JoyRL Actor-Critic算法
发布时间:2024年01月22日
策略梯度算法的缺点
这里策略梯度算法特指蒙特卡洛策略梯度算法,即?REINFORCE?算法。 相比于?DQN?之类的基于价值的算法,策略梯度算法有以下优点。
- 适配连续动作空间。在将策略函数设计的时候我们已经展开过,这里不再赘述。
- 适配随机策略。由于策略梯度算法是基于策略函数的,因此可以适配随机策略,而基于价值的算法则需要一个确定的策略。此外其计算出来的策略梯度是无偏的,而基于价值的算法则是有偏的。
?但同样的,策略梯度算法也有其缺点。
- 采样效率低。由于使用的是蒙特卡洛估计,与基于价值算法的时序差分估计相比其采样速度必然是要慢很多的,这个问题在前面相关章节中也提到过。
- 高方差。虽然跟基于价值的算法一样都会导致高方差,但是策略梯度算法通常是在估计梯度时蒙特卡洛采样引起的高方差,这样的方差甚至比基于价值的算法还要高。
- 收敛性差。容易陷入局部最优,策略梯度方法并不保证全局最优解,因为它们可能会陷入局部最优点。策略空间可能非常复杂,存在多个局部最优点,因此算法可能会在局部最优点附近停滞。
- 难以处理高维离散动作空间:对于离散动作空间,采样的效率可能会受到限制,因为对每个动作的采样都需要计算一次策略。当动作空间非常大时,这可能会导致计算成本的急剧增加。
结合了策略梯度和值函数的?Actor-Critic?算法则能同时兼顾两者的优点,并且甚至能缓解两种方法都很难解决的高方差问题。
Q:为什么各自都有高方差的问题,结合了之后反而缓解了这个问题呢?
A:策略梯度算法是因为直接对策略参数化,相当于既要利用策略去与环境交互采样,又要利用采样去估计策略梯度,而基于价值的算法也是需要与环境交互采样来估计值函数的,因此也会有高方差的问题。
?而结合之后呢,Actor?部分还是负责估计策略梯度和采样,但?Critic?即原来的值函数部分就不需要采样而只负责估计值函数了,并且由于它估计的值函数指的是策略函数的值,相当于带来了一个更稳定的估计,来指导?Actor?的更新,反而能够缓解策略梯度估计带来的方差。
Q Actor-Critic算法

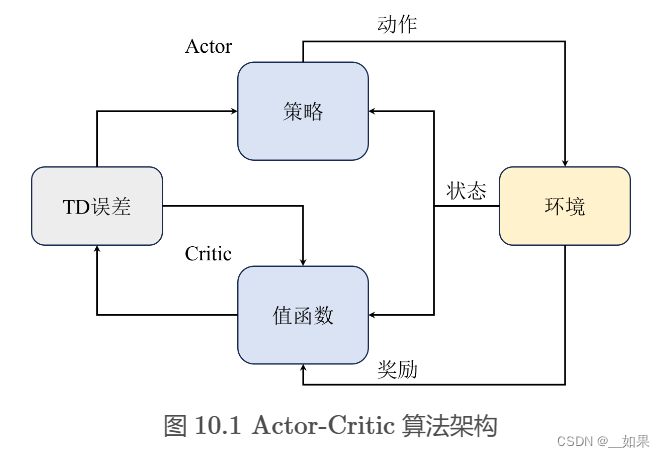
如图?10.1?所示,我们通常将?Actor?和?Critic?分别用两个模块来表示,即图中的策略函数(?Policy?)和价值函数(?Value Function?)。Actor与环境交互采样,然后将采样的轨迹输入?Critic?网络,Critic?网络估计出当前状态-动作对的价值,然后再将这个价值作为?Actor?网络的梯度更新的依据,这也是所有?Actor-Critic?算法的基本通用架构
A2C与A3C算法
A2C



A3C

广义优势估计
未完待续
文章来源:https://blog.csdn.net/m0_73202283/article/details/135755811
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 仰望星空,也要鲜花与掌声
- Javascript高频面试题
- C代码炫技巧
- 2024最新最全:【CISP系列考试大纲】零基础入门到精通
- express.js+mysql实现重置密码功能
- Bito智能辅助编程体验报告
- 从零学Java Object类
- STM32_HAL Freertos按键控制LED
- 结构方程模型分析-结构方程模型的构建与分析——超级详细版,结构方程模型修正(HPV认知与HPV疫苗接种意愿影响因素结构方程模型构建)
- Keil5,ARM编译器限制