Python从入门到精通 第七章(文件和数据格式化)
一、文件的类型
1、文本文件
(1)文本文件一般由单一特定编码的字符组成(如UTF-8编码),内容容易统一展示和阅读。
(2)大部分文本文件都可以通过文本编辑软件或文字处理软件创建、修改和阅读。
(3)由于文本文件存在编码,所以它也可以被看作是存储在磁盘上的长字符串,如一个txt格式的文本文件。
(4)文本文件本质上还是二进制文件,例如Python的源程序。
2、二进制文件
(1)二进制文件直接由比特0和比特 1组成,没有统一的字符编码,文件内部数据的组织格式与文件用途有关。
(2)二进制文件是信息按照非字符但有特定格式形成的文件,如png格式的图片文件、avi格式的视频文件。
(3)二进制文件和文本文件最主要的区别在于是否有统一的字符编码。进制文件由于没有统一的字符编码,只能当作字节流,而不能看作是字符串。
(4)二进制文件保存的内容不是给人直接阅读的,而是提供给其它软件使用的,不能使用文本编辑软件查看(例如图片文件、音频文件、视频文件)。
(5)在计算机中,文件是以二进制的方式保存在磁盘上的。
二、文件的基本操作
1、操作文件的流程
(1)打开文件。
(2)读、写(操作)文件:
?①读:将文件内容读入内存。
?②写:将内存内容写入文件。
(3)关闭文件。
2、文件的打开和关闭
(1)Python通过open函数打开一个文件(如果文件不存在将会抛出异常),并返回一个操作这个文件的变量,语法形式如下:
<变量名>=open(<文件路径及文件名>,<打开模式>)
(2)open函数默认以只读方式打开文件(且默认为文本模式),常用的文件打开模式如下(打开模式使用字符串方式表示)。
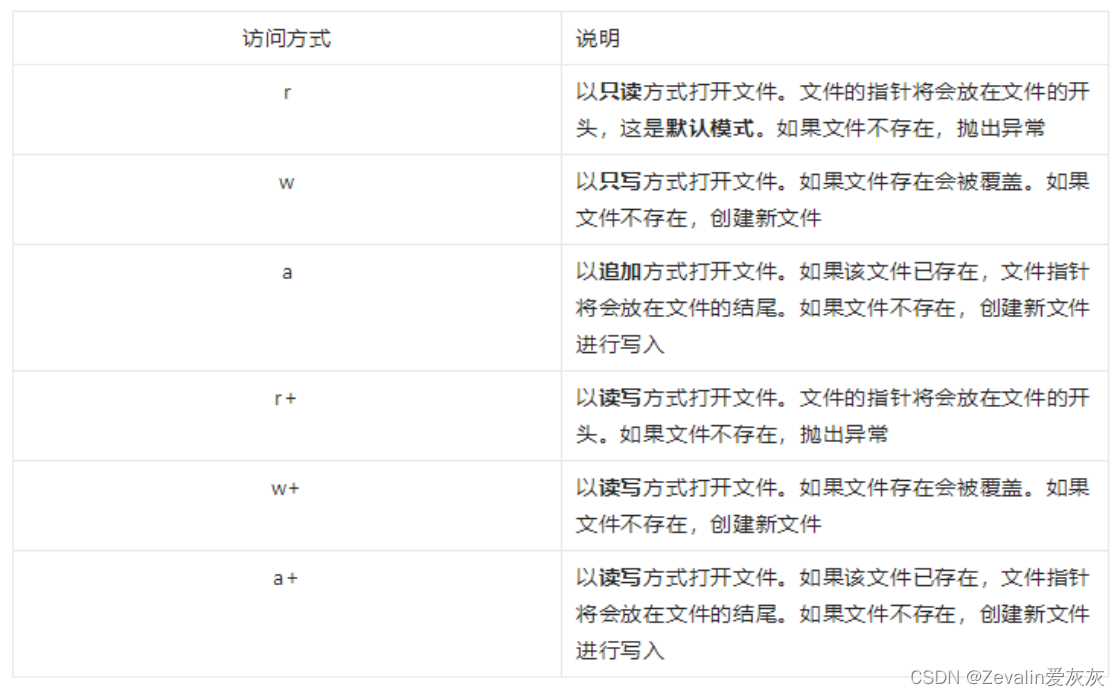
补充:
①x:创建写模式,文件不存在则创建,存在则返回异常FileExistsError。b:二进制文件模式。t:文本文件模式(默认值)。
②文件指针:标记从哪个位置开始读取数据。
③频繁地移动文件指针,会影响文件的读写效率,开发中更多的时候会以只读、只写的方式来操作文件。
(3)文件使用结束后要用close方法关闭,释放文件的使用授权,语法形式如下:
<变量名>.close()
3、操作文件的函数/方法
(1)文件读取方法:
| 方法 | 含义 |
| f.read(size=-1) | 从文件中读入整个文件内容;参数可选,如果给出,读入前size长度的字符串或字节流 |
| f.readline(size=-1) | 从文件中读入一行内容;参数可选,如果给出,读入该行前size长度的字符串或字节流 |
| f.readlines(hint=-1) | 从文件中读入所有行,以每行为元素形成一个列表;参数可选,如果给出,读入hint行 |
| f.seek(offset) | 改变当前文件操作指针的位置,offset取0为文件开头,offset取2为文件结尾 |
①read方法可以一次性读入并返回文件的所有内容,read方法执行后会把文件指针移动到文件的末尾。(如果执行了一次read方法读取了所有内容,那么再次调用read方法,将不能够获得到内容,因为第一次读取之后,文件指针移动到了文件末尾,再次调用不会读取到任何的内容)
# 1. 打开 - 文件名需要注意大小写
file = open("README")
# 2. 读取
text = file.read()
print(text)
# 3. 关闭
file.close()②readline方法可以一次读取一行内容,方法执行后,会把文件指针移动到下一行,准备下一次读取。(对于read方法,如果文件太大,一次性读入文件会对内存的占用非常严重,readline方法可以避免这个问题)
# 打开文件
file = open("README")
while True:
# 读取一行内容
text = file.readline()
# 判断是否读到内容
if not text:
break
# 每读取一行的末尾已经有了一个 `\n`
print(text, end="")
# 关闭文件
file.close()(2)文件写入方法:
| 方法 | 含义 |
| f.write(s) | 向文件写入一个字符串或字节流 |
| f.writelines(lines) | 将一个元素为字符串的列表整体写入文件 |
# 打开文件
f = open("README", "w")
f.write("hello python!\n")
f.write("今天天气真好")
# 关闭文件
f.close()4、文件读写案例——复制文件
(1)小文件复制:打开一个已有文件,读取完整内容,并写入到另外一个文件。
# 1. 打开文件
file_read = open("README")
file_write = open("README[复件]", "w")
# 2. 读取并写入文件
text = file_read.read()
file_write.write(text)
# 3. 关闭文件
file_read.close()
file_write.close()(2)大文件复制:打开一个已有文件,逐行读取内容,并顺序写入到另外一个文件。
# 1. 打开文件
file_read = open("README")
file_write = open("README[复件]", "w")
# 2. 读取并写入文件
while True:
# 每次读取一行
text = file_read.readline()
# 判断是否读取到内容
if not text:
break
file_write.write(text)
# 3. 关闭文件
file_read.close()
file_write.close()三、文件/目录的常用管理操作
在终端/文件浏览器中可以执行常规的文件/目录管理操作,例如:创建、重命名、删除、改变路径、查看目录内容、……
在Python中,如果希望通过程序实现上述功能,需要导入os模块
1、文件操作

2、目录操作

注:文件或者目录操作都支持相对路径和绝对路径
四、数据组织的维度
1、一维数据
(1)一维数据由对等关系的有序或无序数据构成,采用线性方式组织,对应于数学中数组的概念。
(2)在Python中,主要采用列表形式表示一维数据。
list = ["2005","08","03"](3)一维数据的文件存储有多种方式,总体思路是采用特殊字符分隔各数据,常见的存储方法有以下四种:
①采用空格分隔元素。
②采用逗号分隔元素。(该格式被称为CSV格式,比较常用)
③采用换行分隔元素。
④采用其它特殊符号(如分号)分隔元素。
list = ["2005","08","03"]
f = open("date.csv","w")
f.write(",".join(list)+"\n") # 用逗号分隔列表list的每个元素
f.close()(4)要对一维数据进行处理,首先需要从CSV格式文件读入一维数据,并将其表示为列表对象。需要注意的是,从CSV文件中获得内容时,最后一个元素后面包含了一个换行符“\n”,对于数据的表达和使用来说,这个换行符是多余的,可以使用字符串的strip方法去除。
f = open("date.csv","r")
list = f.read().strip('\n').split(",") # 先去掉尾部的换行符,再根据逗号分隔符还原文件中的数据,将它们制作成列表
f.close()
print(list)2、二维数据
(1)二维数据又称表格数据,由关联关系数据构成,采用二维表格方式组织,对应于数学中的矩阵。
(2)二维数据由多个一维数据构成,可以看作是一维数据的组合形式,因此二维数据可以采用二维列表来表示,即大列表中的元素为小列表,大列表的每个元素对应二维数据的一行,这个元素本身也是列表类型,其(小列表)内部各元素对应这行中的各列值。(在C语言中被称为二维数组)
list = [
['奇妙大营救','2022.07.15']
['勇闯四季城','2023.01.06']
['遨游神秘洋','2023.07.06']
](3)二维数据由一维数据组成,用CSV格式文件存储,CSV文件的每一行是一组一维数据,整个CSV文件是一个二维数据。
list = [
['奇妙大营救','2022.07.15']
['勇闯四季城','2023.01.06']
['遨游神秘洋','2023.07.06']
]
f = open("date.csv","w")
"""
list是大列表,for循环遍历大列表,每次循环中row都取list中的一组一维数据
将每次取出的一维数据都使用join方法改造为用逗号分隔各数据的字符串,写入文件中
每写一组一维数据就要写一个换行符
"""
for row in list:
f.write(",".join(row) + "\n")
f.close()(4)要对二维数据进行处理,首先需要从CSV格式文件读入二维数据,并将其表示为列表对象。
f = open("date.csv","r")
list = [] # 创建空列表,用于存放读入的二维数据
for line in f:
list.append(line.strip('\n').split(",")) # 逐行读入,先去掉尾部的换行符,再根据逗号分隔符还原当前行的一维数据,将它们制作成一维列表存进二维列表list中
f.close()
print(list) # 直接打印二维列表
# 以表格的形式打印二维数据
for row in list:
line = ""
for item in row:
line += "{:10}\t".format(item) # 制表(对齐各数据)
print(line) # 逐行打印3、高维数据
(1)高维数据由键值对类型的数据构成,采用对象方式组织,可以多层嵌套。
(2)高维数据相比一维数据和二维数据,能表达更加灵活和复杂的数据关系。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2023年广东省网络安全B模块(笔记详解)
- 【华为OD机试真题2023C&D卷 JAVA&JS】篮球游戏
- 数字经济如何驱动企业高质量发展? ——核心机制、模式选择与推进路径
- node.js express JWT token生成与校验
- 【Python特征工程系列】教你利用XGBoost模型分析特征重要性(源码)
- ECMAScript6详解
- [足式机器人]Part3 机构运动学与动力学分析与建模 Ch00-2(1) 质量刚体的在坐标系下运动
- 【问题记录-A2B】“Line Fault(0xC): Open Wires or Wrong Port Found at Slave Node 0(A2B Slave Node1 WBZ_1)”
- 基于SSM(非maven)的教室预约管理系统——有报告(Javaweb)
- 华为设备命令最全大合集(2024新版),赶紧收藏!