Transformer and Pretrain Language Models3-4
Transformer structure 模型结构
Transformer概述
首先回顾一下之前的RNN的一个端到端的模型,以下是一个典型的两层的LSTM模型,我们可以发现,这样一个RNN模型,一个非常重要的一个缺点就在于,它必须顺序地执行,对于文本这样一个序列,它必须先计算得到第一个位置的一个表示,然后才可以往后计算文本第二个的一个表示,然后接着才能去计算第三个。
而这样的模式,其实对于目前并行能力非常强大的GPU等专业设备来说,非常不友好,会造成很多资源浪费。
然后其次是尽管RNN有很多变体,比如说GRU、LSTM,但是它依然需要依靠前面提到的注意力机制,来解决像信息瓶颈这样的一些问题
考虑到RNN的这些所有的缺点,我们是否能够抛弃RNN的模型结构来来做文本的一些任务?这个答案显然是肯定的,研究人员在2017年发表的这篇文章,用他们的标题就直接回答了这个问题,这个标题叫attention is all you need,影响很大,后期也出现了很多类似xxx?is all you need的论文,这篇文章中,模型作者就提出了一个非常强大的模型结构,来进行机器翻译的任务,这个结构就是接下来要讲的Transformer

我们首先来整体看一下这样一个Transformer 的整体结构,可以看到,它同样是一个encoder和decoder的模型,他的encoder端我们用红色框来框出,decoder端用蓝色的部分来表示
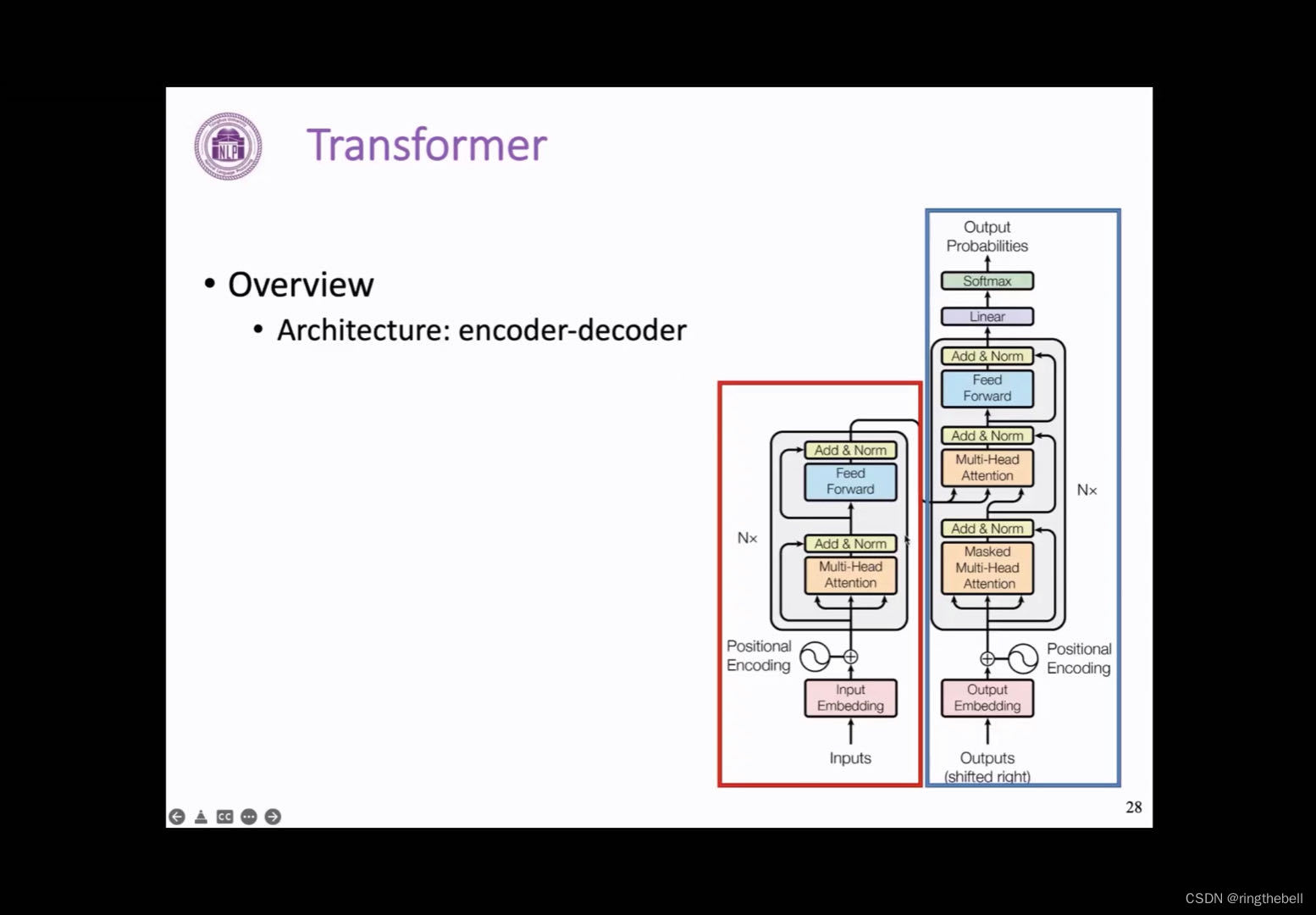
我们从下往上来看这样一个过程,首先,它的第一层是一个输入层
输入层:需要将一个正常的文本序列切成一个个小的单元,这里我们把这个单元叫做token,然后通过embedding可以化为一个向量表示,这里不同于RNN的地方有两点:
1、Transformer 会采用一种叫Byte Pair Encoding的方式,来对文本进行切分,也就是我们常说的BPE的方法,同时在每个位置也会加上一个token的一个位置向量,也就叫positional encoding,用来表示它在文本序列中的一个位置。这两块我们在后面都会有再详细的介绍

接下来是Transformer structure的一个主要图层部分,它是由多个encoder或者decoder的Transformer block堆叠而成的,而这种block在encoder和decoder之间会略有一些不同:
对于encoder端不同层的block以及或者decoder端不同层的block,他们的结构式完全一致的,就是在参数上会有所不同
Transformer也是通过这样一个堆叠方式来得到一个更深,表达能力更强的一个模型

最后模型的输出层其实就是一个线性层的变换和一个softmax来输出一个在词表上的概率分布,其实这个和之前的RNN输出层是基本一致的,在训练的过程中,我们也是通过词表这样一个维度,计算交叉熵来计算loss,进而更新模型的一个参数
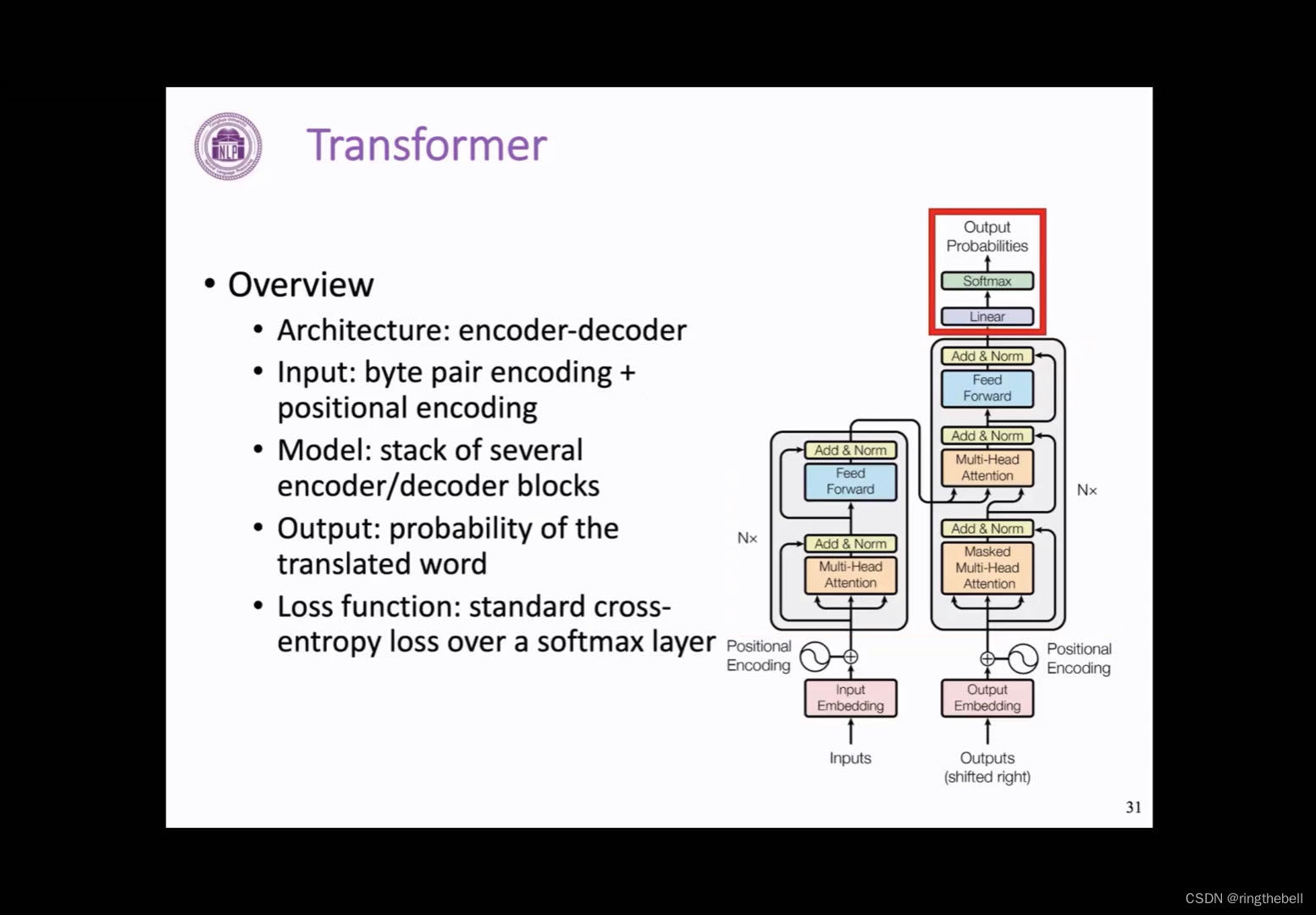
以上就是模型的整体情况,下面我们就逐个部分来一一地进行讲解:
input encoding输入层(输入编码BPE、PE)
输入层中首先介绍的是Byte Pair Encoding的方式,
首先想一下,如果我们要处理一个句子,这个句子是一个连续的文本,我们首先需要把这个句子给切分成一个一个的单词,我们在之前RNN上,可能大部分情况就是直接按照空格这样一种方式来进行切分,这个是一个最简单的切分方式,但显然这个方法还是有一些问题的,比如说他会导致词表的数量会很大,另外,可能像一些单词的复数和它原单词可能就会对应两个完全不一样高的embedding,这些都是使用空格切分的这种简单方式的问题
我们在这里介绍一种全新的分词方式,相比简单方式有很多优点,这是Transformer模型中使用的切分方式,它为Byte Pair Encoding,简称为BPE,他的过程为:
它首先会将语料库中出现的所有单词都切分为一个一个字母,这个就是最初的词表,随后它通过统计,在语料库中每一个byte gram出现的数量,我们就可以一步一步把频度最高的byte gram抽象成一个词加入词表中,然后就不断的扩充词表,最后直到我们达到需要的一个词表的一个数量,以下面的一个具体例子来看BPE构造词表的一个过程:
比如,我们在一个文本中,low这样的单词出现了5次,然后lower这样的一个单词出现了2次,newest单词出现了6次,wildest出现了3次,我们最开始的词表其实就是由这四个单词,所有的这个字母组成的,随后我们左边还要维护一个单词和频率的一个对应关系,然后我们将里面单词所有按照字母来切分之后,我们统计所有的byte gram出现的数量,byte gram其实就是指连续两个相邻位置拼到一起的一个组合,比如:i和o拼到一起就是一个byte gram,o和w拼到一起就是一个byte gram。
我们可以发现,在当前的这样一个语料库中,es这样的一个byte gram,其实是出现频率最高的,它一共出现了9次,分别在newest次中出现了6次,wildest中出现了3次,这里我们就把es拼接称为一个新的单词加入到词表当中,同时,因为s这个单词它不再会单独出现,所以我们将s从词表中去除,这样的话,新的词表就是下面的这个情况,把s去掉后,加入es

随后我们再按照这个新的词表,来组合前面提到的这个,左边这个对应关系中的一个byte gram的情况,可以看到es其实就是一个单词,而est就是一个新的byte gram???????,在这个新的词表和文本中,我们可以发现est这样的一个byte gram出现的频率最高,为9次,我们就将这样一个新的词拼接,变成一个新的词加入到词表当中,同时由于es也不再单独出现,我们将它从词表中去除

我们之后不断重复这样一个过程,直到我们的词表数量达到预定的一个值,这样所有出现在语料库中的句子,其实都可以通过这样一个词表,切分成一个个单独的token,就完成了我们BPE的这个过程。
BPE的提出,但是是为了解决out of vocabulary的问题,其实就是出现OOV的问题,即指在这个输入的文本中,我们会出现了一些在词表中没有出现过的词,这样就导致模型无法理解这个新的单词的含义,我们也没有办法找到对应的这个向量表示,这时候往往会使用一个特殊的,比如说UNK这样一个符号来代替,这个问题其实在NLP中非常常见,比如说像我们之前那样,使用空格直接对句子进行一个切分,势必会很难穷举到所有的单词。
而BPE通过将文本序列,变成一个个sub word的一个更小的单元,就可以通过将之前没有见过的单词分解为一个个见过的小的sub word,就可以表示更多的单词,比如像下面这个例子中,如果出现了一个新的单词lowest,它就可以被切分成low和est两个部分,这样就可以对一个新的单词进行表示,同样通过这样的一个方式,也可以让模型学会low和lowest之间的一个关系,这样的关系也可以被泛化到,比如说像其他的单词中比如samrt和smartest,因为它其实表示的是一个形容词最高级的一个形式,并且在当时,使用BPE编码的机器翻译模型,其实也在很多机器翻译的比赛中取得了非常好的效果。

接下来我们看一下输入层的另一个重要部分,叫做位置编码,即positional encoding,
这个模块出现的主要原因是,Transformer不同于RNN,他没有办法通过处理先后顺序来建模每个单词的位置对应关系,所以,如果没有位置编码,Transformer block对于不同位置的相同单词其实是没有办法区分的,但我们其实都知道,对于文本来说,他的一个位置关系,一个token出现在文本中的位置其实是非常重要的。
Transformer为了解决这个问题,就提出了一个显示好的建模位置关系的一个方法,即:通过在原有的embedding上加上一个位置向量,然后让不同位置单词具有不同的表示,进而让Transformer block可以进行一个区分
我们首先假设BPE得到的这个BPE和经过embedding之后的向量的维度为d,那么我们这个位置编码,其实也需要是一个维度为d的向量,Transformer采用了一个基于三角函数的一个方法,来得到对应的位置向量,具体的公式如下:
其中pos表示这个当前token在句子中的位置,它是一个从0到这个序列长度的一个数
i是一个从0到二分之一d的一个数,它表示当前这个位置在embedding中的index,我们可以看到在embedding维度中的偶数位置,它其实是一个正弦函数,而在奇数位,它是一个余弦函数
同样,通过这个公式,我们也可以看到,位置编码的一些特点:首先是位置,一个具体的位置就是pos和它得到编码向量其实是一一对应的,不会出现说不同的位置会有相同的位置编码向量的情况;第二个的话就是位置编码大小其实是有界的,他不会特别大或者特别小,因为三角函数是有界的;第三个根据三角函数的性质,我们可以发现不同位置的位置编码向量之间的差别取决于他们之间的相对位置,我们最终输入到每个Transformer block中的就是将BPE和PE按照位置相加得到的一个向量表示。

为了更方便理解位置编码向量,我们对一个简单的位置编码进行以下可视化:
这里展示的是一个长度为10个token,维度为64的一个编码向量
可以看到相同维度的,就是每个竖线,它其实是一个周期的正弦或者余弦函数
而相同位置,也就是每个横线的话,它其实对应不同周期的正弦或者余弦函数

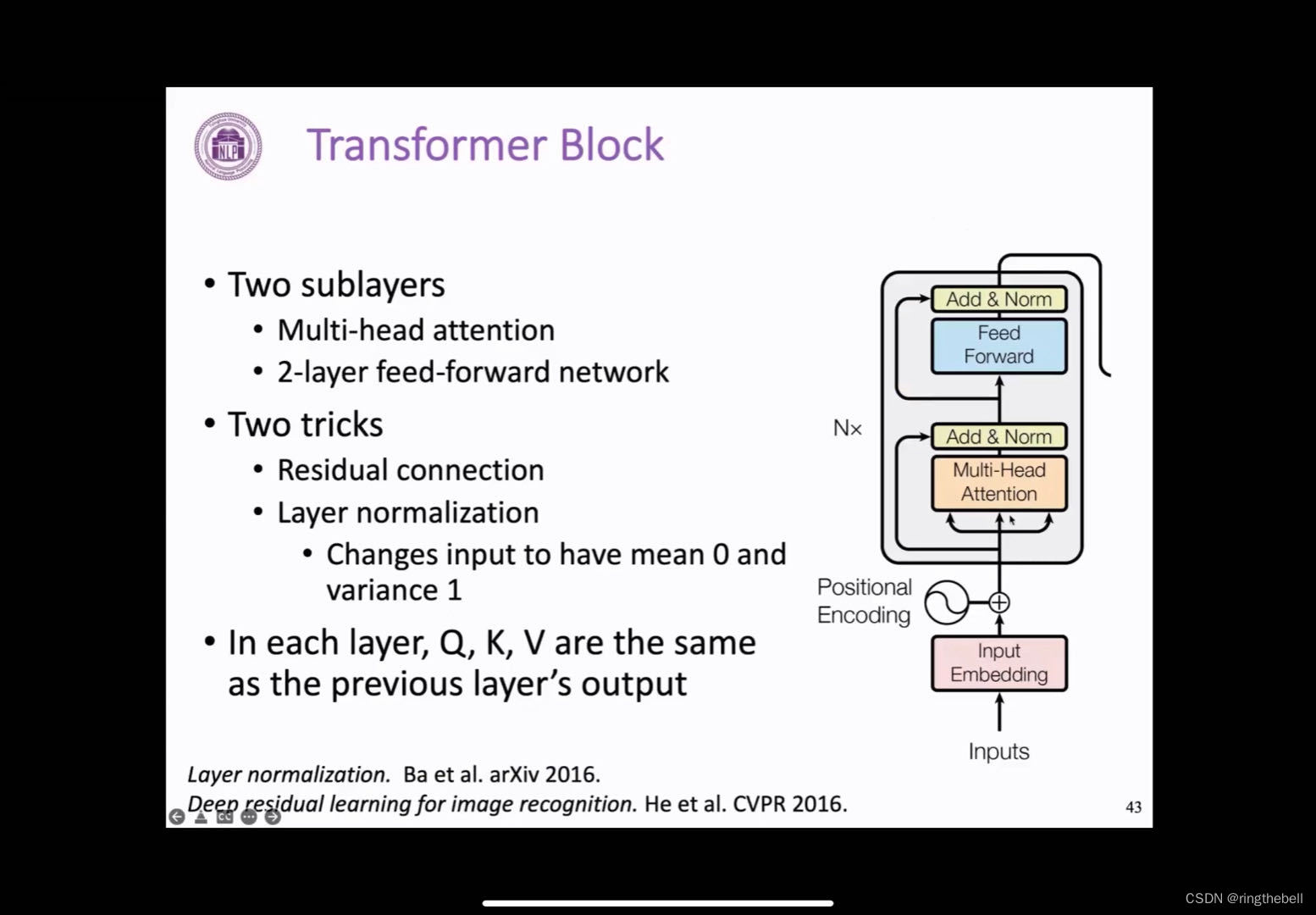
encoder block-核心(Transformer block)
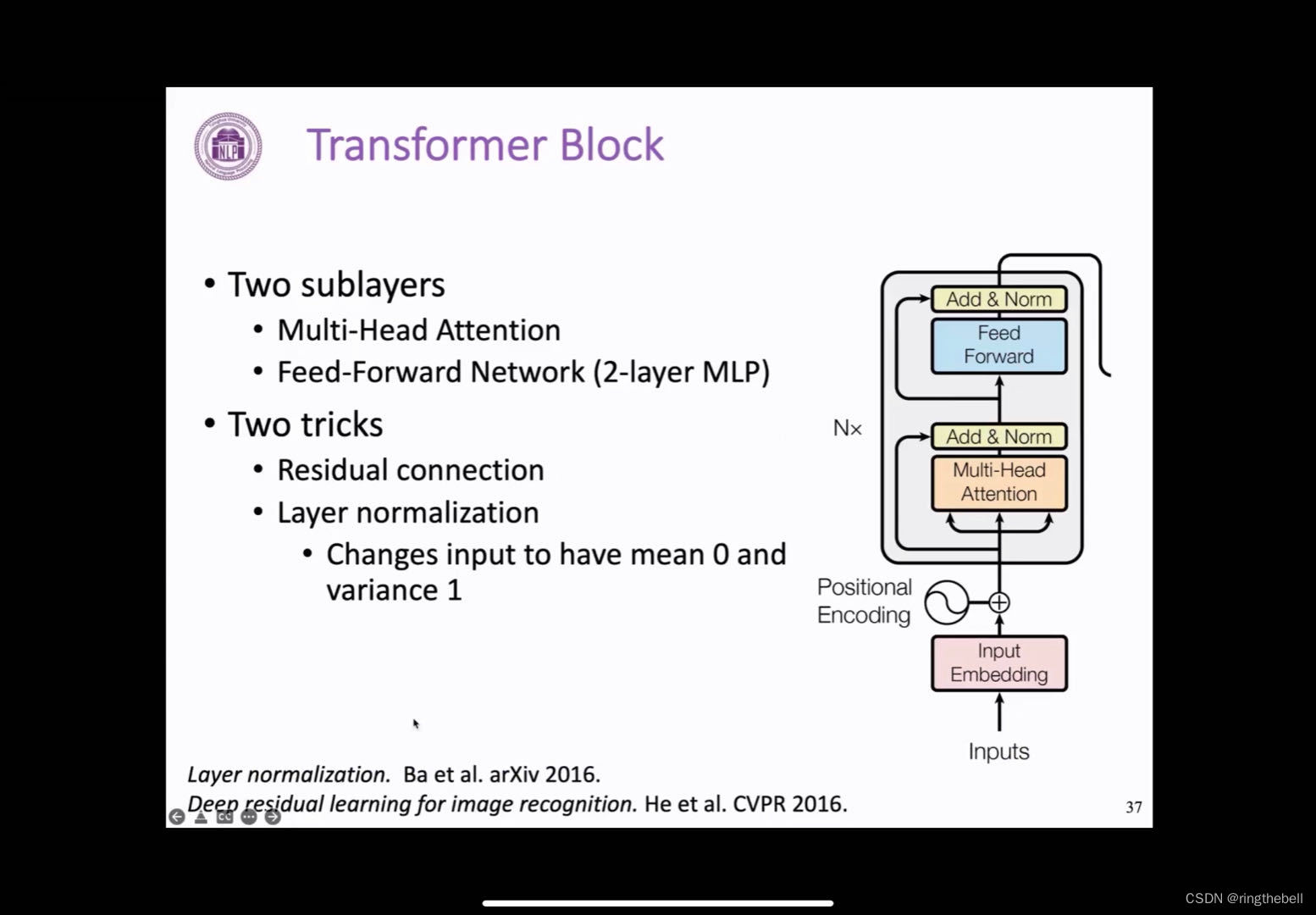
右图是截取的一个encoder端Transformer block的一个情况,encoder的情况会有一些略微的不同,我们现介绍encoder端的这个部分。
它的整体是由两大块组成的,分别是前面的这一块叫做multi-head attention的一个网络,后面是feed-forward network的一个前馈神经网络,它其实本质上就是一个带激活函数的MLP全连接。
(MLP是多层感知器(Multilayer Perceptron)的缩写,是一种常见的人工神经网络模型)
除此之外还有两个小技巧,第一个是残差连接,即图中,从主线指向add&norm的这条线,残差其实本质上是借鉴于计算机视觉的领域中的大名鼎鼎的ResNet,这样一个结构可以通过将它的输入和输出直接相加,我们就可以缓解模型过深之后带来一个梯度消失的问题,而且这样的一个结构在很多计算机视觉的模型中也起到了重要的作用,这个特性也会继续在Transformer 中发挥重要的作用,为后续我们构建成熟很深的预训练模型提供了一个可能。
另一个小的技巧就是Layer normalization,正则化其实是一个比较常见的技巧,它夹在add&norm这个位置,而且有着很多变体,我们这里采用的Layer normalization,其实就是在隐向量这个维度来进行正则化,它会将输入的一个向量变成一个均值为0,方差为1的一个分布,这样的一个技术其实同样是为了针对梯度消失和梯度爆炸的问题。
(注:红色字体相关内容可以进入关于大模型学习中遇到的4查看学习)
(图左下角的两篇文章分别是以上两个技巧的来源)
我们在Transformer中这里用到的一个注意力机制其实是一种基于点积的注意力机制,相比于前面学习的在RNN中使用的一些注意力机制可能略有不同,但主要思想是一致的,我们首先简单回顾一下前面学习的注意力机制,它就是给定一个query向量和value向量的集合,我们通过注意力机制就可以基于query向量对value向量进行一个加权平均。
而在Transformer中,我们不同的是,它给定的是一个query向量和一个k向量和value向量对的一个集合,其中query向量和k向量的维度都是dk,value向量的维度是dv,这样的这个输出,同样是对value向量的一个加权平均,只不过不同于之前用q和v来计算注意力分数,我们这里采用q和k的点积来计算注意力分数,也就是以下公式提到的这个q和ki和kj的一个点积,最后还是会得到一个长度为n的一个注意力分数,然后通过使用softmax,我们就可以将这样一个注意力分数,变为一个注意力分布,一个概率分布,进而就可以对得到的v向量进行一个加权平均,也就是这样一个attention的一个输出。同样如果我们有很多个q向量,它就可以组成一个矩阵Q,我们对每一个q向量都进行上述的这样一个操作,其实更直接地,我们可以用一个矩阵的乘法,来表示这个过程,这样最后得到的这个公式非常简洁,而且易于实现,最重要的是,通过这个公式,我们可以发现公式中的q,其实它的计算是互不干扰的,是可以并行进行的,更方便我们在GPU等设备上进行并行的一个运算。

下面我们用一个图示来解释一下这个attention的过程:
首先这里有3个矩阵:Q、KT、V。其中Q k都是二乘三的一个情况,然后我们首先将Q、K矩阵进行一个矩阵乘法,就可以得到一个二乘二的Attention Score注意力分数,这个注意力分数第一行就是第一个query向量和两个k向量进行点积的结果,第二行就是第二个query向量和两个k向量进行点积的结果,随后我们对每一行都结算一个softmax,就可以得到一个注意力的一个分布,他的每一行就是一个概率分布,然后求和为1
随后我们将这样一个注意力分布和它对应的value矩阵进行一个矩阵乘法,我们就可以看到,其实得到的output第一个向量,就是用前两个值对两个v向量进行加权平均,最后得到二乘三的output
以上基本就是attention在做的主要的一个事情。

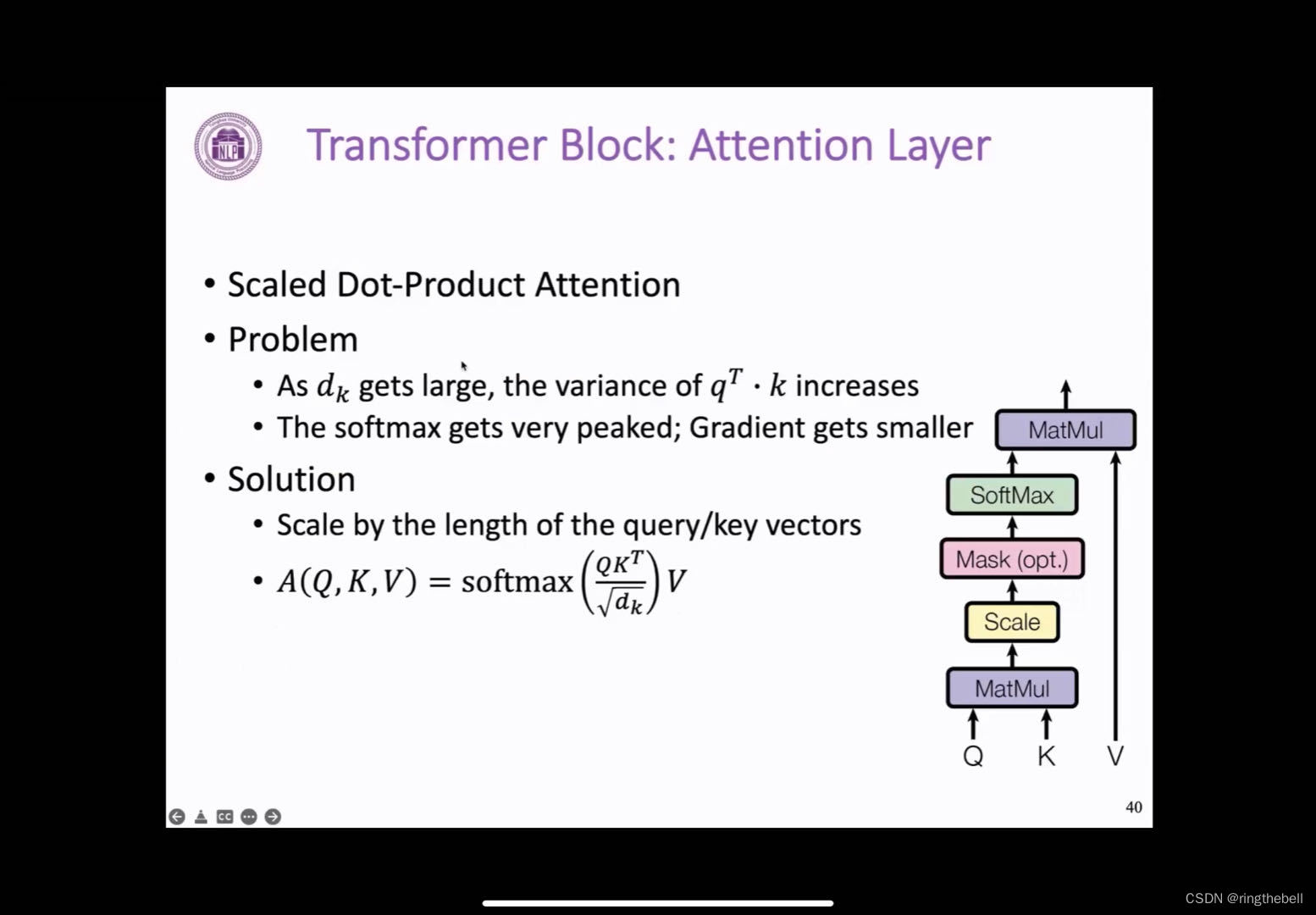
在前面attention的一个基础上,我们进一步需要加入一个scaled系数,就是一个完整的scaled dot-product attention模块,这个也就是在Transformer中使用的一个attention的一个情况,首先我们还是看一下,前面如果没有这个scaled技术他的一些问题:
因为我们这里的注意力分数的计算方式是通过q和k的点积实现的,如果在正常情况下,q和k的点积它得到的这个标量的这个方差,它会随着dk的增加而变大,这个其实如果在之后作用到softmax函数里面,就会出现一个问题是,它得到的概率分布会变得更加尖锐,然后某些有某个位置可能会变为1,其他大部分文字的这个概率分布都非常接近0,这样导致的结果就是梯度可能会变得越来越小,不利于进行参数的一个更新。
这里提供了一个解决方案,将q和k在点积之后除以一个根号k的方式,然后这样可以表示,得到这个注意力分数的方差它依然为1,来防止上述这样问题的一个出现。
右边的图完整的展示了这样一个attention的过程
我们再来重新理一下,首先是q和这个其中这个mask这个位置,我们会在decoder中体现。其次我们可以看到Q和K进行一个矩阵乘法,得到对应的一个注意力分数matmul,然后通过scaled系数,即根号k,来将其这个规模进行一个放缩。然后再通过softmax,将这样一个注意力分数变成了一个概率分布,随后通过预对应的V矩阵进行一个矩阵乘法,就可以对v矩阵实现一个加权平均,也就是我们得到的最后一个输出。
前面提到的K、Q、V也是用这三个字母表示,但其实因为我们这个attention,使用的是一种自注意力机制,我们希望的是,模型能够自己每个token能够自主地选择,应该关注这句话中的哪些token,并进行信息整合,所以,对应到K、Q、V这三个矩阵,其实他们都是从文本的表示向量乘上一个变换矩阵得到的,而对于非第一层的Transformer block来说,文本的表示向量其实就是前面一层的输出,而对于第一层的block来说,这样一个表示文本的表示向量,其实就是我们前面提到的这个词表向量和对应位置编码的一个求和。

在上述单个attention的一个基础上,Transformer 为了进一步增强模型的一个表示能力,它采用了多个结构相同但参数不同的一个注意力模块,组成了一个多头的注意力机制。
其中每个注意力头的一个计算方式都和前面介绍的是完全一致的,只不过每一个头,它都会有一个自己的权重矩阵WiQ、WiK、WiV,就分别对应这个linear这个位置。
每个注意力头通过前面提到的这种方式得到自己的这个输出之后,我们将这些输出在维度层面进行一个拼接,然后通过一个线性层进行整合,就得到了我们多头注意力机制的一个输出。可以看到这样一个多头注意力机制,他的输入就是前一层的输出或者是输入的时候embedding和位置编码的一个相加。

然后它输出的文本,就会通过这个残差连接和正则化之后就会输入到后面的前馈神经网络,这样我们就走完了Transformer block的一个过程。
(注:红色字体相关内容可以进入关于大模型学习中遇到的4查看学习)
我们再重新看一下这个机构,他还是两个主要的部分:第一个部分是一个多头的注意力机制,第二部分还是刚才提到的前馈神经网络。其实本质上它还是一个两层的全连接,通过这样一个过程,他们完成了文本和不同位置文本之间的一个交互,然后中间的残差连接和正则化,也起到防止梯度消失的问题。
K、Q、V这三个字母本质上它都是从文本的表示中得到的,每个Transformer block的一个输入其实就是前一层的输出,或者说是input层的一个输出,所以这样导致的一个情况就是每个Transformer block他可以完全堆叠在一起,然后形成组合,成为一个更深的一个神经网络,然后也就是这个用n来表示他的一个数量,在原始的论文中,encoder端一共堆叠了6个block。
Transformer decoder block
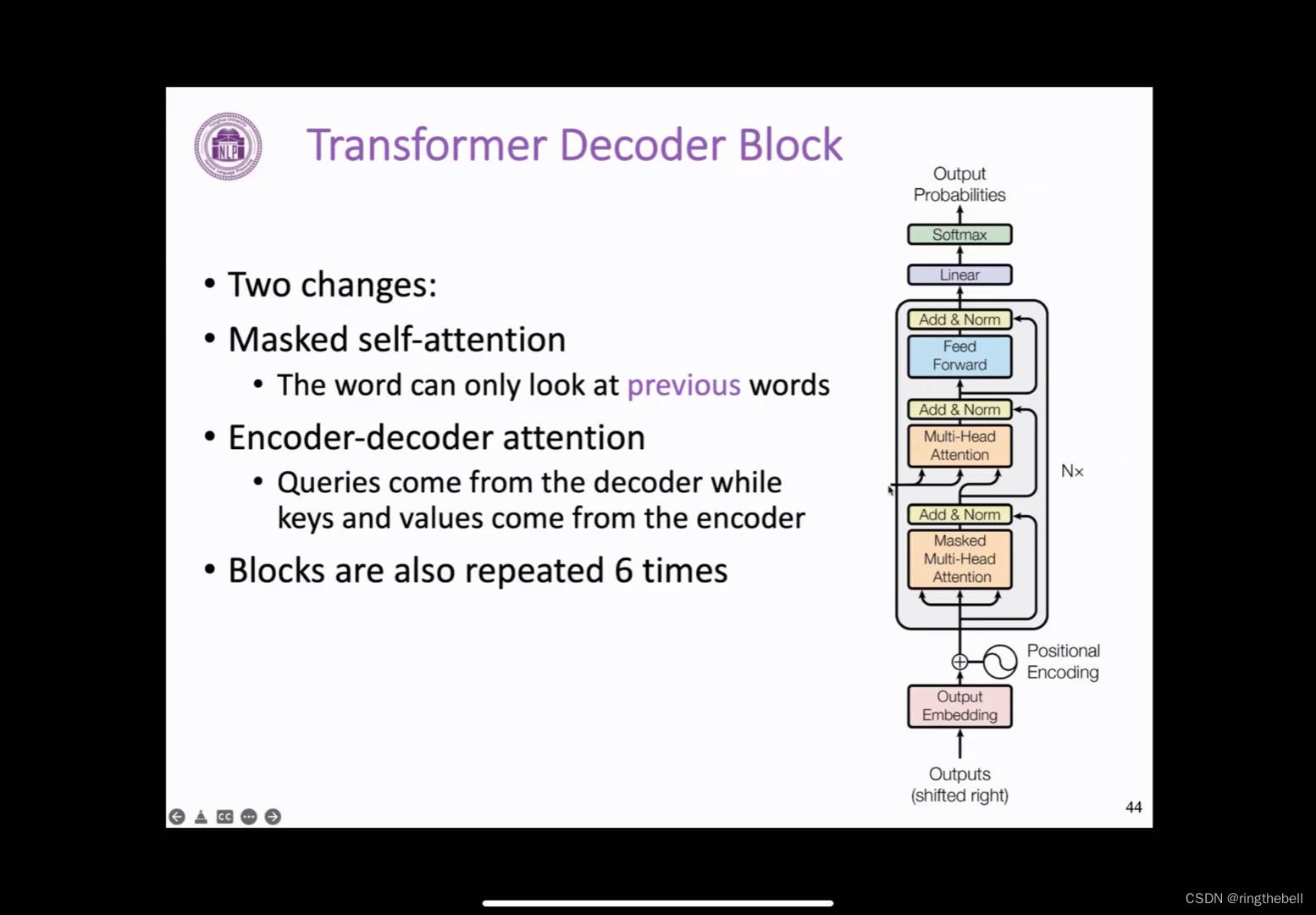
前面介绍的是encoder端每个block的一个内部的一个结构,对于decoder端其实大体上是一致的,但有两个简单的修改。
第一个修改就在于,最开始它并不是一个multi-head的特性,而是一个加了一个mask的这样一个词,这个所谓的mask,就是通过限制得到的q和k相乘的得到的注意力分数的上三角那部分,变成一个负无穷大,这样我们经过softmax之后,那些位置对应的概率都会变为零,使得模型无法在当前输出的这个步骤的时候,看到后面的单词,后面我们会用一个具体的例子来介绍。
另一个部分的话,就是中间加入的这个encode端r和decoder端的attention,这个结构其实和前面提到的multi-head attention完全一致,不同的地方在于,它输入的q向量query向量,它是来自于decoder,而k向量和v向量其实是来自于encoder最后一层的一个输出,通过这个部分,有些类似于之前所介绍的端到端模型中的注意力机制,它是为了帮助decoder端每一步生成都可以关注和整合encoder端每个位置的信息而设计的
同样的是,这样的一个decoder端的Transformer block,它也可以进行堆叠,在原论文中也是一共堆叠了6层。
现在我们来说一下刚才提到的mask的multi-head attebtion的一个具体的一个计算方式,
可以看到输入还是相同的QKV三个矩阵,和之前一样的是,通过Q和K矩阵进行一个矩阵乘法,可以得到一个注意力分数,之后就是mask的一个操作:把左对角线的上三角部分,也就是最右上角的这个值变为一个无穷大,而一个负无穷大导致的结果就是,我们在计算softmax之后,右上角这个值会变为0,这样的话,通过矩阵乘法,第一个位置,即,第一行的输出,它其实只是第一个v向量乘上了第一个值,而0会导致第二个v向量,他对output第一行是没有帮助的。第二行的话其实是和原来一样的,这个保证了我们decoder端在文本生成的时候,它是顺序生成的,不会出现我们在生成第i个未知的时候,参考了第i+1个位置的信息这样一个情况,那之后我们从人类我们自己是从左到右来进行书写或者文本创作也好,这个逻辑和顺序是保持一致的。

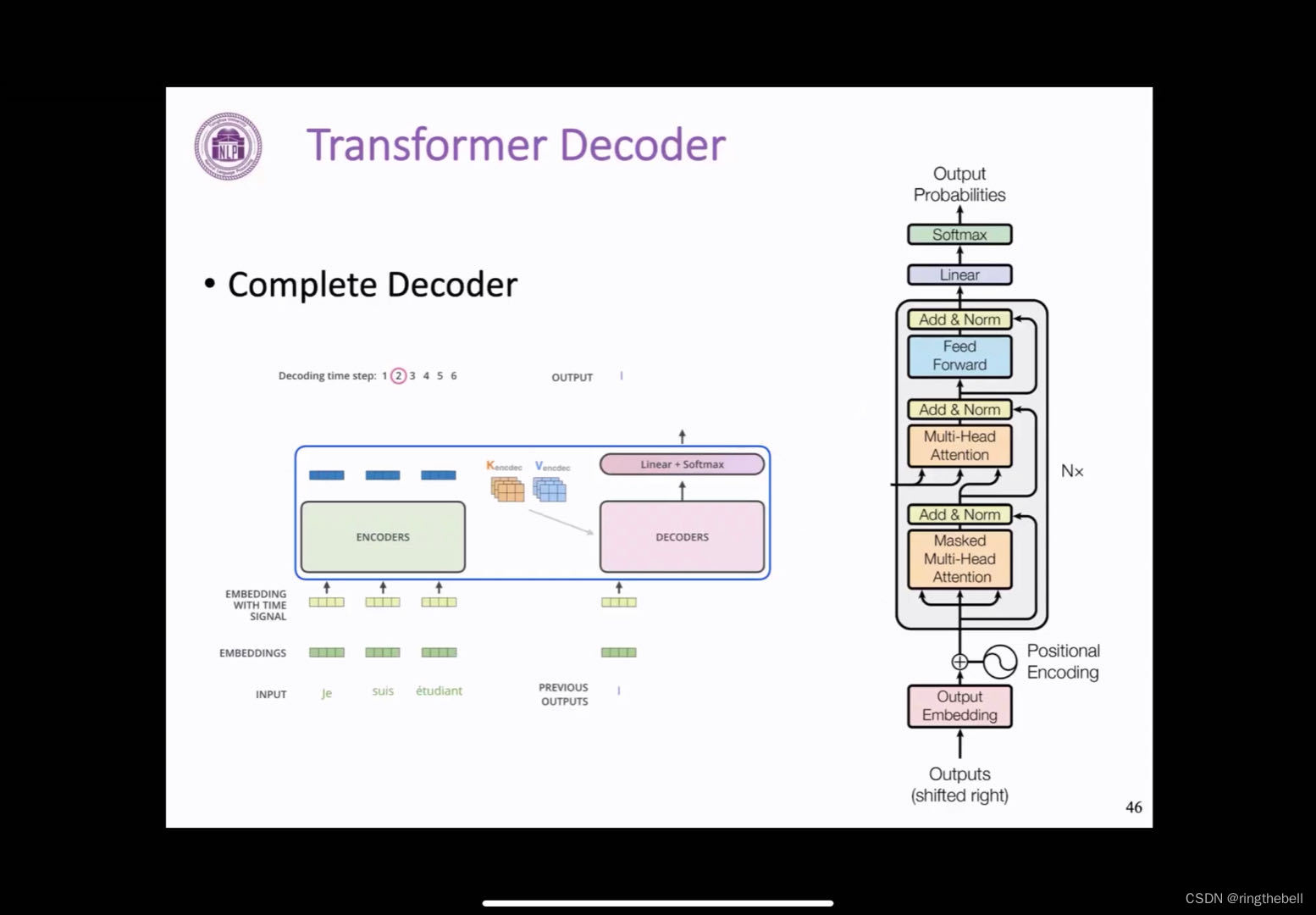
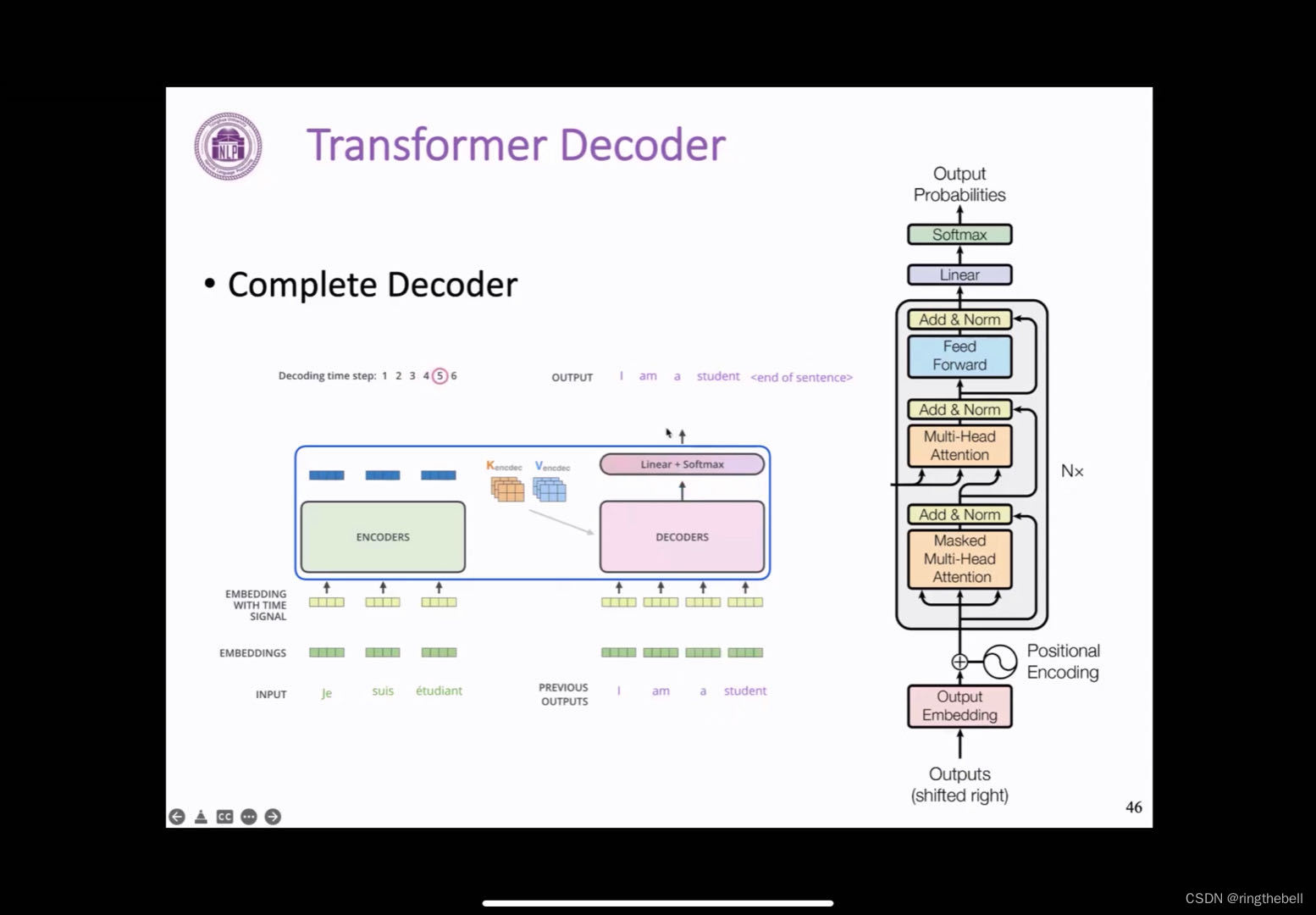
下面就是一个完整的一个Transformer block过程:
在推理阶段,模型首先会生成第一个字母i,进行拼接,然后再生成下一个am……逐个生成这样的token,然后每个位置的输出,都会拼接到decoder输入后面,最后完成整个句子的一个输出。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AWS简介(Amazon Web Services )想使用怎么办?
- 机器学习 | 密度聚类和层次聚类
- Java刷题篇——链表分割
- Mac版JDK环境配置及Java多版本切换、Android 升级签名算法从SHA1withRSA 升级到SHA256withRSA
- ChatGPT 报:“Unable to load history…”如何处理?
- 理德外汇名人故事:投资大师查理·芒格的传奇人生与投资智慧
- 电阻分类,选型注意事项
- leetcode47,leetcode491,leetcode40,leetcode90,系列问题包你懂!!!Trie树对于排列问题、组合等结果集去重的应用
- centos 编译安装 libxml-2.0
- 【基础】【Python网络爬虫】【3.chrome 开发者工具】(详细笔记)