想要学习大语言模型?这些开源模型带你轻松入门!(附论文和代码)
要说现在人工智能界最火的东西,那大语言模型肯定榜上有名,这可不只是技术上的小花招,它们真的能开启新世界的大门,让咱们想到的事情都能变成现实。
入门级
GPT-2
论文:Language Models are Unsupervised Multitask Learners
刚开始接触大语言模型的话,OpenAI推出的GPT-2小模型版,比如那个117M参数的,是个不错的起点。这类模型对电脑配置要求没那么高,比较容易上手,就像玩游戏先从简单级别开始一样,摸索这些小模型可以帮你逐渐搞懂大语言模型的套路,为将来挑战更高级别的模型做好准备。
DistilBERT
论文:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
它就像是BERT的迷你版,在把BERT的主要特点都保留下来的同时还变得更小巧,速度也快了不少。如果你是新手或者已经有点基础,想进一步弄明白Transformer和BERT是怎么回事,DistilBERT就挺合适的。

中级
BERT
论文:Pre-training of Deep Bidirectional Transformers for Language Understanding
如果你已经对Transformer有所了解了,那么下一步可以深入研究一下BERT的基础版本。BERT基本上就是现在很多高级NLP模型的根基,用途超级广,当你开始学习和实践BERT,就能更深刻地理解那些预训练语言模型是怎么运作的,以及它们是怎样被应用到各种各样的任务中去的。
RoBERTa
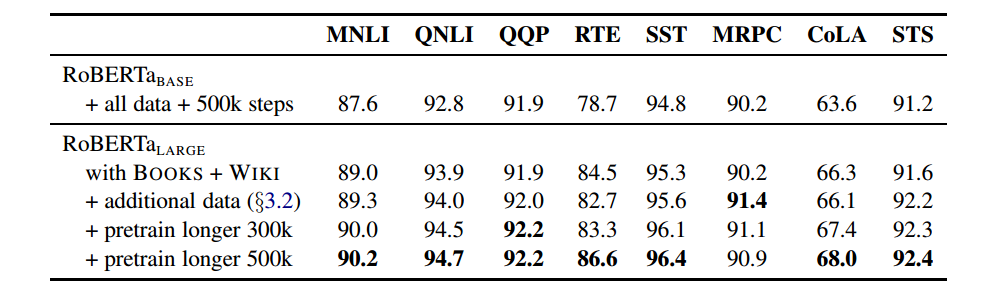
论文:RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa其实是对BERT的升级版,在性能上做了很多提升。如果你想深入了解语言模型,看看RoBERTa是怎么改进的,这对你挺有好处的,可以提升对预训练语言模型的认识和应用能力。
Transformer-XL
论文:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
TransformerXL就像是Transformer的加强版,专门为了处理那些长篇大论的文本而设计的,它会把把文本切成一段段的,然后让这些段落之间能记住彼此的信息,还有一种特别的方式来理解单词之间的位置关系。这些都让TransformerXL在处理那些需要考虑很多上下文的任务上表现得特别棒,像是写作、总结、回答问题或者是学习语言的规则之类的。

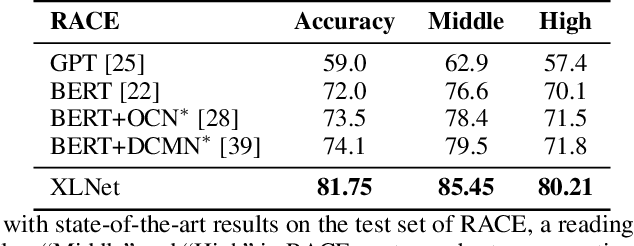
XLNet
论文:XLNet: Generalized Autoregressive Pretraining for Language Understanding
一种预训练语言模型方法,这个模型用了一种特别的办法,叫做广义回归预测,这样它就能像我们人类一样,在理解文本的时候既看前面的内容,也看后面的内容,还借鉴了Transformer-XL模型的思路,所以它处理双向文本信息的能力超强。
高级
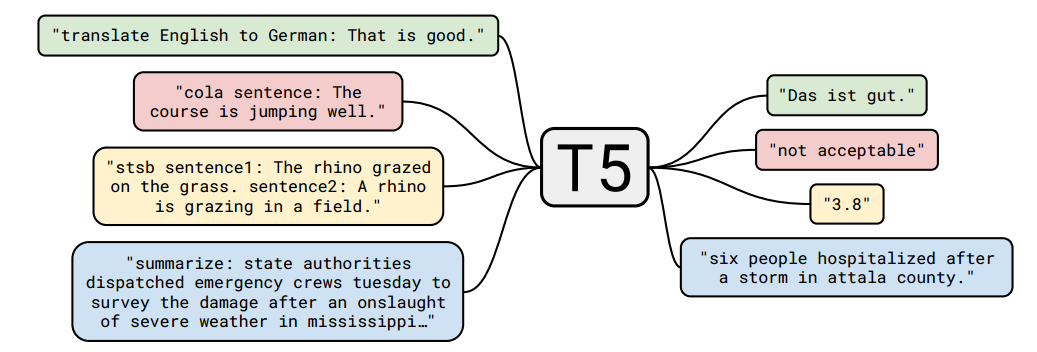
T5
论文:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Google的T5模型用的是一种文本到文本的方式,能搞定好多不同的NLP任务,这个模型有扎实的理论知识和实战经验才行,特别适合那些经验丰富的研究人员和开发者。如果你想在NLP领域深入挖掘,那可以试试学习和应用T5模型吧!
BART
论文:BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
一个强大的多任务语言模型,它融合了双向编码器和自回归解码器的架构,这种设计让BART既能理解文本全貌,又能生成连贯的内容。它通过破坏并恢复文本的预训练方式让模型擅长于理解和重构信息,在文本摘要、翻译、问答等自然语言处理任务上表现优秀。
另外还整理了一些2023年开源大语言模型,大家可以了解一下大语言模型的新进展。
?LLaMA/LLaMA 2
LLaMA(Large Language Model Family of AI)是由Meta发布的大型语言模型系列,包含不同版本如LLaMA和LLaMA 2,每个版本都有特色和改进。这些模型经过训练,能处理多种NLP任务,如文本分类、问答和生成,它能够在通过预训练捕获语言的广泛特性,以适应不同的语言处理需求。
BLOOM
Bloom是BigScience团队开发的一个超大型多语言模型,用来处理多种自然语言的任务。它训练了好几种语言,用了大量的文本数据,参数有高达1760亿个!它特别厉害的地方在于,它即使在一张GPU上也能高效处理大量文本,并且架构设计得很灵活,可以根据不同的需求进行调整或扩展,适合各种语言处理任务。
MPT-7B
MPT是由MosaicML团队推出的英文预训练大模型,基础版本包含70亿参数,在大量数据上训练,支持超长输入,使用FlashAttention和FasterTransformer优化速度。MPT与原版LLaMA性能相当,有三个变体::MPT-7B-Instruct,用于遵循简短指令;MPT-7B-Chat,用于多轮聊天对话;以及MPT-7B-StoryWriter-65k+,用于阅读和编写故事,支持65k tokens的超长上下文,用小说数据集微调。
Vicuna-13B
一个基于LLaMA的大型语言模型,通过使用监督数据微调,实现了高性能的对话生成。该模型在LLaMA-13B的基础上进行微调,数据集来源于ShareGPT产生的用户对话数据,共包含70K条数据。Vicuna-13B的性能表现优秀,通过GPT-4作为评判标准,该模型在超过90%的情况下与OpenAI的ChatGPT和Google Bard相当,并且在超过90%的情况下优于LLaMA和斯坦福大学的Alpaca等其他模型。
关注下方《享享学AI》
回复【LLM开源】获取完整论文和代码
👇
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!