MongoDB 索引管理
文章目录
前言
索引是数据库中离不开的话题,其作用是提高数据的获取性能。与关系型数据库一样,MongoDB 同样可以利用索引提高查询效率。如果没有索引 MongoDB 的查询需要扫描集合中的每一条记录,然后挑选出与查询条件匹配的文档记录。也就是常说的全表扫描,一个非常耗时的操作。
MongoDB 默认索引数据结构也是 B+Tree 与关系型数据库的索引相似。本篇文章将介绍 MongoDB 中的索引与维护。
1. 术语介绍
本小节介绍 MongoDB 索引相关的术语,不难发现 MongoDB 索引与关系型数据库使用的是同一套理论,如果懂一款关系型数据库,应该会很好理解。
1.1 index / key
索引,是一种数据结构,在 MongoDB 中使用 B+tree 算法。索引只包含索引字段,不包含数据,叶子节点记录的是一行数据的物理位置,与 PostgreSQL 存储方式类似,数据与索引分开存储。
1.2 Coverd Query
覆盖查询,MongoDB 也支持多列索引,所以也可以使用索引完成覆盖查询。所有需要返回的数据都包含在索引中,不需要额外的字段,就可以不需要从数据页加载数据,查询的性能也会得到提升,但是存储成本和维护成本也会增加。
1.3 IXSCAN / COLLSCAN
索引扫描 / 集合扫描,指的是表的方法方式。如下表是 MongoDB 中的术语。
| SQL 术语概念 | MongoDB 术语概念 | 解释说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表 / 集合 |
| row | field | 数据字段 / 域 |
| index | index | 索引 |
所以 IXSCAN 指的是索引扫描,通过索引定位到行记录。COLLSCAN 指的是全表扫描,在 MongoDB 中表也叫集合。通过索引定位记录的速度肯定要比整个集合搜索一次的效率要高很多,所以优秀的索引设计也是数据库性能的关键。
1.4 Selectivity
选择性,也可称为过滤性,是判断一个字段是否适合创建索引的重要参考指标。
例如,在一个 10000 条记录的集合中:
- 满足 gender = F 的记录有 4000 条
- 满足 city = LA 的记录有 100 条
- 满足 ln = Tony 的记录有 10 条
条件 ln 能过滤最多的数据,所以它的选择性最好,其次是 city 字段,gender 字段最弱。
如果有一条查询需要同时满足三个字段的条件,只能创建一个单列索引,那么最优的选择是选择性最好的字段。
1.5 Index Prefix
索引前缀,当创建一个 a, b, c, d 四个字段的复合索引时,该索引会有三个前缀。分别是:
- a
- a, b
- a, b, c
所有索引前缀都可以被该索引覆盖,所以就无需针对使用到这些前缀的查询创建额外的索引。
2. 索引原理
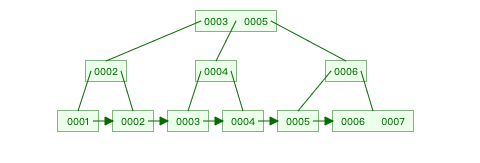
B+Tree 多路平衡搜索树,是一种树形分层结构,第 1 层为顶部节点,第 2 层为分支节点,均只保存索引字段上的键值,第 3 层为叶子节点,除了保存索引字段的键值外,还有一个指针变量,指向具体数据文件上的某条文档记录的位置。
推荐使用:B-Tree 动画演示
B+Tree 类型索引结构有以下几个特点。
- 每个叶子节点的深度都相同,通常为 3 层或 4 层。
- 由于第 1 层顶部节点和第 2 层分支节点几乎总被加载到内存中,因此查询文档记录时,物理磁盘的读取实际次数通常仅为一次或两次,性能非常可观。
- 叶子节点是通过双向链表连接且已经排好序的,因此对于范围查询来说,直接遍历叶子节点的链表就能快速定位匹配文档记录的指针位置。
- 数据不断的写入,也会涉及到索引维护,索引节点的拆分和分裂移动,是一个非常耗时的操作。
3. 索引的维护
MongoDB 中有 8 种索引类型,分别是单列索引、组合索引、多值索引、地理位置索引、全文索引、TTL 索引、部分索引、哈希索引。
3.1 创建索引语法
在 MongoDB 集合中插入文档记录时,如果没有指定 _id 字段的值,则会默认生成一个 ObjectID 类型的值并赋给 _id 字段,同时也会默认在 _id 字段上创建一个具有唯一性的主键索引。
在集合其他字段上创建索引的语法:
db.collection.createIndex(Keys, options)
- keys:指定需要创建索引的字段,可以是一个字段或多个字段,其值的格式为 {“字段名” : “索引类型”},索引类型可以为 1 或 -1,当为 1 时表示创建一个升序排列的索引,当为 -1 时表示创建一个降序排列的索引。索引类型还可以为 text、hashed 文本类型 hash 类型索引等。
- options:为可选字段,例如通过 name 指定索引的名称,unique 指定索引的唯一性等。
3.2 单字段索引
给如下示例集合创建一个单列索引。
db.schools.insertOne(
{
"_id": ObjectId("570c04a4ad233577f97dc459"),
"studentsEnrolled": 1034,
"location": { state: "NY", city: "New York" }
}
)
选择给 studentsEnrolled 字段创建一个升序索引。
db.schools.createIndex({studentsEnrolled:1})
可通过如下命令查询一个集合的索引。
db.schools.getIndexes({})
{
"v": 2,
"key": {
"_id": 1
},
"name": "_id_",
"ns": "test.schools"
}
{
"v": 2,
"key": {
"studentsEnrolled": 1
},
"name": "studentsEnrolled_1",
"ns": "test.schools"
}
索引记录中 v 表示索引记录的版本号,key 表示索引创建哪个字段上,name 表示索引名称,ns 表示索引命名空间依次为索引所在的 “数据库名.集合名”。
3.3 多字段复合索引
给 schools 集合创建一个复合索引。
db.schools.insertOne(
{
"_id": ObjectId("570c04a4ad233577f97dc459"),
"studentsEnrolled": 1034,
"location": { state: "NY", city: "New York" }
}
)
可通过如下命令创建一个多字段的复合索引。
db.products.createIndex( { "studentsEnrolled": 1, "location": 1 } )
执行成功后,通过如下命令查询 schools 集合中的索引情况。
{
"v": 2,
"key": {
"_id": 1
},
"name": "_id_",
"ns": "test.schools"
}
{
"v": 2,
"key": {
"studentsEnrolled": 1
},
"name": "studentsEnrolled_1",
"ns": "test.schools"
}
{
"v": 2,
"key": {
"studentsEnrolled": 1,
"location": 1
},
"name": "studentsEnrolled_1_location_1",
"ns": "test.schools"
}
复合索引包含两个字段,分别是 studentsEnrolled 和 location,B+tree 中的叶子节点按照 studentsEnrolled 字段升序排列,对于相同的 studentsEnrolled 将以 location 字段进行升序排列。
3.4 数组的多列索引
MongoDB 支持数组类型的字段,涉及到数组内部的查询,如精确匹配数组中所有元素的查询、匹配其中任意元素的查询、匹配特定位置元素的查询等。为了提高数组查询的性能,可以在数组类型的字段创建索引,当 MongoDB 在构造索引的 B-Tree 时,将默认在 B-Tree 叶子节点为数组中的每一个元素创建索引条目。
集合数据如下:
{ _id: 5, type: "food", item: "aaa", ratings: [ 5, 8, 9 ] }
{ _id: 6, type: "food", item: "bbb", ratings: [ 5, 9 ] }
{ _id: 7, type: "food", item: "ccc", ratings: [ 9, 5, 8 ] }
其中 ratings 字段为数组类型,在其上面创建一个索引,语法如下。
db.inventory.createIndex({"ratings": 1})
数组中的每一个元素,都会被当作一个独立的键值构建在 B+tree 叶子节点中,如 ratings: [ 5, 8, 9 ] 被拆成 5、8、9 共三个键存储在索引条目中,且这 3 条索引记录都指向同一个文档 { _id: 5 } 在数据文件中的位置。
3.5 全文索引
创建一个 stores 集合。
db.stores.insert(
[
{ _id: 1, name: "Java Hut", description: "Coffee and cakes" },
{ _id: 2, name: "Burger Buns", description: "Gourmet hamburgers" },
{ _id: 3, name: "Coffee Shop", description: "Just coffee" },
{ _id: 4, name: "Clothes Clothes Clothes", description: "Discount clothing"},
{ _id: 5, name: "Java Shopping", description: "Indonesian goods" }
]
)
创建一个 name 字段的全文索引语句示例如下:
db.stores.createIndex({'name': 'text'})
查看该集合的索引信息:
{
"v": 2,
"key": {
"_id": 1
},
"name": "_id_",
"ns": "test.stores"
}
{
"v": 2,
"key": {
"_fts": "text",
"_ftsx": 1
},
"name": "name_text",
"ns": "test.stores",
"weights": {
"name": 1
},
"default_language": "english",
"language_override": "language",
"textIndexVersion": 3
}
在创建 B+tree 索引过程中,会将文本字符串按特定语言中的分隔符进行分词,生成一个键值对加入到索引条目,插入 B+tree 的叶子节点。由于在创建文本索引过程中会对每一个主干单词生成索引条目,所以文本索引所需的空间可能是巨大的。
文本索引在插入过程中,要验证分词,所以对插入性能也会有所影响。
3.6 Hash 索引
创建 Hash 索引时,利用 hash 函数计算字段的值,保证计算后的取值更加均匀分布。
db.stores.createIndex({'name':'hashed'})
Hash 索引仅支持等值查询,不支持范围查询。
3.7 TTL 索引
TTL 索引是一种特殊的单字段索引,用户可以使用 TTL 索引淘汰过期数据,节省存储空间。比如对于存储事件日志的场景,如果只需要存储最近 1 小时的数据,可以在每条文档中指定 “lastModifiedDate” 字段记录生成的时间,然后按照这个字段创建 1 个 1 小时过期的 TTL 索引:
db.eventlog.createIndex( { "lastModifiedDate": 1 }, { expireAfterSeconds: 3600 } )
创建 TTL 索引字段的值类型必须是一个日期类型或者包含日期属性的数组。
每个 mongod 进程在启动时,会创建一个 TTLMonitor 后台线程,这个后台线程会每隔 60s 发起 1 轮 TTL 清理操作。每轮 TTL 操作会在搜集完实例上的所有 TTL 索引后,依次对每个 TTL 索引生成执行计划并执行数据清理。
3.8 删除索引
删除集合中指定索引的语法如下:
db.collection.dropIndex(index)
index 参数表示字符串类型的索引名称或创建索引时指定的文档记录。
如下示例集合中,有两个索引:
{
"v": 2,
"key": {
"_id": 1
},
"name": "_id_",
"ns": "test.stores"
}
{
"v": 2,
"key": {
"_fts": "text",
"_ftsx": 1
},
"name": "name_text",
"ns": "test.stores",
"weights": {
"name": 1
},
"default_language": "english",
"language_override": "language",
"textIndexVersion": 3
}
{
"v": 2,
"key": {
"name": "hashed"
},
"name": "name_hashed",
"ns": "test.stores"
}
db.stores.dropIndex("name_hashed")
一次性删除多个索引语法:
db.stores.dropIndex(["name_hashed", "name_text"])
3.9 后台创建索引
创建索引时,将默认使用前台的方式,执行过程中会堵塞所有读写操作。可通过指定 background 参数设置索引后台创建,与 MySQL 中的 Online DDL 类似,后台创建索引虽然不会堵塞读写操作,但是执行时间会变长。
语法如下:
db.stores.createIndex({'name':'hashed'}, {background: true})
4. 执行计划
未完待续
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 实战——Mac M2 安装mat工具
- django的gunicorn的异步任务执行
- 遗传算法优化BP神经网络实现光伏出力预测(附带MATLAB代码)
- 国企石油化工单位任职资格体系搭建案例
- Shell脚本小游戏:石头剪刀布
- 日常之伦敦金等额加仓法的简介
- Python机器学习入门:从零开始,10天学会
- RAM读写测试
- springboot/java/php/node/python宠物领养系统【计算机毕设】
- 如何使用批量重命名技巧:将文件名称中文翻译成英文