YOLOv8改进 添加新型卷积注意力框架SegNext_Attention
发布时间:2024年01月02日

一、SegNext论文

论文地址:2209.08575.pdf (arxiv.org)
二、?SegNext_Attention注意力框架结构
在SegNext_Attention中,注意力机制被引入到编码器和解码器之间的连接中,帮助模型更好地利用全局上下文信息。具体而言,注意力机制通过学习像素级的注意力权重,使得模型可以对感兴趣的区域进行更加准确的注重,同时忽略背景区域。
SegNext_Attention的注意力框架结构由以下几个组成部分组成:
-
编码器:使用卷积神经网络(CNN)来提取图像的特征表示。编码器由多个卷积层和池化层组成,逐渐减小特征图的尺寸,并增加特征图的通道数。
-
注意力机制:在编码器的输出特征图上应用注意力机制,以生成注意力权重。注意力权重是一个与输入图像尺寸相同的特征图,用于指示每个像素的重要性。
-
解码器:解码器使用上采样和卷积操作将编码器的特征图映射到像素级的分割结果。解码器逐渐恢复特征图的尺寸和减少通道数。
-
损失函数:通过计算预测结果和真实标签的差异来定义损失函数,用于训练模型。常用的损失函数包括交叉熵损失和Dice损失。
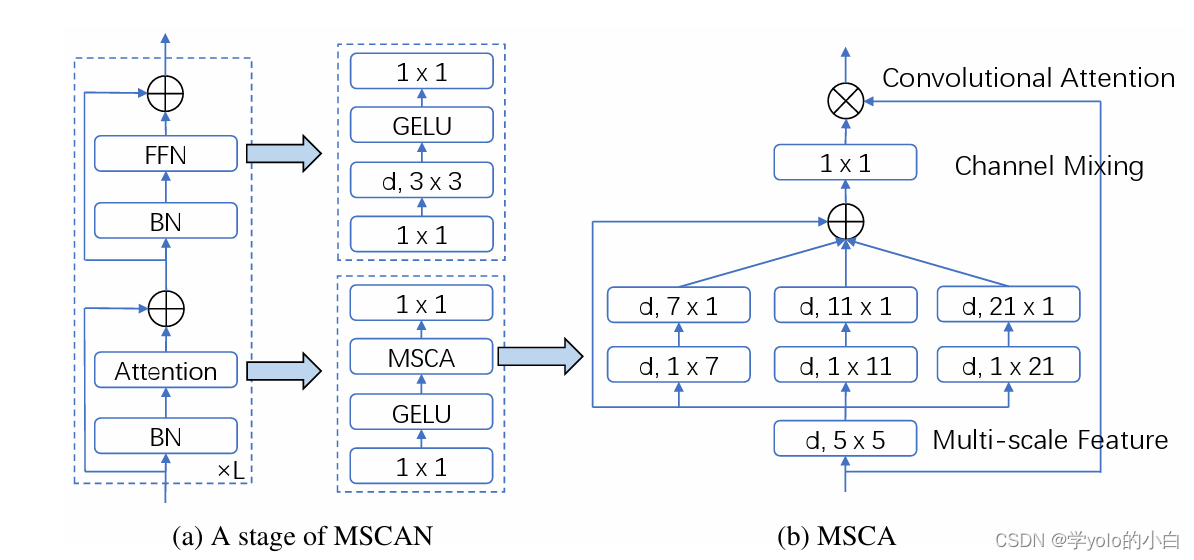
SegNext_Attention的主要优点是能够更好地利用全局上下文信息,并且能够对感兴趣的区域进行更加准确的注重,从而提高图像分割的性能。
三、代码实现
1、在官方的yolov8包中ultralytics\ultralytics\nn\modules\__init__.py文件中的from .conv import和__all__中加入注意力机制SegNext_Attention。
2、在ultralytics\ultralytics\nn\modules\conv.py文件中上__all__中添加SegNext_Attention:

并在该conv.py文件中输入SegNext_Attention的代码:
########### 添加SegNext_Attention注意力机制 ################
class SegNext_Attention(nn.Module):
# SegNext NeurIPS 2022
# https://github.com/Visual-Attention-Network/SegNeXt/tree/main
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv0_1 = nn.Conv2d(dim, dim, (1, 7), padding=(0, 3), groups=dim)
self.conv0_2 = nn.Conv2d(dim, dim, (7, 1), padding=(3, 0), groups=dim)
self.conv1_1 = nn.Conv2d(dim, dim, (1, 11), padding=(0, 5), groups=dim)
self.conv1_2 = nn.Conv2d(dim, dim, (11, 1), padding=(5, 0), groups=dim)
self.conv2_1 = nn.Conv2d(dim, dim, (1, 21), padding=(0, 10), groups=dim)
self.conv2_2 = nn.Conv2d(dim, dim, (21, 1), padding=(10, 0), groups=dim)
self.conv3 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn_0 = self.conv0_1(attn)
attn_0 = self.conv0_2(attn_0)
attn_1 = self.conv1_1(attn)
attn_1 = self.conv1_2(attn_1)
attn_2 = self.conv2_1(attn)
attn_2 = self.conv2_2(attn_2)
attn = attn + attn_0 + attn_1 + attn_2
attn = self.conv3(attn)
return attn * u3、在 ultralytics\ultralytics\nn\tasks.py文件中开头引入SegNext_Attention。

并在该文件?def parse_model模块中加入SegNext_Attention注意力机制代码:
elif m in {SegNext_Attention}:
c2 = ch[f]
args = [c2, *args]4、创建yolov8+SegNext_Attention的yaml文件:
(可根据自己的需求选择注意力机制SegNext_Attention插入的位置,本文以插入yolov8结构中池化层SPPF后边为例)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, SegNext_Attention, []] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
四、模型验证

可以看出模型中已经包含SegNext_Attention注意力机制。
文章来源:https://blog.csdn.net/zmyzcm/article/details/135295762
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 四、HTML 属性
- 【QT入门】基础知识
- php curl 传参文件
- 靶机来源-basic_pentesting_1【VX订阅号:0x00实验室】
- Linux文件系统结构及相关命令1(man pwd ls ctrl +Shift +T ls /etc)
- 掌握 SEO:提升网站在搜索结果中的排名(中)
- OpenHarmony如何隐藏系统状态栏、导航栏
- python3中traceback的用法有哪些
- MySQL- SELECT ... FOR UPDATE语句
- Java LeetCode刷题 单调栈