Redis-学习笔记

一、数据类型
Redis定义了丰富的原语命令,可以直接与Redis服务器交互。
但是,实际应用中,我们不太会直接使用这些原语命令,Redis提供了很多客户端,大多情况下我们是通过各式各样的客户端来操作Redis。
但是,任何语言的客户端实际上都是对Redis原语命令的封装,了解原语命令有助于理解客户端的设计原理,知其然,知其所以然。
众所周知,Redis支持五中数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)及zset(sortedset:有序集合)
那么具体怎么使用他们呢?
1、String
简介:Redis的字符串是动态字符串,是可以修改的字符串,它的内部表示就是一个字符数组,内部结构的实现类似于Java的ArrayList,它的内部结构是一个带长度信息的字节数组。
特性:可以包含任何数据,比如jpg图片或者序列化的对象,规定字符串的长度不得超过512MB。Redis的字符串有两种存储方式,在长度特别短时,使用embstr形势存储,而长度超过44字节时候,使用raw形势存储
场景:
1、访问量统计:每次访问博客和文章使用 INCR 命令进行递增
2、将数据以二进制序列化的方式进行存储
String类型有三个特点:
1、String是Redis最基本的数据类型,结构为一个key对应一个value。
2、String类型是二进制安全的,意味着可以包含任何数据,比如jpg图片或者序列化的对象。
3、String类型的最大能存储512M。
Redis的原语命令很简单,而且有规律可循,一句话概括,就是干净利索脆,我们列举以下常用命令:
| 命令 | 说明 |
|---|---|
| SET?key value | 设置指定 key 的值 |
| GET?key | 获取指定 key 的值 |
| SETNX?key value | 只有在 key 不存在时设置 key 的值 |
| SETRANGE?key offset value | 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始 |
| GETRANGE?key start end | 返回 key 中字符串值的子字符 |
| MSET?key value [key value …] | Multi Set)同时设置一个或多个 key-value 对 |
| MGET?key1 [key2…] | 获取所有(一个或多个)给定 key 的值 |
| SETEX?key seconds value | (Set Expire)将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位) |
| PSETEX?key milliseconds value | (Precise Set Expire)这个命令和 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间,而不是像 SETEX 命令那样,以秒为单位 |
?
比如我们想设置往Redis中存放一个用户名,用String类型存储:
127.0.0.1:6379>?SET?name chenlongfei
OK
“OK”是Redis返回的响应,代表设置成功。
取出这个name的值:
127.0.0.1:6379>?GET?name
“chenlongfei”
想修改name的值为“clf”,重新SET一遍,覆盖掉原来的值:
127.0.0.1:6379>?SET?name clf
OK
127.0.0.1:6379>?GET?name
“clf”
想删除该条数据:
127.0.0.1:6379>?DEL?name
(integer) 1 --该数字代表影响的记录总数
127.0.0.1:6379>?GET?name
(nil) --nil代表为空,不存在该对象
增删改查命令一分钟学会,想忘记都难,妈妈再也不用担心我的学习!
2、Hash
Redis的哈希是field和value之间的映射,即键值对的集合,所以特别适合用于存储对象。
Redis 中每个 hash 最多可以存储 232 - 1 键值对(40多亿)。
简介:Redis的字典相当于Java语言里面的HashMap,字典结构内部包含了两个Hashtable,通常情况下只有一个Hashtable是有值的,但是在字典扩容缩容时候,需要重新分配新的Hashtable,然后进行渐进式搬迁,这时候两个Hashtable存储的分别是旧的Hashtable和新的Hashtable;待搬迁结束后,旧的Hashtable被删除,新的Hashtable取而代之。
特性:适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去)。大字典的扩容是比较耗时的,需要重新申请新的数组,然后将旧字典所有链表中的元素重新挂接到新的数组下面,这是一个O(n)级别的操作,作为单线程的Redis很难承受这样耗时的过程,所以Redis使用渐进式rehash小步搬迁虽然慢一点,但是肯定可以搬完。
场景:存储、读取、修改对象属性,比如:用户(姓名、性别、爱好),文章(标题、发布时间、作者、内容)
| 命令 | 说明 |
|---|---|
| HMSET?key field1 value1 [field2 value2… ] | (Hash Multi Set)同时将多个 field-value 对设置到哈希表 key 中 |
| HMGET?key field1 [field2…] | 获取所有给定字段的值 |
| HSET?key field value | 将哈希表 key 中的字段 field 的值设为 value |
| HGET?key field | 获取存储在哈希表中指定字段的值 |
| HGETALL?key | 获取在哈希表中指定 key 的所有字段和值 |
| HDEL?key field2 [field2] | 删除一个或多个哈希表字段 |
| HSETNX?key field value | 只有在字段 field 不存在时,设置哈希表字段的值 |
| HKEYS?key | 获取所有哈希表中的字段 |
| HVALS?key | 获取哈希表中所有值 |
例如,我们想在Redis中存储一个用户信息,包括用户ID,用户名,邮箱地址三个字段:
127.0.0.1:6379>HMSET?user_1 userId 123 userName clf email chenlongfei@163.com
OK
127.0.0.1:6379>?HGETALL?user_1
“userId”
“123”
“userName”
“clf”
“email”
“chenlongfei@163.com”
3、List
Redis列表是简单的字符串列表,按照插入顺序排序。
支持添加一个元素到列表头部(左边)或者尾部(右边)的操作。
一个列表最多可以包含 232- 1 ,即超过40亿个元素。
简介:Redis的列表相当于Java的LinkedList,List的结构底层实现不是一个简单的LinkedList,而是快速链表(quicklist)。首先在列表元素较少的情况下,会使用一块连续的内存存储,这个结构是ziplist,即压缩列表。它将所有的元素彼此紧挨着一起存储,分配的是一块连续的内存;当数据量比较多的时候才会改成quicklist。
特性:增删快,提供了操作某一段元素的API,普通的链表需要的附加指针空间太大,会浪费空间,加重内存的碎片化。Redis将链表和ziplist结合起来组成了quicklist,也就是将多个ziplist使用双向指针串联起来使用,既满足了快速的插入删除性能,又不会出现太大的空间冗余。
场景:
1、最新消息排行等功能(比如朋友圈的时间线)
2、消息队列
我们列举以下它的命令:
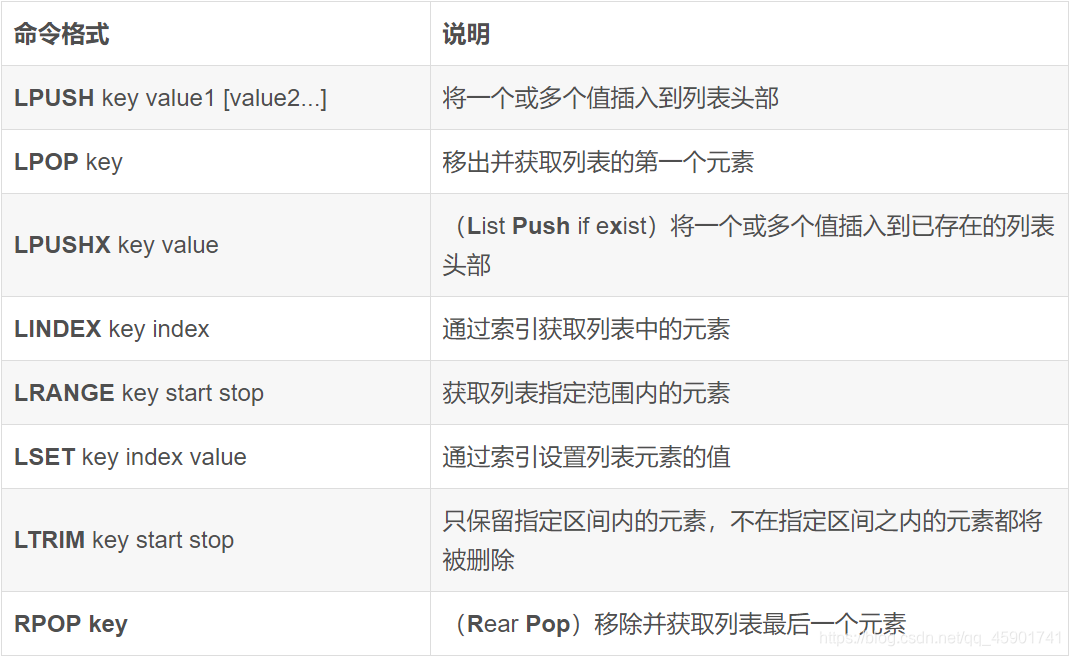
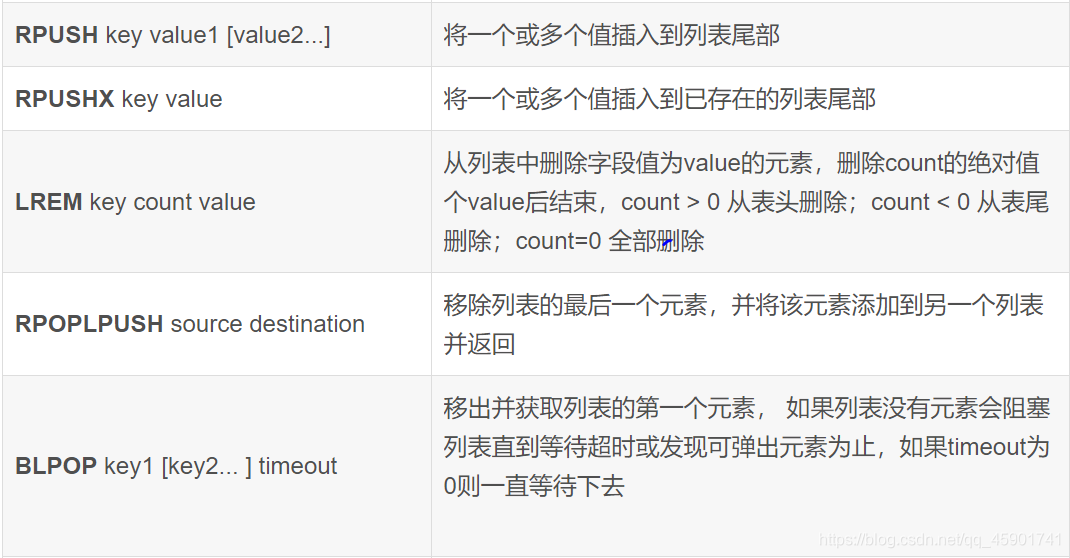
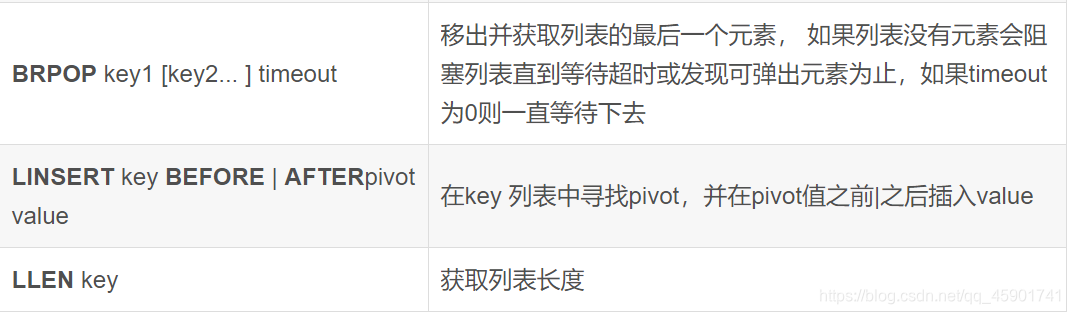
例如,我们想用一个名为“Continents”的列表盛放五大洲的名字:
127.0.0.1:6379>?LPUSH?Continents Asia Africa America Oceania Antarctica
(integer) 5
127.0.0.1:6379>?LRANGE?Continents 0 4 --获取下标为0~4的元素
“Antarctica”
“Oceania”
“America”
“Africa”
“Asia”
需要注意的是,Redis列表虽然名为列表,其实从特性上来讲更像是栈,以最近放进去的元素为头,以最早放进去的元素为尾,所以,Redis列表的下标呈倒序排列。上例中依次放进去的五个元素:Asia、Africa、America、Oceania、Antarctica,下标分别为4、3、2、1、0。
这与Java中List的概念完全不一样,需要特别注意。
与栈类似,当执行POP操作时,Redis列表弹出的是最新放进去的元素,类似于栈顶元素。
Redis列表还支持一种阻塞式操作,比如BLPOP(Blockd List Pop之缩写),移出并获取列表的第一个元素,如果列表没有元素(或列表不存在)会阻塞列表直到等待超时或发现可弹出元素为止。
例如,我们对一个不存在的列表“myList”执行BLPOP命令:
27.0.0.1:6379>?BLPOP?myList 20 – 弹出myList列表的第一个元素,如果没有,阻塞20秒该客户端会进入阻塞状态,如果20秒之内该列表存入了元素,则弹出:
27.0.0.1:6379>?BLPOP?myList 20 --若无元素则进入阻塞状态,限时20秒
“myList”
“hello”
(6.20s)
如果超时后仍然没有等到元素,则结束阻塞,返回nil:
127.0.0.1:6379>?BLPOP?myList 20
(nil)
(20.07s)
4、set(集合)
?
Redis集合是String类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
集合中最大的成员数为 2^32- 1 ,即每个集合最多可存储40多亿个成员。
Redis集合还有两大特点,一是支持随机获取元素,二是支持集合间的取差集、交集与并集操作。
简介:Redis的集合相当于Java语言里面的HashSet,内部的键值对是无须的、唯一的,Set的结构底层实现是字典,只不过所有的value都是NULL,其他的特性和字典一摸一样。
特性:
1、添加、删除、查找的复杂度都是O(1)
2、为集合提供了求交集、并集、差集等操作
当set集合容纳的元素都是整数并且元素个数较少时,Redis会使用intset来存储集合元素。intset是紧凑的数组结构,同时支持16位,32位和64位整数
场景:
1、共同好友
2、利用唯一性,统计访问网站的所有独立ip
3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐
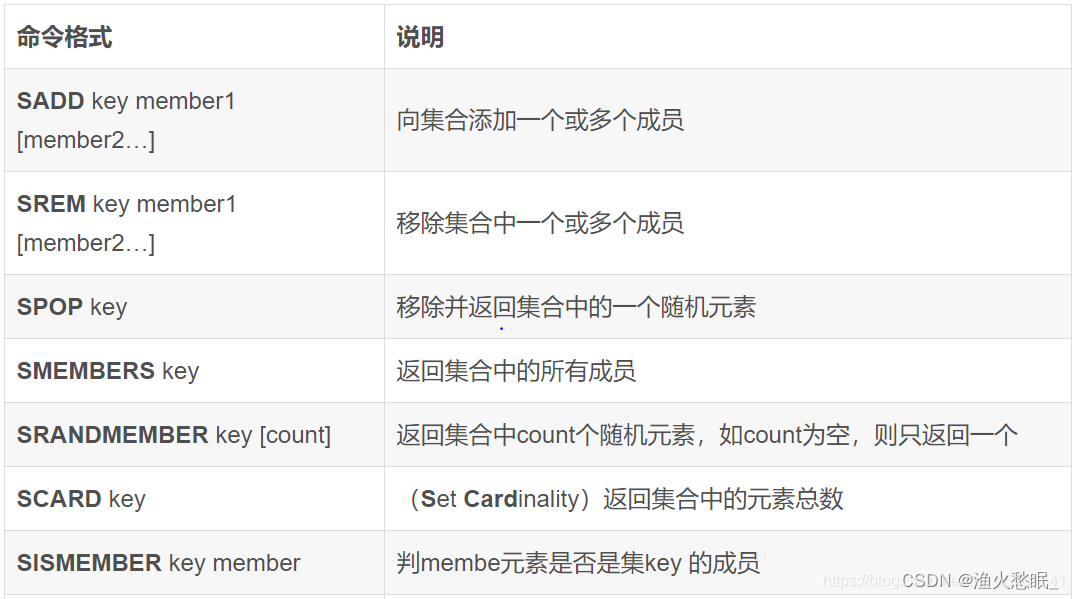
集合的一大特点就是不能有重复元素,如果插入重复元素,Redis会忽略该操作:
127.0.0.1:6379>?SADD?direction east west south north
(integer) 4
127.0.0.1:6379>?SMEMBERS?direction
“west”
“east”
“north”
“south”
127.0.0.1:6379>?SADD?direction east
(integer) 0 --east元素已经存在,该操作无效
127.0.0.1:6379>?SMEMBERS?direction
“west”
“east”
“north”
“south”
?
5、SortedSet(有序集合)
Redis 有序集合和集合一样也是String类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。Redis正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
集合中最大的成员数为 232- 1 ,即每个集合最多可存储40多亿个成员。
简介:Redis有序列表类似于Java的SortedSet和HashMap的结合体,一方面是一个set,保证内部value的唯一性,另一方面可以给每个value赋予一个score,代表这个value的排序权重。它的内部实现是一个Hash字典 + 一个跳表。
特性:
数据插入集合时,已经进行天然排序
Redis的跳表共有64层,能容纳2的64次方个元素。
Redis之所以用跳表来实现有序集合
插入、删除、查找以及迭代输出有序序列这几个操作,红黑树都能完成,时间复杂度跟跳表是一样的。但是按照区间来查找数据,红黑树的效率就没有跳表高
跳表更容易代码实现,比起红黑树来说还是好懂、好写很多,可读性好,不容易出错
跳表更加灵活,可以通过改变索引构建策略,有效平衡执行效率和内存消耗
场景:
1、排行榜,取TopN操作
2、带权重的消息队列

例如,、使用有序列表来存储学生的成绩单:
127.0.0.1:6379>?ZADD?scoreList 82 Tom
(integer) 1
127.0.0.1:6379>?ZADD?scoreList 65.5 Jack
(integer) 1
127.0.0.1:6379>?ZADD?scoreList 43.5 Rubby
(integer) 1
127.0.0.1:6379>?ZADD?scoreList 99 Winner
(integer) 1
127.0.0.1:6379>?ZADD?scoreList 78 Linda
(integer) 1
127.0.0.1:6379>?ZRANGE?scoreList 0 100 WITHSCORES --获取名次在0~100之间的记录
1)“Rubby”
2)“43.5”
3)“Jack”
4)“65.5”
5)“Linda”
6)“78”
7)“Tom”
8)“82”
9)“Winner”
10)“100”
需要注意的是,Redis有序集合是默认升序的,score越低排名越靠前,即score越低的元素下标越小。
?二、存储结构
我们都知道,Redis存取都比Mysql快得多,除开众所周知的他是个内存数据库之外,还有什么原因呢?
1、Redis 采用的是 ANSI C 语言编写,采用 C 语言编写的好处是底层代码执行效率高。依赖性低,使用 C 语言开发的库没有太多运行时(Runtime)依赖,并且系统兼容性好,稳定性高。
2、Redis 采用的 Key-Value 方式进行存储,数据的操作复杂度为 O(1)。
3、采用单线程模型,单线程避免了线程上下文切换和不必要的线程资源竞争。
4、采用了多路 I/O 复用技术,这里的多路是多个 Socket 网络连接,复用是指复用一个线程,采用多路技术的好处是同一个线程中可以处理多个 I/O 请求,减少网络 IO 消耗,提升了使用效率。
5、众所周知也是最最关键的原因,内存存储:Redis是使用内存(in-memeroy)存储,没有磁盘IO上的开销
而且,Redis的一种对象类型可以有不同的存储结构来实现,从而同时兼顾性能和内存。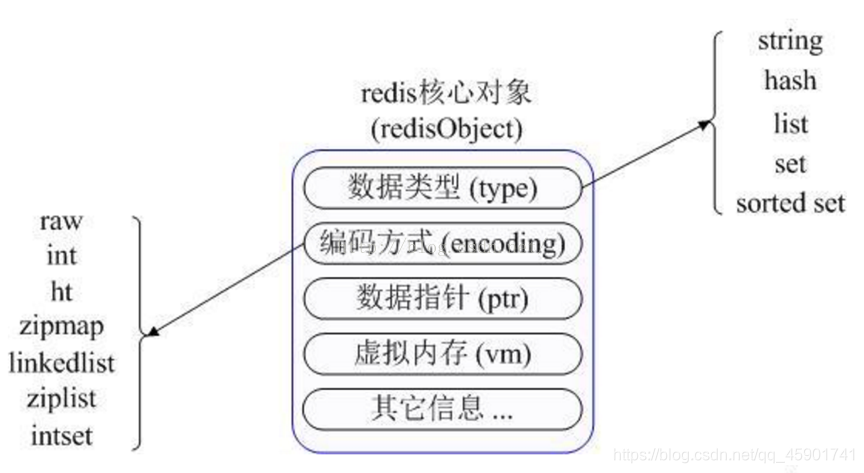
字典是Redis最基础的数据结构,一个字典即一个DB,Redis支持多DB。
Redis字典采用Hash表实现,针对碰撞问题,采用的方法为“链地址法”,即将多个哈希值相同的节点串连在一起,从而解决冲突问题。
但是,“链地址法”的问题在于当碰撞剧烈时,性能退化严重,例如:当有n个数据,m个槽位,如果m=1,则整个Hash表退化为链表,查询复杂度O(n)。为了避免Hash碰撞攻击,Redis随机化了Hash表种子。
Redis的方案是“双buffer”,正常流程使用一个buffer,当发现碰撞剧烈(判断依据为当前槽位数和Key数的对比),分配一个更大的buffer,然后逐步将数据从老的buffer迁移到新的buffer。
redisObject是真正存储redis各种类型的结构,在Redis源码的redis.h文件中,定义了这些结构:
#define REDIS_LRU_BITS 24
#define REDIS_LRU_CLOCK_MAX ((1<<REDIS_LRU_BITS)-1)/* Max value of obj->lru */
#define REDIS_LRU_CLOCK_RESOLUTION 1000/* LRU clock resolution in ms */
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time(relative to server.lruclock) */
intrefcount;
void*ptr;
} robj;
type即Redis支持的逻辑类型,包括:
/* Object types*/
#define REDIS_STRING 0
#define REDIS_LIST 1
#define REDIS_SET 2
#define REDIS_ZSET 3
#define REDIS_HASH 4
即前面所列举的五种数据类型。
而type定义的只是逻辑类型,encoding才是物理存储方式,一种逻辑类型可以使用不同的存储方式,包括:
/* Objectsencoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The'encoding' field of the object
* is set to one of this fields for thisobject. */
#defineREDIS_ENCODING_RAW 0 /* Rawrepresentation */
#defineREDIS_ENCODING_INT 1 /* Encoded asinteger */
#define REDIS_ENCODING_HT2 /* Encoded as hash table */
#defineREDIS_ENCODING_ZIPMAP 3 /* Encoded aszipmap */
#defineREDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
#defineREDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define REDIS_ENCODING_INTSET6 /* Encoded as intset */
#defineREDIS_ENCODING_SKIPLIST 7 /* Encoded asskiplist */
#defineREDIS_ENCODING_EMBSTR 8 /* Embedded sdsstring encoding */
(1)?REDIS_ENCODING_RAW?即原生态的存储结构,就是以字符串形式存储,字符串类型在redis中用 sds ( s imple d ynamic s tring)封装,主要为了解决长度计算和追加效率的问题。
(2)REDIS_ENCODING_INT?代表整数,以long型存储。
(3)?REDIS_ENCODING_HT?代表哈希表(Hash Table),以哈希表结构存储,与字典的实现方法一致。
(4)REDIS_ENCODING_ZIPMAP?其实质是用一个字符串数组来依次保存key和value,查询时是依次遍列每个key-value 对,直到查到为止。
(5)REDIS_ENCODING_LINKEDLIST?代表链表,以典型的链表结构存储。
(6)?REDIS_ENCODING_ZIPLIST?代表一种双端列表,且通过特殊的格式定义,压缩内存适用,以时间换空间。ZIPLIST适合小数据量的读场景,不适合大数据量的多写/删除场景。
(7)?REDIS_ENCODING_INTSET?是用一个有序的整数数组来实现的。
(8)REDIS_ENCODING_SKIPLIST?同时采用字典和有序集两种数据结构来保存数据元素。跳跃表(SkipList)是一个特殊的链表,相比一般的链表,有更高的查找效率,其效率可比拟于二叉查找树。缺点即浪费了空间,自古空间和时间两难全。
(9)REDIS_ENCODING_EMBSTR?代表使用embstr编码的简单动态字符串。好处有如下几点: embstr的创建只需分配一次内存,而raw为两次(一次为sds分配对象,另一次为objet分配对象,embstr省去了第一次)。相对地,释放内存的次数也由两次变为一次。embstr的objet和sds放在一起,更好地利用缓存带来的优势。需要注意的是,Redis并未提供任何修改embstr的方式,即embstr是只读的形式。对embstr的修改实际上是先转换为raw再进行修改。
1、 String的存储结构
Redis的所有的key都采用字符串保存,而值可以是字符串,列表,哈希,集合和有序集合对象的其中一种。
字符串存储的逻辑类型即REDIS_STRING,其物理实现(enconding)可以为 REDIS_ENCODING_INT、 REDIS_ENCODING_EMBSTR或REDIS_ENCODING_RAW。
首先,如果可以使用REDIS_ENCODING_EMBSTR编码,Redis首选REDIS_ENCODING_EMBSTR保存;
其次,如果可以转换,Redis会尝试将一个字符串转化为Long,保存为REDIS_ENCODING_INT,如“26”、“180”等;最后,Redis会保存为REDIS_ENCODING_RAW,如“chenlongfei”、“Redis”等。
2、 Hash的存储结构
REDIS_HASH可以有两种encoding方式: REDIS_ENCODING_ZIPLIST 和 REDIS_ENCODING_HT
Hash表默认的编码格式为REDIS_ENCODING_ZIPLIST,在收到来自用户的插入数据的命令时:
(1)调用hashTypeTryConversion函数检查键/值的长度大于配置的hash_max_ziplist_value(默认64)
(2)调用hashTypeSet判断节点数量大于配置的hash_max_ziplist_entries(默认512)
以上任意条件满足则将Hash表的数据结构从REDIS_ENCODING_ZIPLIST转为REDIS_ENCODING_HT。
3、 List的存储结构
REDIS_SET有两种encoding方式,REDIS_ENCODING_ZIPLIST和REDIS_ENCODING_LINKEDLIST。
列表的默认编码格式为REDIS_ENCODING_ZIPLIST,当满足以下条件时,编码格式转换为REDIS_ENCODING_LINKEDLIST:
(1)元素大小大于list-max-ziplist-value(默认64)
(2)元素个数大于配置的list-max-ziplist-entries(默认512)
4、 Set的存储结构
REDIS_SET有两种encoding方式: REDIS_ENCODING_INTSET 和 REDIS_ENCODING_HT。
集合的元素类型和数量决定了encoding方式,默认采用REDIS_ENCODING_INTSET ,当满足以下条件时,转换为REDIS_ENCODING_HT:
(1)元素类型不是整数
(2)元素个数超过配置的set-max-intset-entries(默认512)
5、SortedSet的存储结构
REDIS_ZSET有两种encoding方式: REDIS_ENCODING_ZIPLIST(同上)和 REDIS_ENCODING_SKIPLIST。
由于有序集合每一个元素包括:<member,score>两个属性,为了保证对member和score都有很好的查询性能,REDIS_ENCODING_SKIPLIST同时采用字典和有序集两种数据结构来保存数据元素。字典和有序集通过指针指向同一个数据节点来避免数据冗余。
字典中使用member作为key,score作为value,从而保证在O(1)时间对member的查找跳跃表基于score做排序,从而保证在 O(logN) 时间内完成通过score对memer的查询。
有序集合默认也是采用REDIS_ENCODING_ZIPLIST的实现,当满足以下条件时,转换为REDIS_ENCODING_SKIPLIST:
(1)数据元素个数超过配置zset_max_ziplist_entries 的值(默认值为 128 )
(2)新添加元素的 member 的长度大于配置的zset_max_ziplist_value 的值(默认值为 64 )
三、Redis持久化
为什么要持久化?
众所周知,Redis本身运行时数据保存在内存中。
所以,那么在关闭redis的进程或者关闭计算机后数据肯定被会操作系统从内存中清掉。
而为了避免这一情况,redis默认采用了一种持久化方式,即RDB (Redis DataBase)——可以在redis的目录中找到dump.rdb文件,这就是使用RDB方式做持久化后生成的数据文件。
所以,redis如果没有做持久化,在重启redis后,数据会丢失,而redis默认就采用了一种持久化方式,即RDB。
1、持久化方式
redis的持久化方式有两种,RDB (Redis DataBase)和 AOF (Append Only File),下面分别对两种持久化方式做一个介绍。
1、 RDB
RDB(Redis DataBase)方式采用的思想是定时将内存中的数据进行快照,并写入dump.rdb文件当中,这个文件当中所存储的就是当前redis环境中的配置以及数据。
因此,每次当redis重启之后,redis会先读dump.rdb文件,将数据从硬盘写入到内存中。
1、RDB模式的配置方式
在redis的配置文件redis.conf中搜索save,这一个save可以设置在指定时间内,更新操作达到了固定次数,就将数据同步到数据文件,这里可以写多个save多条件配合使用。比如以下代码所示:
?# 表示900秒内有一次更改,或者900秒内有10次更改,或者60秒内有10000此更改执行同步操作 ?save 900 1 ?save 300 10 ?save 60 10000
另外,如果想不使用RDB做持久化了,可以不配置任何的save,或者将save配成空字符串
2、dbfilename与dir
在redis的配置文件中如果使用RDB的方式做持久化,除了要注意save的配置外,还有两个配置需注意。
dbfilename:这一个配置表示存储的快照文件(数据文件)的文件名,redis默认为dump.rdb,所以我们看到redis目录中会有这样一个文件,这个文件中存放了二进制的内容。
dir:表示了dbfilename所配置的这一个文件的路径,这里最好配一个绝对路径,因为如果使用了相对路径,那么通过不同的方式其启动redis可能会出现文件找不到导致数据前后不一致的情况发生。
2、AOF
redis默认是关闭AOF(Append-only file)模式持久化的,如果要使用需要修改一下配置:
?# 默认为no,需修改为yes
?appendonly yes
?# AOF默认的持久化文件的文件名称
?appendfilename "appendonly.aof"而指定更新日志条件的同步策略有三个可选条件:
?# 当操作系统进行数据缓存同步到磁盘文件
?# appendfsync no
?# 同步持久化,当数据发生变更时,立即同步到磁盘文件(效率慢些,能保证数据的完整性)
?# appendfsync always
?# 每秒同步一次(默认值,也是最佳的选择,速度快,可能会丢失一秒以内的数据(最多不过2秒))
?appendfsync everysec另外,可以配置当持久化的文件到达一定程度后,进行重写,为什么要进行重写?由于AOF模式持久化记录的是操作命令,比如说当有这两个命令set key "value1", set key "value2"依次执行后,实际上要恢复数据只需要执行set key "value2"即可。经过类似的压缩,可以为原本已经很大的文件“瘦身”,以下的内容,即为执行此“瘦身”操作的配置。
?# 当AOF的持久化文件大小的增长率大于此配置时,自动开启重写,redis会自动执行“BGREWRITEAOF”命令;
?auto-aof-rewrite-percentage 100
?# 当AOF的持久化文件大小大于此配置时,自动开启重写,redis会自动执行“BGREWRITEAOF”命令;
?auto-aof-rewrite-min-size 3000mbAOF模式的优缺点
AOF模式的优点如下:
(1)AOF模式可以更好的保护数据不丢失,在redis因为非正常原因挂掉时,其保存数据的完整度理论上高于RDB模式,因为采用appendfsync everysec去写入持久化文件,最多丢失一秒到两秒的数据;而RDB模式丢失的数据根据其配置的写入频率决定;
(2)AOF写入性能高,这归功于其是以append-only的方式写入;
而AOF的缺点如下:
(1)对于同样的数据,通常AOF文件的大小回比RDB的要大;
(2)因为AOF存的是命令而不是数据,所以恢复数据时可能较慢。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!