[Python练习]使用Python爬虫爬取豆瓣top250的电影的页面源码
发布时间:2024年01月15日
1.安装requests第三方库
在终端中输入以下代码(直接在cmd命令提示符中,不需要打开Python)
pip install requests -i https://pypi.douban.com/simple/从豆瓣网提供的镜像网站下载requests第三方库
pip install requests是从国外网站下载,速度慢甚至有时候无法下载
2.导入第三方库
import requests3.编写代码
import requests
response = requests.get('https://movie.douban.com/top250')
print(response.text) # 打印返回的原始HTML4.运行
运行代码之后,没反应,无输出结果
可以看一下返回的页面请求状态码是多少:
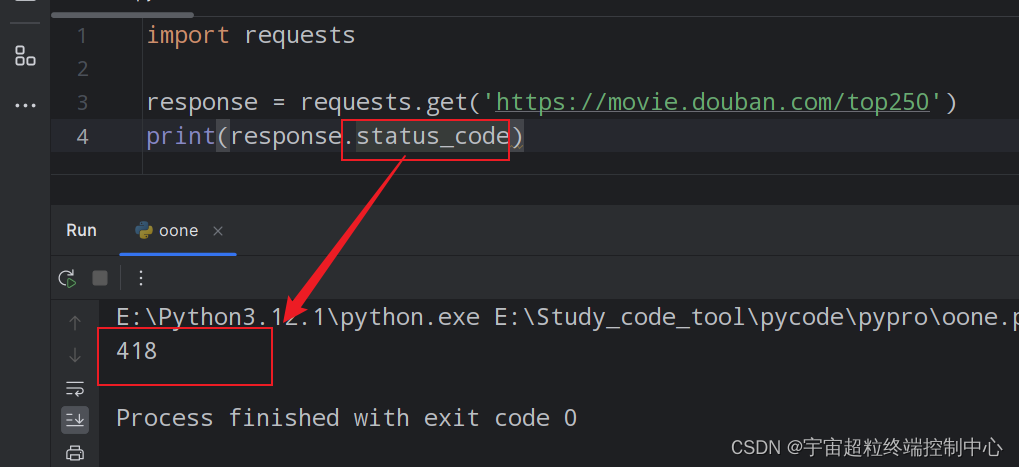
状态码是418,所有4开头的状态码都表示客户端错误,也就是说我们这边发送的请求存在问题。418状态码表示服务器不想响应你的请求。
但是我们的请求并没有问题。其实,这里是豆瓣在用这个状态码回应爬虫:希望服务正常的浏览器而不是爬虫程序的请求
遇到这种情况,可以绕过去的一个方法就是可以定义请求头,把程序伪装成浏览器
可以新建一个叫做headers的字典变量,请求头的User-Agent里面会给服务器提供一些客户端的信息。所以要去指定User-Agent的值

现在的问题是User-Agent的值是什么?
我们可以从浏览器发送的请求里去“抄作业”
回到浏览器,进入任何一个页面,右键,点击检查

找到“网络”或network。

刷新一下网页,这样你就能看到浏览器发出的所有http请求。随便点击一个请求,找到User-Agent

把冒号后边的信息复制下来到代码中


修改代码为:
import requests
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
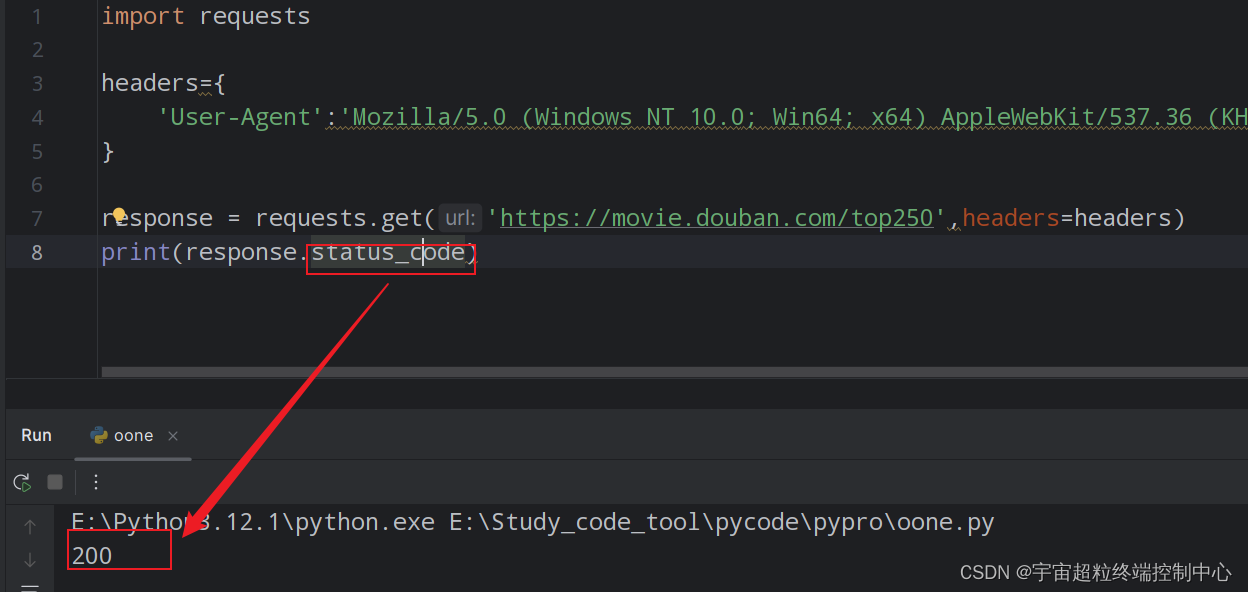
response = requests.get('https://movie.douban.com/top250',headers=headers)
print(response.status_code)运行成功
现在,获取豆瓣top250的电影的页面源码:
import requests
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
response = requests.get('https://movie.douban.com/top250',headers=headers)
print(response.text)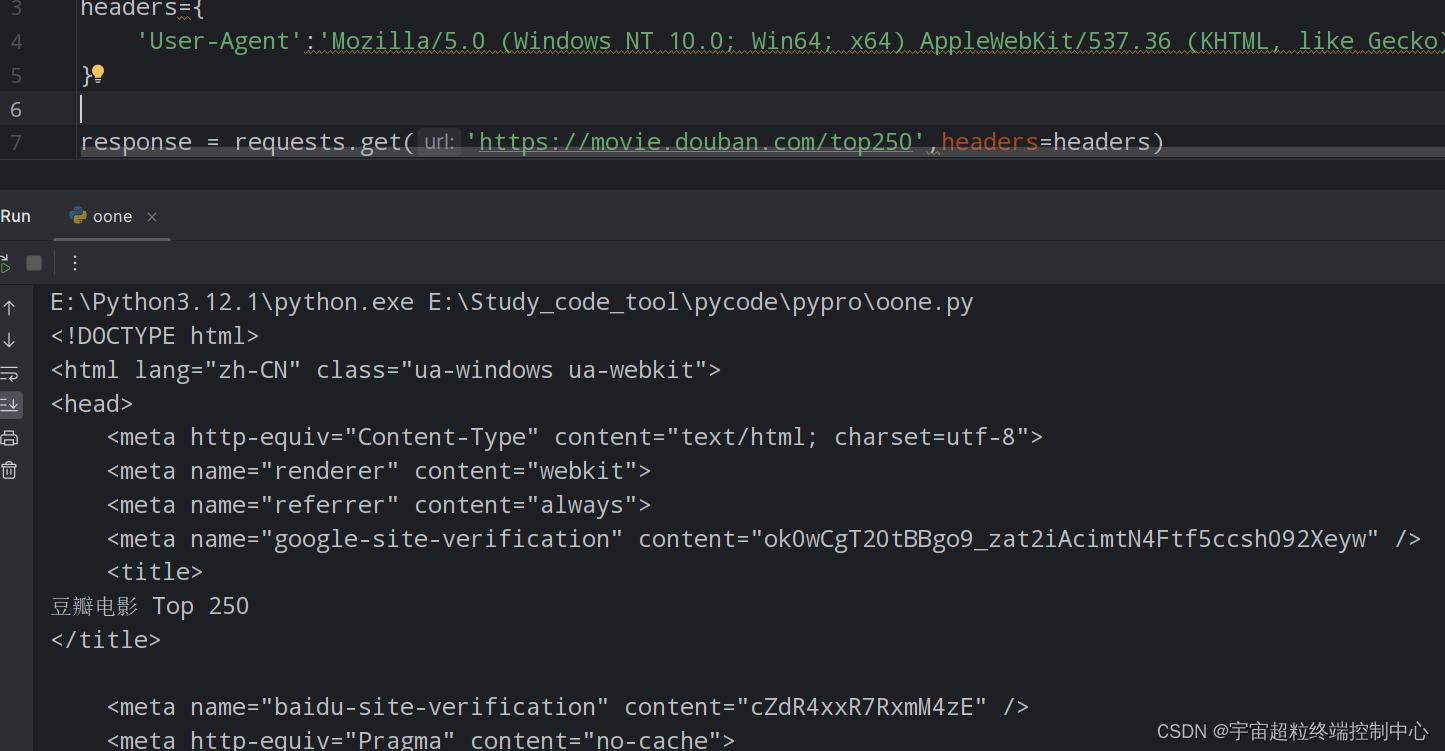
文章来源:https://blog.csdn.net/2301_82018821/article/details/135599197
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java常用类---包装类
- day 25回溯(二)
- 实验六 指针程序设计 要求设三个指针变量p1,p2,p3, 使p1指向三个数中最大者,p2指向次大者,p3指向最小者
- LeetCode75| 滑动窗口
- 微机原理4练习题答案
- 在 WebRTC 中,Offer/Answer 模型是协商 WebRTC 连接参数的关键部分
- 登陆提示:不支持你所在的地区,“Openai’s services are not available in your country…”
- 阿里云腾讯七牛内容安全配置
- 选数C语言
- 防火墙综合实验