Datax多源数据同步工具介绍、详解及部署使用
1、datax介绍
Datax是一款支持多数据源的数据采集框架
-mysql、-oracle、-db2、-mongodb、-hdfs
异构数据源(异构数据库系统是相关的多个数据库系统的集合)离线同步工具
多种不同类型的数据库可进行数据交叉同步
Task介绍
结构-----[reader-channel-writer] channel:缓冲模块
Reader负责抽取数据,而writer写入
其中还包括transformer,可对数据进行自定义处理
taskgroup介绍
一个job分成多个task 再按并发要求数量分成多个taskgroup 每个taskgroup固定可并发数为5 并发要求数量是自定义(配置)的
假设一个job被分成100个task,并发要求数量为20,则可分为20/5 个组taskgroup 每个taskgroup 有25个task
Datax的安装
最好centos7及以上,因为centos7及以上系统自带python
将datax包解压 用python执行python文件即可
2、参数配置简单说明
job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": { /*读取数据源信息参
"column": [], 数配置*/
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": { /*写数据源信息参
"encoding": "", 数配置*/
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": "",/*就是上述并发数量设置,决定taskgroup数量*/
"byte": "", /*控制每秒多少字节*/
"record": "" /*每秒多少条数*/
}
}
}
}
3、直接使用phython执行
执行方式
datax目录下 – python bin/datax.py ./job/job.json
这里的job.json可以在官网进行查询配置格式,进行自定义配置
查看参数结构
datax目录下 bin/datax.py -r xxxreader -w xxxwriter
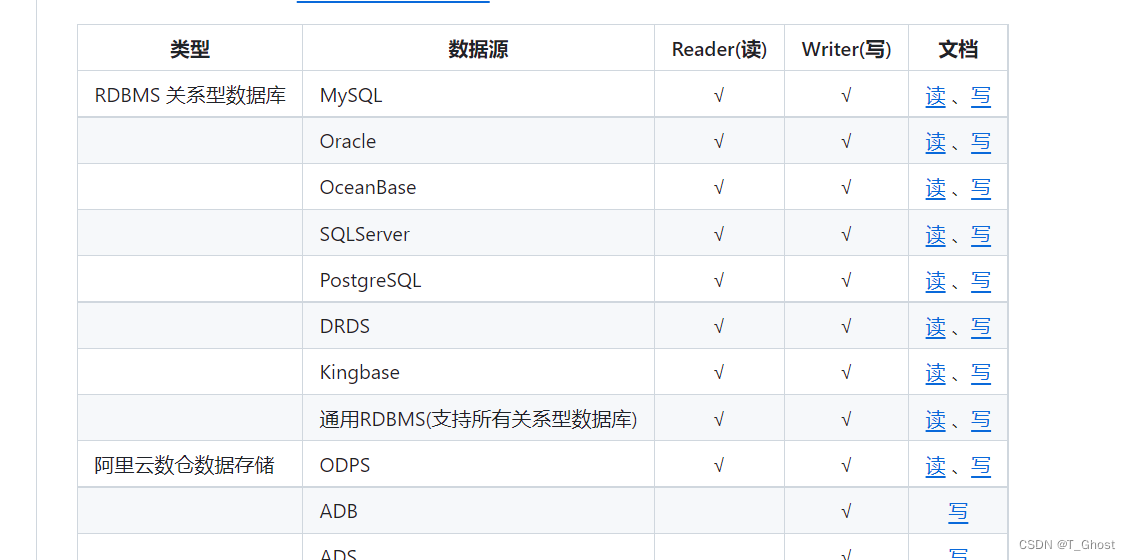
reader和writer均在官网目录可查看 (如 mysqlreader mongodbwriter)
4、代码执行
在datax根目录进行打包
可在datax-master的pom中注掉不需要的模块,并在package.xml中注掉。然后再进行打包,在datax目录下执行以下命令:
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
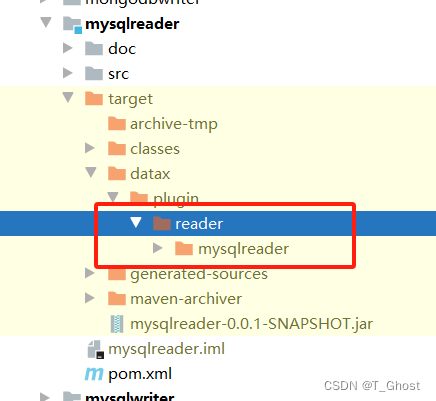
打包完成后,找到根目录下的target文件,在它的plugin中引入所需要用的reader和writer。这些reader和writer都在各自模块的target中,如mysqlreader:
然后在datax-core模块中的CoreConstant常量中设置datax_home为根目录下target中的datax/datax。如:
public static String DATAX_HOME = "D:\\idea\\workspace\\ff-masterf\\DataX-master\\target\\datax\\datax";
然后根据官网配置json文件,入口类在datax-core的Engine中,使用其entry(final String[] args)方法执行。参数构造如下:
public static void main(String[] args) throws Exception {
int exitCode = 0;
String[] testArgs = {"-job","D:\\idea\\workspace\\ff-masterf\\DataX-master\\target\\datax\\datax\\job\\job2.json","-mode","standalone","-jobid","-1"};
try {
Engine.entry(testArgs);
} catch (Throwable e) {
exitCode = 1;
LOG.error("\n\n经DataX智能分析,该任务最可能的错误原因是:\n" + ExceptionTracker.trace(e));
if (e instanceof DataXException) {
DataXException tempException = (DataXException) e;
ErrorCode errorCode = tempException.getErrorCode();
if (errorCode instanceof FrameworkErrorCode) {
FrameworkErrorCode tempErrorCode = (FrameworkErrorCode) errorCode;
exitCode = tempErrorCode.toExitValue();
}
}
System.exit(exitCode);
}
System.exit(exitCode);
}
5、源码打包与java集成
在java中执行同datax中执行是一样的,同样需要一个指定的datax_home。也需要指定相应的json文件。
首先同上,在pom.xml和package.xml中留下所需的模块。再将打包后的core和common的jar包安装到maven仓库。具体如下:
mvn install:install-file -Dfile="jar包的绝对路径" -Dpackaging=jar -DgroupId=groupid名 -DartifactId=artifactId名 -Dversion=jar版本
mvn install:install-file -Dfile=E:\ff\DataX-master\core\target\datax-core-0.0.1-SNAPSHOT.jar -Dpackaging=jar -DgroupId=com.datax -DartifactId=datax-core -Dversion=0.0.1-SNAPSHOT
mvn install:install-file -Dfile=E:\ff\DataX-master\common\target\datax-common-0.0.1-SNAPSHOT.jar -Dpackaging=jar -DgroupId=com.datax -DartifactId=datax-common -Dversion=0.0.1-SNAPSHOT
并在需要datax的maven项目中引入如下依赖:
<!--datax配置-->
<dependency>
<groupId>com.datax</groupId>
<artifactId>datax-core</artifactId>
<version>0.0.1</version>
</dependency>
<dependency>
<groupId>com.datax</groupId>
<artifactId>datax-common</artifactId>
<version>0.0.1</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-io</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
接着进行如下操作:
1、将core的target下datax文件拷贝至指定的DATAX_HOME(非源码不需要)
2、需要什么类型reader/writer就将指定的reader/writer下target中的datax/plugin拷贝至core中的plugin(直接下载的datax自带不需此步骤/如果是datax源码则需要)
3、调用 com.alibaba.datax.core.Engine.entry()或自定义的入口方法 指定要执行的json文件位置

6、直接在java程序中调用phython执行json脚本
这种方式很简单,不需要引入jar包。部署好datax后,在Java中执行Linux命令,可以使用Runtime.getRuntime().exec()方法。使用这个方法执行:
python bin/datax.py ./job/job.json
即可开启任务
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MySQL增删改查(查询)
- watermark-dom 水印不显示
- YOLOv8改进 | 2023主干篇 | EfficientViT替换Backbone(高效的视觉变换网络)
- Flask:模板渲染
- Django请求生命周期
- 基于ssm珠江学院大学生自愿者服务网论文
- 【简单总结】中断类型号 中断向量 中断入口地址
- java基于ssm框架的校园闲置物品交易平台论文
- CCC数字钥匙设计【NFC】--NFC通信之APDU & TLV
- 进程通信知识基础【Linux】——下篇