cilium原理之ebpf尾调用与trace
背景
在深入剖析cilium原理之前,有两个关于epbf的基础内容需要先详细介绍一下:
1. ebpf尾调用
尾调用类似于程序之间的相互跳转,但它的功能更加强大。
2. trace
虽然之前使用trace_printk输出日志,但这个函数不能多用,会有性能问题。而且它的输出可读性差,不利于程序进行分析。本文将着重讲讲如何进行分析,方便程序后续跟踪。
1.ebpf尾调用介绍
尾调用能够从一个程序调到另一个程序,提供了在运行时(runtime)原子地改变程序行为的灵活性。为了选择要跳转到哪个程序,尾调用使用了程序数组map( BPF_MAP_TYPE_PROG_ARRAY),将map及其索引(index)传递给将要跳转到的程序。跳转动作一旦完成,就没有办法返回到原来的程序;但如果给定的map索引中没有程序(无法跳转),执行会继续在原来的程序中执行。
特殊在于,由于函数的调用是由map来保存的,可以使用TC更新map对应的函数为新的函数,实现ebpf程序的局部更新。当然,这就对功能编码也会有更高的要求,需要明确更新可能的影响范围。因为ebpf的单个程序大小是有限制的,而尾调用可以绕开这种限制。
以下是摘自cilium官方文档中的样例:(官方样例无法编译,下面摘取的内容经过作者调整)
#include <bits/types.h>
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/in.h>
#include <linux/ip.h>
#include <linux/pkt_cls.h>
#include <linux/tcp.h>
#include <errno.h>
#include <stdio.h>
#include <string.h>
typedef __uint32_t uint32_t;
#define PIN_GLOBAL_NS 2
struct bpf_elf_map {
__u32 type;
__u32 size_key;
__u32 size_value;
__u32 max_elem;
__u32 flags;
__u32 id;
__u32 pinning;
};
#ifndef __stringify
# define __stringify(X) #X
#endif
#ifndef __section
# define __section(NAME) \
__attribute__((section(NAME), used))
#endif
#ifndef __section_tail
# define __section_tail(ID, KEY) \
__section(__stringify(ID) "/" __stringify(KEY))
#endif
#ifndef BPF_FUNC
# define BPF_FUNC(NAME, ...) \
(*NAME)(__VA_ARGS__) = (void *)BPF_FUNC_##NAME
#endif
#define BPF_JMP_MAP_ID 1
static int (*bpf_trace_printk)(const char *fmt, int fmt_size,
...) = (void *)BPF_FUNC_trace_printk;
#define printk(fmt, ...) \
do { \
char _fmt[] = fmt; \
bpf_trace_printk(_fmt, sizeof(_fmt), ##__VA_ARGS__); \
} while (0)
static void BPF_FUNC(tail_call, struct __sk_buff *skb, void *map,
uint32_t index);
struct bpf_elf_map jmp_map __section("maps") = {
.type = BPF_MAP_TYPE_PROG_ARRAY,
.id = BPF_JMP_MAP_ID,
.size_key = sizeof(uint32_t),
.size_value = sizeof(uint32_t),
.pinning = PIN_GLOBAL_NS,
.max_elem = 1,
};
__section_tail(BPF_JMP_MAP_ID, 0)
int looper(struct __sk_buff *skb)
{
printk("skb cb: %u\n", skb->cb[0]++);
tail_call(skb, &jmp_map, 0);
printk("skb end looper: cb: %u\n", skb->cb[0]);
return TC_ACT_OK;
}
__section("prog")
int entry(struct __sk_buff *skb)
{
skb->cb[0] = 0;
tail_call(skb, &jmp_map, 0);
printk("skb end: cb: %u\n", skb->cb[0]);
return TC_ACT_OK;
}
char __license[] __section("license") = "GPL";官方代码很清晰,需要注意的是:定义函数时,__section_tail(BPF_JMP_MAP_ID, 0)使用的是BPF_JMP_MAP_ID;而在bpf代码中,调用的时候使用的是tail_call(skb, &jmp_map, 0);中的jmp_map。而这两者之间的关系,则是在定义jmp_map时指定。
功能测试演示
# 将上面文件保存为tail.c
# build
clang -g -c -O2 -target bpf -c tail.c -o tail.o
# load
tc qdisc add dev enp1s0 ingress
tc filter replace dev enp1s0 ingress prio 1 handle 1 bpf da obj tail.o sec prog verbose
# cat log
cat /sys/kernel/debug/tracing/trace_pipe虽然上面的程序是死循环,但测试后发现,程序不是真的死循环,会在looper中执行34次后结束。验证函数热更新功能。
<idle>-0 [007] ..s. 443032.404122: 0: skb cb: 29
<idle>-0 [007] ..s. 443032.404122: 0: skb cb: 30
<idle>-0 [007] ..s. 443032.404123: 0: skb cb: 31
<idle>-0 [007] ..s. 443032.404123: 0: skb cb: 32
<idle>-0 [007] ..s. 443032.404123: 0: skb cb: 33
<idle>-0 [007] ..s. 443032.404124: 0: skb end looper: cb: 34
<idle>-0 [007] ..s. 443032.404146: 0: skb cb: 0
<idle>-0 [007] ..s. 443032.404148: 0: skb cb: 1
<idle>-0 [007] ..s. 443032.404149: 0: skb cb: 2
<idle>-0 [007] ..s. 443032.404149: 0: skb cb: 3
<idle>-0 [007] ..s. 443032.404150: 0: skb cb: 4在之前的源代码中,添加如下函数:
__section("newloop")
int newlooper(struct __sk_buff *skb)
{
printk("skb end in new looper: cb: %u\n", skb->cb[0]);
return TC_ACT_OK;
}
# build
clang -g -c -O2 -target bpf -c tail.c -o tail.o
# update func
tc exec bpf graft m:globals/jmp_map key 0 obj tail.o sec newloop
# 特别注意:由于centos8自带的tc版本太低,无法更新,需要使用高版本的tc.可使用cilium自带的tc
# docker run -it --name=mytest --network=host --privileged -v $PWD:/hosts/ -v /sys/fs/bpf:/sys/fs/bpf -v /run/cilium/cgroupv2/:/run/cilium/cgroupv2 cilium:v1.12.7 bash 进入容器后,执行上面的命令
# 结果检查
cat /sys/kernel/debug/tracing/trace_pipe2.?send_trace_notify 跟踪
send_trace_notify –> ctx_event_output –> skb_event_outputevent_output
// 调用样例
send_trace_notify(ctx, TRACE_FROM_LXC, SECLABEL, 0, 0, 0,
TRACE_REASON_UNKNOWN, TRACE_PAYLOAD_LEN);
// 函数定义
send_trace_notify(struct __ctx_buff *ctx, enum trace_point obs_point,
__u32 src, __u32 dst, __u16 dst_id, __u32 ifindex,
enum trace_reason reason, __u32 monitor)
msg = (typeof(msg)) {
__notify_common_hdr(CILIUM_NOTIFY_TRACE, obs_point), // 事件大类:CILIUM_NOTIFY_TRACE,子类:obs_point
__notify_pktcap_hdr(ctx_len, (__u16)cap_len),
.src_label = src, // 源对象id cilium identity list, identity 全局唯一
.dst_label = dst, // 目的对象id
.dst_id = dst_id, // 不同的子类,id取值不同
.reason = reason, // 原因标识
.ifindex = ifindex, // 不同的子类,取值类型不同
};
ctx_event_output(ctx, &EVENTS_MAP,
(cap_len << 32) | BPF_F_CURRENT_CPU,
&msg, sizeof(msg));上报的信息,就是harbor展示的数据来源。
信息说明????
-
发送的信息,会放在ring buffer中。如果未读取,会进行覆盖写入。
-
这个buffer是cpu级别的,每个cpu中都会有一个独立的。
-
读取时,需要指定读取哪个cpu,-1表示读取所有cpu中的信息。
-
读取event的具体细节,可参考:
https://man7.org/linux/manpages/man2/perf_event_open.2.html
下面为cilium使用go实现了perf读取库的使用说明:"github.com/cilium/ebpf/perf"
cilium目前的信息结构说明:
cilium monitor可以读取perf信息,并且能基于identity进行过滤,具体使用可参考该命令说明。
var err error
path := oldBPF.MapPath(signalmap.MapName)
signalMap, err := ebpf.LoadPinnedMap(path, nil)
if err != nil {
log.WithError(err).Warningf("Failed to open signals map")
return
}
events, err = perf.NewReader(signalMap, os.Getpagesize())
if err != nil {
log.WithError(err).Warningf("Cannot open %s map! Ignoring signals!",
signalmap.MapName)
return
}
go func() {
log.Info("Datapath signal listener running")
for {
record, err := events.Read()
switch {
case err != nil:
signalCollectMetrics(nil, "error")
log.WithError(err).WithFields(logrus.Fields{
logfields.BPFMapName: signalmap.MapName,
}).Errorf("failed to read event")
case record.LostSamples > 0:
signalCollectMetrics(nil, "lost")
default:
signalReceive(&record)
}
}
}()消息结构如下:
总体分两大类:
-
lost count,用于记数:数据包丢弃数。
-
详细报文说明。
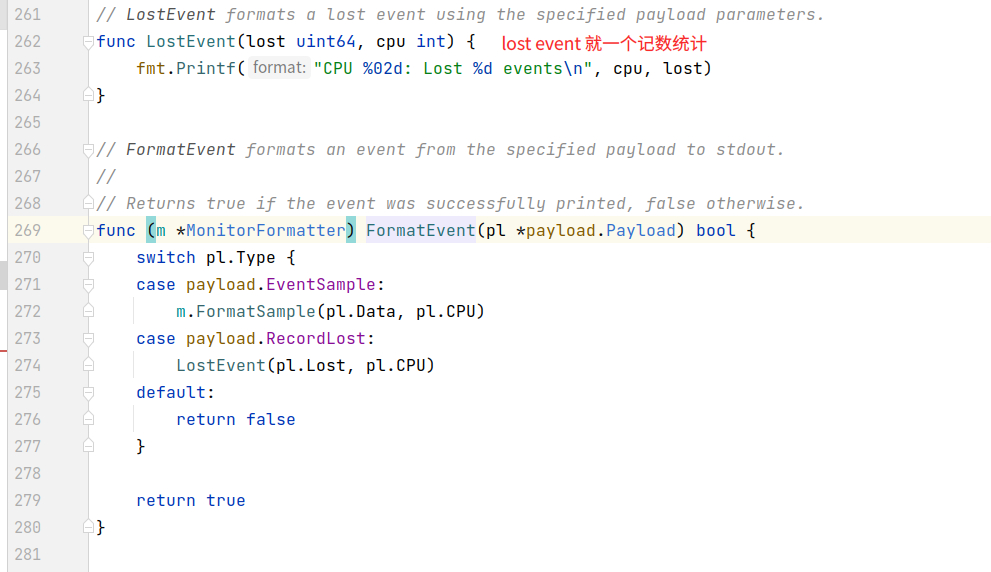
各种sample数据格式说明。
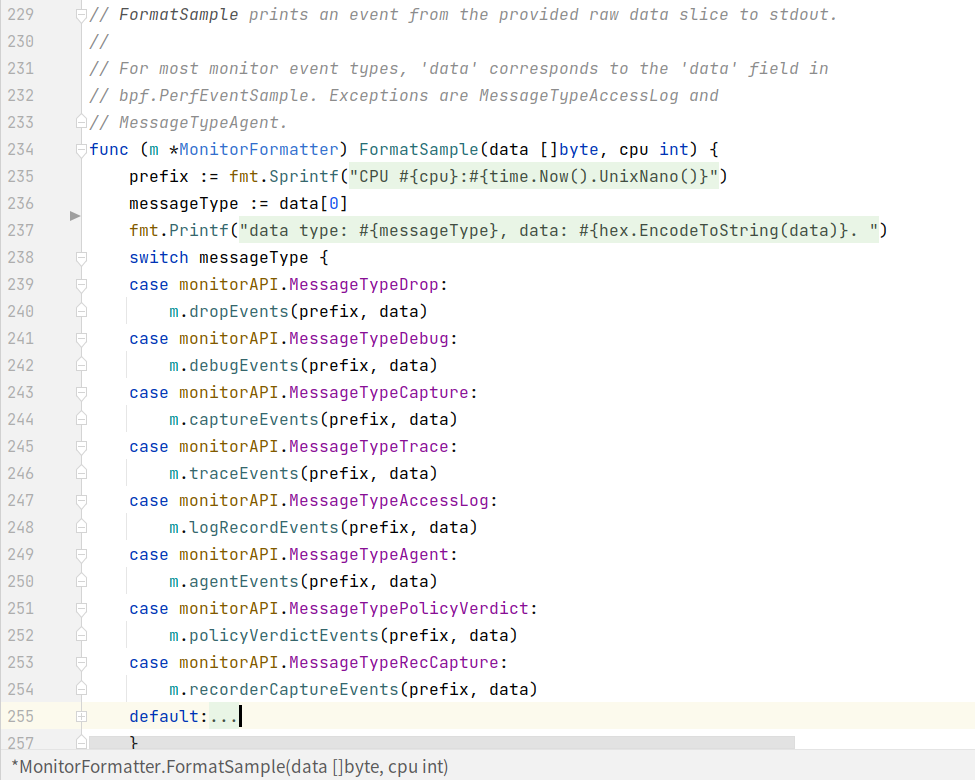
cilium monitor使用样例。
# 使用cilium monitor查看网络策略执行情况:
# remoteID 表示针对对象
# ingress/egress表示入与出流量
# action表示策略结果
cilium monitor -t policy-verdict
Listening for events on 8 CPUs with 64x4096 of shared memory
Press Ctrl-C to quit
level=info msg="Initializing dissection cache..." subsys=monitor
Policy verdict log: flow 0x95e0951 local EP ID 2467, remote ID kube-apiserver, proto 6, ingress, action allow, auth: disabled, match L3-L4, 172.18.0.6:46866 -> 172.18.0.8:2380 tcp SYN
Policy verdict log: flow 0x580738e1 local EP ID 2467, remote ID 16777218, proto 6, ingress, action allow, auth: disabled, match L3-L4, 172.18.0.2:40122 -> 172.18.0.8:6443 tcp SYN
Policy verdict log: flow 0x4dfe98a0 local EP ID 2467, remote ID kube-apiserver, proto 6, ingress, action allow, auth: disabled, match L3-L4, 172.18.0.4:52314 -> 172.18.0.8:2380 tcp SYN
Policy verdict log: flow 0xb3af0a31 local EP ID 2467, remote ID kube-apiserver, proto 6, egress, action allow, auth: disabled, match L3-L4, 172.18.0.8:42736 -> 172.18.0.6:2380 tcp SYN
Policy verdict log: flow 0xfdb19557 local EP ID 2467, remote ID kube-apiserver, proto 6, egress, action allow, auth: disabled, match L3-L4, 172.18.0.8:46246 -> 172.18.0.4:2380 tcp SYN
Policy verdict log: flow 0x5438a30a local EP ID 2467, remote ID 16777218, proto 6, ingress, action allow, auth: disabled, match L3-L4, 172.18.0.2:40164 -> 172.18.0.8:6443 tcp SYNendpoint id,可通过这个方式查到。

展望
跟踪只允许基于endpointID进行跟踪,无法基于ip、端口等信息,当网络流量在多个节点中流转时,无法有效的进行跟踪。
这一块可基于数据分析组件来实现,它可以导出json结构数据,采集统一汇总分析统计。
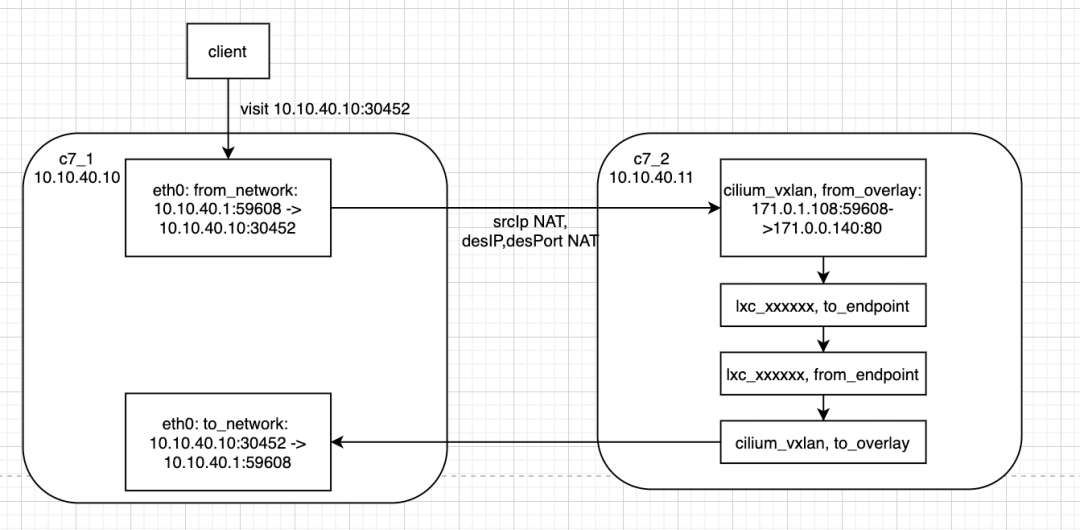
1.访问入口与目标pod在同节点上,ip nat情况:
2.访问入口与目标pod在同节点上,流量跟踪情况:
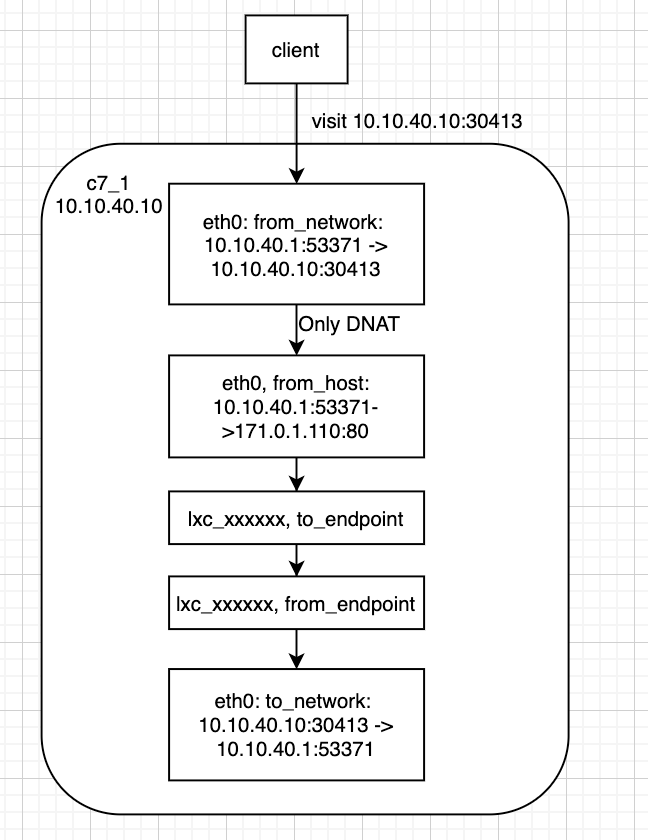
可以看到,源端口在网络流转中是不变的,可以基于此作为跟踪线索。
可基于es+kibana,将cilium trace相关数据统一在es中存储,并基于kibana展示,如下图所示:
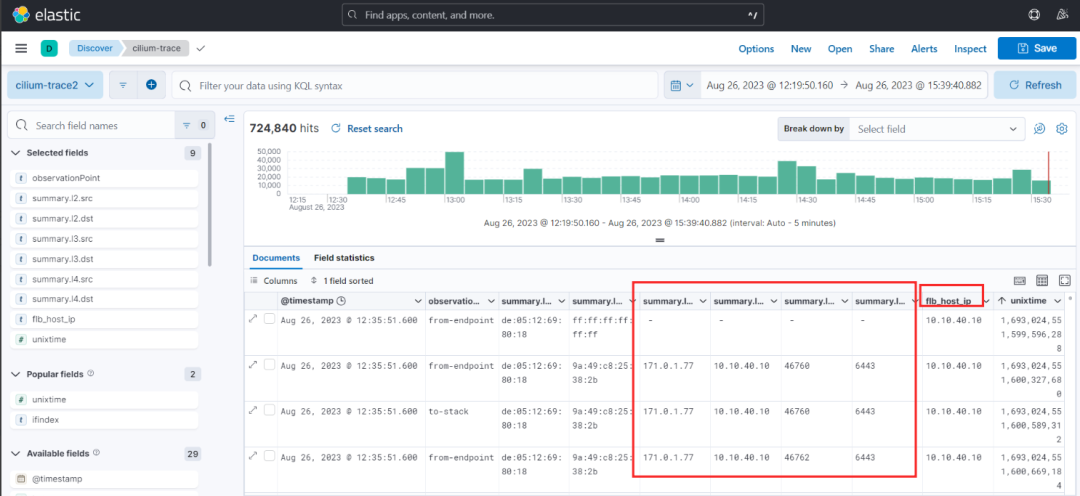
红色框分别为源ip、目标ip、源端口、目标端口。而特殊的flb_host_ip是坐着在采集时添加的节点主机的ip,用来分析不同主机间的流量。
作者:沃趣科技产品研发部
更多技术干货请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。
irds.cn,多数据库管理平台(私有云)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 拯救流浪猫狗:使用Java, Spring Boot, Vue和MySQL构建救助救援网站的创新实践
- Centos 7 安装Nginx
- 虚拟机域环境的搭建
- vue学习中,一些vscode插件配置
- vim快速使用
- (第48-59讲)STM32F4单片机,FreeRTOS【事件标志、任务通知、软件定时器、Tickless低功耗】【纯文字讲解】【原创】
- Linux全套课程(持续更新中)
- 巴尔加瓦算法图解——第八章 贪婪算法(上)
- 阿里云 ACK 新升级,打造智算时代的现代化应用平台
- 线程之间如何传递上下文信息