Yi-VL模型发布:全球开源顶尖水平,仅次于GPT-4V多模态模型
Yi-VL模型概况
零一万物公司最新发布的Yi-VL多模态语言大模型,以其先进的技术和卓越的性能,标志着在多模态人工智能领域的一个新时代。Yi-VL模型以Yi语言模型为基础,开发了包括Yi-VL-34B和Yi-VL-6B两个版本,这两个版本均在全新的多模态基准测试MMMU中表现出色。
-
Huggingface模型下载:https://huggingface.co/01-ai
-
AI快站模型免费加速下载:https://aifasthub.com/models/01-ai
架构设计的创新
Yi-VL模型的架构设计体现了对当前多模态技术的深入理解。模型采用Vision Transformer(ViT)进行图像编码,Projection模块实现图像与文本特征的对齐。此外,Yi系列的大规模语言模型为Yi-VL提供了强大的语言理解和生成能力。这种创新的架构设计使Yi-VL在处理复杂的视觉和语言信息时更加高效和准确。

基准测试MMMU的成绩
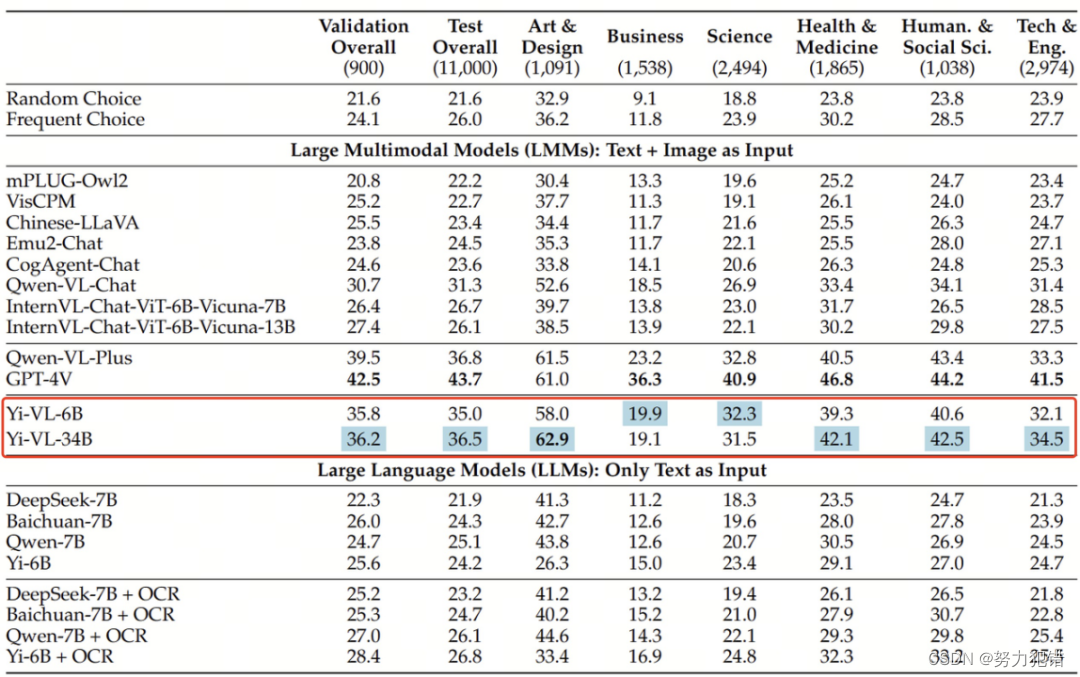
在MMMU数据集中,Yi-VL-34B模型以41.6%的准确率取得了显著成绩。这个数据集包含来自六大学科领域的11500个问题,要求模型不仅要理解高度多样化的图像类型,还要处理交织的文本和图像信息。Yi-VL模型在此测试中展示了其在跨学科知识理解和应用能力上的强大实力。

在CMMMU数据集上的表现
Yi-VL模型在CMMMU数据集上同样展现了卓越的性能。CMMMU专注于中文场景,包含约12000道问题,涉及多个领域。在这个数据集中,Yi-VL-34B以36.5%的准确率紧随GPT-4V之后,展现了其对中文文化和语境的深刻理解。

训练方法的精心规划
Yi-VL模型的训练过程分为三个阶段,每个阶段都针对性地提升模型的视觉和语言处理能力。第一阶段,使用“图像-文本”配对数据集训练ViT和Projection模块,注重提高模型在特定架构中的知识获取能力。第二阶段,提升ViT的图像分辨率,使模型更擅长处理复杂视觉细节。第三阶段,则开放整个模型的参数进行训练,以提高模型在多模态交互中的表现。
多元场景中的应用潜力
Yi-VL模型在多元场景下的应用前景十分广阔。它不仅能够有效处理图文对话,还能在跨学科的复杂任务中发挥作用。例如,在教育、医疗、娱乐等领域,Yi-VL能够深入理解和响应用户的需求,提供更为丰富和精准的信息。

面向未来的开源贡献
Yi-VL模型的开源不仅是对全球AI研究和应用领域的重大贡献,也为未来的多模态人工智能发展提供了新的方向。通过开源,Yi-VL模型将促进技术的交流和创新,推动多模态人工智能技术的发展,最终实现在更广泛的应用领域的落地。
总结
Yi-VL模型的发布,不仅展现了在多模态理解和生成领域的卓越性能,也预示着人工智能在理解和处理复杂信息方面的新突破。随着技术的不断发展和优化,Yi-VL有望在更多领域发挥其强大的应用潜力。
模型下载
Huggingface模型下载
https://huggingface.co/01-ai/Yi-VL-34B
https://huggingface.co/01-ai/Yi-VL-6B
AI快站模型免费加速下载
https://aifasthub.com/models/01-ai/Yi-VL-34B
https://aifasthub.com/models/01-ai/Yi-VL-6B
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!