NLP项目实战02:英文文本识别
简介:
欢迎来到本篇文章!今天我们将讨论一个新的自然语言处理任务——英文短文识别。具体而言,即通过分析输入的英文文本来判断其是比较消极的还是比较积极的。
展示:
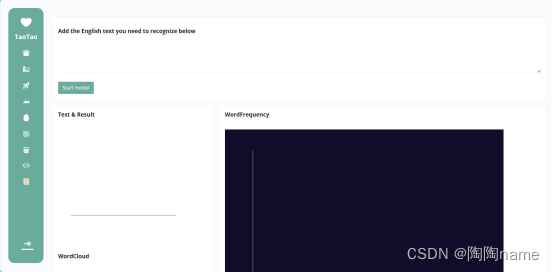
1、项目界面
如下所示是项目启动后用户使用使用界面
2、布局介绍
首先可以看到用户使用界面上存在这么几个部分:
2.1、最左边的功能栏
2.2、最上面的添加识别文本的输入框
2.3、一个start model按钮
2.3、Test & Result
2.4、Wordcloud
2.5、WordFrequency
3、功能介绍
3.1、最左边的功能栏
这部分暂时没有功能接入,可以根据个人需求进行功能接入
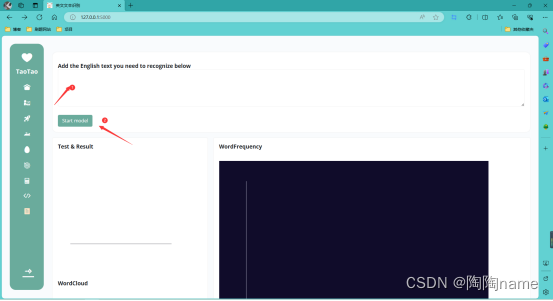
3.2、最上面的添加识别文本的输入框
在这里输入需要模型进行识别的文本,这里需要注意,由于本项目是关于英文文本识别的,所以这里输入的文本需要是英文才可以。如果输入的是其他语言的文本,可能模型没有办法进行识别,或者说会出现识别出错的情况。此外由于是英文文本识别,所以用户使用界面,我也全用英文写的
3.3、一个start model按钮
当我们输入好了文本以后,我们就可以点击这个Start model进行文本的识别了
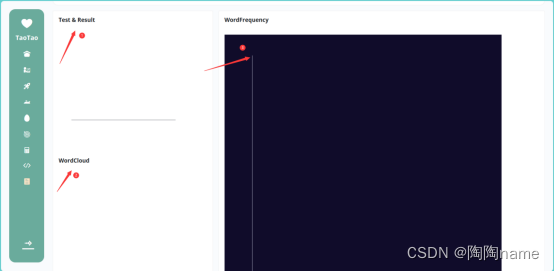
3.3、Test & Result
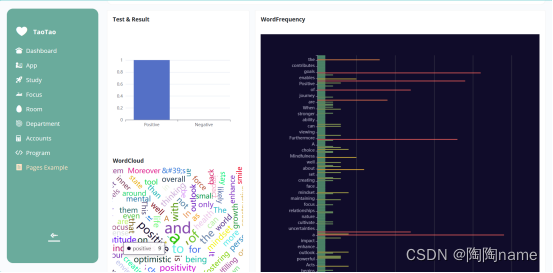
当模型识别以后,用户界面会将识别结果进行展示,Test & Result的结果TaoTao这里使用的图表的形式展示的,图表有两个属性,一个是Positive还有一个是Negative,其中Positive表示输入的识别文本是积极的一类,而Negative则表示消极
3.4、Wordcloud
这里属于词云的范畴了,也就是说这里会给我们输入的文本进行统计,并给数据以词云的方式展示出来。单个词在文本中出现的次数多,则词云的字体就越大。相反当单个单词在文本中出现的次数越少,则词云的字体就越小
3.5、WordFrequency
这里统计的是输入文本中每一个单词出现的单词频率。
详细的界面效果如下所示
4、项目设计思路
本项目的实现思路如下流程图所示:
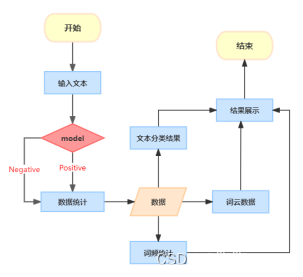
这里的model采用的是深度学习中比较基础的全连接网络实现的。
数据使用的是开源数据数据集IMDB,然后用户界面采用的是Flask结合着echarts实现的。可以看到数据和模型算法都是比较容易实现的。所以我建议大家还是需要多多练习实践,只有实践,才可以对代码有更加深刻的理解。
5、功能演示
项目的具体演示如下面的视频所示:
202312161354
6、运行环境介绍
环境:windows+anaconda
主要的python库如下:
Flask 3.0.0
torch 1.8.2+cu102
torchaudio 0.8.2
torchdata 0.7.1
torchtext 0.9.2
torchvision 0.9.2+cu102
说明:运行本项目cpu版本的torch也是可以运行的,但是建议使用GPU进行
7.、运行项目:
首先在项目目录下打开cmd,然后输入:python model.py
当然了,你也可以在pycharm中直接run
等待项目启动就可以了。项目启动可能会慢一点,这是由于代码需要加载数据集和模型,但是之后的使用还是比较快的,包括模型的识别速度。
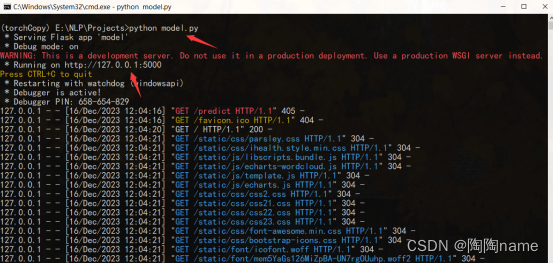
之后,在terminal中会有一个url,如下所示:
http://127.0.0.1:5000/
我们给这个url输入到网页中回车,就可以访问了
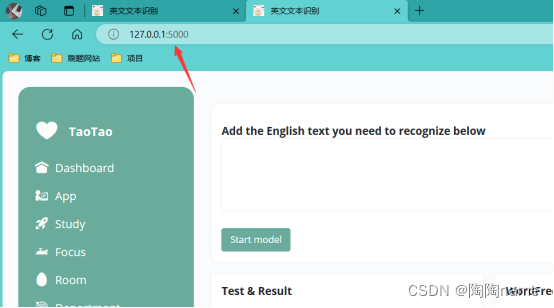
之后正常使用就可以了
最后说明:
由于笔者能力有限,所以在描述的过程中难免会有不准确的地方,还请多多包含!最后TaoTao还是建议大家需要多多练习实践,只有实践,才可以对代码有更加深刻的理解。
更多NLP和CV文章以及完整代码请到"陶陶name"获取。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!