Spark流式读取文件数据
发布时间:2024年01月19日
流式读取文件数据
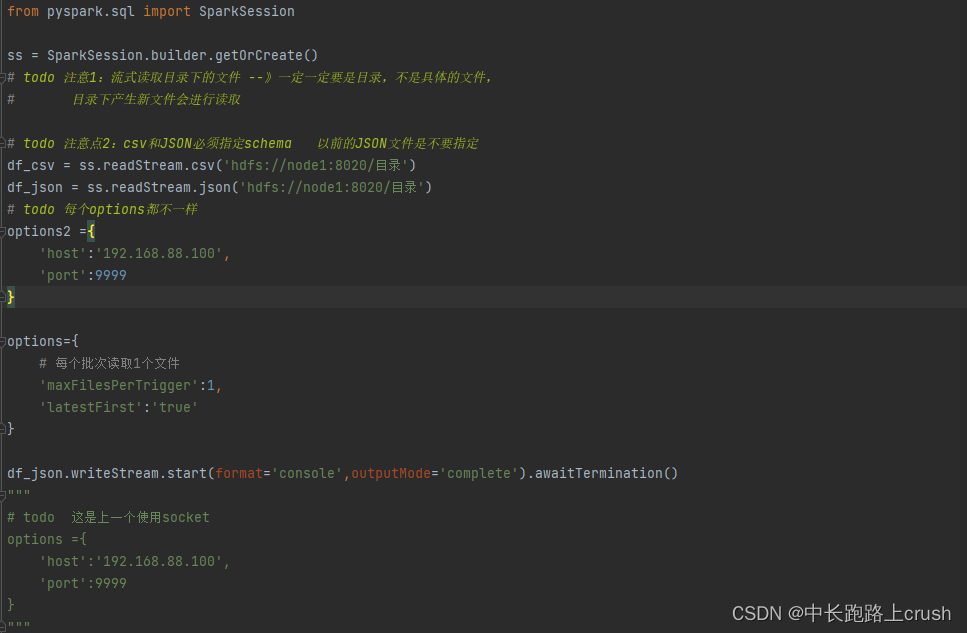
from pyspark.sql import SparkSession
ss = SparkSession.builder.getOrCreate()
# todo 注意1:流式读取目录下的文件 --》一定一定要是目录,不是具体的文件,
# 目录下产生新文件会进行读取
# todo 注意点2:csv和JSON必须指定schema 以前的JSON文件是不要指定
df_csv = ss.readStream.csv(‘hdfs://node1:8020/目录’)
df_json = ss.readStream.json(‘hdfs://node1:8020/目录’)
# todo 每个options都不一样
options2 ={
‘host’:‘192.168.88.100’,
‘port’:9999
}
options={
# 每个批次读取1个文件
‘maxFilesPerTrigger’:1,
‘latestFirst’:‘true’
}
df_json.writeStream.start(format=‘console’,outputMode=‘complete’).awaitTermination()
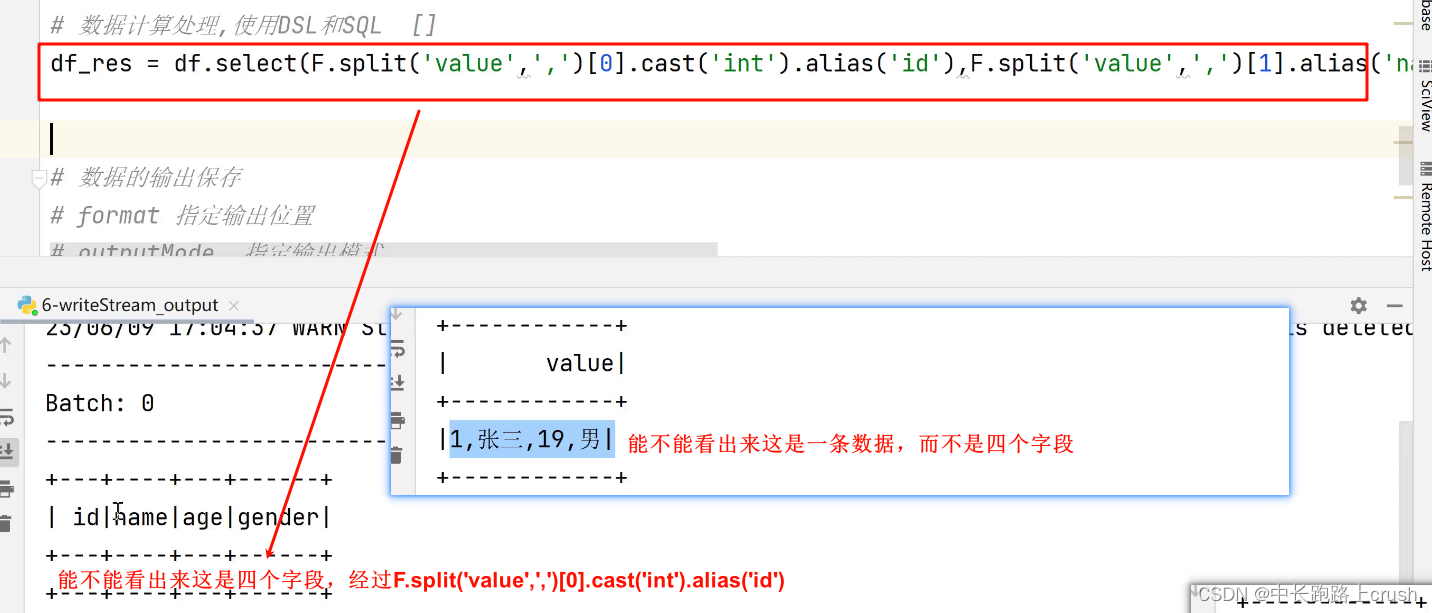
流式读取文件的注意点
删除已经处理的文件(文件一)
你修改了文件一的内容,不修改文件名,你再次上传会发现它不去读取
但是你不修改文件内容,修改文件名,你再上传会发现它还会去读取
场景:某天你上传一个文件,发现它不做任何读取和处理,你需要考虑,这个文件名以前是否处理过了。
文件的读取方式在实际开发中用的比较少,每生产一条数据,就要生成一个文件(
单单正对流处理)
但是,如果将多条数据收集之后同一写入文件,那就变成了和批处理方式一样的开发
文件读取数据的参数指定
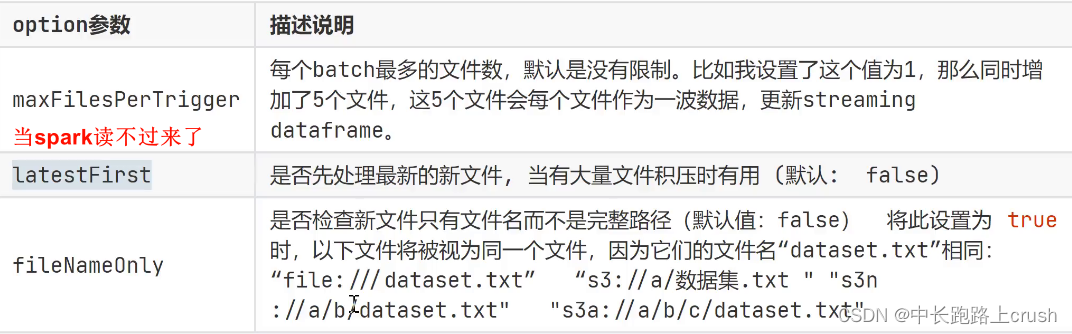
当spark读不过来的时候,可以调整
latestFirst,设置为True就会处理最新的文件
true时,就会将所有相同文件名认定为同一个文件,不管全部路径是否相同,这就涉及到相同的路径不会连续处理上面刚说的
文章来源:https://blog.csdn.net/weixin_58026490/article/details/135702792
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章