大数据之使用Flume监听本地文件采集数据流到HDFS
发布时间:2024年01月10日
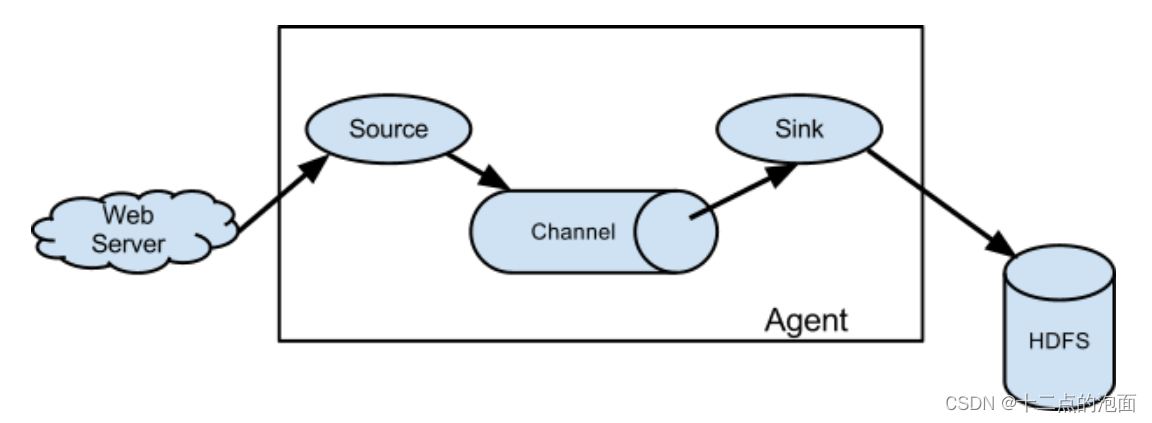
任务一:
在Master节点使用Flume采集/data_log目录下实时日志文件中的数据(实时日志文件生成方式为在/data_log目录下执行./make_data_file_v1命令即可生成日志文件,如果没有权限,请执行授权命令chmod 777 /data_log/make_data_file_v1),将数据存入到Kafka的Topic中(Topic名称分别为ChangeRecord、ProduceRecord和EnvironmentData,分区数为4),将Flume采集ChangeRecord主题的配置截图粘贴至对应报告中;
任务二:
编写新的Flume配置文件,将数据备份到HDFS目录/user/test/flumebackup下,要求所有主题的数据使用同一个Flume配置文件完成,将Flume的配置截图粘贴至对应报告中。
①模拟数据源环境
进入/data_log路径运行脚本make_data_file_v1产生数据源
cd /data_log
./make_data_file_v1
②创建Topic
bin/kafka-topics.sh --create --bootstrap-server bigdata1:9092 --replication-factor 1 --partitions 4 --topic ChangeRecord
?
bin/kafka-topics.sh --create --bootstrap-server bigdata1:9092 --replication-factor 1 --partitions 4 --topic ProduceRecord
?
bin/kafka-topics.sh --create --bootstrap-server bigdata1:9092 --replication-factor 1 --partitions 4 --topic EnvironmentData列出Topic
bin/kafka-topics.sh --list --bootstrap-server bigdata1:9092③创建flume的Agent
cd /opt/module/flume-1.9.0/job解决任务一:
vim gy_to_kafka.conf内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
?
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = ? tail -f +0 /data_log/2024-01-09\@15\:27-changerecord.csv
# Describe the sink KafkaSink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = bigdata1:9092,bidata2:9092,bidata3:9092
a1.sinks.k1.kafka.topic = ChangeRecord
?
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
?
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1解决任务二:
vim gy_to_hdfs.conf内容如下:
# Name the components on this agent
a1.sources = r1 r2 r3
a1.sinks = k1 k2 k3
a1.channels = c1 c2 c3
?
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r2.type = exec
a1.sources.r3.type = exec
#command -> 命令 tail -> 监控(实时查看文件的更新内容) -f -> 持续实时监听文件的更改 +0 -> 从文件开头开始读取
a1.sources.r1.command = ? tail -f +0 /data_log/2024-01-09@21:06-changerecord.csv
a1.sources.r2.command = ? tail -f +0 /data_log/2024-01-09@21:06-environmentdata.csv
a1.sources.r3.command = ? tail -f +0 /data_log/2024-01-09@21:06-producerecord.csv
?
# Describe the sink KafkaSink
a1.sinks.k1.type = hdfs
#hdfs中 changerecord存储路径
a1.sinks.k1.hdfs.path=/user/test/flumebackup/changerecord/%Y-%m-%d/%H%M/%S
a1.sinks.k2.type = hdfs
#hdfs中 environmentdata存储路径
a1.sinks.k2.hdfs.path=/user/test/flumebackup/environmentdata/%Y-%m-%d/%H%M/%S
a1.sinks.k3.type = hdfs
#hdfs中 producerecord存储路径
a1.sinks.k3.hdfs.path=/user/test/flumebackup/producerecord/%Y-%m-%d/%H%M/%S
?
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 1000
?
a1.channels.c2.type = memory
a1.channels.c2.capacity = 100000
a1.channels.c2.transactionCapacity = 1000
?
a1.channels.c3.type = memory
a1.channels.c3.capacity = 100000
a1.channels.c3.transactionCapacity = 1000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
?
a1.sources.r2.channels = c2
a1.sinks.k2.channel = c2
?
a1.sources.r3.channels = c3
a1.sinks.k3.channel = c3④启动flume服务
在flume目录下
flume-ng agent -n a1 -c conf/ -f job/gy_to_kafka.conf -Dflume.root.logger=INFO,console
flume-ng agent -n a1 -c conf/ -f job/gy_to_hdfs.conf -Dflume.root.logger=INFO,console-Dflume.root.logger=INFO,console 打印输出在控制台上
⑤消费数据
#任务一 提交到kafka上 所以通过kafka查看
kafka-console-consumer.sh --bootstrap-server bigdata1:9092,bigdata2:9092,bigdata3:9092 --topic ChangeRecord --from-beginning
?
#任务二 提交到hdfs集群 所以要通过hdfs查看
hadoop fs -ls /user/test/flumebackup

文章来源:https://blog.csdn.net/2301_78038072/article/details/135490910
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 企业微信模板卡片消息
- 要给客户圣诞发圣诞祝福了!
- 面试题 05.06. 整数转换(力扣)(OJ题)
- M1安装tensorflow
- Linux系统下文本编辑常用的命令有哪些?
- 4.28 构建onnx结构模型-Unfold
- SpringSecurity深度解析与实践(3)
- Docker部署Mysql5.7x和Myslq8.x
- 视觉检测不合格品剔除FC(Smart PLC简单状态机编程应用)
- SAP 采购订单暂存 EKKO-MEMORY 做标识