/ \
B C
/ \ \
D E F
对应的遍历结果为:
- 前序遍历:A -> B -> D -> E -> C -> F
- 中序遍历:D -> B -> E -> A -> C -> F
- 后序遍历:D -> E -> B -> F -> C -> A
树的遍历方式可以根据实际需求进行选择,每种方式都有其特定的应用场景。
森林的遍历
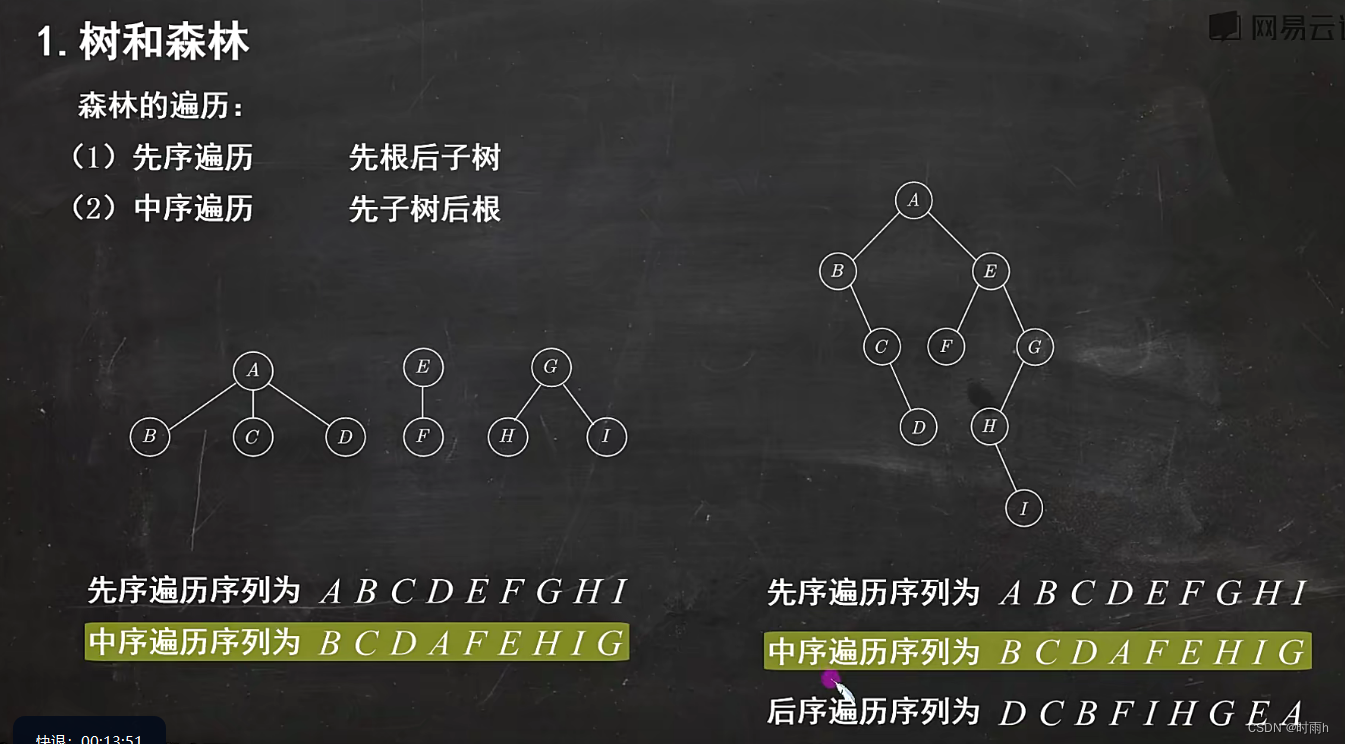
森林是由多个独立的树组成的集合。对于森林的遍历,我们可以将其看作对每个树分别进行遍历操作。
常见的森林遍历方式有三种:前序遍历、中序遍历和后序遍历。下面我将逐一介绍这三种遍历方式在森林中的操作步骤:
-
前序遍历(Preorder Traversal):
- 对于森林中的每棵树,先访问根节点。
- 递归地前序遍历树的所有子树。
-
中序遍历(Inorder Traversal):
- 对于森林中的每棵树,递归地中序遍历树的所有左子树。
- 访问根节点。
- 递归地中序遍历树的所有右子树。
-
后序遍历(Postorder Traversal):
- 对于森林中的每棵树,递归地后序遍历树的所有子树。
- 访问根节点。
需要注意的是,在森林遍历中,每棵树都是独立的,互不影响。因此,遍历顺序是先处理完一棵树,再处理下一棵树。
以下是一个示例森林的结构,由两棵树组成:
A D
/ \ / \
B C E F
对应的遍历结果为:
- 前序遍历:A -> B -> C -> D -> E -> F
- 中序遍历:B -> A -> C -> E -> D -> F
- 后序遍历:B -> C -> A -> E -> F -> D
通过对每棵树进行遍历操作,我们可以依次访问到森林中的所有节点。森林的遍历方式可以根据实际需求进行选择,每种方式都有其特定的应用场景。
二叉排序树

二叉排序树(Binary Search Tree,BST),也称为二叉搜索树或二叉查找树,是一种特殊的二叉树结构。它满足以下性质:
- 对于树中的每个节点n,其左子树的所有节点的值都小于n的值。
- 对于树中的每个节点n,其右子树的所有节点的值都大于n的值。
- 左子树和右子树都是二叉排序树。
这个性质保证了在二叉排序树中,每个节点的值都大于其左子树的所有节点的值,并且小于其右子树的所有节点的值。这使得在二叉排序树中进行查找、插入和删除操作都可以在平均情况下以O(log n)的时间复杂度完成。
以下是一个示例的二叉排序树:
6
/ \
2 8
/ \ / \
1 4 7 9
/ \
3 5
在这个二叉排序树中,每个节点的值都满足左小右大的关系。例如,节点2的左子树所有节点的值都小于2,节点4的左子树所有节点的值都小于4,节点8的右子树所有节点的值都大于8。
通过二叉排序树,我们可以很方便地进行查找、插入和删除等操作。例如,要查找值为3的节点,我们可以从根节点开始比较,由于3小于6,在根节点的左子树中继续查找;再由于3大于2,在2的右子树中继续查找;最终找到了值为3的节点。
需要注意的是,当二叉排序树中存在重复的值时,通常有多种可能的构建方式,因为相同的值可以放在左子树或右子树中。此外,如果二叉排序树不平衡(即左右子树的高度差过大),可能会导致查找效率下降,因此有一些平衡二叉排序树的变种,如红黑树和AVL树,用于提高性能。
当我们对二叉排序树进行操作时,可以执行以下几种常见的操作:
-
查找(Search):在二叉排序树中查找某个特定值。从根节点开始比较,根据比较结果决定是向左子树还是右子树搜索,直到找到目标值或搜索到空节点。
-
插入(Insert):向二叉排序树中插入一个新的节点。首先进行查找操作,找到插入位置的父节点,然后根据插入值与父节点值的大小关系,确定新节点应该插入到父节点的左侧还是右侧。
-
删除(Delete):删除二叉排序树中的某个节点。首先进行查找操作,找到待删除节点。删除节点时需要考虑不同情况:
- 若待删除节点为叶子节点(没有子节点),直接删除即可。
- 若待删除节点只有一个子节点,将其子节点替代待删除节点的位置。
- 若待删除节点有两个子节点,可以选择将其左子树的最大节点或右子树的最小节点替代待删除节点,保持二叉排序树的性质。
-
遍历(Traversal):按照特定的顺序访问二叉排序树中的所有节点。常见的遍历方式包括前序遍历、中序遍历和后序遍历。这些遍历方式在前面的回答中已经详细介绍过了。
对于二叉排序树的操作,需要注意保持树的性质不变。在插入和删除操作中,需要进行相应的调整,以确保新树仍然是一个有效的二叉排序树。
需要指出的是,二叉排序树的性能取决于树的结构是否平衡。如果树的不平衡程度过高,可能会导致操作的时间复杂度退化为线性复杂度,从而降低效率。因此,为了提高性能,可以使用一些平衡二叉排序树的数据结构,如红黑树、AVL树等。这些树结构可以自动调整节点的位置,以保持树的平衡性。
插入:比较插入值和根节点大小
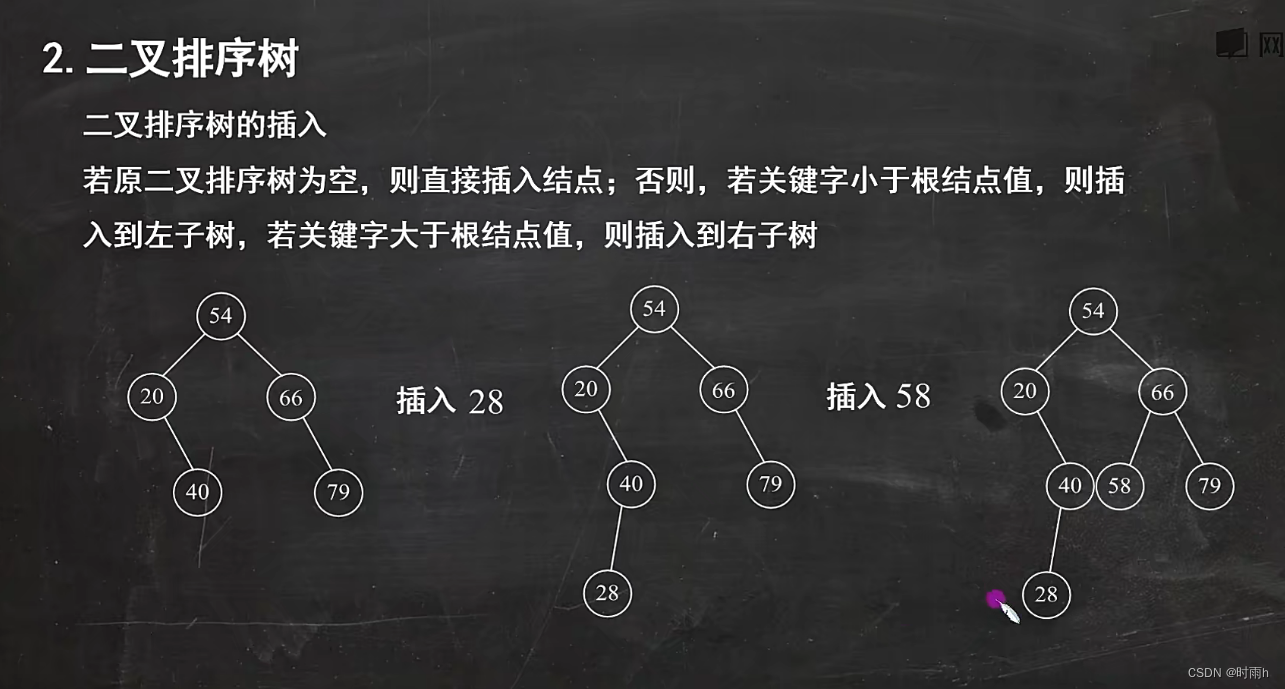
二叉排序树的构造
构造二叉排序树的基本思路是将元素逐个插入到树中。下面是一种常用的构造方法:
-
创建一个空的二叉排序树。
-
依次将元素插入到二叉排序树中:
- 如果树为空,则将第一个元素作为根节点。
- 如果树不为空,则从根节点开始比较待插入元素与当前节点的大小关系:
- 如果待插入元素小于当前节点的值,继续在左子树中插入。
- 如果待插入元素大于当前节点的值,继续在右子树中插入。
- 如果待插入元素等于当前节点的值,根据具体需求,可以将重复元素放在左子树或右子树中。
-
重复步骤2,直到所有元素都插入到二叉排序树中。
以下是一个示例的二叉排序树的构造过程:
假设有以下元素需要插入到二叉排序树中:7, 3, 9, 2, 1, 4, 8, 6, 5。
-
创建一个空的二叉排序树。
-
将第一个元素7作为根节点。
-
插入元素3:
- 3小于7,插入到7的左子树中。
-
插入元素9:
- 9大于7,插入到7的右子树中。
-
插入元素2:
- 2小于3,插入到3的左子树中。
-
插入元素1:
- 1小于2,插入到2的左子树中。
-
插入元素4:
- 4大于3,插入到3的右子树中。
-
插入元素8:
- 8大于7,插入到7的右子树中。
-
插入元素6:
- 6大于3,小于7,插入到7的左子树的右子树中。
-
插入元素5:
- 5大于3,小于6,插入到6的左子树中。
最终的二叉排序树如下所示:
7
/ \
3 9
/ \ /
2 4 8
/ \
1 6
/
5
通过以上步骤,我们成功地构造了一个二叉排序树。需要注意的是,由于二叉排序树的构造过程是依次插入元素,如果元素的插入顺序不同,最终构造出的二叉排序树可能会有所不同,但它们都满足二叉排序树的性质。

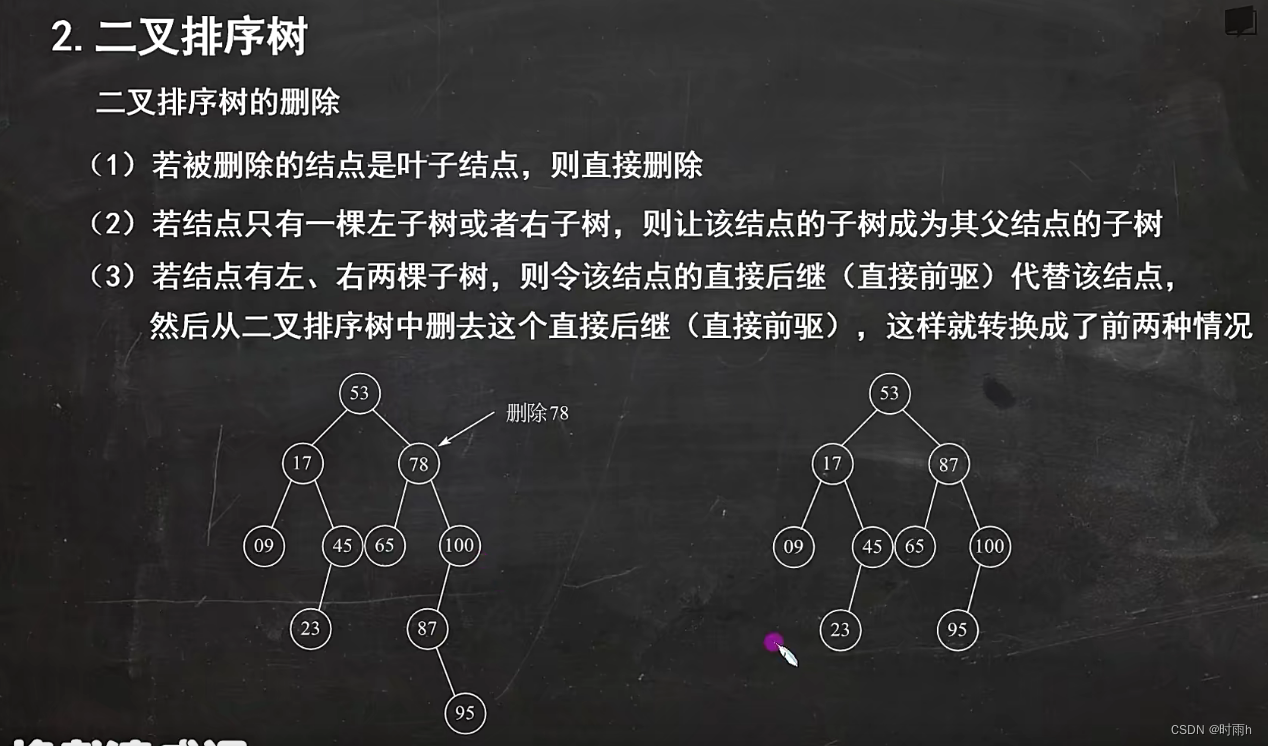
二叉排序树的删除
二叉排序树的删除操作需要考虑到三种情况:
-
待删除节点为叶子节点:直接删除即可。
-
待删除节点只有一个子节点:用其子节点代替待删除节点。
-
待删除节点有两个子节点:找到待删除节点的前驱或后继节点,用它来替代待删除节点。
下面分别介绍这三种情况的具体操作步骤。
1. 待删除节点为叶子节点
如果待删除节点为叶子节点,即没有左右子节点,那么直接将该节点从树中删除即可。
假设我们要删除节点5,如下图所示:
7
/ \
3 9
/ \ /
2 4 8
/ \
1 5
/
6
首先找到要删除的节点5,因为它是叶子节点,所以直接将它从树中删除。删除后,需要将节点5的父节点4的右子树指针置为空。
删除后的树结构如下图所示:
7
/ \
3 9
/ \ /
2 4 8
/
1
/
6
2. 待删除节点只有一个子节点
如果待删除节点只有一个子节点,那么可以直接用其子节点代替它。
以删除节点4为例,如下图所示:
7
/ \
3 9
/ \ /
2 4 8
/ \
1 5
/
6
首先找到要删除的节点4,因为它只有一个子节点5,所以将节点5代替节点4。注意,此时需要将节点5的左子树指针指向节点4的左子树,同时将节点5的父节点指针指向节点4的父节点。
删除后的树结构如下图所示:
7
/ \
3 9
/ \ /
2 5 8
/ \
1 6
3. 待删除节点有两个子节点
如果待删除节点有两个子节点,那么需要找到它的前驱或后继节点,用它来替代待删除节点。这里以使用前驱节点作为例子。
前驱节点是指比待删除节点小的最大节点。在二叉排序树中,前驱节点一定在待删除节点的左子树中。具体操作步骤如下:
-
在待删除节点的左子树中,找到最右侧的节点,即为前驱节点。
-
将前驱节点的值赋给待删除节点,并删除前驱节点。
以删除节点3为例,如下图所示:
7
/ \
3 9
/ \ /
2 4 8
/ \
1 5
/
6
首先找到要删除的节点3,因为它有两个子节点,需要找到它的前驱节点2。在节点3的左子树中,最右侧的节点就是节点2。将节点2的值赋给节点3,然后删除节点2,即可完成删除操作。
删除后的树结构如下图所示:
7
/ \
2 9
/ \ /
1 4 8
/ \
5 6
通过以上三种情况的操作,我们可以实现二叉排序树节点的删除。需要注意的是,在删除节点时,需要保证删除后的树仍然满足二叉排序树的性质。
哈夫曼树


哈夫曼树(Huffman Tree),又称最优树,是一种带权路径长度最短的树。在哈夫曼树中,每个叶子节点都有一个权值,每个非叶子节点的权值等于其左右子树权值之和,因此哈夫曼树是一棵带权树。
哈夫曼树应用广泛,特别是在数据压缩领域中。数据压缩就是将一个数据集合转换为另一个更小的数据集合,以便通过更少的存储空间或网络带宽来传输数据。哈夫曼树可以用来实现无损压缩,即将数据压缩为更小的数据集合,并且在解压缩时不会丢失原始数据。
构建哈夫曼树的过程如下:
-
将所有权值作为单独的节点,构造n棵只有根节点的二叉树。
-
在这n棵二叉树中,选取两棵根节点权值最小的树作为左右子树合并成一棵新树。新树的根节点权值为左右子树根节点权值之和。
-
将这个新树插入到原来的二叉树集合中。
-
重复步骤2和3,直到只剩下一棵二叉树,这棵二叉树即为哈夫曼树。
例如,给定下面的权值数组:
[5, 6, 7, 8, 9]
首先,将这些权值构造成5棵只有根节点的二叉树,如下所示:
5 6 7 8 9
| | | |
| | | |
+ + + +
| | | |
| | | |
null null null null
选取两个根节点权值最小的二叉树进行合并,得到一棵新的二叉树,其根节点权值为5+6=11,如下所示:
11
/ \
5 6
再将这棵新树插入到原来的二叉树集合中,得到4棵二叉树,如下所示:
7 8 9 11
/ \ / \ / \ / \
5 6 5 6 5 6 7 8
| | |
| | |
null null 9
重复以上步骤,直到只剩下一棵二叉树,即可得到哈夫曼树,如下所示:
36
/ \
16 20
/ \
7 9
/ \ / \
3 4 5 4
在哈夫曼树中,叶子节点代表原始数据中的符号,非叶子节点代表两个或更多符号的组合。哈夫曼编码就是将每个符号映射到其所对应的叶子节点路径上的二进制编码。哈夫曼编码的特点是:任何一个符号的编码都不是另一个符号编码的前缀,因此可以通过哈夫曼编码实现无损压缩。

当我们有一个已经构建好的哈夫曼树后,可以利用它进行数据的压缩和解压缩。
首先,我们需要通过遍历哈夫曼树来构建每个字符对应的哈夫曼编码。在遍历过程中,左子树路径上的编码为0,右子树路径上的编码为1。当遍历到叶子节点时,就可以得到该字符对应的哈夫曼编码。
例如,在上面给出的哈夫曼树中,假设字符’A’对应的叶子节点路径为左-左-左(编码为000),字符’B’对应的叶子节点路径为左-左-右(编码为001),以此类推。
在进行数据压缩时,我们可以将原始数据中的字符替换为其对应的哈夫曼编码。这样,相同的字符在压缩后会占用更少的空间,从而实现了数据的压缩。
例如,如果原始数据是"ABACD",对应的哈夫曼编码为"0000010001010100",压缩后的数据只需占用16位空间。
在进行数据解压缩时,我们需要借助哈夫曼树来根据压缩后的编码逐步还原出原始数据。从根节点开始,根据压缩数据的每一位编码,依次遍历哈夫曼树。当遇到叶子节点时,就找到了对应的字符,可以将其输出,并回到根节点继续下一位编码的解析。
例如,对于压缩后的数据"0000010001010100",我们可以根据哈夫曼树还原出原始数据"ABACD"。
总结一下,哈夫曼树是一种带权路径长度最短的树,常用于数据压缩中。通过构建哈夫曼树和生成哈夫曼编码,我们可以实现数据的无损压缩和解压缩。
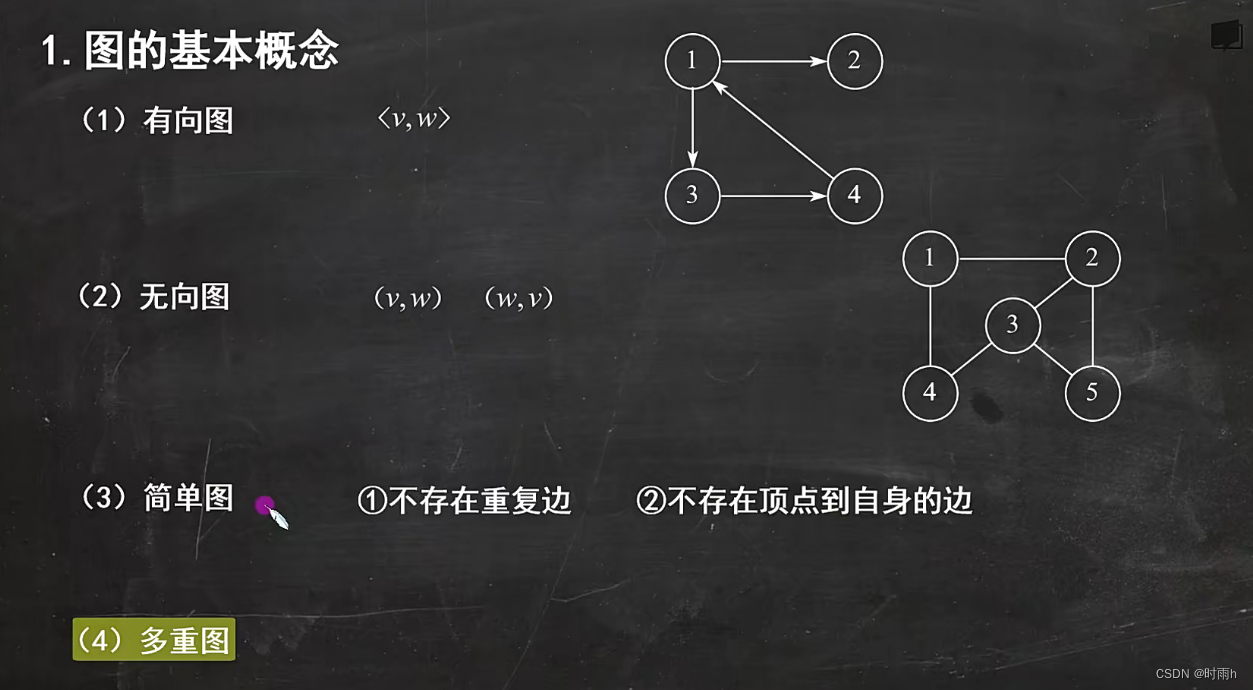
图

在数据结构中,图(Graph)是由节点(Vertex)和边(Edge)组成的一种非线性数据结构。图可以用来表示不同事物之间的关系,比如社交网络中的用户和好友关系、城市之间的道路网络等。
图的基本组成部分包括:
-
节点(Vertex):也称为顶点或点,表示图中的一个元素或对象。每个节点可以有一个或多个属性,比如名称、值等。
-
边(Edge):表示两个节点之间的连接关系。边可以是有向的(指定连接的方向)或无向的(没有指定连接的方向),也可以带有权重(表示连接的权重或距离)。
-
路径(Path):由一系列节点和连接它们的边组成的序列。路径可以是有向的或无向的,可以是闭合的(起点和终点相同)或开放的。
-
无向图(Undirected Graph):所有边都是无向的,即没有指定连接的方向。
-
有向图(Directed Graph):边具有方向,从一个节点指向另一个节点。
-
加权图(Weighted Graph):边具有权重或距离,表示节点之间的某种度量。
-
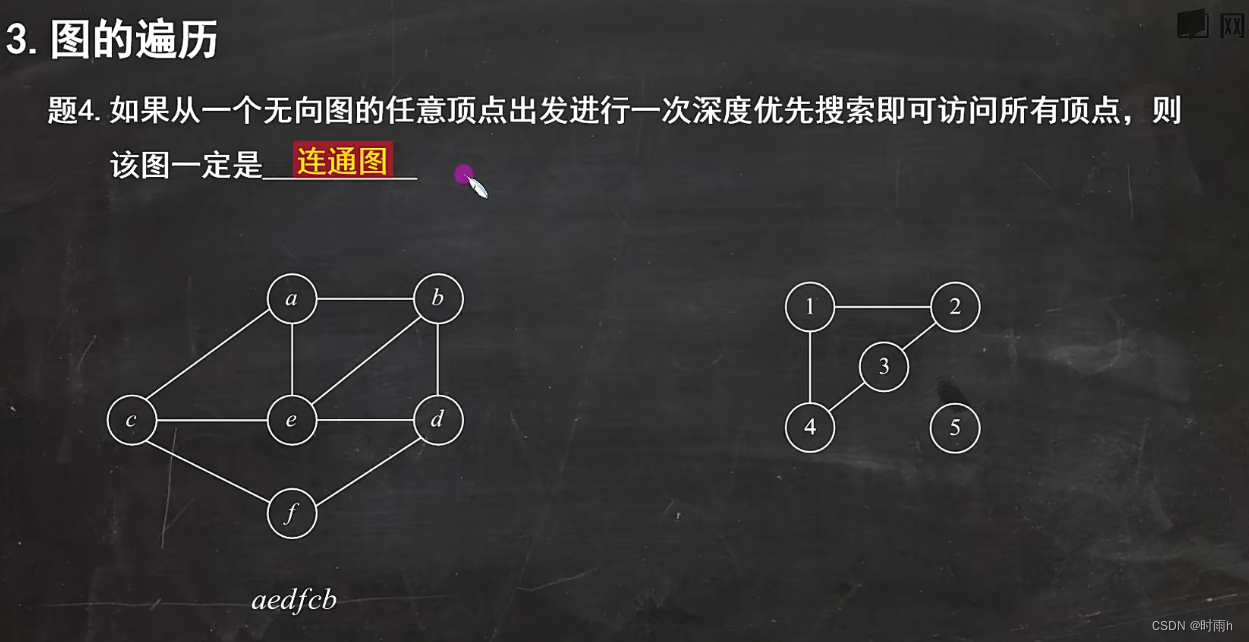
连通图(Connected Graph):图中的任意两个节点之间都存在路径。
-
子图(Subgraph):图中的一部分节点和边的集合,仍然构成一个图。
图可以用多种方式实现,包括邻接矩阵、邻接表和关联矩阵等。常见的图算法有深度优先搜索(DFS)、广度优先搜索(BFS)、最短路径算法(如Dijkstra算法和Floyd-Warshall算法)、最小生成树算法(如Prim算法和Kruskal算法)等。
图在计算机科学中有广泛的应用,包括社交网络分析、路由算法、图像处理、电路设计等领域。

生成树边数等于顶点数-1 极小!!!


图的存储矩阵
(1)图的邻接矩阵


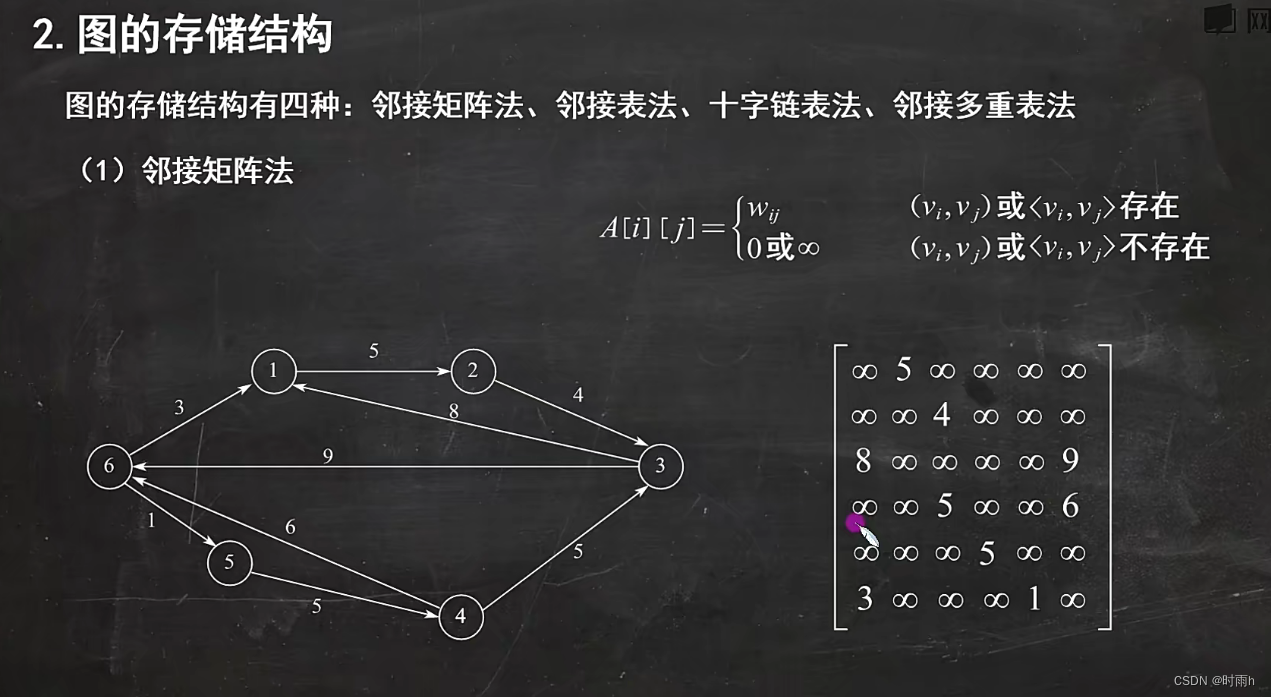
n个顶点的无向连通图用邻接矩阵表示时,该矩阵至少有2n一2个非零元素



V顶点 E边


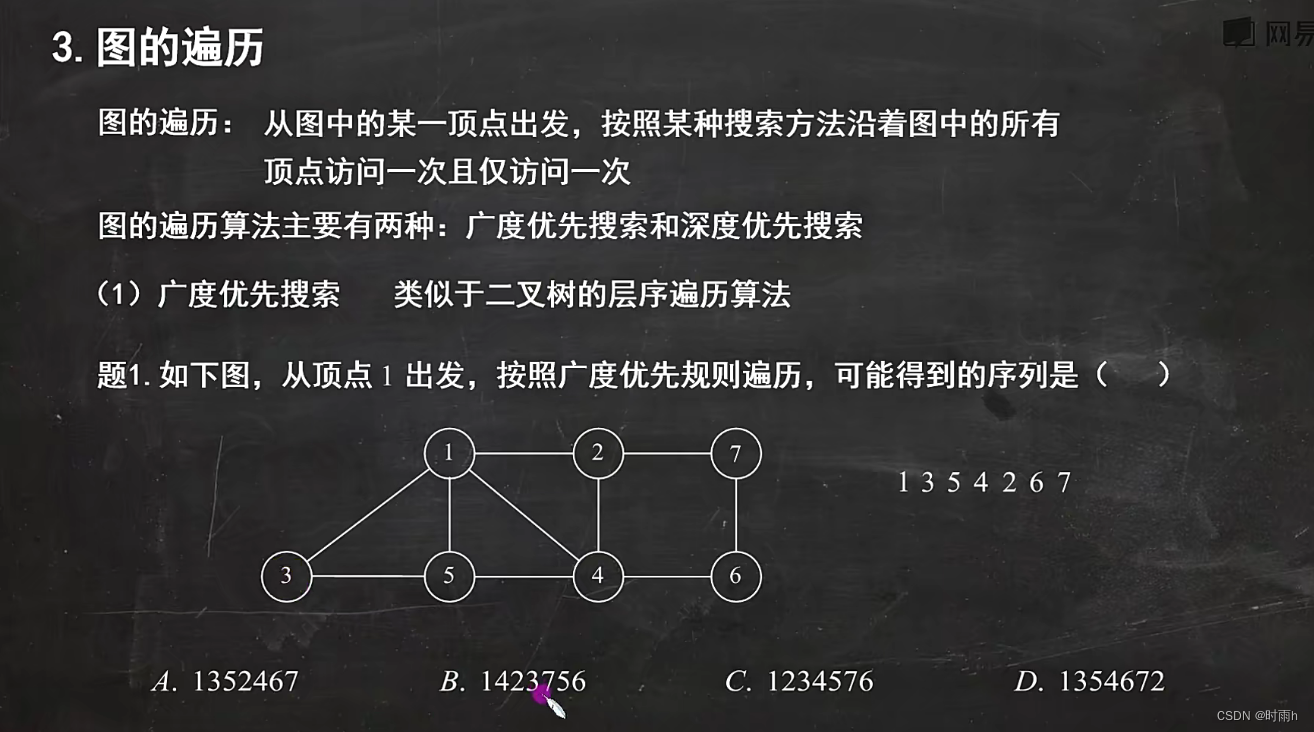
图的遍历
图的遍历是指按照一定的规则,依次访问图中的所有节点,确保每个节点都被访问且仅被访问一次的过程。常用的图遍历算法有深度优先搜索(DFS)和广度优先搜索(BFS)。
-
深度优先搜索(DFS):
- 选择一个起始节点作为当前节点,并将其标记为已访问。
- 从当前节点出发,依次访问与该节点相邻且未被访问过的节点。
- 对于每个未被访问的相邻节点,重复上述步骤直到所有节点都被访问。
-
广度优先搜索(BFS):
- 选择一个起始节点作为当前节点,并将其标记为已访问。
- 将当前节点加入到一个队列中。
- 从队列中取出一个节点作为当前节点,访问该节点的所有未被访问过的相邻节点,并将它们标记为已访问。
- 将这些相邻节点加入队列中。
- 重复上述步骤直到队列为空。
这两种遍历算法都能够访问图中的所有节点,只是访问顺序不同。DFS按照深度优先的原则,先访问一个节点的所有相邻节点,然后再递归地访问下一个节点的相邻节点。而BFS按照广度优先的原则,先访问一个节点的所有相邻节点,然后再逐层地访问下一个节点的相邻节点。
这些遍历算法在解决图相关的问题时非常有用,例如寻找路径、判断连通性、查找最短路径等。具体选择哪种遍历算法取决于具体的问题需求。


最小生成树
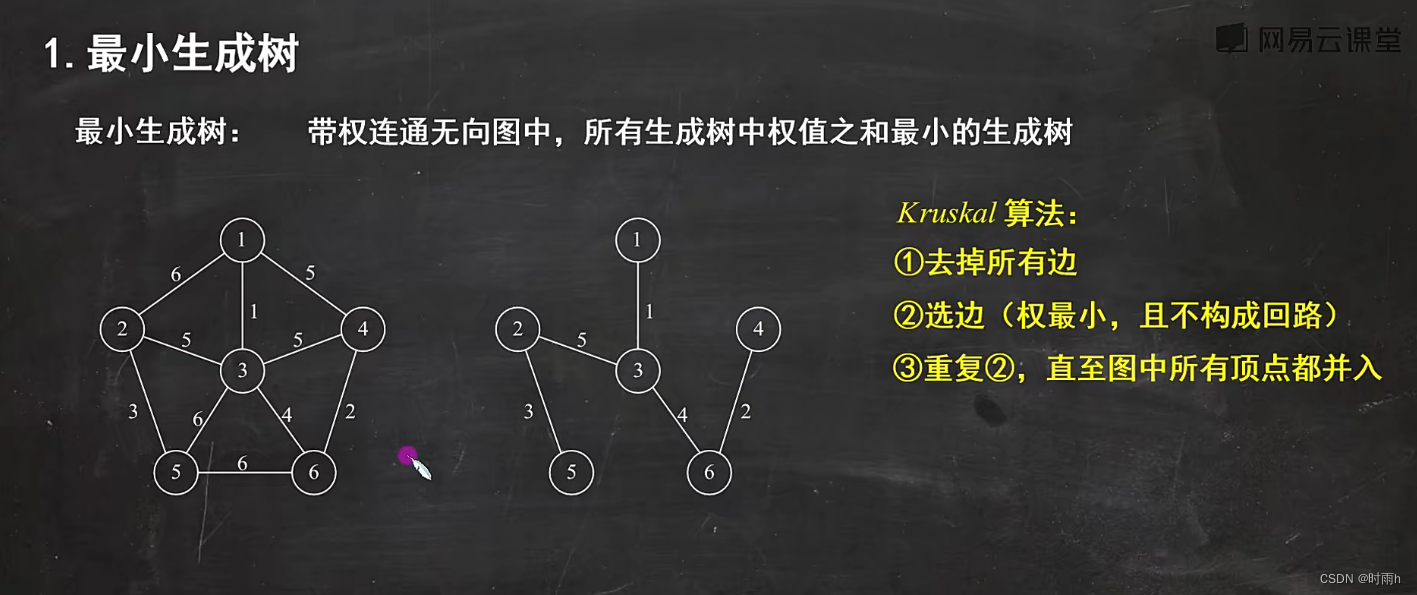
最小生成树(Minimum Spanning Tree,简称MST)是指在一个连通图中选择一棵树,使得这棵树包含图中的所有节点,并且总权值最小。
常用的求解最小生成树的算法有以下两种:
-
Prim算法:
- 选择一个起始节点,将其加入到最小生成树中。
- 在剩余的节点中,找到与当前最小生成树连接的边的最小权值边所连接的节点,并将其加入到最小生成树中。
- 重复上述步骤直到最小生成树包含图中的所有节点。
-
Kruskal算法:
- 将图中的所有边按照权值从小到大进行排序。
- 依次选择权值最小的边,并判断是否会形成环路。如果不会形成环路,则将该边加入到最小生成树中。
- 重复上述步骤直到最小生成树包含图中的所有节点。
这两种算法都可以求解最小生成树,但是它们的思想和实现方式略有不同。Prim算法从一个起始节点开始,逐步扩展最小生成树,直到包含所有节点。Kruskal算法则通过按照边权值排序的方式,依次选择边,并判断是否形成环路来构建最小生成树。
最小生成树在实际应用中非常重要,例如在网络设计、电力传输、通信网络等领域都有广泛的应用。求解最小生成树可以帮助我们找到一个具有最小成本或最小距离的连通子图,以满足特定的需求。

最短路径

最短路径是指在图中找到两个节点之间的最短路径,即路径上的边权重之和最小。
常用的求解最短路径的算法有以下三种:
-
Dijkstra算法:
- 选择一个起始节点,并将其到起始节点的距离初始化为0,其他节点的距离初始化为正无穷。
- 从未标记的节点中选择距离起始节点最近的节点,将其标记为已访问。
- 对于该节点的所有未标记的相邻节点,更新它们到起始节点的距离,如果经过当前节点到达相邻节点的路径比之前的路径更短。
- 重复上述步骤直到所有节点都被标记为已访问或者没有可选的节点。
-
Bellman-Ford算法:
- 将所有节点的距离初始化为正无穷,起始节点的距离初始化为0。
- 依次对图中的边进行松弛操作,即通过当前边缩短起始节点到相邻节点的距离。
- 重复对所有边进行松弛操作,直到没有可更新的距离为止。
- 如果还存在可以更新的距离,则说明图中存在负权回路。
-
Floyd-Warshall算法:
- 初始化一个二维数组,记录任意两个节点之间的距离。
- 通过三层循环,分别遍历所有节点对,更新它们之间的最短路径。
- 最后得到一个二维数组,其中记录了任意两个节点之间的最短路径。
这些算法可以用于求解不同情况下的最短路径问题。Dijkstra算法适用于单源最短路径问题,即从一个起始节点到其他所有节点的最短路径。Bellman-Ford算法适用于解决含有负权边的最短路径问题,而Floyd-Warshall算法适用于求解任意两个节点之间的最短路径。
最短路径算法在实际应用中有广泛的应用,例如路由选择、导航系统、货物配送等领域。通过求解最短路径,可以帮助我们找到在图中最快或最经济的路径,以满足特定的需求。
拓扑排序

拓扑排序是一种对有向无环图(DAG)进行排序的算法。它可以将图中的节点按照一定的顺序进行排序,使得所有的依赖关系都得到满足。
具体的拓扑排序算法如下:
- 统计每个节点的入度(即指向该节点的边的数量)。
- 初始化一个队列,并将所有入度为0的节点加入队列中。
- 从队列中取出一个节点,并将其加入结果集中。
- 对于该节点的所有邻接节点,将其入度减1。
- 如果某个节点的入度变为0,则将其加入队列中。
- 重复步骤3到步骤5,直到队列为空。
如果图中存在环路,则无法进行拓扑排序,因为环路中的节点互相依赖,无法确定它们之间的相对顺序。
拓扑排序可以用于解决许多实际问题,例如任务调度、编译顺序的确定、依赖关系分析等。通过拓扑排序,我们可以确定节点之间的执行顺序,确保依赖关系得到满足,从而有效地解决相关问题。
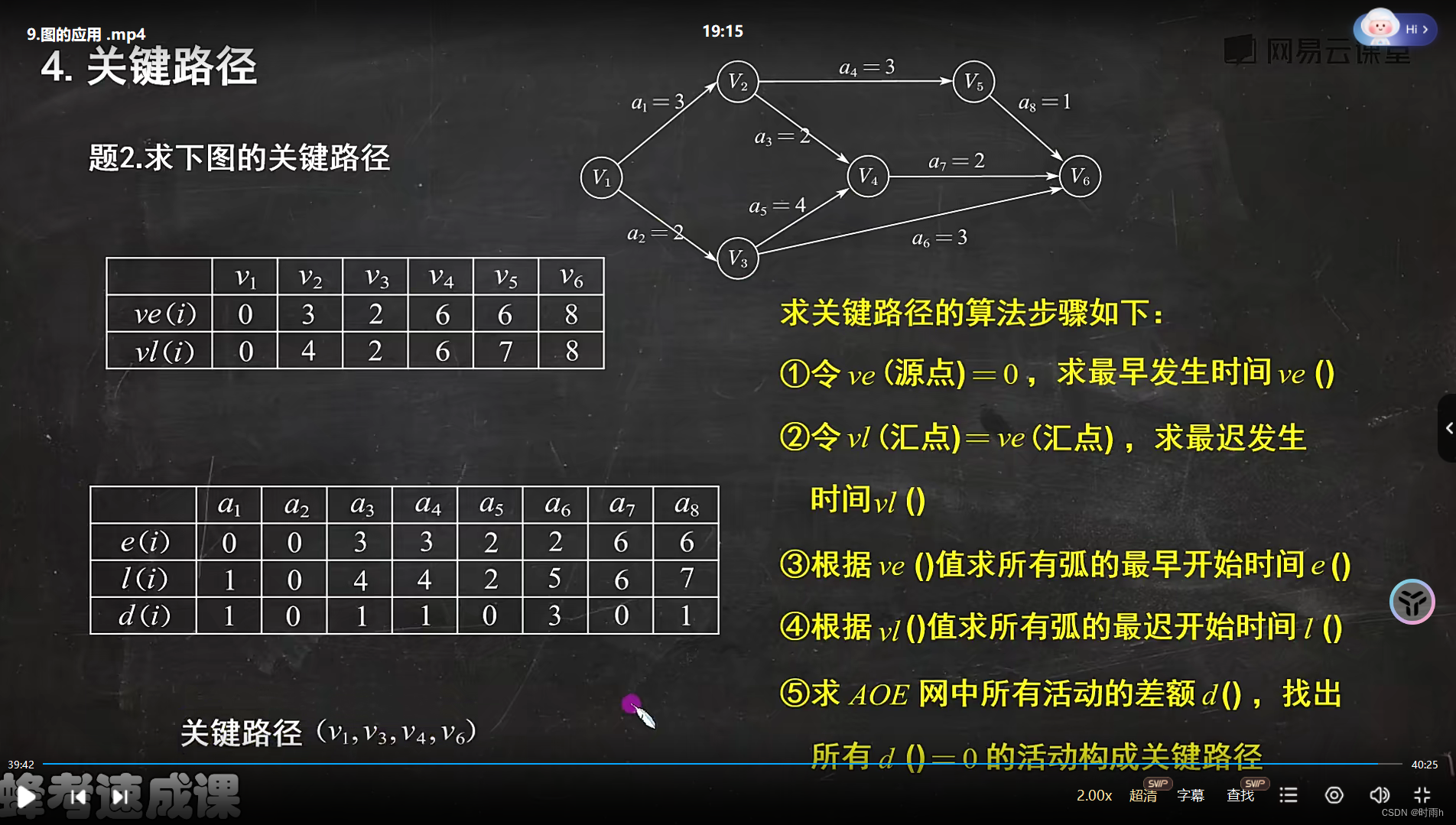
AOE网
AOE 网(Activity On Edge Network)是一种以有向边表示活动(Activity),以顶点表示活动之间的事件(Event)和控制关系的有向无环图(DAG)。
在 AOE 网中,每条有向边表示一个活动,而顶点则表示活动之间的事件或者控制关系。与 AOV 网不同,AOE 网在边上标注了活动的持续时间或者其他相关信息。
AOE 网通常用于表示工程项目的网络计划,其中活动之间存在着先后顺序、依赖关系以及活动的持续时间。通过对 AOE 网进行网络计划的分析,可以确定整个工程项目的最早开始时间、最晚开始时间、关键路径等关键信息。
在 AOE 网中,顶点表示事件,有向边表示活动,每个顶点都有两个时间属性:最早发生时间(EST,Earliest Start Time)和最迟发生时间(LST,Latest Start Time)。通过计算这些时间属性,可以确定活动的最早开始时间、最晚开始时间以及整个项目的关键路径。
AOE 网的关键路径是指项目中耗时最长的路径,它决定了整个项目的最短完成时间。通过计算关键路径,可以确定项目中哪些活动对整个项目的进度具有关键影响。
总结来说,AOE 网是一种用于表示工程项目网络计划的有向无环图,其中边表示活动,顶点表示事件或者控制关系。通过对 AOE 网进行分析,可以确定项目的最早开始时间、最晚开始时间、关键路径等关键信息。


查找算法
查找算法通常有两种常见的实现方式:顺序查找和二分查找。
- 顺序查找
顺序查找也称为线性查找,是最简单的一种查找算法。它从数据集的起点开始逐个比较每个元素,直到找到目标元素或者搜索到数据集的末尾。
示例代码:
int sequential_search(int arr[], int n, int target) {
for (int i = 0; i < n; i++) {
if (arr[i] == target) {
return i;
}
}
return -1;
}
- 二分查找
二分查找也称为折半查找,是一种针对有序数据集合进行查找的算法。它利用了数据集的有序性,将数据集从中间分为两份,如果目标元素小于中间元素,则在左半部分继续查找,否则在右半部分继续查找,直到找到目标元素或者数据集缩小到只有一个元素为止。
示例代码:
int binary_search(int arr[], int n, int target) {
int left = 0, right = n - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1;
}
其中,left 表示左边界,right 表示右边界,mid 表示中间位置。每次查找都将数据集缩小一半,时间复杂度为 O(log n)。
需要注意的是,二分查找算法只适用于有序的数据集合。




折半查找,也称为二分查找,是一种高效的查找算法,适用于有序数据集合。它通过将数据集从中间进行分割,并与目标元素进行比较,缩小查找范围,直到找到目标元素或者确定目标元素不存在。
折半查找的具体步骤如下:
- 定义左边界
left为数据集的起始位置,右边界right为数据集的末尾位置。 - 计算中间位置
mid,可以使用mid = left + (right - left) / 2或者mid = (left + right) / 2。 - 比较中间位置的元素与目标元素的大小关系:
- 如果中间元素等于目标元素,则返回中间位置作为结果。
- 如果中间元素大于目标元素,则在左半部分继续查找,更新右边界为
mid - 1。 - 如果中间元素小于目标元素,则在右半部分继续查找,更新左边界为
mid + 1。
- 重复步骤 2 和步骤 3,直到左边界大于右边界,表示没有找到目标元素,返回 -1。
以下是一个使用 C 语言实现的折半查找的示例代码:
int binary_search(int arr[], int n, int target) {
int left = 0;
int right = n - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid; // 找到目标元素,返回索引
} else if (arr[mid] < target) {
left = mid + 1; // 在右半部分继续查找
} else {
right = mid - 1; // 在左半部分继续查找
}
}
return -1; // 目标元素不存在,返回 -1
}
请注意,折半查找算法要求数据集已经按照升序或降序排列,否则不能保证正确性。此外,折半查找的时间复杂度为 O(log n),是一种高效的查找算法。
散列表
散列表(Hash Table),也被称为哈希表或哈希映射,是一种常见的数据结构,用于实现键值对的存储和查找。它通过将键映射到一个固定大小的数组中,以便快速访问和操作数据。
散列表的核心思想是使用散列函数(Hash Function)将键转换为数组索引。散列函数将键映射到数组中的特定位置,这个位置被称为散列桶(Hash Bucket)或槽位(Slot)。当需要插入、查找或删除元素时,只需通过散列函数计算键的散列值,然后在散列桶中进行操作。
散列函数应该具有以下特性:
- 一致性:对于相同的键,散列函数应该始终返回相同的散列值。
- 均匀性:散列函数应尽可能地将不同的键映射到不同的散列值,以避免冲突。
解决冲突:
由于散列函数的输出空间远远小于输入空间,不同的键可能会映射到相同的散列值,导致冲突。为了解决冲突,通常有以下两种常见的方法:
- 链接法(Chaining):每个散列桶维护一个链表,冲突的元素都存储在链表中。当需要查找时,先通过散列函数计算散列值,然后在对应的链表中顺序查找目标元素。
- 开放地址法(Open Addressing):尝试将冲突的元素存储到其他空闲的散列桶中,而不是使用链表。常见的开放地址法有线性探测、二次探测和双重散列等。
散列表的优点是可以在平均情况下实现快速的插入、查找和删除操作。但是,散列表的性能可能会受到冲突的影响,如果冲突过多,会导致性能下降。因此,在设计散列表时,选择合适的散列函数和解决冲突的方法很重要。
总结一下,散列表是一种基于散列函数的数据结构,用于实现键值对的高效存储和查找。它通过将键映射到数组中的位置来快速定位数据。
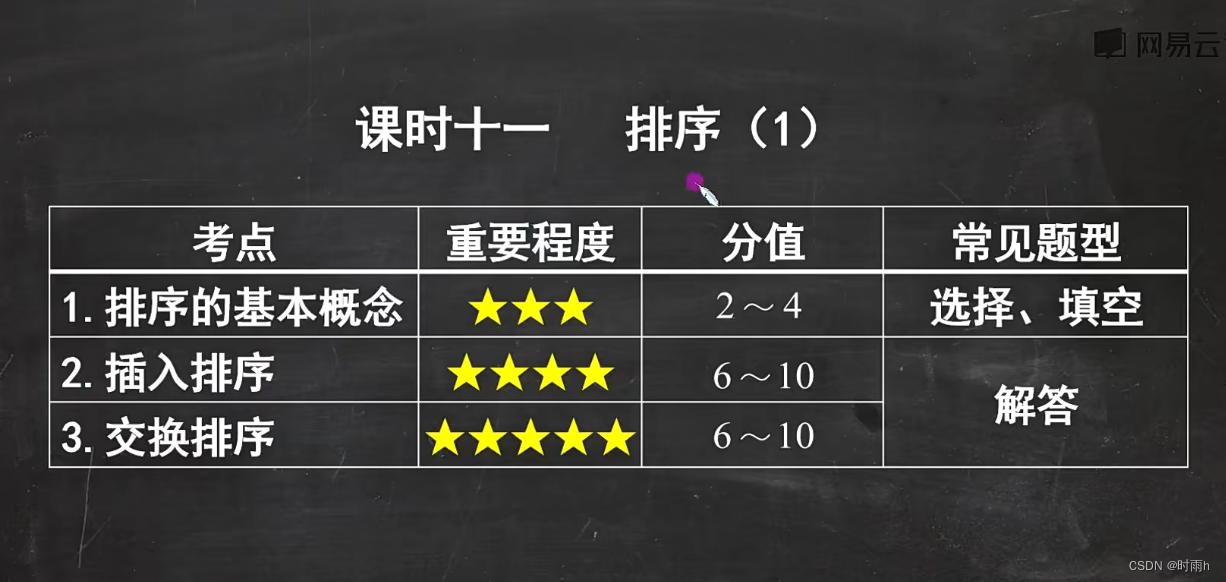
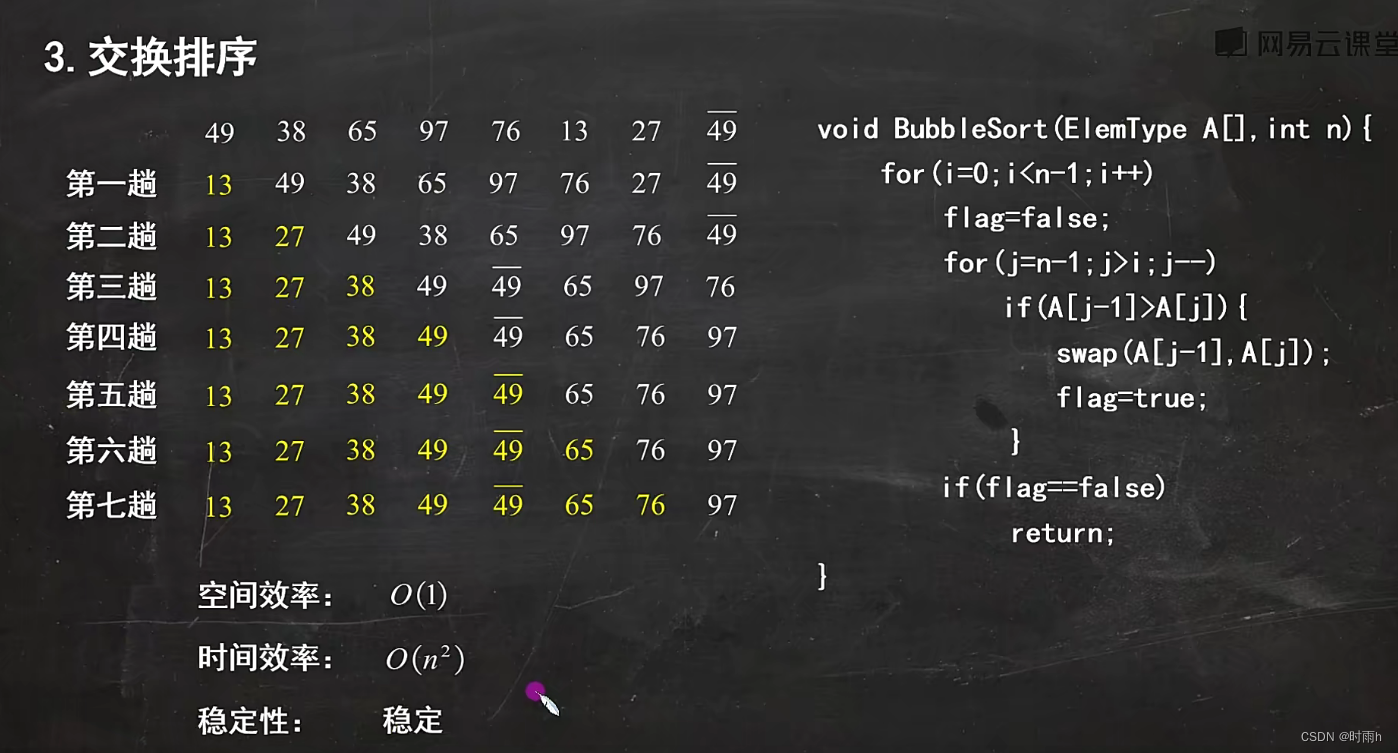
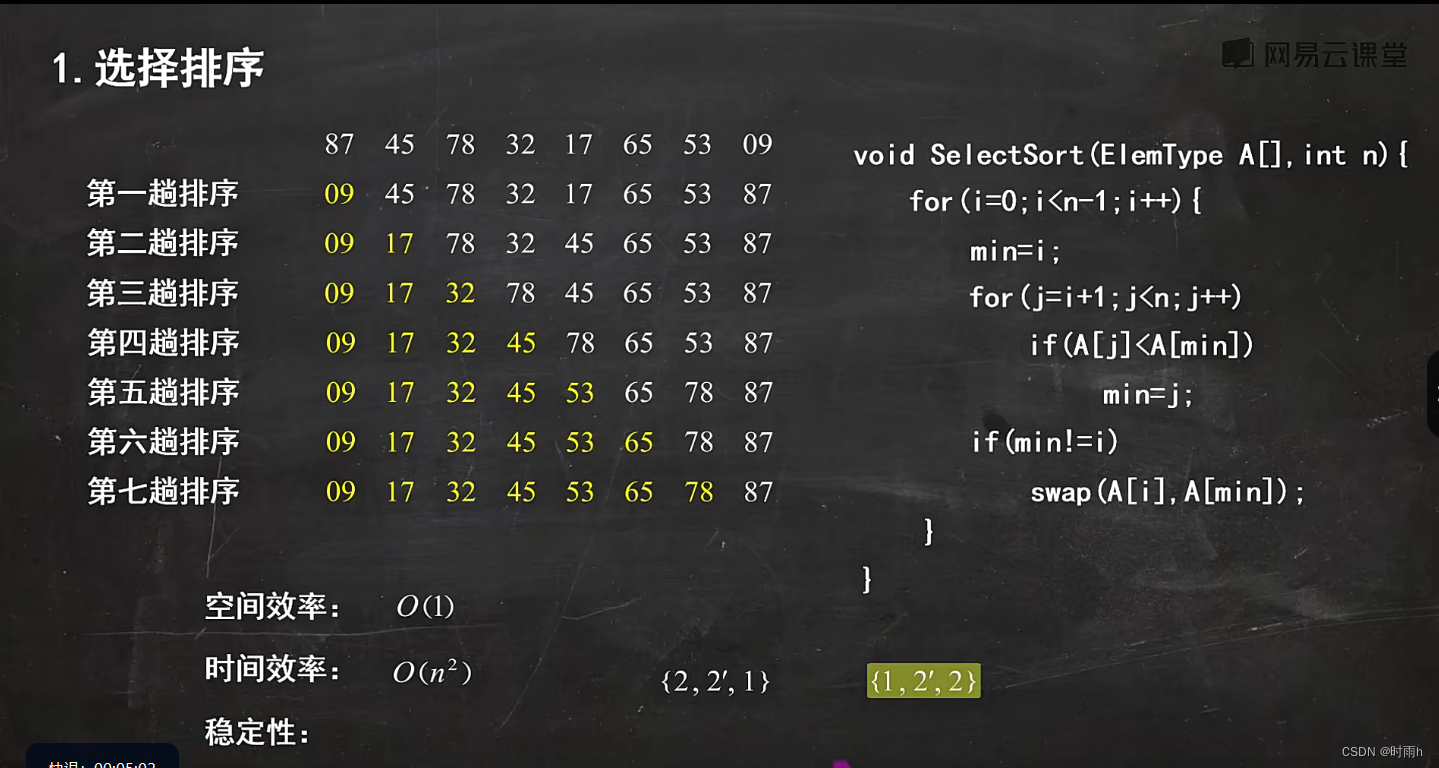
排序


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- linux常用命令(主机信息、用户管理、用户组管理、文件管理、快捷键)
- leetcode 2418. 按身高排序
- elementUI+el-upload 上传、下载、删除文件以及文件展示列表自定义为表格展示
- java预科
- FL Studio21.2上市更新发布中文有版本
- 线性代数-第五课,第六课,第七课,第八课
- 高速PCB的铜箔选用指南—外层避坑设计
- 基于Java SSM框架实现雁门关风景区宣传网站项目【项目源码】
- priority_queue比较规则
- LeetCode394.字符串解码