贝叶斯分类器(公式推导+举例应用)
引言
在机器学习的世界中,有一类强大而受欢迎的算法——贝叶斯分类器,它倚仗着贝叶斯定理和朴素的独立性假设,成为解决分类问题的得力工具。这种算法的独特之处在于其对概率的建模,使得它在面对不确定性和大规模特征空间时表现卓越。
本文将深入探讨贝叶斯分类器,首先通过详细的公式推导带你走进其内部机制,随后通过实际案例展示其在各个领域的广泛应用。
贝叶斯决策论
贝叶斯决策论是一种基于概率论和决策理论的决策框架,其核心思想是通过最大化期望效用来做出最优的决策。该理论的基础是贝叶斯定理,它将不确定性引入决策过程中,特别适用于需要考虑不确定性因素的问题。
假设有
N
N
N种可能的类别标记,即
y
=
{
c
1
,
c
2
,
.
.
.
,
c
N
}
y=\{c_1,c_2,...,c_N\}
y={c1?,c2?,...,cN?},
λ
i
j
\lambda_{ij}
λij?是将一个真实标记为
c
j
c_j
cj?的样本误分类为
c
i
c_i
ci?所产生的损失。基于后验概率
P
(
c
i
∣
x
)
P(c_i|x)
P(ci?∣x)可获得将样本
x
x
x分类为
c
i
c_i
ci?所产生的期望损失,即样本
x
x
x上的条件风险:
R
(
c
i
∣
x
)
=
∑
j
=
1
N
λ
i
j
P
(
c
j
∣
x
)
(1)
R(c_i|x)=\sum_{j=1}^N\lambda_{ij}P(c_j|x) \tag{1}
R(ci?∣x)=j=1∑N?λij?P(cj?∣x)(1)
我们的任务是寻找一个判定准则
h
:
χ
?
y
h:\chi\mapsto y
h:χ?y以最小化总体风险:
R
(
h
)
=
E
[
R
(
h
(
x
)
∣
x
)
]
(2)
R(h)=\mathbb{E}[R(h(x)|x)] \tag{2}
R(h)=E[R(h(x)∣x)](2)
其中
E
\mathbb{E}
E表示期望值。显然,对于每个样本
x
x
x,若
h
h
h能最小化条件风险
R
(
h
(
x
)
∣
x
)
R(h(x)|x)
R(h(x)∣x),则总体的
R
(
h
)
R(h)
R(h)也将会被最小化。
贝叶斯判定准则:为最小化总体风险,只需在每个样本上选择那个能使条件风险
R
(
c
∣
x
)
R(c|x)
R(c∣x)最小的类别标记,即:
h
?
(
x
)
=
a
r
g
c
∈
y
m
i
n
?
R
(
c
∣
x
)
(3)
h^\star(x)=arg_{c\in y} \quad min\ R(c|x) \tag{3}
h?(x)=argc∈y?min?R(c∣x)(3)
此时, h ? h^\star h?称为贝叶斯最优分类器,与之对应的总体风险 R ( h ? ) R(h^\star) R(h?)称为贝叶斯风险。 1 ? R ( h ? ) 1-R(h^\star) 1?R(h?)反映了分类器所能达到的最好性能。
具体来说,若目标是最小化分类错误率,则误判损失
λ
i
j
\lambda_{ij}
λij?可写为:
λ
i
j
=
{
0
,
i
f
?
i
=
j
1
,
o
t
h
e
r
w
i
s
e
(4)
\lambda_{ij}= \begin{cases} 0,\quad if \ i=j\\ 1, \quad otherwise \end{cases} \tag{4}
λij?={0,if?i=j1,otherwise?(4)
此时条件风险:
R
(
c
∣
x
)
=
1
?
P
(
c
∣
x
)
(5)
R(c|x)=1-P(c|x) \tag{5}
R(c∣x)=1?P(c∣x)(5)
于是最小化分类错误率的贝叶斯分类器为:
h
?
(
x
)
=
a
r
g
c
∈
y
m
a
x
?
P
(
c
∣
x
)
(6)
h^\star(x)=arg_{c\in y} \quad max\ P(c|x) \tag{6}
h?(x)=argc∈y?max?P(c∣x)(6)
即对每个样本 x x x,选择能使后验概率 P ( c ∣ x ) P(c|x) P(c∣x)最大的类别标记。
然而在现实任务中,我们很难得到后验概率 P ( c ∣ x ) P(c|x) P(c∣x)。
自此我们有两种策略:
- 判别式模型:给定 x x x,可通过直接建模 P ( c ∣ x ) P(c|x) P(c∣x)来预测 c c c。
- 生成式模型:对联合概率分布 P ( x , c ) P(x,c) P(x,c)建模,然后再由此获得 P ( c ∣ x ) P(c|x) P(c∣x)。
显然对于生成式模型来说,需考虑:
P
(
c
∣
x
)
=
P
(
x
,
c
)
P
(
x
)
(7)
P(c|x)=\frac{P(x,c)}{P(x)} \tag{7}
P(c∣x)=P(x)P(x,c)?(7)
基于贝叶斯定理,
P
(
c
∣
x
)
P(c|x)
P(c∣x)可写为:
P
(
c
∣
x
)
=
P
(
c
)
P
(
x
∣
c
)
P
(
x
)
(8)
P(c|x)=\frac{P(c)P(x|c)}{P(x)} \tag{8}
P(c∣x)=P(x)P(c)P(x∣c)?(8)
因此估计 P ( c ∣ x ) P(c|x) P(c∣x)的问题就转化为如何基于训练数据 D D D来估计先验概率 P ( c ) P(c) P(c)和似然 P ( x ∣ c ) P(x|c) P(x∣c)。
先验概率和后验概率
先验概率(Prior Probability)
先验概率是在考虑任何观测数据之前,对事件的概率进行估计。它是基于以往经验、领域知识或其他信息得出的概率。符号通常表示为 P ( A ) P(A) P(A),其中 A A A是事件。先验概率反映了在考虑新观测数据之前我们对事件的信念。
后验概率(Posterior Probability)
后验概率是在考虑了新的观测数据之后,对事件的概率进行修正的概率。它是基于先验概率和新观测数据的联合影响得出的概率,使用贝叶斯定理计算。符号通常表示为 P ( A ∣ B ) P(A|B) P(A∣B),其中 A A A是事件, B B B是观测数据。后验概率反映了在获得新信息后我们对事件的修正信念。
让我们通过一个简单的例子来生动形象地描述先验概率和后验概率的概念。
场景:病人的健康检查
- 先验概率的理解: 假设有一个医生,他的病人群体中,有 10% 的人患有某种疾病(事件 A A A)。这个 10% 的患病率是基于医生以往的经验和病历统计得到的。在这里,患病率 10% 就是先验概率 P ( A ) P(A) P(A)。
- **后验概率的理解:**现在,该医生对一位新的病人进行了检查,得到了一些特定的症状(事件 B B B)。在这个特定的病人身上,这些症状出现的概率是多少呢?这就是后验概率 P ( A ∣ B ) P(A|B) P(A∣B)。
使用贝叶斯定理,医生可以更新他的信念。假设在已知患病率为 10% 的情况下,症状出现的概率为 80%(这是似然度 P ( B ∣ A ) P(B|A) P(B∣A)),而病人患有该疾病的概率就可以通过贝叶斯定理计算。
P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ) P(A|B)=\frac{P(B|A)P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)P(A)?
这里, P ( B ) P(B) P(B)表示症状出现的概率,可以通过考虑所有可能情况来计算。例如,患病且出现症状的情况和不患病但出现症状的情况。
医生通过这个计算,得到了在考虑了新的症状后,病人患有该疾病的后验概率。这个后验概率可以帮助医生更准确地评估病人的健康状况,这就是后验概率的概念。
极大似然估计
极大似然估计(Maximum Likelihood Estimation,简称MLE)是一种常用的参数估计方法,用于估计统计模型中的参数。该方法基于观测到的数据,寻找使得观测到这些数据的概率最大的模型参数。
具体的,记关于类别 c c c的类条件概率为 P ( x ∣ c ) P(x|c) P(x∣c),假设 P ( x ∣ c ) P(x|c) P(x∣c)具有确定的形式且被参数向量 θ c \theta_c θc?唯一确定,则我们的任务就是利用训练集 D D D估计参数 θ c \theta_c θc?。为明确起见,我们将 P ( x ∣ c ) P(x|c) P(x∣c)记为 P ( x ∣ θ c ) P(x|\theta_c) P(x∣θc?)。
令
D
c
D_c
Dc?表示训练集
D
D
D中的第三
c
c
c类样本组成的集合,假设他们都是独立同分布的,则参数
θ
c
\theta_c
θc?对于数据集
D
c
D_c
Dc?的似然是:
P
(
D
c
∣
θ
c
)
=
∏
x
∈
D
c
P
(
x
∣
θ
c
)
(9)
P(D_c|\theta_c)=\prod_{x\in D_c}P(x|\theta_c) \tag{9}
P(Dc?∣θc?)=x∈Dc?∏?P(x∣θc?)(9)
对 θ c \theta_c θc?进行极大似然估计,就是去寻找能最大化似然 P ( D c ∣ θ c ) P(D_c|\theta_c) P(Dc?∣θc?)的参数值 θ ^ c \hat \theta_c θ^c?。从直观上讲,极大似然估计就是寻找在所有取值中,最大的一个 θ ^ c \hat \theta_c θ^c?。
式(9)中连乘会导致下溢,通常使用对数似然:
L
L
(
θ
c
)
=
l
o
g
P
(
D
c
∣
θ
c
)
=
∑
x
∈
D
c
l
o
g
P
(
x
∣
θ
c
)
(10)
\begin{aligned} LL(\theta_c) &= logP(D_c|\theta_c) \\ &= \sum_{x\in D_c} logP(x|\theta_c) \end{aligned} \tag{10}
LL(θc?)?=logP(Dc?∣θc?)=x∈Dc?∑?logP(x∣θc?)?(10)
此时的参数
θ
c
\theta_c
θc?的极大似然估计
θ
^
c
\hat \theta_c
θ^c?为:
θ
^
c
=
arg
θ
c
?
m
a
x
?
L
L
(
θ
c
)
(11)
\begin{aligned} \hat \theta_c =&\underset{\theta_c}{\text{arg}} \ max\ LL(\theta_c) \end{aligned} \tag{11}
θ^c?=?θc?arg??max?LL(θc?)?(11)
朴素贝叶斯分类器
朴素贝叶斯分类器是一种基于贝叶斯定理的分类算法,它假设特征之间是相互独立的(朴素贝叶斯的"朴素"就体现在这里),并且使用了一些概率统计的方法进行分类。它广泛应用于文本分类、垃圾邮件过滤、情感分析等领域。
基于属性条件独立性假设,式(8)可重写为:
P
(
c
∣
x
)
=
P
(
c
)
P
(
x
∣
c
)
P
(
x
)
=
P
(
c
)
P
(
x
)
∏
i
=
1
d
P
(
x
i
∣
c
)
(12)
P(c|x)=\frac{P(c)P(x|c)}{P(x)}=\frac{P(c)}{P(x)}\prod_{i=1}^dP(x_i|c) \tag{12}
P(c∣x)=P(x)P(c)P(x∣c)?=P(x)P(c)?i=1∏d?P(xi?∣c)(12)
其中 d d d为属性数目, x i x_i xi?为 x x x在第 i i i个属性上的取值。
由于对于所有类别来说
P
(
x
)
P(x)
P(x)相同,因此基于式(6)的贝叶斯判定准则有:
h
n
b
(
x
)
=
arg
c
∈
y
?
m
a
x
?
P
(
c
)
∏
i
=
1
d
P
(
x
i
∣
c
)
(13)
\begin{aligned} h_{nb}(x) =&\underset{c \in y}{\text{arg}} \ max\ P(c)\prod_{i=1}^dP(x_i|c) \end{aligned} \tag{13}
hnb?(x)=?c∈yarg??max?P(c)i=1∏d?P(xi?∣c)?(13)
这就是朴素贝叶斯分类器的表达式。
令
D
c
D_c
Dc?表示训练集
D
D
D中第
c
c
c类样本组成的集合,若有充足的独立同分布样本,则可容易地估计出类先验概率:
P
(
c
)
=
∣
D
c
∣
∣
D
∣
(14)
P(c)=\frac{|D_c|}{|D|} \tag{14}
P(c)=∣D∣∣Dc?∣?(14)
现在我们估计似然 P ( x i ∣ c ) P(x_i|c) P(xi?∣c):
- 对于离散数据而言:令
D
c
,
x
i
D_{c,x_i}
Dc,xi??表示
D
c
D_c
Dc?中的第
i
i
i个属性上取值为
x
I
x_I
xI?的样本组成的集合,则条件概率
P
(
x
i
∣
c
)
P(x_i|c)
P(xi?∣c)可估计为:
P ( x i ∣ c ) = ∣ D c , x i ∣ ∣ D c ∣ (15) P(x_i|c)=\frac{|D_{c,x_i}|}{|D_c|} \tag{15} P(xi?∣c)=∣Dc?∣∣Dc,xi??∣?(15)
- 对于连续数据而言:可以考虑概率密度,假定
p
(
x
i
,
c
)
~
N
(
μ
c
,
i
,
σ
c
,
i
2
)
p(x_i,c)\sim N(\mu_{c,i},\sigma_{c,i}^2)
p(xi?,c)~N(μc,i?,σc,i2?),即
p
(
x
i
,
c
)
p(x_i,c)
p(xi?,c)服从均值为
μ
c
,
i
\mu_{c,i}
μc,i?,方差为
σ
c
,
i
2
\sigma_{c,i}^2
σc,i2?的正态分布,则有:
p ( x i , c ) = 1 2 π σ c , i e ? ( x i ? μ c , i ) 2 2 σ c , i 2 (16) p(x_i,c)=\frac{1}{\sqrt{2\pi}\sigma_{c,i}}e^{-\frac{(x_i-\mu_{c,i})^2}{2\sigma_{c,i}^2}}\tag{16} p(xi?,c)=2π?σc,i?1?e?2σc,i2?(xi??μc,i?)2?(16)
朴素贝叶斯分类器的优点与缺点
优点
- 朴素贝叶斯算法简单,易于实现。
- 在处理大规模数据集时表现良好。
- 在特征之间相对独立的情况下,效果良好。
缺点
- 对于特征之间相关性较强的数据,朴素贝叶斯可能表现不佳。
- 对于缺失数据的处理相对较为复杂。
总体而言,朴素贝叶斯分类器在许多实际应用中表现良好,特别是在文本分类等领域。
总结
在本文中,我们深入探讨了贝叶斯分类器及其相关概念。首先,我们通过详细的公式推导介绍了贝叶斯决策论,阐述了其基于概率和决策理论的决策框架。接着,我们讨论了贝叶斯定理的先验概率和后验概率,通过生动的例子说明了这两个概念的重要性和应用场景。
随后,我们转向了极大似然估计,解释了在统计模型中使用观测数据来估计参数的方法。通过推导极大似然估计的基本原理,我们理解了其在模型参数估计中的重要性。
最后,我们详细介绍了朴素贝叶斯分类器,阐述了其基于贝叶斯定理和属性条件独立性假设的工作原理。我们还探讨了朴素贝叶斯分类器的优点和缺点,以及其在实际应用中的广泛使用,特别是在文本分类等领域。
总体而言,贝叶斯分类器作为一种强大而灵活的机器学习算法,在不同领域展现出了卓越的性能。通过深入了解其原理和应用,我们能够更好地理解和利用这一算法来解决实际问题。希望本文能够为读者提供清晰的认识,并激发对贝叶斯分类器更深层次研究的兴趣。
实验分析
判断一封邮件是否为垃圾邮件。
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, classification_report
# 读入数据集
df = pd.read_csv('data/spam_or_not_spam.csv')

训练朴素贝叶斯分类器
# 先去除包含 NaN 值的行
df = df.dropna(subset=['email', 'label'])
X = df['email']
y = df['label']
# 文本转词袋模型
vectorizer = CountVectorizer(stop_words='english')
X = vectorizer.fit_transform(X)
# 数据拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练朴素贝叶斯分类器
nb_classifier = MultinomialNB()
nb_classifier.fit(X_train, y_train)
# 预测
y_pred = nb_classifier.predict(X_test)
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 模型评估
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print("Classification Report:\n", report)
# 设置中文字体
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=12)
plt.rcParams['font.sans-serif'] = ['SimSun'] # 设置字体为宋体
# 生成混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 绘制混淆矩阵图
plt.figure(figsize=(8, 6))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=['非垃圾邮件', '垃圾邮件'])
disp.plot(cmap=plt.cm.Blues)
plt.title('混淆矩阵', fontproperties=font)
plt.show()
# 生成 ROC 曲线
y_probs = nb_classifier.predict_proba(X_test)[:, 1]
fpr, tpr, _ = roc_curve(y_test, y_probs)
roc_auc = auc(fpr, tpr)
# 绘制 ROC 曲线图
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC 曲线(面积 = {:.2f})'.format(roc_auc))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('假正率', fontproperties=font)
plt.ylabel('真正率', fontproperties=font)
plt.title('接收者操作特征曲线 (ROC) 曲线', fontproperties=font)
plt.legend(loc='lower right')
plt.show()
Accuracy: 0.9916666666666667
Classification Report:
precision recall f1-score support
0 0.99 1.00 1.00 500
1 1.00 0.95 0.97 100
accuracy 0.99 600
macro avg 1.00 0.97 0.98 600
weighted avg 0.99 0.99 0.99 600
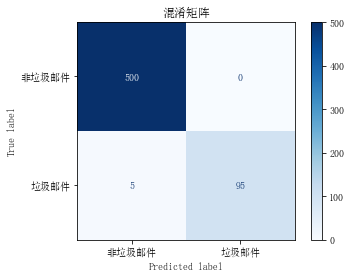
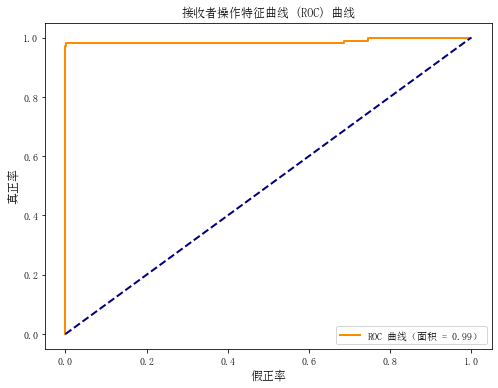
-
准确度(Accuracy): 0.9917,表示模型在整体上正确预测的比例。这是一个很高的准确度,说明模型在测试数据上的表现非常好。
-
分类报告(Classification Report):
- 对于类别 0(非垃圾邮件):
- 精确度(Precision):0.99,表示在所有模型预测为非垃圾邮件的样本中,实际上有 99% 是正确的。
- 召回率(Recall):1.00,表示在所有实际非垃圾邮件的样本中,模型成功预测的比例为 100%。
- F1 分数(F1-score):1.00,是精确度和召回率的调和平均值,综合考虑了两者。
- 支持度(Support):500,表示测试集中实际为非垃圾邮件的样本数量。
- 对于类别 1(垃圾邮件):
- 精确度:1.00,表示在所有模型预测为垃圾邮件的样本中,实际上有 100% 是正确的。
- 召回率:0.95,表示在所有实际垃圾邮件的样本中,模型成功预测的比例为 95%。
- F1 分数:0.97,是精确度和召回率的调和平均值,综合考虑了两者。
- 支持度:100,表示测试集中实际为垃圾邮件的样本数量。
-
加权平均(weighted avg): 这是对各类别指标进行加权平均,考虑到每个类别的支持度。在这里,加权平均的准确度、精确度、召回率和 F1 分数都达到了 0.99。
-
宏平均(macro avg): 这是对各类别指标取平均,不考虑各类别的支持度。在这里,宏平均的准确度、精确度、召回率和 F1 分数分别为 1.00、0.97、1.00 和 0.98。
总体来说,模型在非垃圾邮件的预测上表现非常好,而在垃圾邮件的预测上稍微有些降低,主要体现在垃圾邮件的召回率上。综合考虑各指标,模型在整体上仍然表现出色。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 双端队列和优先级队列
- 数据库用户密码修改时间和密码加密值查询(DM8:达梦数据库)
- MFC 绘图
- 基于Mapify的在线艺术地图设计
- 《数字图像处理-OpenCV/Python》连载(26)绘制椭圆和椭圆弧
- 软件测试/测试开发丨Selenium环境安装配置
- C语言实现将不同数字组成无重复的三位数【一题一策】第一期
- (aiohttp-asyncio-FFmpeg-Docker-SRS)实现异步摄像头转码服务器
- 响应式Web开发项目教程(HTML5+CSS3+Bootstrap)第2版 例4-1 表单
- css3实现类似地图定位循环扩散光圈效果