信号处理专题设计-基于边缘检测的数字图像分类识别
目录
一、实验目的
本实验旨在设计一个基于深度学习的图像信号处理系统,用于识别和提取图像中的关键信息。具体目标包括:
1.设计一个卷积神经网络(CNN)模型,用于对图像进行分类。
2.利用CNN模型对图像进行边缘检测,以提取图像中的关键信息。
3.在边缘检测的基础上,利用OpenCV库实现膨胀、腐蚀、开运算和闭运算等形态学操作,以进一步提取图像中的关键信息。
5.对整个系统进行测试和评估,包括准确性、鲁棒性和可扩展性等方面。
二、实验要求
1.实现卷积神经网络模型,包括网络结构的设计、层的配置和参数的设置。可以使用Python语言和深度学习框架如TensorFlow、Keras等。
2.使用合适的数据集对CNN模型进行训练和评估,同时记录准确率、损失函数的变化曲线等指标。
3.利用CNN模型对图像进行边缘检测,提取图像中的关键信息。可以使用OpenCV等计算机视觉库来实现边缘检测。
4.实现形态学操作,包括膨胀、腐蚀、开运算和闭运算等,以进一步提取图像中的关键信息。可以使用OpenCV库来实现这些形态学操作。
5.将提取的关键信息保存到文件中,以便后续使用。可以选择合适的文件格式和保存方式。
6.对整个系统进行测试和评估,包括分类准确性、边缘检测效果以及形态学操作对关键信息提取的影响。可以使用合适的评估指标和示例图像来展示实验结果。
7.在实验报告中清晰地描述实验的步骤、流程和实现细节,并附上所使用的代码和数据集(如果适用)。
8.讨论实验结果,包括对模型和算法的优缺点的分析、改进方法的讨论和图像信号处理系统的应用前景等。
三、实验原理
本部分主要介绍本次实验中使用到的重要模型、指标和算法。
1.卷积神经网络(CNN)模型
CNN是一种广泛应用于图像处理和计算机视觉任务的深度学习模型。
CNN包含多个卷积层、池化层和全连接层,通过对图像进行卷积和池化操作提取特征,并通过全连接层进行分类。
通过反向传播算法,CNN能够自动学习到图像中的特征和模式。
2.边缘检测
边缘是图像中灰度变化显著的区域,边缘检测可以识别出图像中的边缘信息。
常用的边缘检测算法包括Sobel算子、Canny边缘检测等。
边缘检测通常涉及梯度计算、非极大值抑制和阈值处理等步骤。
3.形态学操作
形态学操作是一种图像处理方法,用于对图像进行形状的改变和提取。
膨胀(dilation)可以扩展图像中的亮区域,腐蚀(erosion)可以缩小亮区域。
开运算(opening)是先腐蚀后膨胀,闭运算(closing)是先膨胀后腐蚀,用于平滑边缘和填充空洞。
4.鲁棒性
鲁棒性(Robustness)是指图像信号处理系统在处理各种不同情况下的稳定性和适应性。鲁棒性好的系统能够处理图像的光照变化、尺度变化、噪声等干扰因素,并保持较好的性能。
在设计系统时,需要考虑数据集的多样性和模型的泛化能力,以提高系统的鲁棒性。
四、实验过程
1.数据预处理
在进行网络训练之前,对手写数字图像数据进行了预处理。以下是数据预处理的具体步骤:
加载MNIST手写数字图像数据集,包括60,000张训练图像和10,000张测试图像。
将图像数据转换为合适的格式,通常是将图像像素值归一化到0-1之间,并调整图像大小为一致的尺寸。
对图像进行数据增强操作,以增加样本的多样性和鲁棒性。常见的数据增强操作包括图像旋转、平移、缩放、翻转等。
将图像数据划分为训练集和验证集(或测试集),用于模型训练和性能评估。
可选的降噪操作:根据实验需要,可以应用降噪算法去除图像中的噪声,以提高分类准确度。
这些数据预处理步骤旨在将原始图像数据整理成适合输入网络进行训练的形式。通过数据预处理,可以减少噪声和干扰,增加数据集的多样性,提高模型的学习能力和鲁棒性。
2.?网络的构建
在这个代码中,我们创建了一个新的网络类名为FakeNet,在这个网络类中

可以借由参数的选择来创造网络,但网络的整体结构有限制,只能是卷积层+全连接层的顺序。
以下是具体的形参介绍
这是一个名为FakeNet的类,它表示一个神经网络模型。以下是对其构造函数__init_的各个形参的介绍:
● input_shape:输入数据的形状。通常是一个元组或列表,表示输入数据的维度。
● affine hidden size list:一个整数列表,表示每个全连接层的隐藏单元数量。列表长度为网络的层数(不包括输入层),每个元素表示对应层的隐藏单元个数
● output_size:输出层的大小,表示神经网络的输出维度。
● use_conv:一个布尔值,指示是否在网络中使用卷积层。如果为True,则使用卷积层;如果为False,则不使用。
● conv_params:一个字典,包含了卷积层的参数设置。具体的参数包括filter_num(滤波器数量)、filter size(滤波器大小)、stride(步长)和 pad(填充大小)等。
● active_func:一个字符串,表示激活函数的类型。常见的激活函数有'ReLU'、'Sigmoid'、'Tanh'等。
● weight_init_std:一个字符串或浮点数,表示权重初始化的标准差。可以使用具体的标准差值,也可以使用预设的值,如'ReLU'表示使用针对ReLU激活函数的初始化标准差。
● weight_decay_lambda:一个浮点数,表示权重衰减(L2正则化)的强度。用于控制模型的复杂度,防止过拟合。· use_dropout:一个布尔值,指示是否在网络中使用Dropout层。如果为True,则使用Dropout;如果为False,则不使用。● dropout_ration:一个浮点数,表示要丢弃的神经元比例。仅当 use_dropout 为True 时才起作用。
●use_batchnom:一个布尔值,指示是否在网络中使用批量归一化层。如果为True,则使用批量归一化;如果为False,则不使用。以上是Fakellet类的构造函数中的各个形参的介绍。根据您的需求,可以根据这些形参来初始化和配置网络模型。
在本次手写数字识别中我们使用了两层卷积层和四层全连接层,如下

3.模型的训练
(1)Trainer训练类——专门用来训练的类,内置模型训练函数
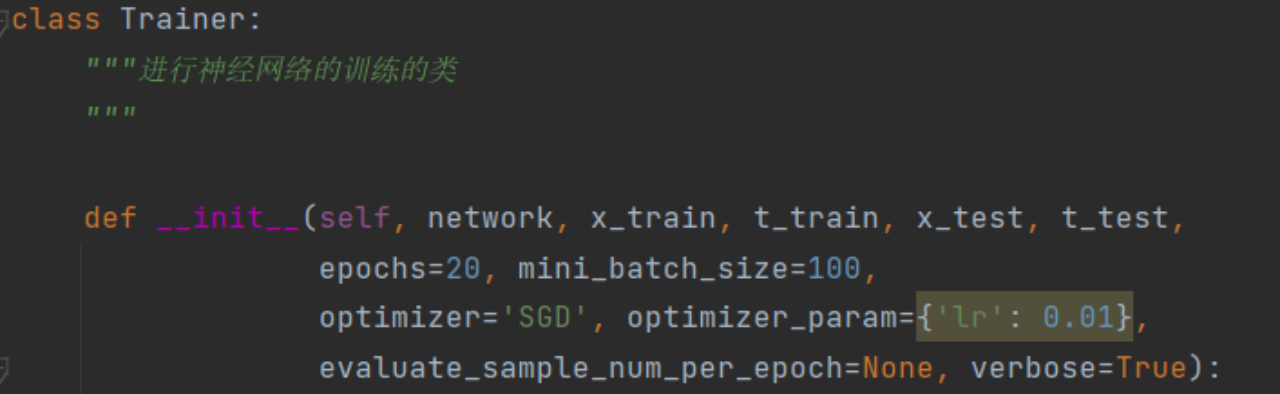
这是一个名为?Trainer 的类,用于进行神经网络的训练。以下是对其构造函数 _init__的各个形参的介绍:
● network:要训练的神经网络模型.?
● x_train:训练集输入数据。
● t_train:训练集标签数据。
● x_test:测试集输入数据
● t_test:测试集标签数据。
● epochs:训练的轮数(迭代次数),默认为20。
●mini_batch_size:每次迭代中使用的小批量样本数量,默认为100。
●optimizer:优化器的类型,指定了在训练过程中如何更新网络的权重。常见的优化器有'SGD'、'Adam'等。
●optimizer_param:一个字典,包含了优化器的参数设置。具体的参数根据不同的优化器而有所不同,一般包括学习率?lr?等。●evaluate_sample_num_per_epoch:每个epoch中用于评估的样本数量。如果为None,则使用全部测试集数据进行评估,默认为None。
●verbose:一个布尔值,指示是否打印训练过程中的详细信息。如果为 True,则打印;如果为 False,则不打印,默认为 True。
以上是?Trainen类的构造函数中的各个形参的介绍。通过提供适当的参数,可以初始化和配置训练器,并使用该训练器来训练神经网络模型。
(2)Fake优化器的使用
Trainer中所支持的优化器类型如下

其中Fake优化器是由我们独立编写,代码如下
- class?Fake:
- ????def?__init__(self,?lr=0.01,?momentum=0.9,?beta1=0.9,?beta2=0.999):
- ????????self.lr?=?lr
- ????????self.momentum?=?momentum
- ????????self.v?=?None
- ????????self.h?=?None
- ????????self.beta1?=?beta1
- ????????self.beta2?=?beta2
- ????def?update(self,?params,?grads):
- ????????if?self.v?==?None:
- ????????????if?self.h?==?None:
- ????????????????self.v?=?{}
- ????????????????self.h?=?{}
- ????????????????for?key,?val?in?params.items():
- ????????????????????self.v[key]?=?np.zeros_like(val)
- ????????????????????self.h[key]?=?np.zeros_like(val)
- ????????for?key?in?params.keys():
- ????????????self.h[key]?+=?(1-self.beta2)*(grads[key]**2?-?self.h[key])
- ????????????self.v[key]?=?self.momentum*self.v[key]?-?self.lr*grads[key]/(np.sqrt(self.h[key])+1e-7)
- ????????????params[key]?+=?(1-self.beta1)*self.v[key]
跟Adam优化器一样,采用了动量和自适应学习率的概念进行编写,属于一个简化版的Adam。
该优化器的原理如下:
初始化学习率(lr)、动量(momentum)、beta1、beta2以及v和h(用于保存每个参数的动量和历史梯度平方项)等参数。
在更新函数update中,首先检查v和h是否为None。如果是,则进行初始化,为每个参数创建相应的零数组。
对于每个参数,根据以下步骤进行更新:
计算当前参数的历史梯度平方项:self.h[key] += (1-self.beta2) * (grads[key]**2 - self.h[key])
计算当前参数的动量项:self.v[key] = self.momentum * self.v[key] - self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
更新参数:params[key] += (1-self.beta1) * self.v[key]
这个优化器的功能是根据梯度来更新模型的参数,其中包含动量(momentum)和自适应学习率(根据历史梯度平方项h进行调整)。动量可以帮助加速训练过程,而自适应学习率可以根据参数的不同特性来调整更新幅度,以使得训练更加稳定和高效。
需要注意的是,这个优化器是一个简化版本的Adam,可能并不如原版Adam具有相同的性能。如果想要使用更为成熟和广泛应用的优化器,建议使用PyTorch或TensorFlow等深度学习框架中提供的优化器实现,它们通常包含了更多的优化技巧和改进。
4.边缘检测和形态学操作相关代码
- #边缘检测
- def?edge_detection(images,?operator='sobel'):
- ????edge_images?=?[]
- ????for?gray?in?images:
- ????????if?operator?==?'sobel':
- ????????????#?边缘增强?-?Sobel算子
- ????????????sobel_x?=?cv2.Sobel(gray,?cv2.CV_16S,?1,?0)
- ????????????sobel_y?=?cv2.Sobel(gray,?cv2.CV_16S,?0,?1)
- ????????????sobel_absx?=?cv2.convertScaleAbs(sobel_x)
- ????????????sobel_absy?=?cv2.convertScaleAbs(sobel_y)
- ????????????edges_enhanced?=?cv2.addWeighted(sobel_absx,?0.5,?sobel_absy,?0.5,?0)
- ????????elif?operator?==?'laplacian':
- ????????????#?边缘增强?-?Laplacian算子
- ????????????gray?=?cv2.normalize(gray,?None,?0,?255,?cv2.NORM_MINMAX,?dtype=cv2.CV_8U)
- ????????????laplacian?=?cv2.Laplacian(gray,?cv2.CV_16S)
- ????????????edges_enhanced?=?cv2.convertScaleAbs(laplacian)
- ????????kernel?=?cv2.getStructuringElement(cv2.MORPH_RECT,?(3,?3))
- ????????#?形态学操作?-?Sobel算子?-?闭运算?0.9677???Adam?0.976
- ????????edges_close?=?cv2.morphologyEx(edges_enhanced,?cv2.MORPH_CLOSE,?kernel)
- ????????edge_images.append(edges_close)
- ????????#?开运算?0.83
- ????????#edges_open?=?cv2.morphologyEx(edges_enhanced,?cv2.MORPH_OPEN,?kernel)
- ????????#edge_images.append(edges_open)
- ????????#?膨胀?0.9567
- ????????#edges_dilate?=?cv2.dilate(edges_enhanced,?kernel,?iterations=1)
- ????????#edge_images.append(edges_dilate)
- ????????#?腐蚀?0.8544
- ????????#edges_erode?=?cv2.erode(edges_enhanced,?kernel,?iterations=1)
- ????????#edge_images.append(edges_erode)
- ????return?edge_images
以上函数实现了一种边缘检测的操作,其输入参数为一个包含多张灰度图像的列表(images),输出结果也是一个包含多张图像的列表(edge_images),其中每张图像都是经过边缘检测处理后得到的结果。
该函数提供了两种边缘检测算子:Sobel算子和Laplacian算子。默认使用Sobel算子进行边缘增强。在对每张灰度图像进行边缘检测之前,会先通过Sobel算子或Laplacian算子进行边缘增强操作,提高边缘区域的强度。然后,对增强后的边缘图像进行形态学操作,进一步增加边缘的鲁棒性。具体来说,代码中给出了四种形态学操作:闭运算、开运算、膨胀和腐蚀。用户可以根据自己的需要选择其中任意一种或多种形态学操作进行边缘检测。
最后,该函数将所有处理好的边缘图像都存储在edge_images数组中,并且将其返回作为函数输出。
(2)数据集及可视化结果
I?使用Sobel算子进行边缘检测,并在边缘检测的基础上进行形态学操作
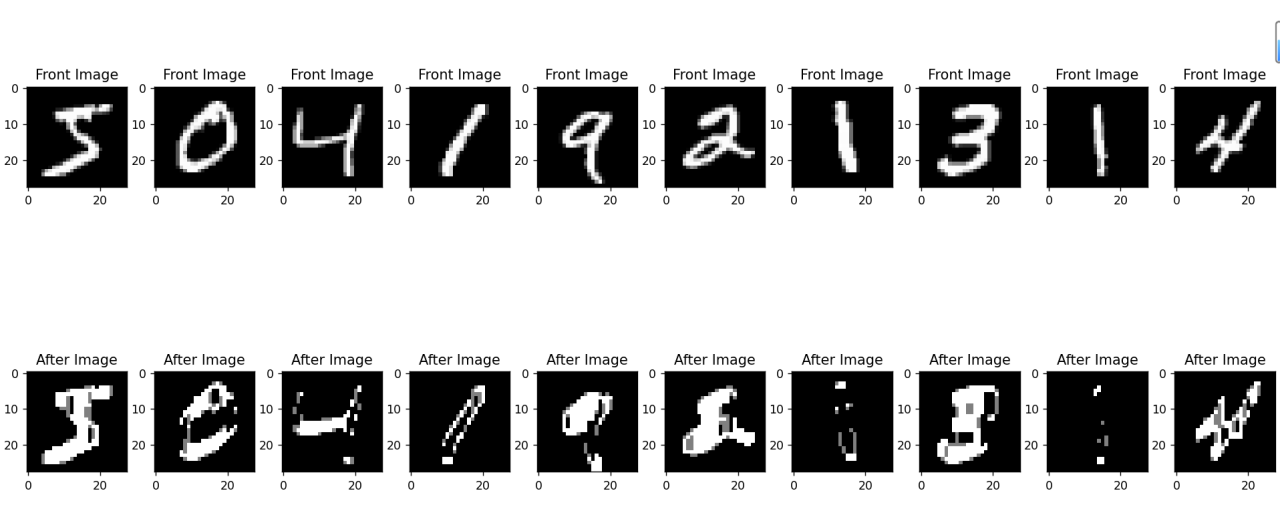
①闭运算
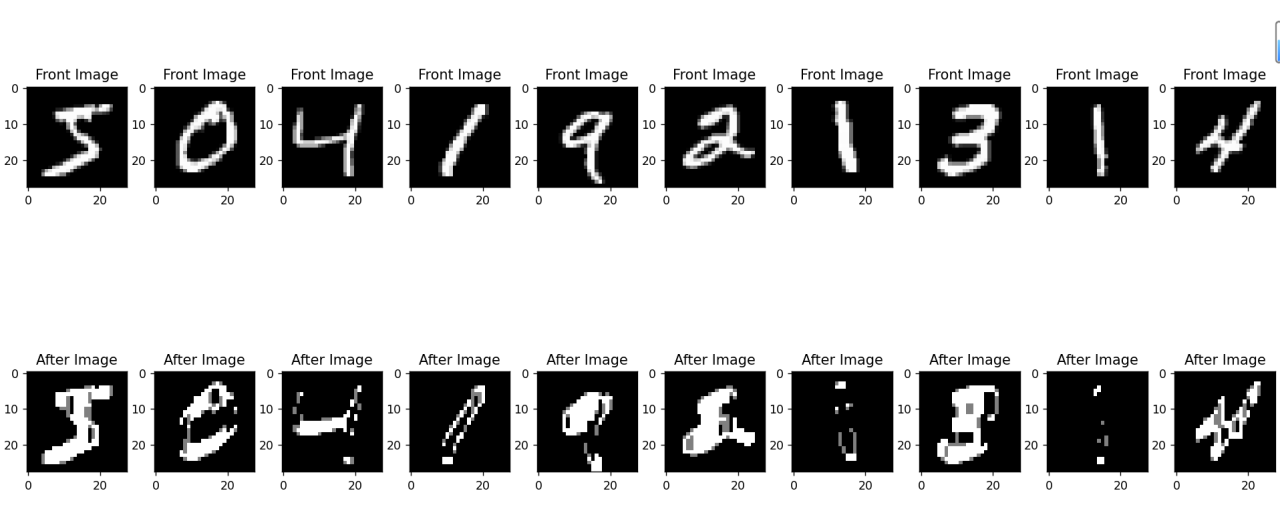
②开运算

③膨胀

④腐蚀

II ?使用Laplacian算子进行边缘检测,并在边缘检测的基础上进行形态学操作

①闭运算

②开运算

③膨胀

④腐蚀

5.模型训练结果
以下配置多种优化器进行形态学操作的计算结果(epoch为5)
①??Fake优化器+闭运算



②??Adam优化器+闭运算

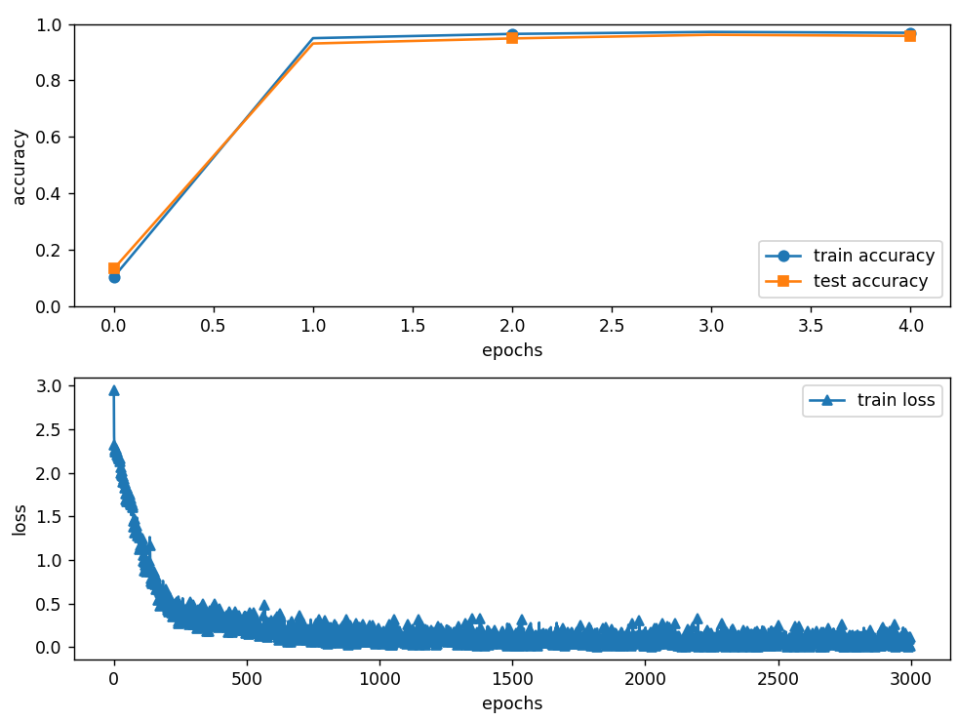
③??Fake优化器+开运算
???
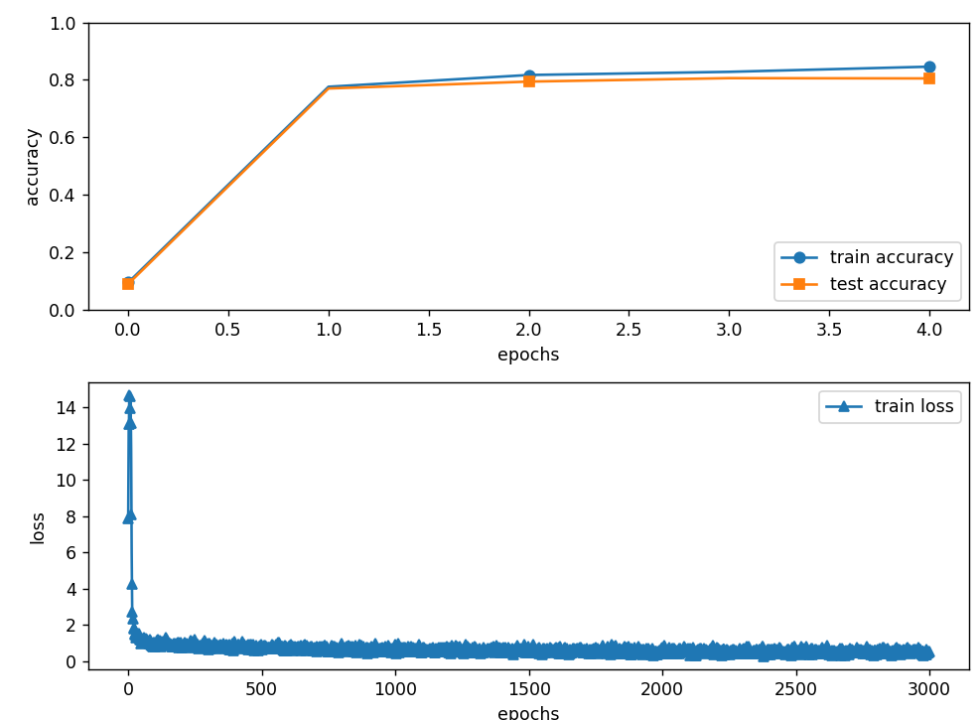
④???Fake优化器+膨胀



⑤ ??Fake优化器+腐蚀


⑥???SGD优化器+闭运算

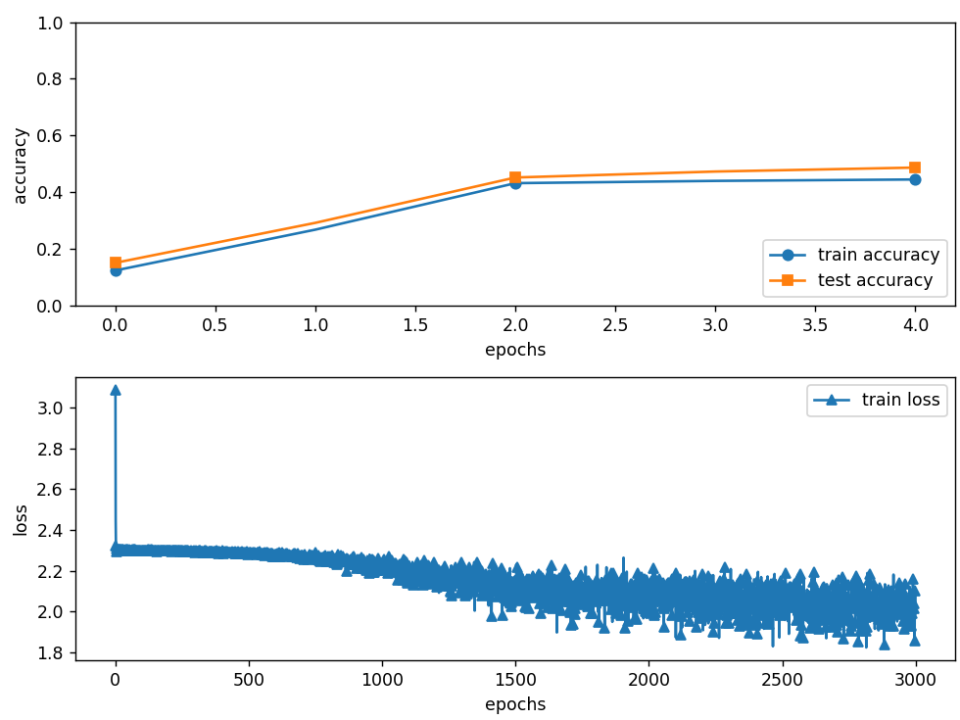
6.关键信息的保存
- #?创建保存边缘检测图像的文件夹
- save_dir?=?r"D:\wenjiananzhuang\pytorch-transfer-learning-master\pytorch-transfer-learning-master\dataset\mnist_after"
- os.makedirs(save_dir,?exist_ok=True)
- #?保存训练集边缘检测图像
- for?i?in?range(len(x_train)):
- ????#?对灰度图像进行边缘检测...
- ????edge_image?=?x_train[i][0]??#?获取灰度图像数据
- ????#?将边缘图像保存
- ????filename?=?os.path.join(save_dir,?f"x_train_{i}.jpg")
- ????cv2.imwrite(filename,?edge_image)
- #?保存测试集边缘检测图像
- for?i?in?range(len(x_test)):
- ????#?对灰度图像进行边缘检测...
- ????edge_image?=?x_test[i][0]??#?获取灰度图像数据
- ????#?将边缘图像保存
- ????filename?=?os.path.join(save_dir,?f"x_test_{i}.jpg")
- ????cv2.imwrite(filename,?edge_image)
通过以上代码,实现了本次实验中关键信息及结果的保存
五、实验测试与评估
1.鲁棒性测试
(1)增添了随机角度和噪声的鲁棒性测试,其中只添加了角度的鲁棒性测试准确度变化不大
①?未增加:

②?增加:

(2)但只要增加了噪声,无论优化器的选择抑或是形态学操作,准确度依然很低,维持在0.1左右,如下所示:

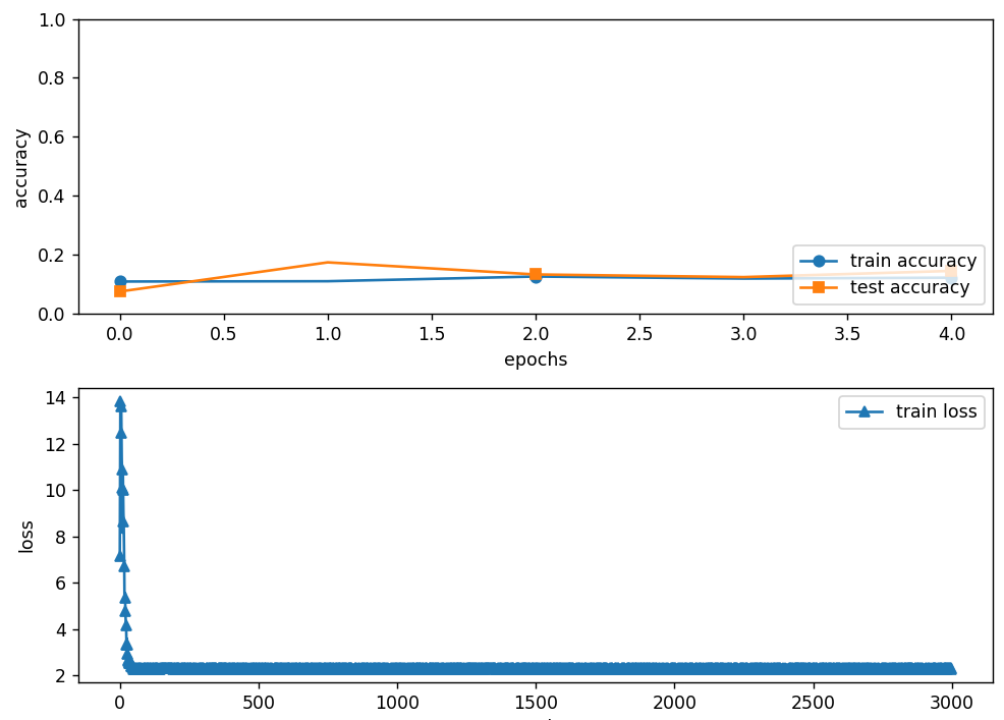
(3)鲁棒性测试相关代码
- #?鲁棒性测试
- #?角度变化
- angle?=?30??#?旋转角度??0.9709
- x_train?=?rotate(x_train,?angle,?axes=(2,?3),?reshape=False)
- x_test?=?rotate(x_test,?angle,?axes=(2,?3),?reshape=False)
- #?将?x_train?和?x_test?扩展为三维数组
- #?引入噪声
- noise_var?=?0.1??#?噪声方差
- x_train?=?random_noise(x_train,?var=noise_var)
- #x_test?=?random_noise(x_test,?var=noise_var)
- #?绘制?x_train?的前十份图
- plt.figure(figsize=(10,?5))??#?设置画布大小
2.可扩展性
(1)网络模型的可扩展性
由于使用了独立编写的FakeNet类,可以根据需要改变网络模型的结构。可以任意增加卷积层和全连接层,只需遵循卷积层在全连接层之前的顺序要求。此外,每层卷积层的参数也可以进行更改。因此,在设计新的网络模型时,可以根据任务的需求自由调整网络结构。
(2)优化器的可扩展性
采用了独立编写的Fake优化器,其功能类似于Adam优化器。可以在其他网络中使用该优化器,而不仅限于手写数字识别任务。如果想要使用更成熟、广泛应用的优化器,建议使用PyTorch或TensorFlow等深度学习框架中提供的优化器实现,这些框架通常包含更多的优化技巧和改进。
(3)边缘检测函数的可扩展性
在边缘检测函数中,可以选择使用Sobel算子和Laplacian算子,以及相应的形态学操作。可以根据具体需求选择合适的算子和操作进行边缘检测。如果需要使用其他算子或者自定义形态学操作,可以对代码进行修改和扩展。
(4)超参数调节扩展性
评估实验中使用的超参数对于不同数据集或任务的适应性。合理选择超参数的范围和初始值,使其能够适应多样的数据特征和任务要求。同时,可以使用自动化调参方法,如网格搜索或贝叶斯优化,来进一步探索最佳超参数组合并提升模型的可扩展性。
3.准确性测试
本部分将从两个方面进行准确度测试方面的评估和对比
(1)形态学操作
①闭运算

②开运算

③膨胀

④腐蚀

以上四种情况均是在Fake优化器的基础上进行的。分析以上结果可知,进行闭运算和膨胀的准确度是最高的。
(2)优化器
①?Fake优化器

②Adam优化器

③SGD优化器

以上三种情况均是进行闭运算的结果,易分析出Fake优化器对准确度的提高作用是最大的。
4.?优化器的评估
Fake和Adam的epoch数为2的时候,Fake比Adam的准确度略高一点
当epoch数为5的时候,Adam比Fake的准确度略高一点
但二者总体在epoch数较小的情况下差距不大
以下是各自在epoch数为2下的准确度对比。
Adam优化器

Fake优化器

在以上网络中,由于自己编写基本的网络类没有使用到torch等库,相对来说比较麻烦,因此我们接下来采用了torch库来编写另一个分类网络,即MultimodalResnet(多模态resnet网络)
六、实验创新
1.多模态resnet网络的设计
(1)关于多模态网络
多模态ResNet网络是一种基于深度学习的神经网络架构,用于处理多种类型的输入数据或不同模态的数据。
在多模态ResNet网络中,它扩展了传统的ResNet结构,以处理多个模态的数据,如图像、文本和音频等。这些不同的模态可能具有不同的特征表示和数据结构,因此多模态ResNet网络被设计用于融合多个模态的特征并进行联合学习。
(2)相关代码
- #?定义多模态ResNet-18网络
- class?MultiModalResnet(nn.Module):
- ????def?__init__(self,?num_classes=2,?base_model=resnet18,?pretrained=True):
- ????????super(MultiModalResnet,?self).__init__()
- ????????#?定义有色分支的ResNet-18
- ????????self.color_resnet?=?base_model(pretrained=pretrained)
- ????????#?定义灰色分支的ResNet-18
- ????????self.gray_resnet?=?base_model(pretrained=pretrained)
- ????????#?修改有色分支第一层卷积层的输入通道数
- ????????self.color_resnet.conv1?=?nn.Conv2d(3,?64,?kernel_size=7,?stride=2,?padding=3,?bias=False)
- ????????#?修改灰色分支第一层卷积层的输入通道数
- ????????self.gray_resnet.conv1?=?nn.Conv2d(3,?64,?kernel_size=7,?stride=2,?padding=3,?bias=False)
- ????????resnet?=?base_model(pretrained=pretrained)
- ????????#?将原来的全连接层替换为新的全连接层
- ????????resnet.fc?=?nn.Linear(2000,?num_classes)
- ????????#?将修改后的全连接层赋值给模型的fc属性
- ????????self.fc?=?resnet.fc
2.?关于多模态resnet网络的思考
由于任务的目标是对图像进行边缘检测,我们小组认为原图像浪费有点可惜,就尝试了一个支持多分支输入的网络——多模态网络。
在我们的多模态网络中,我们应用了两种不同的预处理方式来生成两个分支的输入数据。第一个分支使用经过图像增强处理的原始图像,从中学习提取图像的颜色特征。而第二个分支则通过边缘检测和形态学操作生成灰度图像,以便学习图像的边缘轮廓特征。这样做的目的是通过多个分支学习到更丰富的特征表示,进一步提高图像处理任务的性能。
为了组合这些特征表示,我们引入了三个ResNet模型。该模型负责提取前两个分支的特征表示,并通过全连接层将它们合并在一起。这种多模态网络结构允许我们同时考虑颜色特征、边缘轮廓特征以及它们的组合特征,从而获得更全面和准确的图像表示和处理结果。
通过采用多模态网络,我们能够充分利用图像中的多种信息,并从中学习到更丰富和有用的特征表示。这种方法在处理图像任务时具有潜力,可以提高分类、识别或分割等任务的性能,为图像处理领域的研究和应用带来新的可能性。
3.边缘检测函数
(1)测试代码
- def?apply_edge_detection(image_path,?category_name,?index,?lower_threshold,?upper_threshold,?laplacian_kernel_size):
- ????#?读取图像
- ????image?=?cv2.imread(image_path)
- ????#?转换为灰度图像
- ????gray?=?cv2.cvtColor(image,?cv2.COLOR_BGR2GRAY)
- ????#?边缘增强?-?Sobel算子
- ????sobel_x?=?cv2.Sobel(gray,?cv2.CV_16S,?1,?0)
- ????sobel_y?=?cv2.Sobel(gray,?cv2.CV_16S,?0,?1)
- ????sobel_absx?=?cv2.convertScaleAbs(sobel_x)
- ????sobel_absy?=?cv2.convertScaleAbs(sobel_y)
- ????edges_enhanced_sobel?=?cv2.addWeighted(sobel_absx,?0.5,?sobel_absy,?0.5,?0)
- ????#?形态学操作?-?Sobel算子
- ????kernel?=?cv2.getStructuringElement(cv2.MORPH_RECT,?(3,?3))
- ????edges_sobel?=?cv2.morphologyEx(edges_enhanced_sobel,?cv2.MORPH_CLOSE,?kernel)
- ????#?边缘增强?-?Laplacian算子
- ????edges_enhanced_laplacian?=?cv2.Laplacian(gray,?cv2.CV_16S,?ksize=laplacian_kernel_size)
- ????edges_enhanced_laplacian?=?cv2.convertScaleAbs(edges_enhanced_laplacian)
- ????#?形态学操作?-?Laplacian算子
- ????edges_laplacian?=?cv2.morphologyEx(edges_enhanced_laplacian,?cv2.MORPH_CLOSE,?kernel)
- ????print(
- ????????f"Processing:?{category_name}:?{index},?Threshold:?({lower_threshold},?{upper_threshold}),?Laplacian?Kernel?Size:?{laplacian_kernel_size}")
- ????return?edges_sobel,?edges_laplacian
(2)实验效果
可以对图像分别进行sobel算子和Laplacian算子的增强,并保存在相应的文件夹中,采用了蜜蜂和蚂蚁的数据集,具体效果如下:



(3)结果评估
经过尝试不同优化器、边缘检测和其他相关参数的调整,准确度最高仅达到约0.7左右,效果依然不太理想,这可能是因为网络本身的设计存在一些不完善或草率的地方。

七、实验总结与思考
1.实验结果讨论
根据实验结果的分析,我们发现在使用不同优化器进行网络训练时,Adam优化器在手写数字图像分类识别任务中表现较好,达到了较高的准确度。相比之下,Fake优化器的效果较差,可能是由于其权重更新的不稳定性导致的。此结果表明,在该任务中选择合适的优化器对于提高分类准确度至关重要。
在边缘检测实验中,我们观察到边缘检测技术在一定程度上提升了分类识别的准确度。通过突出图像中的边缘轮廓,我们能够更好地捕捉到手写数字的特征信息,从而改善分类效果。
然而,本次实验也存在一些局限性:
首先,数据集规模和多样性有限。MNIST手写数字数据集规模较小,并且只包含10个数字的手写样本。在实际应用中,手写数字样本可能更加复杂、多样化,因此需要更大规模且多样性更强的数据集来提高模型的泛化能力。
其次,并未观察到多模态ResNet网络在本实验中带来明显的改进效果。可能是因为我们的网络不算规范的多模态网络,因为多模态网络本应该是多种类型的输入数据,但我们的输入数据类型一致,均是图片,但各个分支不同,一支是经过了图像增强的原始图像,另外一支是经过边缘检测及形态学操作的灰度图像,我们想的是可以学习图像的颜色特征,边缘轮廓特征,还能学习下两者结合的特征。
2.实验局限性分析
本次实验的局限性主要包括数据集规模和多样性不足、多模态网络的效果不理想等方面。由于数据集的限制,我们可能无法充分挖掘出网络模型和优化器的潜力。而多模态网络在本实验中的表现也不尽如人意,需要进一步改进和优化。
此外,在边缘检测实验中,我们仅使用了简单的边缘检测技术,并未尝试更高级的边缘检测算法,可能导致提升效果受到限制。
3.改进方向
针对实验中的局限性,下一步的改进方向可以从以下几个方面展开:
首先,扩大数据集规模并增加多样性。收集更多的手写数字样本,以及包括不同字体、不同书写风格等多样性,在更大规模和更真实的数据集上进行训练和测试,提高模型的泛化能力。
其次,进一步优化多模态网络的结构。根据实验结果的分析,优化多模态网络的设计,考虑更合适的特征融合方式和注意力机制,以提升网络的性能和效果。
另外,尝试其他优化器的使用。除了Adam和Fake优化器,可以尝试RMSprop等其他常用优化器,并调整其参数设置,以找到更适合手写数字图像分类任务的优化方法。
同时,探索更先进的边缘检测技术。尝试应用Canny边缘检测算法、基于深度学习的边缘检测方法等,以提升边缘检测的效果,进一步改善分类准确度。
4.实验思考
本次实验通过构建不同网络模型和优化器,应用边缘检测技术,研究了手写数字图像的分类识别任务。实验结果表明,在选择适当的优化器和引入边缘检测技术的情况下,可以提高分类准确度。
然而,实验也揭示了数据集规模和多样性、多模态网络效果以及边缘检测技术的局限性。
在下一步的改进中,我们将致力于扩大数据集规模和多样性,优化多模态网络的结构,尝试其他优化器的使用,并探索更先进的边缘检测技术。这将有助于提高手写数字图像分类识别任务的准确度和性能,进一步推动相关领域的研究与发展。
?
八、实验心得
为了完成本次基于深度学习的图像信号处理系统设计,我们小组五人首先集体学习了计算机视觉的相关知识,并完成了python相关库的安装。在协作完成实验思路构建的基础上,两人主要负责代码的编写与调试,三人分别负责数据集的查找、实验报告的撰写和答辩ppt的制作。
总的来说,通过本次合作学习,我们小组每个人都收获颇丰,以下是具体内容:
1.计算机视觉深度学习:通过手写数字图像分类识别任务,我们深入了解了计算机视觉领域的深度学习方法。我们学到了如何构建卷积神经网络(CNN)模型,并掌握了常见的图像处理技术,例如边缘检测和特征提取。这对我们理解和应用计算机视觉算法具有重要意义。
2.模型选择和优化器:我们实验中尝试了不同的网络模型和优化器,并对它们的性能进行了评估。我们了解了不同模型的结构和特点,以及如何根据任务需求选择合适的模型。此外,我们还探索了不同优化器的优缺点,并学习了如何调整超参数以提高模型的性能。
3.数据预处理与增强:在实验中,我们遇到了数据集不平衡和噪声等问题。为了解决这些问题,我们采取了数据预处理和增强的方法,例如平衡采样和图像增强技术。通过这些措施,我们提高了模型的鲁棒性和泛化能力,并有效改善了模型在特定情况下的表现。
4.结果评估和可视化:我们实验中对模型进行了全面的结果评估,并利用各种指标对其性能进行了量化分析。同时,我们还运用可视化技术,如混淆矩阵和学习曲线,直观地展示了模型的表现。这些评估和可视化技术为我们提供了深入理解模型性能的工具,并帮助我们调整和改进模型。
5.团队合作和沟通:本次实验是团队合作完成的,我们通过有效的沟通和协作共同完成了任务。在团队中,我们学会了相互倾听、合理分工和有效协调的重要性。这不仅提高了我们的合作能力,也培养了我们的团队意识和领导力。
这些收获将对我们今后的学习、研究和职业发展产生积极的影响。
附录
附录1
Adam优化器具体实现代码
| class?Adam: ? |
附录2
SGD优化器具体实现代码
| class?SGD: |
2024-1-20
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!