【订单领域】如果订单要分库分表,如何确认最佳库表数量?
?🎉欢迎来系统设计专栏:如果订单要分库分表,如何确认最佳库表数量?
🎬作者简介:大家好,我是小徐🥇
??博客首页:CSDN主页小徐的博客
🌄每日一句:好学而不勤非真好学者📜 欢迎大家关注! ??
一、前言
首先我们先对分库分表的概念有一定的了解~
分库分表,是企业里面比较常见的针对高并发、数据量大的场景下的一种技术优化方案,所谓”分库分表”,根本就不是一件事儿,而是三件事儿,他们要解决的问题也都不一样。
这三个事儿分别是"只分库不分表”、"只分表不分库"、以及"既分库又分表”
分库主要解决的是并发量大的问题。因为并发量一旦上来了,那么数据库就可能会成为瓶颈因为数据库的连接数是有限的,虽然可以调整,但是也不是无限调整的。所以,当你的数据库的读或者写的QPS过高,导致你的数据库连接数不足了的时候,就需要考虑分库了,通过增加数据库实例的方式来提供更多的可用数据库链接,从而提升系统的并发度。
分表主要解决的是数据量大的问题。假如你的单表数据量非常大,因为并发不高,数据量连接可能还够,但是存储和查询的性能遇到了瓶颈了,你做了很多优化之后还是无法提升效率的时候,就需要考虑做分表了。
那么,当你的数据库链接也不够了,并且单表数据量也很大导致查询比较慢的时候,就需要做既分库又分表了。
接下来我们以订单领域为例,探讨如何分库分表~
二、如何确认最佳库表数量?
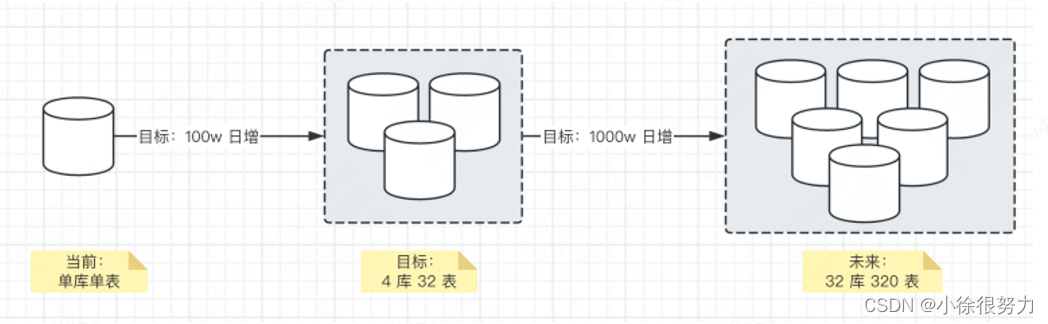
随着业务发展,订单单库单表到达性能瓶,需要进行分库分表。
分库分表需要重点考虑 sharding key 分片键、库表数量。一般情况下,订单可以使用 id、user id、merchant_id 作为 key。
因此,本文的重心放在如何计算库表数量。需要考虑的因素有: 单表性能、硬盘容量、在线 DDL耗时、数据库连接数。
1、单表性能
这是最关键的因素。MySQL 单表最大记录数,行业内没有定论,有说 500w 的,有说 2000w 的。本质的原因,数据量过大,会超过 B+ 树的建议层高 3-4 层,影响 0 性能。
总的来说,我们可以设置一个标准:
- ?优秀: 500w ~ 1000w
- ?良好: 1000w~ 2000w
- ?较差: 2000w ?5000w
基于这个标准,我们期望分库分表后,单表控制在 1000w 以内,可进 (优秀) 可退 (良好)
现在,我们来定义下这次分库分表的目标
- 单表控制在 1000w 以内
- ? 日增订单量 100w
- 满足近 1 年的用户订单存储
那么,1 年总的订单量是 365 天 x 100w = 36500w 单。计算下,需要多少个表如下:
| ? | 500w | 1000w | 2000w |
| 总表个数 | 73个 | 36.5个 | 18.25个 |
这样的话,我们可以考分 4 个库,每个库 8 个表,基本控制在 1000w 单,运维成本也可控
问: 为什么不考虑存量订单,只考虑增量订单?
答:这个主要看场景,在较大的订单日增下,存量基本可以忽略不计,例如说上面这个案例。
问: 会不会存在 1 年后,现有分库分表又达到瓶颈?
答:首先,确实存在这种可能性,但是尽量不要过度设计,硬件是有成本的。并且我们在做上面这个案例设计时,虽然定的目标是日增 100w 订单,但是可能当下日增实际值有 10w 左右,提前做的技术预研。
其次,架构是持续迭代的,如果真碰到日增从 100w 朝着 500w 或者 1000w 时,恭喜你,继续做下一轮拆分吧。如下图所示:
另外,订单是有明显冷热之分的,超过 90 天的订单往往就不再查询和变更,会考虑归档订单历史库。例如说: 某东、每日优鲜、淘宝、收钱吧等公司。这样,我们可以进一步控制订单表的单表大
2、在线 DDL 耗时
对 MySQL 大表的 DDL 作时,一般放在业务低峰期,往往是半夜,避免可能的锁表影响业务.在我们把单表控制在 1000-2000w 记录以内的话,半夜 6 小时内肯定可以完成
另外,也可以使用一些开源的工具来进行 DDL 操作,尽可能避免锁表。例如说: pt-online-schema-change、gh-ost 等等.
3、数据连接数
分库分表后,单个数据库实例会有多个库,因此 MySQL 的连接数会相应的增加。不过一般情况下,也就乘以几倍,基本问题不大,可以不用考虑太多
4、硬盘容量
需要预留 20% 硬盘容量,避免数据继续增长,数据库无法写入。例如说: 华为云 RDS 的“磁盘空间满”情况:
随着业务数据的增加,原来申请的数据库磁盘容量可能会不足,需要为云数据库RDS实例进行扩容。实例扩容的同时备份空间也会随之扩大。1T8以下盘空间使用事达到95%,或1T8及以上强盘空间使用量剩余50CB,实例将显示"磁盘空间满”,此时数据库不可进行写入操作。您需要扩容至磁盘空间使用率小于85%才可使实例处于可用状态,使数据库恢复正常的写入操作。
虽然比较少出现这种情况,但是还是要稍微注意下,== 我就踩过这样的生产事故
题外话:
如果订单日增 5000w,你会拆分多少库表呢? 可以分别计算保留 90 天、180 天、365 天不同的结果哟~
学习是一个输入输出的过程,一定要勤动手,动手才会动脑”

?
三、扩展
1、分库分表后如何进行分页查询?
在我们做了分库分表之后,数据会散落在不同的数据库中,这时候跨多个库的分页查询、以及排序等都非常的麻烦。
如果分的库不多,那么我们还可以通过扫表的方式把多个库中的数据都取出来,然后在内存中进行分页和排序。
比如我要查询limit 100,100 的话,有三个库,那我就分别到这三个库中把0 - 200之间的数据都取回来,然后再在内存中给他们排序,之后,再取出第100-200之间的数据。
这种做法非常的麻烦,而且随着偏移量越大,当要分的页很多的时候,可想而知这种方法根本就不靠谱。
网上有很多文章写了几种做法,还起了几个名字,比如全局视野法、二次查询法、业务折衷法的,在我看来,这几种做法根本就都不靠谱,而且只会带来复杂的理解和维护成本,而且没有办法都一定的前提条件限制。
一般来说,在企业中是怎么做的呢? 我们还是拿订单的分库分表举例,当我们用买家ID分表之后:
- shardingkey查询
一般来说,买家的订单查询是最高频的,而对于买家来说,查询的时候天然就是可以带买家ID般来说,的,所以就可以路由到单个库中进行分页以及排序了
- 非shardingkey的关键查询
那么,电商网站上不仅有买家,还有卖家,他们的查询也很高频,该怎么做呢?
般来说,业务上都会采用空间换时间的方案,同步出一张按照卖家维度做分表的表来,同步的过程中一般是使用canal基于bin log 做自动同步。虽然这种情况下可能存在秒级的延迟但是一般业务上来说都是可以接受的。
也就是说,当一条订单创建出来之后,会在买家表创建一条记录,以买家ID作为分表字段,同时,也会在卖家表创建一条记录出来,用卖家ID进行分表
并且这张卖家表不会做任何写操作,只提供查询服务,完全可以用一些机器配置没有那么高的数据库实例。
这样,卖家的分页等查询就可以直连卖家表做查询了。
- 非shardingkey的复杂查询
那除了买家、卖家以外,其他的查询怎么办呢?
般来说,大型互联网公司用的比较多的方案就是使用分布式数据仓库来实现,也就是说我们会把这些数据同步到像TiDB、PolarDB、AnalticDB等这些数据库中,或者同步到ES中,然后在这些数据库中做数据的聚合查询。
有人说,都用了MySQL了,还要用这些数据库,那方案也太重了,搞的这么复杂干什么?
那话又说回来了,分库分表,真不建议小公司、小团队用,这玩意本身就是意味着成本高的又想要简单,又想要高效,又想要没问题? 在技术领域,是没有银弹的~
2、分库分表后,表还不够怎么办?
有的时候,当我们对数据库做了分库分表后,因为最初的预估数据不够准确,导致后续数据增长很快,表不够了,那么遇到这种情况该怎么办呢?
首先,我们应该尽量避免这种情况的发生,在第一次决定分表的时候,就尽可能根据当前的业务增长量预估一下未来可能需要存储的数据量,并且最好一定的buffer,让这个分表尽可能够,避免出现不够的情况。
比如我们线上分表基本都是256、512、1024这样分的。
其次,如果真的后面就不够了,其实也没啥特别好的办法,要么就通用其他的手段来减少数据量,比如我们之前提到过的数据归档等.
那还有,就只剩一条路了,那就是二次分表,即原来的128张不够,那么就需要重新分成256张表。这个过程和第一次从单表分成128张表过程差不多。
涉及到分表算法的更新,数据的迁移等。其中最关键的就是如何无损、无缝的做数据迁移了这个我后面会再加一篇单独写如何做数据迁移。 (占坑。)
另外,还有一个值得考虑的,就是如果最开始用的是一致性hash的算法进行分表路由,那么在做二次分表的时候,数据迁移的成本就会低很多,因为影响的节点可能没那么多。
所以,总结一下,就是要么提前多分点、要么就是先办法减少数据量,如做数据归档,要么就是重新分,然后做数据迁移。如果提前考虑过的话,用了一致性哈希的话会影响更小一点。除了这些,也没啥更好的办法了。
仅供参考,欢迎评论区留言,一起讨论~
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于cityselect 搜索插件
- 压缩编码之变换的选择之离散余弦变换(DCT)和离散傅立叶变换(DFT)——数字图像处理
- C# QuartzHelper 封装Quartz 简化操作流程
- c++环形缓冲区学习
- 成都谷达冠楠:抖店新手怎么上货
- 数据结构学习 jz53_1 在排序数组中查找数字1 0 ~ n - 1 中缺失的数字
- [mysql 基于C++实现数据库连接池 连接池的使用] 持续更新中
- 【MySQL】主从异步复制配置
- 架构设计的核心:从多个维度理论分析
- 亚信安慧AntDB数据库引领数字时代通信创新